Azure Data Factory と Synapse Analytics を使用して Azure Data Lake Analytics で U-SQL スクリプトを実行してデータを処理する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory または Synapse Analytics ワークスペースのパイプラインは、リンクされたコンピューティング サービスを使用して、リンクされたストレージ サービス内のデータを処理します。 パイプラインは、一連のアクティビティで構成されます。各アクティビティは、特定の処理操作を実行します。 この記事では、Azure Data Lake Analytics コンピューティング リンク サービスで U-SQL スクリプトを実行する Data Lake Analytics U-SQL アクティビティについて説明します。
Data Lake Analytics U-SQL アクティビティでパイプラインを作成する前に、Azure Data Lake Analytics アカウントを作成します。 Azure Data Lake Analytics の詳細については、 Azure Data Lake Analytics の使用開始に関するページをご覧ください。
UI を使用したパイプラインへの Azure Data Lake Analytics の U-SQL アクティビティの追加
パイプラインで Azure Data Lake Analytics に対して U-SQL アクティビティを使用するには、次の手順を実行します。
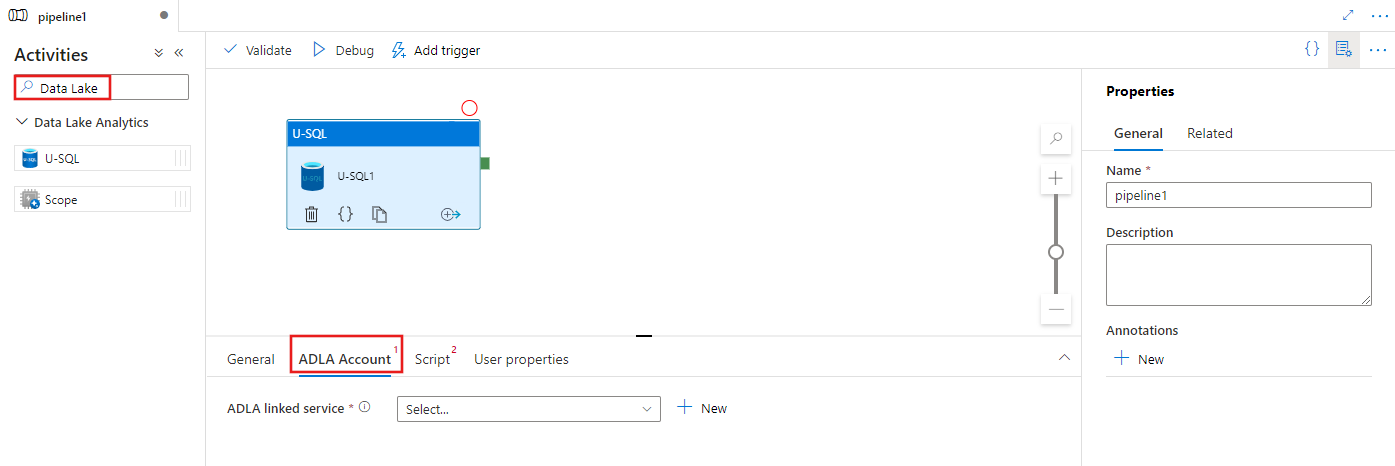
パイプラインの [アクティビティ] ペイン内で Data Lake を検索し、U-SQL アクティビティをパイプライン キャンバスにドラッグします。
まだ選択されていない場合は、キャンバスで新しい U-SQL アクティビティを選択します。
[ADLA アカウント] タブを選択して、U-SQL アクティビティを実行するために使用する新しい Azure Data Lake Analytics リンクされたサービスを選択または作成します。
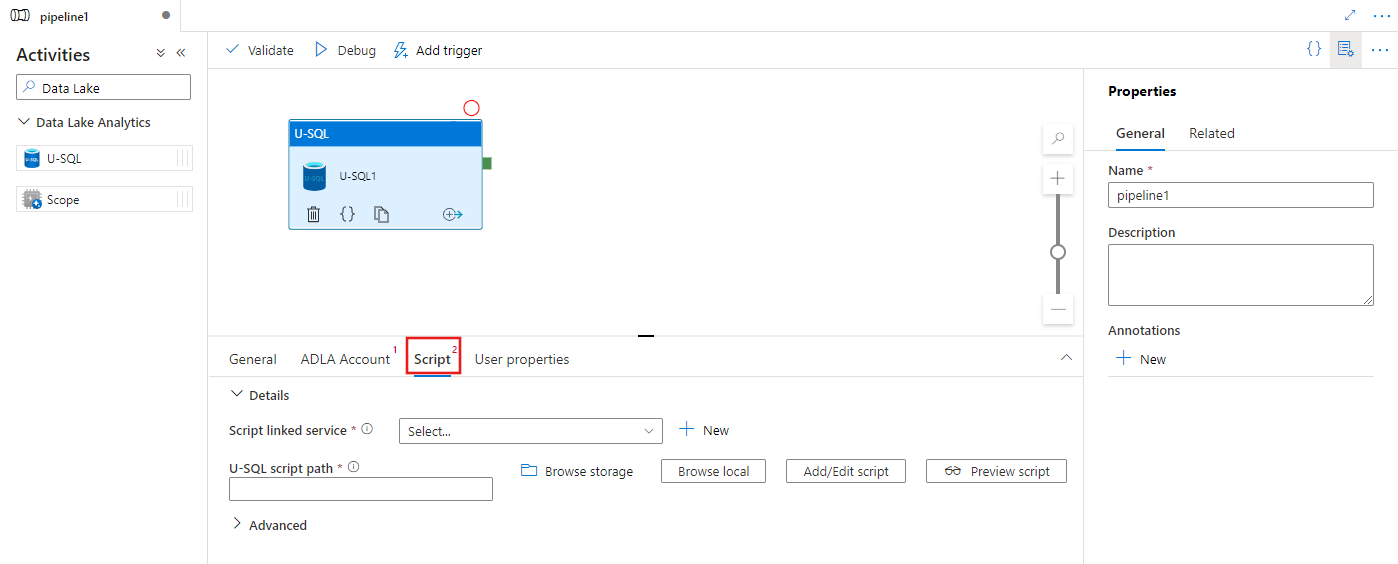
[スクリプト] タブを選択して、新しいストレージのリンクされたサービスと、スクリプトをホストするストレージの場所内のパスを選択または作成します。
Azure Data Lake Analytics リンク サービス
Azure Data Lake Analytics リンク サービスを作成して、Azure Data Lake Analytics コンピューティング サービスを Azure Data Factory または Synapse Analytics ワークスペースにリンクします。 パイプラインの Data Lake Analytics U-SQL アクティビティは、このリンク サービスを参照します。
次の表では、JSON 定義で使用される一般的なプロパティを説明しています。
| プロパティ | Description | 必須 |
|---|---|---|
| type | type プロパティは次の値に設定されます。AzureDataLakeAnalytics。 | はい |
| accountName | Azure Data Lake Analytics アカウント名。 | はい |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI。 | いいえ |
| subscriptionId | Azure サブスクリプション ID | いいえ |
| resourceGroupName | Azure リソース グループ名 | いいえ |
サービス プリンシパルの認証
Azure Data Lake Analytics のリンクされたサービスには、Azure Data Lake Analytics サービスに接続するためのサービス プリンシパル認証が必要です。 サービス プリンシパル認証を使用するには、Microsoft Entra ID にアプリケーション エンティティを登録し、Data Lake Analytics とそれが使用する Data Lake Store の両方へのアクセス権を付与します。 詳細な手順については、「サービス間認証」を参照してください。 次の値を記録しておきます。リンクされたサービスを定義するときに使います。
- アプリケーション ID
- アプリケーション キー
- テナント ID
ユーザー追加ウィザードを使用して、Azure Data Lake Analytics へのサービス プリンシパル アクセス許可を付与します。
次のプロパティを指定して、サービス プリンシパル認証を使います。
| プロパティ | Description | 必須 |
|---|---|---|
| servicePrincipalId | アプリケーションのクライアント ID を取得します。 | はい |
| servicePrincipalKey | アプリケーションのキーを取得します。 | はい |
| tenant | アプリケーションが存在するテナントの情報 (ドメイン名またはテナント ID) を指定します。 Azure Portal の右上隅をマウスでポイントすることにより取得できます。 | はい |
例:サービス プリンシパルの認証
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。
Data Lake Analytics U-SQL アクティビティ
次の JSON のスニペットでは、Data Lake Analytics U-SQL アクティビティを使用してパイプラインを定義します。 このアクティビティ定義には、先ほど作成した Azure Data Lake Analytics リンク サービスへの参照が含まれています。 Data Lake Analytics U-SQL スクリプトを実行するために、指定したスクリプトがサービスによって Data Lake Analytics に送信されます。必要な入力と出力は、Data Lake Analytics がフェッチおよび出力するためのスクリプトで定義されています。
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
次の表は、このアクティビティに固有のプロパティの名前と説明です。
| プロパティ | Description | 必須 |
|---|---|---|
| name | パイプラインのアクティビティの名前。 | はい |
| description | アクティビティの動作を説明するテキスト。 | いいえ |
| type | Data Lake Analytics U-SQL アクティビティの場合、アクティビティの種類は DataLakeAnalyticsU-SQL です。 | はい |
| linkedServiceName | Azure Data Lake Analytics にリンクされたサービス。 このリンクされたサービスの詳細については、計算のリンクされたサービスに関する記事をご覧ください。 | はい |
| scriptPath | U-SQL スクリプトを含むフォルダーのパス。 ファイル名は大文字と小文字が区別されます。 | はい |
| scriptLinkedService | スクリプトを含む Azure Data Lake Store または Azure Storage をリンクするリンク サービス | はい |
| degreeOfParallelism | ジョブを実行するために同時に使用される最大ノード数。 | いいえ |
| priority | キューされているすべてのジョブのうち、先に実行するジョブを決定します。 数値が小さいほど、優先度は高くなります。 | いいえ |
| parameters | U-SQL スクリプトに渡すパラメーター。 | いいえ |
| runtimeVersion | 使用する U-SQL エンジンのランタイム バージョン。 | いいえ |
| compilationMode | U-SQL のコンパイル モード。 次のいずれかの値を指定する必要があります。Semantic: セマンティック チェックと必要なサニティ チェックのみを実行します。Full: 構文チェック、最適化、コード生成などを含めた完全コンパイルを実行します。SingleBox: TargetType を SingleBox に設定して完全コンパイルを実行します。 このプロパティの値を指定しない場合、サーバーが最適なコンパイル モードを決定します。 |
いいえ |
スクリプト定義については、SearchLogProcessing.txt をご覧ください。
U-SQL スクリプトのサンプル
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
前述のスクリプト例では、スクリプトの入力と出力は @in パラメーターと @out パラメーターで定義されます。 U-SQL スクリプトの @in および @out パラメーターの値は、'parameters' セクションを使用してサービスによって動的に渡されます。
Azure Data Lake Analytics サービスで実行されるジョブのパイプライン定義で、他のプロパティ (degreeOfParallelism など) や優先度も指定できます。
動的パラメーター
パイプライン定義のサンプルでは、in パラメーターと out パラメーターにハード コーディングされた値が割り当てられています。
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
代わりに、動的パラメーターを使用することもできます。 次に例を示します。
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
この場合、入力ファイルは引き続き /datalake/input フォルダーから取得され、出力ファイルは /datalake/output フォルダーに生成されます。 ファイル名は、パイプラインのトリガー時に渡される期間の開始時間に基づいて動的に付けられます。
関連するコンテンツ
別の手段でデータを変換する方法を説明している次の記事を参照してください。