Azure Data Factory および Azure Synapse Analytics でパイプラインの戻り値を設定する
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
呼び出し元パイプラインと子パイプラインのパラダイムでは、Set Variable アクティビティ を使用して、子パイプラインから呼び出し元パイプラインに値を返すことができます。 次のシナリオでは、Execute Pipeline アクティビティを通じて子パイプラインが存在します。 また、子パイプラインから情報を取得し、呼び出し元パイプラインで使用する必要があります。
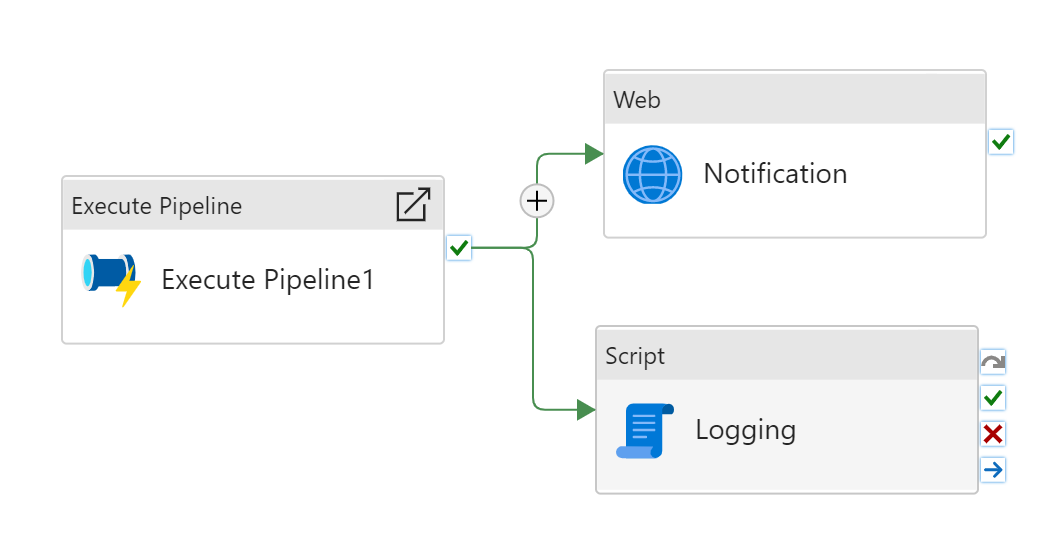
子パイプラインと親パイプライン間の通信を可能にする、キーと値のペアのディクショナリであるパイプラインの戻り値を導入します。
前提条件 - 子パイプラインの呼び出し
前提条件として、設計には、子パイプラインを呼び出す Execute Pipeline Activity を含め、そのアクティビティ上で Wait on Completion を有効にする必要があります。
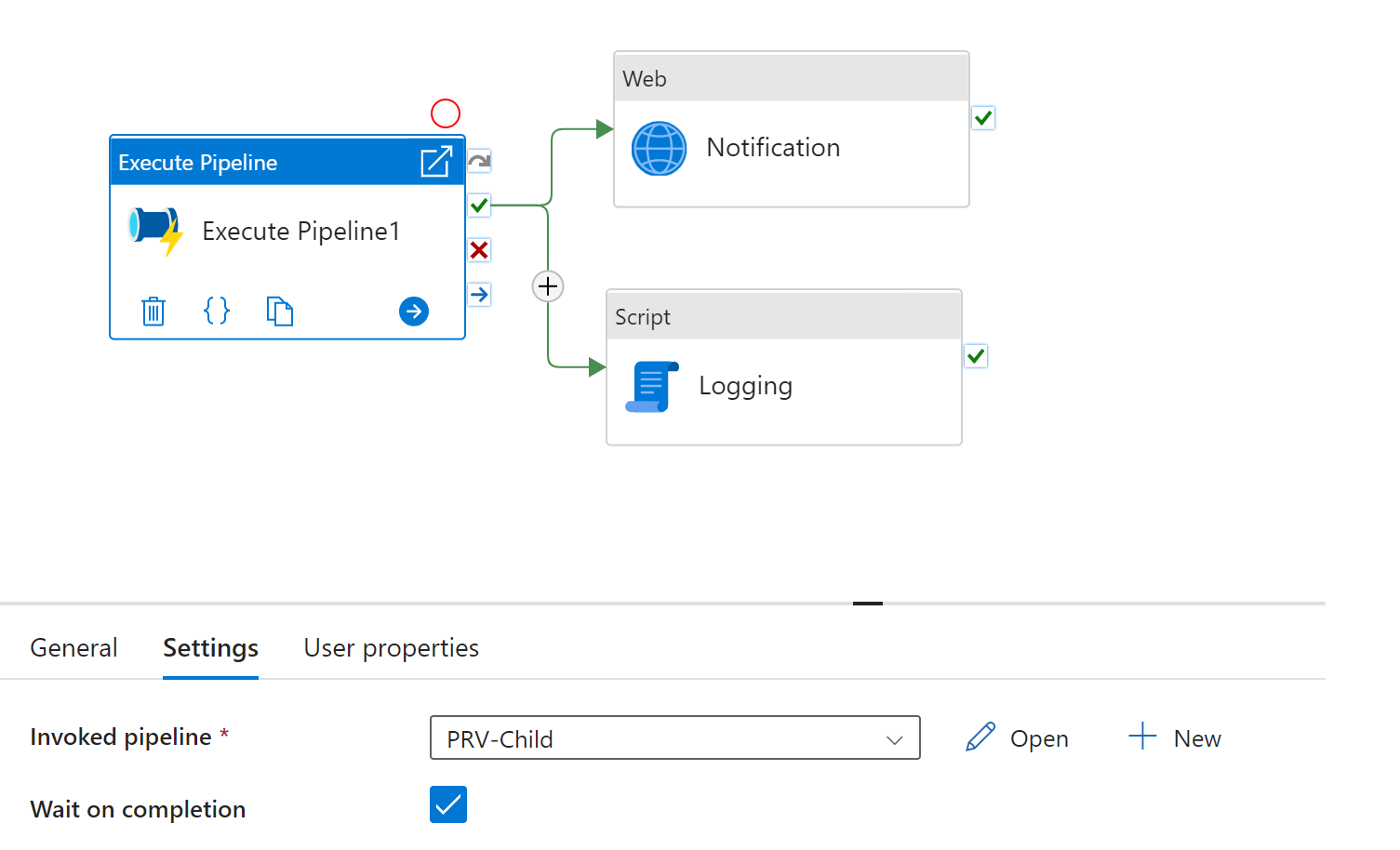
子パイプラインでパイプラインの戻り値を構成する
システム変数 Pipeline Return Value を含むように、Set Variable Ativity を拡張しました。 (パイプライン で使用する他の変数とは対照的に) パイプライン レベルで定義する必要はありません。
- パイプラインのアクティビティ ペイン内で "変数の設定" を検索し、変数の設定アクティビティをパイプライン キャンバスにドラッグします。
- キャンバス上で変数の設定アクティビティ (まだ選ばれていない場合)、その [変数] タブの順に選んで、その詳細を編集します。
- 変数型に [Pipeline return value](パイプラインの戻り値) を選択します。
- [新規] を選択して、新しいキーと値のペアを追加します。
- 追加できるキーと値のペアの数は、返される JSON のサイズ制限 (4 MB) によってのみ制限されます。
 の UI を示すスクリーンショット。](media/pipeline-return-value/pipeline-return-value-02-child-pipeline.png)
値の型には、次のようないくつかのオプションがあります
| 種類名 | 説明 |
|---|---|
| String | 定数文字列値。 例: 'ADF is awesome' |
| Expression | 以前のアクティビティからの出力を参照できます。 ここで文字列補間を使用して、"The value is @{guid()}" などのインライン式の値を含めることができます。 |
| Array | "文字列値" の配列である必要があります。 配列内の値を区切るには "Enter" キーを押します |
| Boolean | True または False |
| Null | シグナルのプレースホールダーの状態。値は定数 null です |
| int | 整数型の数値。 例: 42 |
| Float | float 型の数値。 例: 2.71828 |
| Object | 警告 (複雑なユース ケースのみ)。 値に対するキーと値のペアの型のリストを埋め込むことができます |
オブジェクト型の値は、次のように定義されます。
[{"key": "myKey1", "value": {"type": "String", "content": "hello world"}},
{"key": "myKey2", "value": {"type": "String", "content": "hi"}}
]
呼び出し元パイプラインでの値の取得
子パイプラインのパイプラインの戻り値は、Execute Pipeline アクティビティのアクティビティ出力になります。 @activity('Execute Pipeline1').output.pipelineReturnValue.keyName を使用して情報を取得できます。 ユース ケースには限りがありません。 たとえば、以下を使用できます
- Wait アクティビティの待機期間を定義するための子パイプラインからの int 値。
- Web アクティビティの URL を定義するための "文字列" の値。
- ログ記録用の Script アクティビティの expression 値のペイロード。
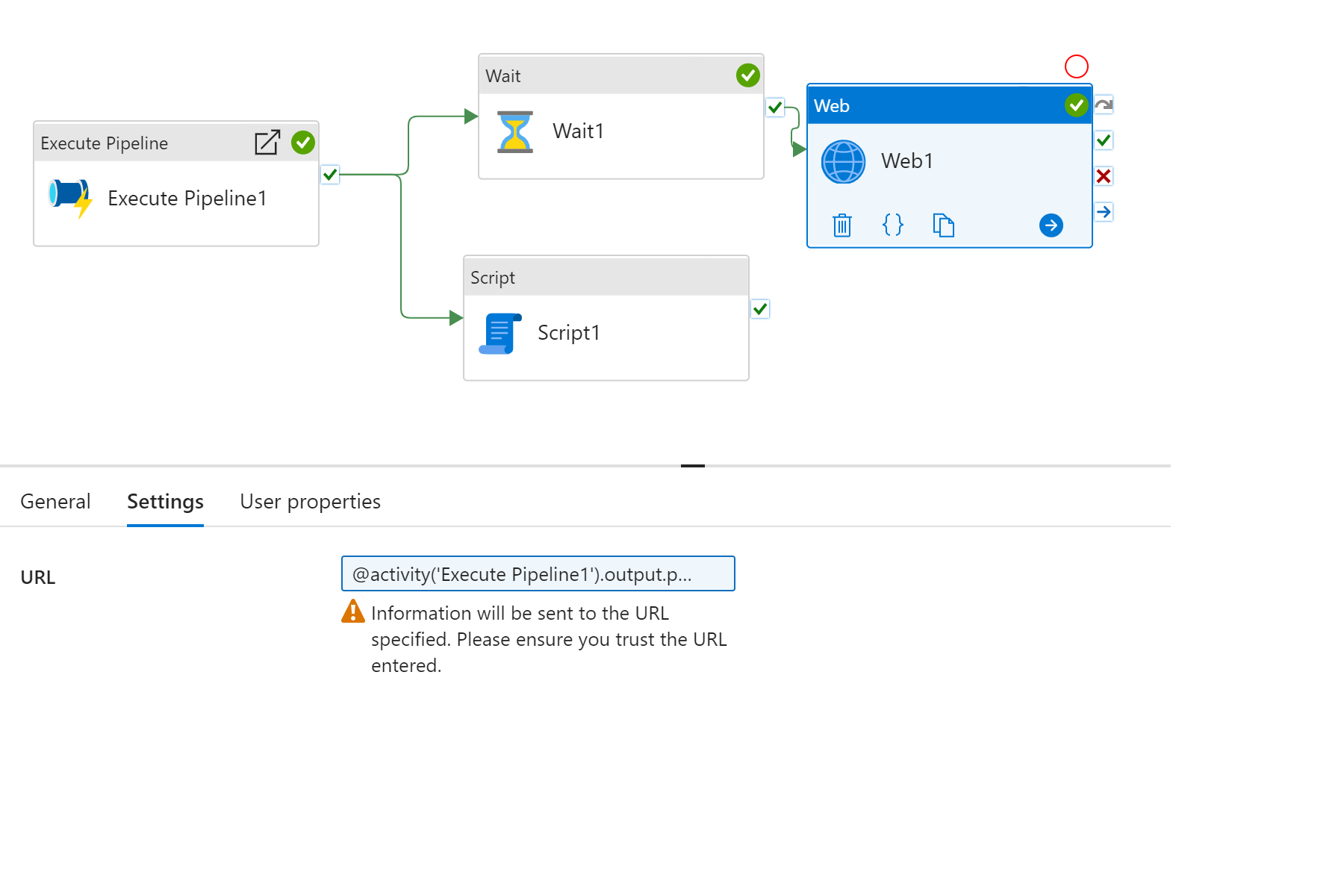
パイプラインの戻り値の参照には、2 つの重要なコールアウトがあります。
- Object 型を使用すると、入れ子になった JSON オブジェクトへとさらに拡張を行うことができます。例: @activity('Execute Pipeline1').output.pipelineReturnValue.keyName.nextLevelKey
- Array 型を使用すると、@activity('Execute Pipeline1').output.pipelineReturnValue.keyName[0] といった形式で、リストのインデックスを指定できます。 インデックスには 0 の数値があります。つまり、0 から始まります。
注意
参照している keyName が子パイプラインに存在することを確認してください。 ADF 式ビルダーは自動で参照チェックを確認することが "できません"。 参照されているキーがペイロードに存在しない場合、パイプラインは失敗します
特別な考慮事項
パイプラインには複数の Set Pipeline Return Value アクティビティを含めることができますが、パイプラインで実行されるのはそのうちの 1 つだけになるようにすることが重要です。
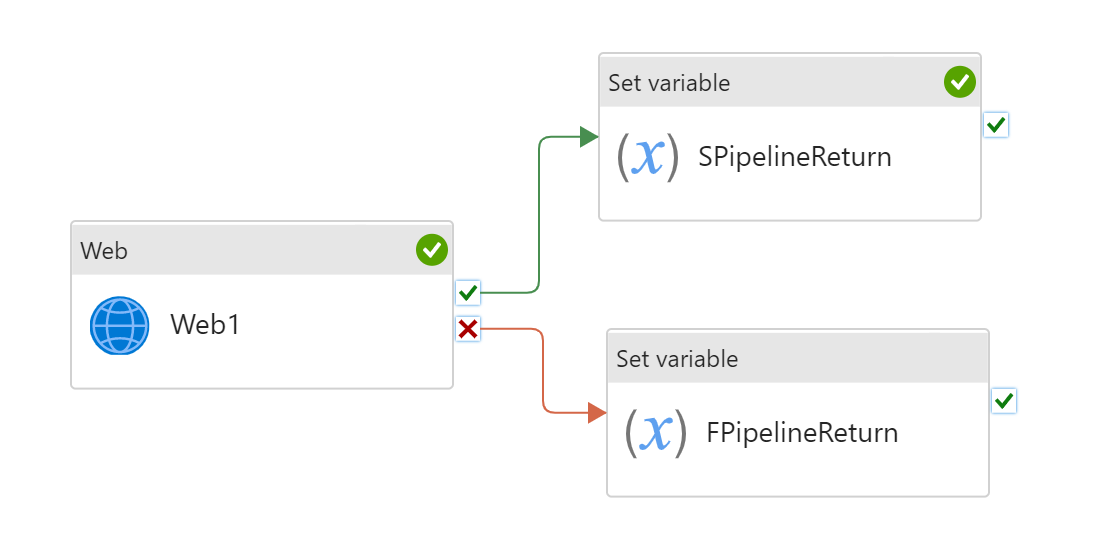
前述の呼び出し元パイプラインでキーが見つからない状況を回避するために、子パイプライン内のすべてのブランチに対して同じキーのリストを使用することをお勧めします。 特定のブランチで、値を持たないキーには null 型を使用することを検討してください。
Azure Data Factory 式言語は、インライン JSON オブジェクトを直接サポートしていません。 代わりに、文字列と式を適切に連結する必要があります。
たとえば、次の JSON 式の場合は次のようになります。
{ "datetime": "@{utcnow()}", "date": "@{substring(utcnow(),0,10)}", "year": "@{substring(utcnow(),0,4)}", "month": "@{substring(utcnow(),5,2)}", "day": "@{substring(utcnow(),8,2)}" }同等の Azure Data Factory 式の場合は次のようになります。
@{ concat( '{', '"datetime": "', utcnow(), '", ', '"date": "', substring(utcnow(),0,10), '", ', '"year": "', substring(utcnow(),0,4), '", ', '"month": "', substring(utcnow(),5,2), '", ', '"day": "', substring(utcnow(),8,2), '"', '}' ) }
関連するコンテンツ
制御フローに関連するその他のアクティビティを確認します。