Azure portal から Azure Data Factory 内の Hive アクティビティを使用して Azure Virtual Network のデータを変換する
適用対象: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure Portal を使用して Data Factory パイプラインを作成します。このパイプラインで、Azure Virtual Network (VNet) にある HDInsight クラスター上の Hive アクティビティを使用してデータを変換します。 このチュートリアルでは、以下の手順を実行します。
- データ ファクトリを作成します。
- 自己ホスト型統合ランタイムを作成する
- Azure Storage および Azure HDInsight のリンクされたサービスを作成する
- Hive アクティビティを含むパイプラインを作成する。
- パイプラインの実行をトリガーする。
- パイプラインの実行を監視します
- 出力を検証する
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
Note
Azure を操作するには、Azure Az PowerShell モジュールを使用することをお勧めします。 作業を始めるには、「Azure PowerShell をインストールする」を参照してください。 Az PowerShell モジュールに移行する方法については、「AzureRM から Az への Azure PowerShell の移行」を参照してください。
Azure Storage アカウント。 Hive スクリプトを作成し、Azure ストレージにアップロードします。 Hive スクリプトからの出力は、このストレージ アカウントに格納されます。 このサンプルでは、この Azure ストレージ アカウントがプライマリ ストレージとして HDInsight クラスターによって使用されます。
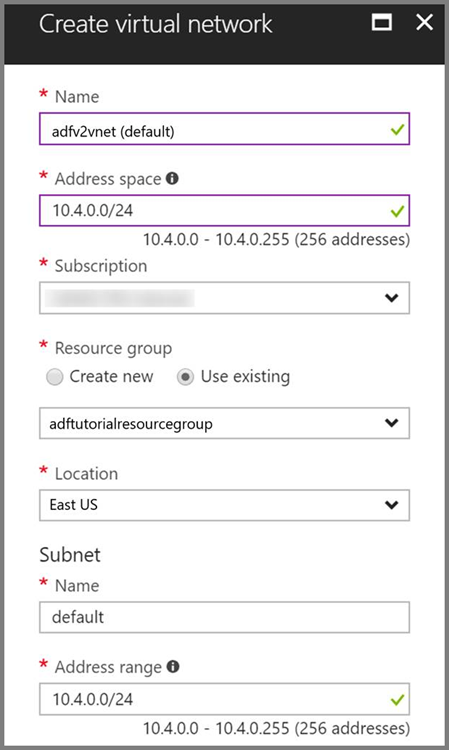
Azure Virtual Network。 Azure 仮想ネットワークを持っていない場合は、こちらの手順に従って作成してください。 このサンプルでは、HDInsight は Azure 仮想ネットワーク内にあります。 Azure Virtual Network の構成例を次に示します。
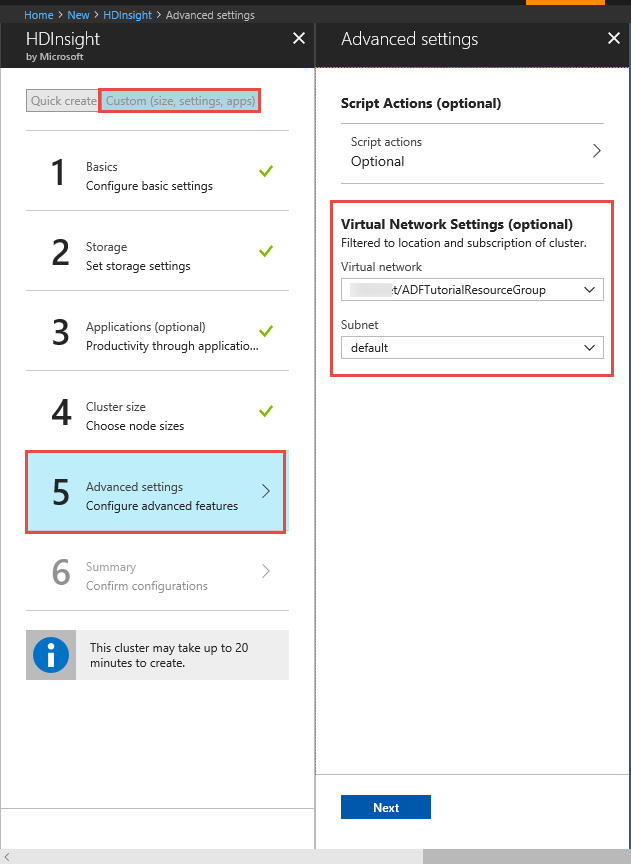
HDInsight クラスター。 HDInsight クラスターを作成し、前の手順で作成した仮想ネットワークに参加させます。手順については、「Azure Virtual Network を使用した Azure HDInsight の拡張」を参照してください。 仮想ネットワークでの HDInsight の構成例を次に示します。
Azure PowerShell。 Azure PowerShell のインストールと構成の方法に関するページに記載されている手順に従います。
仮想マシン。 Azure 仮想マシン VM を作成し、HDInsight クラスターが含まれている仮想ネットワークに参加させます。 詳細については、仮想マシンの作成方法に関するページを参照してください。
Hive スクリプトを BLOB ストレージ アカウントにアップロードする
次の内容で、hivescript.hql という名前の Hive SQL ファイルを作成します。
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableAzure BLOB ストレージで、adftutorial という名前のコンテナーを作成します (存在しない場合)。
hivescripts という名前のフォルダーを作成します。
hivescript.hql ファイルを hivescripts サブフォルダーにアップロードします。
Data Factory の作成
データ ファクトリをまだ作成していない場合は、「クイック スタート: Azure portal と Azure Data Factory Studio を使用してデータ ファクトリを作成する」の手順に従って作成してください。 作成した後、Azure portal 内のデータ ファクトリに移動します。
![[Open Azure Data Factory Studio] (Azure Data Factory Studio を開く) タイルを含む、Azure Data Factory のホーム ページのスクリーンショット。](../reusable-content/ce-skilling/azure/media/data-factory/data-factory-home-page.png)
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブでデータ統合アプリケーションを起動します。
自己ホスト型統合ランタイムを作成する
Hadoop クラスターは仮想ネットワーク内にあるため、同じ仮想ネットワークにセルフホステッド統合ランタイム (IR) をインストールする必要があります。 このセクションでは、新しい VM を作成し、それを同じ仮想ネットワークに参加させた後、セルフホステッド IR をインストールします。 セルフホステッド IR により、Data Factory サービスは、仮想ネットワーク内の HDInsight などのコンピューティング サービスに処理要求をディスパッチできます。 また、仮想ネットワーク内のデータ ストアと Azure との間でデータを移動することもできます。 セルフホステッド IR は、データ ストアまたはコンピューティングがオンプレミス環境にある場合にも使用します。
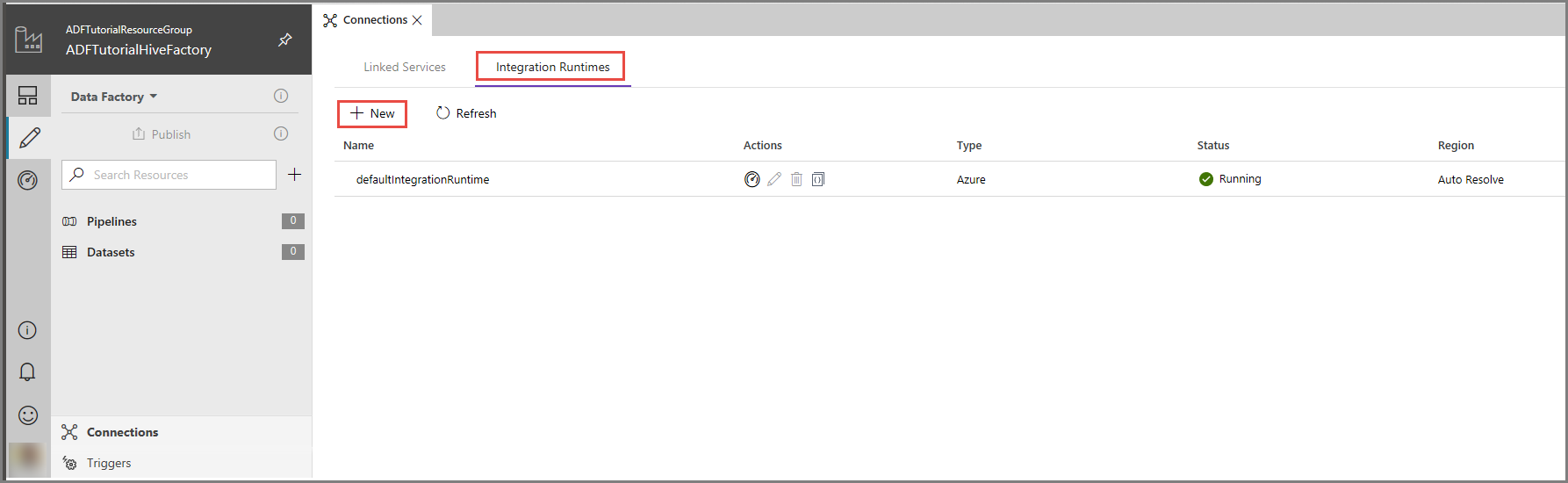
Azure Data Factory UI で、ウィンドウの下部にある [接続] をクリックします。 [Integration Runtimes](統合ランタイム) タブに切り替え、ツール バーの [+ 新規] ボタンをクリックします。
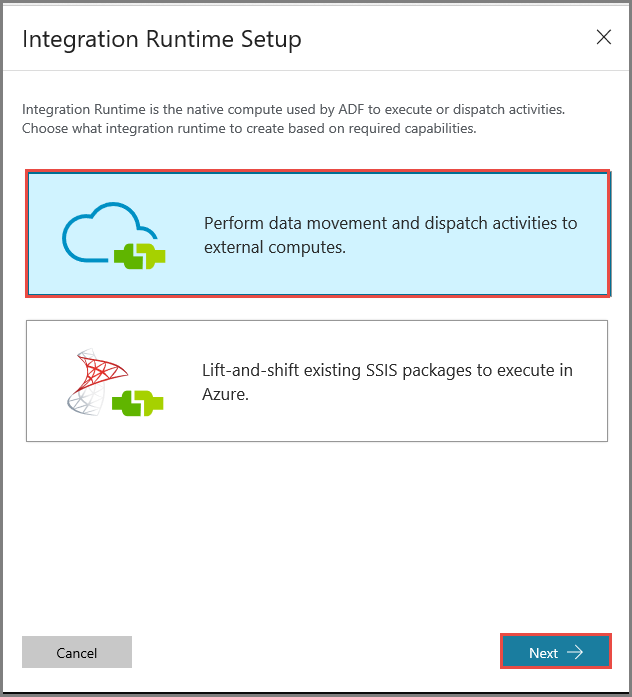
[Integration Runtime Setup](統合ランタイムの設定) ウィンドウで、 [Perform data movement and dispatch activities to external computes](データの移動を実行し、アクティビティを外部コンピューティングにディスパッチする) オプションを選択し、 [次へ] をクリックします。
[プライベート ネットワーク] を選択し、 [次へ] をクリックします。
![[プライベート ネットワーク] の選択](media/tutorial-transform-data-using-hive-in-vnet-portal/select-private-network.png)
[名前] に「MySelfHostedIR」と入力し、 [次へ] をクリックします。
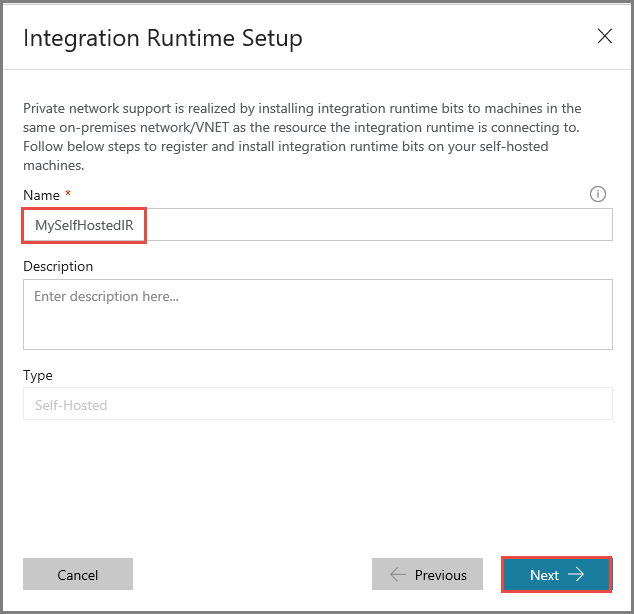
コピー ボタンをクリックして、統合ランタイムの認証キーをコピーして保存します。 ウィンドウを開いたままにしておきます。 このキーは、仮想マシンにインストールされている IR を登録するために使用します。
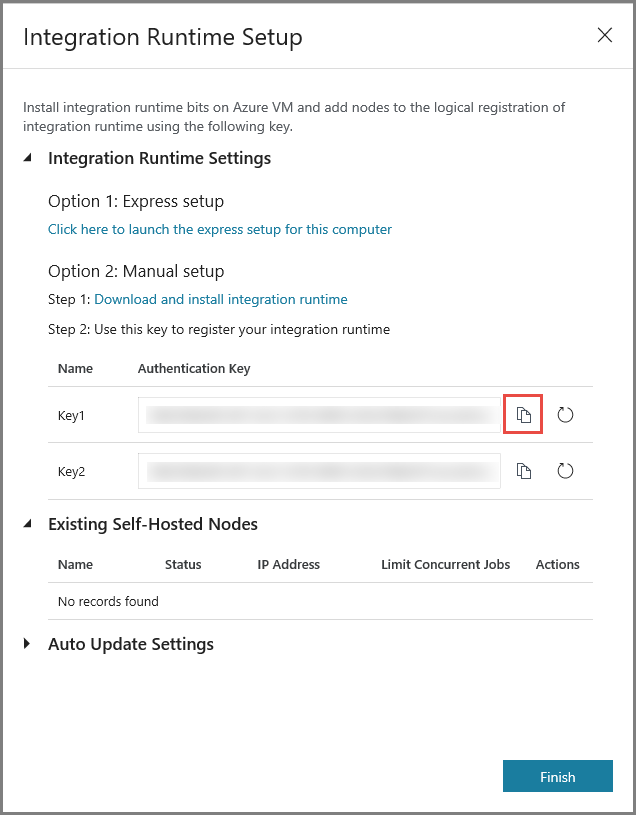
仮想マシンに IR をインストールする
Azure VM で、セルフホステッド統合ランタイムをダウンロードします。 前の手順で取得した認証キーを使用して、セルフホステッド統合ランタイムを手動で登録します。
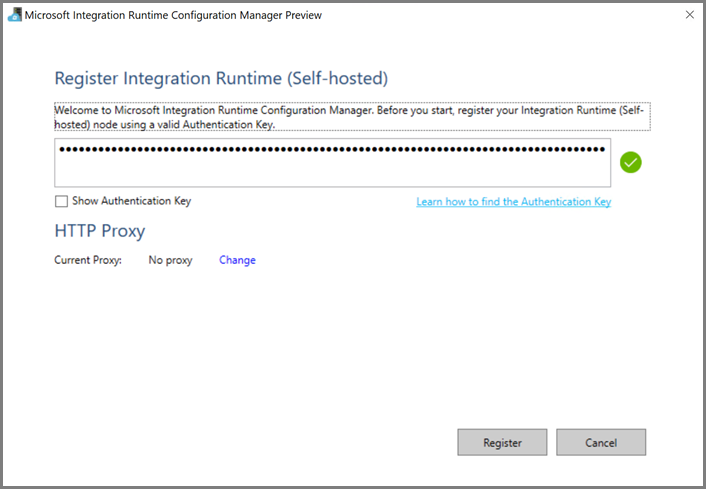
セルフホステッド統合ランタイムが正常に登録されると、次のメッセージが表示されます。
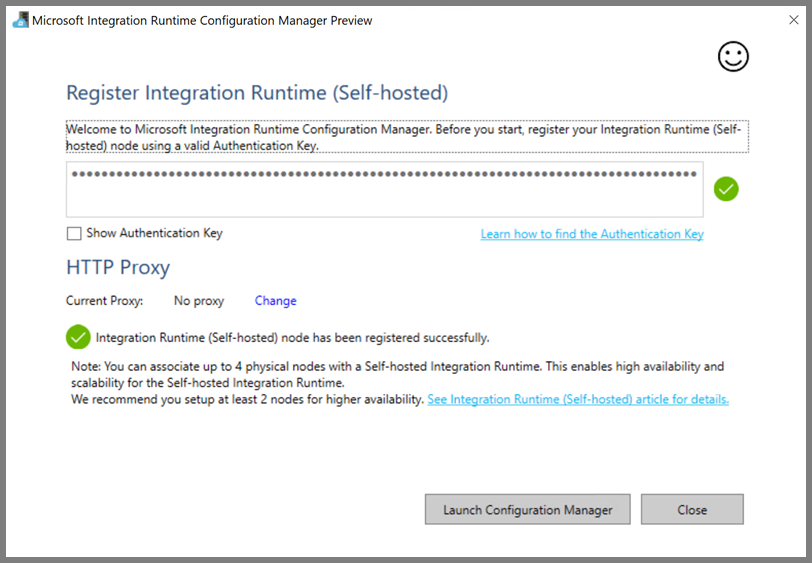
[構成マネージャーの起動] をクリックします。 ノードがクラウド サービスに接続されると、次のページが表示されます。
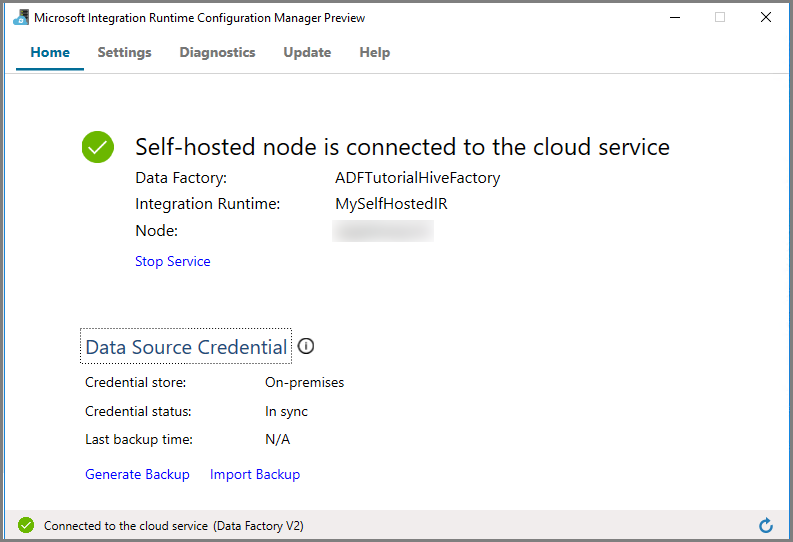
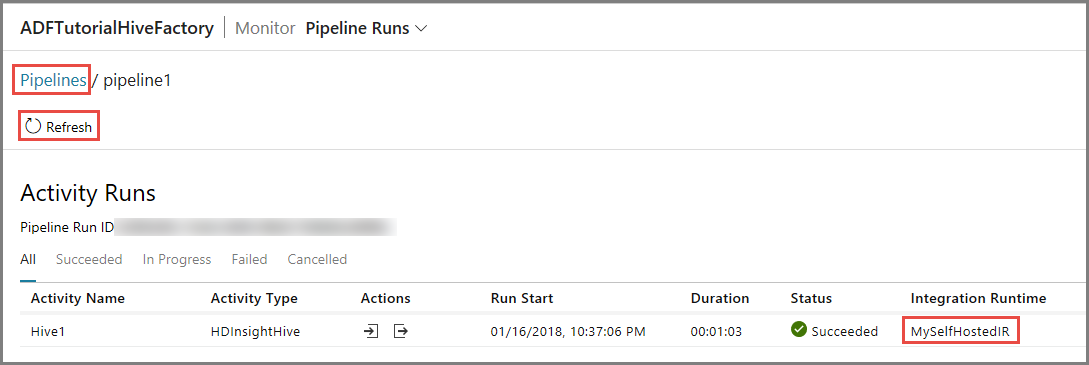
Azure Data Factory UI のセルフホステッド IR
Azure Data Factory UI に、セルフホステッド VM の名前とその状態が表示されます。
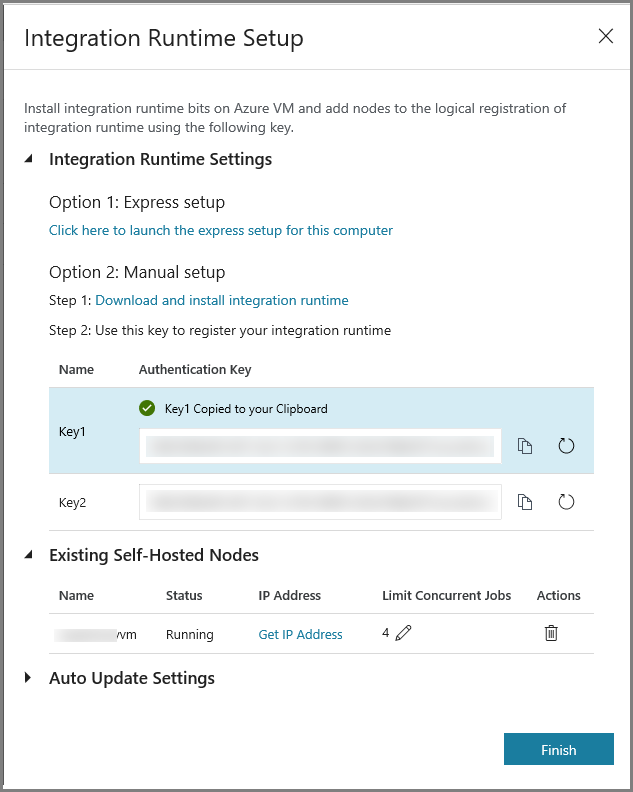
[完了] をクリックして [Integration Runtime Setup](統合ランタイムの設定) ウィンドウを閉じます。 統合ランタイムの一覧にセルフホステッド IR が表示されます。

リンクされたサービスを作成します
このセクションでは、次の 2 つのリンクされたサービスを作成してデプロイします。
- Azure Storage アカウントをデータ ファクトリにリンクする、Azure Storage のリンクされたサービス。 このストレージは、HDInsight クラスターによって使用されるプライマリ ストレージです。 この場合、この Azure Storage アカウントを使用して、Hive スクリプトとスクリプトの出力を保存します。
- HDInsight のリンクされたサービス。 Hive スクリプトは、実行のために、Azure Data Factory によってこの HDInsight クラスターに送信されます。
Azure Storage のリンクされたサービスを作成する
[リンクされたサービス] タブに切り替え、 [新規] をクリックします。
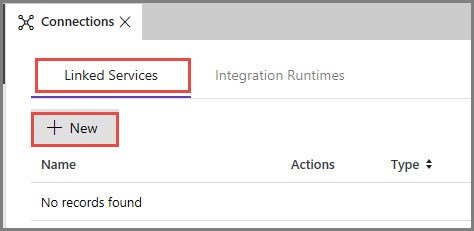
[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure Blob Storage] を選択し、 [続行] をクリックします。
![[Azure Blob Storage] の選択](media/tutorial-transform-data-using-hive-in-vnet-portal/select-azure-storage.png)
[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を行います。
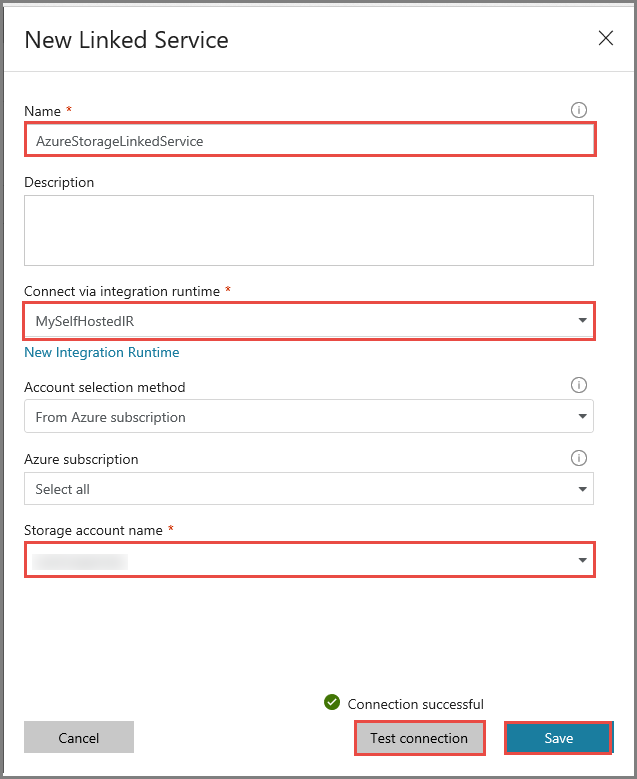
[名前] に「AzureStorageLinkedService」と入力します。
[Connect via integration runtime](統合ランタイム経由で接続) で [MySelfHostedIR] を選択します。
[ストレージ アカウント名] で、使用する Azure ストレージ アカウントを選択します。
ストレージ アカウントへの接続をテストするために、 [テスト接続] をクリックします。
[保存] をクリックします。
HDInsight のリンクされたサービスを作成する
[新規] ボタンをもう一度クリックして、別のリンクされたサービスを作成します。
[Compute] タブに切り替えます。 [Azure HDInsight] を選択し、 [続行] をクリックします。
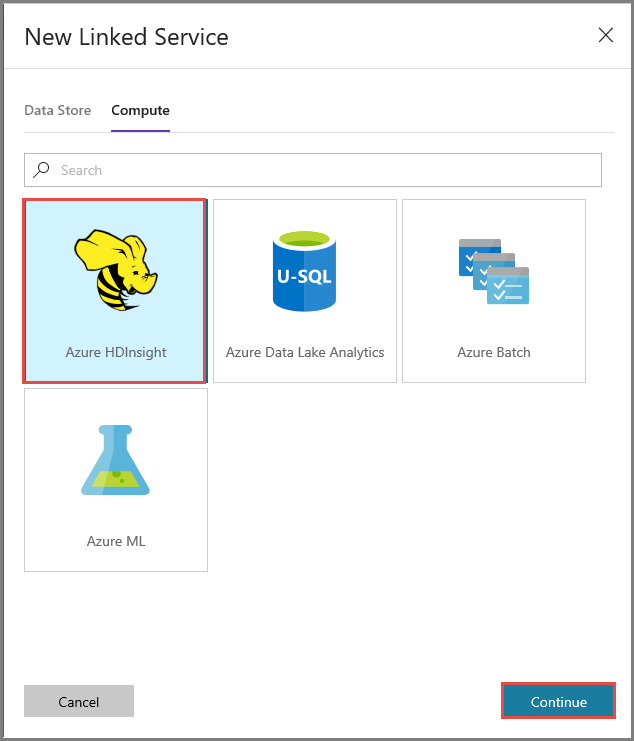
[New Linked Service](新しいリンクされたサービス) ウィンドウで、次の手順を行います。
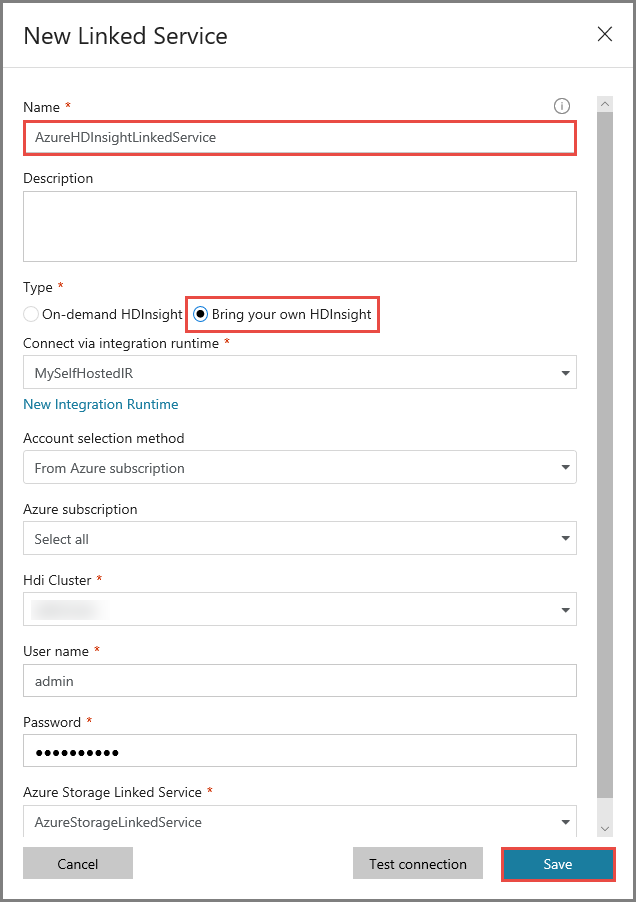
[名前] に「AzureHDInsightLinkedService」と入力します。
[Bring your own HDInsight](自分で HDInsight を用意する) を選択します。
[Hdi cluster](HDI クラスター) で、使用する HDInsight クラスターを選択します。
HDInsight クラスターのユーザー名を入力します。
ユーザーのパスワードを入力します。
この記事では、インターネット経由でクラスターにアクセスできることが前提となっています。 たとえば、https://clustername.azurehdinsight.net でクラスターに接続できることが必要です。 このアドレスではパブリック ゲートウェイが使用されていますが、ネットワーク セキュリティ グループ (NSG) またはユーザー定義ルート (UDR) を使用してインターネットからのアクセスが制限されている場合は、このゲートウェイを使用できません。 Data Factory が Azure Virtual Network の HDInsight クラスターにジョブを送信できるようにするには、HDInsight によって使用されるゲートウェイのプライベート IP アドレスに URL を解決できるように、Azure 仮想ネットワークを構成する必要があります。
Azure Portal で、HDInsight がある仮想ネットワークを開きます。 名前が
nic-gateway-0で始まるネットワーク インターフェイスを開きます。 そのプライベート IP アドレスをメモしておきます。 たとえば、10.6.0.15 です。Azure 仮想ネットワークに DNS サーバーがある場合は、HDInsight クラスターの URL
https://<clustername>.azurehdinsight.netを10.6.0.15に解決できるように、DNS レコードを更新します。 Azure 仮想ネットワークに DNS サーバーがない場合は、セルフホステッド統合ランタイム ノードとして登録されているすべての VM の hosts ファイル (C:\Windows\System32\drivers\etc) を編集し、次のようなエントリを追加することで、一時的にこれを回避することができます。10.6.0.15 myHDIClusterName.azurehdinsight.net
パイプラインを作成する
この手順では、Hive アクティビティがある新しいパイプラインを作成します。 このアクティビティでは、Hive スクリプトを実行してサンプル テーブルからデータを返し、定義されたパスに保存します。
以下の点に注意してください。
- scriptPath は、MyStorageLinkedService に使用した Azure ストレージ アカウントの Hive スクリプトへのパスを示します。 パスの大文字と小文字は区別されます。
- Output は、Hive スクリプトで使用される引数です。
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/の形式で、Azure ストレージ上の既存のフォルダーを指定します。 パスの大文字と小文字は区別されます。
Data Factory UI で、左側のウィンドウの [+] (プラス記号) をクリックし、 [パイプライン] をクリックします。
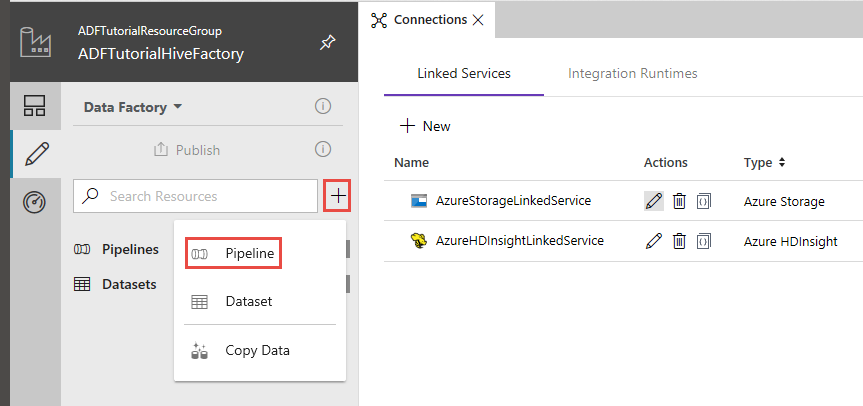
[アクティビティ] ツールボックスで [HDInsight] を展開し、パイプライン デザイナー画面に Hive アクティビティをドラッグ アンド ドロップします。
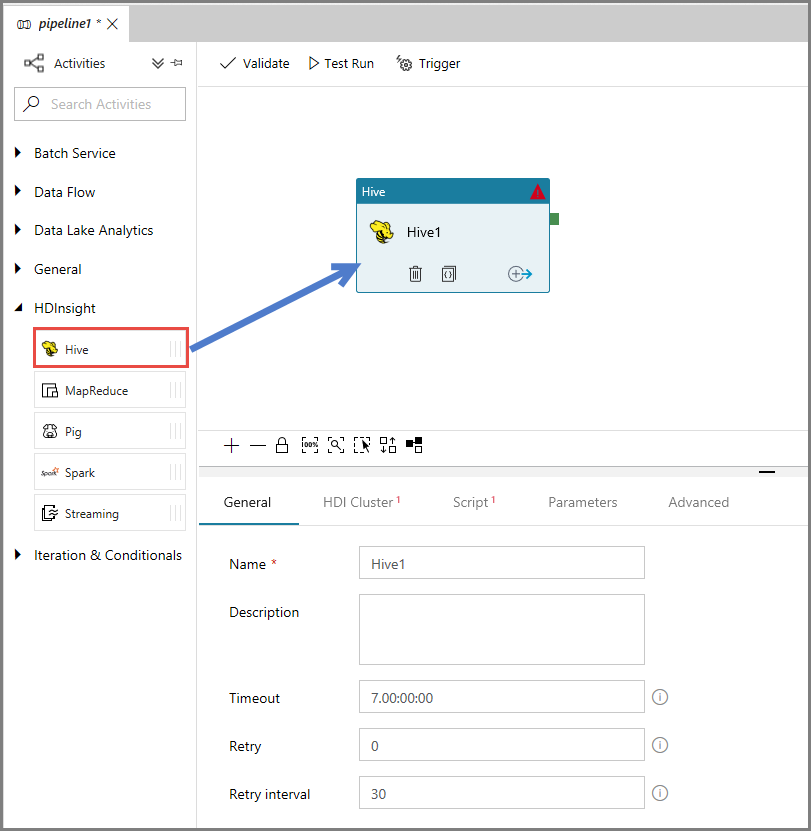
プロパティ ウィンドウで、 [HDI cluster](HDI クラスター) タブに切り替え、 [HDInsight Linked Service](HDInsight のリンクされたサービス) で [AzureHDInsightLinkedService] を選択します。

[スクリプト] タブに切り替え、次の手順を実行します。
[スクリプトにリンクされたサービス] で [AzureStorageLinkedService] を選択します。
[ファイル パス] で、 [ストレージを参照] をクリックします。
![[ストレージを参照]](media/tutorial-transform-data-using-hive-in-vnet-portal/browse-storage-hive-script.png)
[Choose a file or folder](ファイルまたはフォルダーの選択) ウィンドウで、adftutorial コンテナーの hivescripts フォルダーに移動します。hivescript.hql を選択し、 [完了] をクリックします。
![[Choose a file or folder]\(ファイルまたはフォルダーの選択\)](media/tutorial-transform-data-using-hive-in-vnet-portal/choose-file-folder.png)
[ファイル パス] に adftutorial/hivescripts/hivescript.hql が表示されていることを確認します。
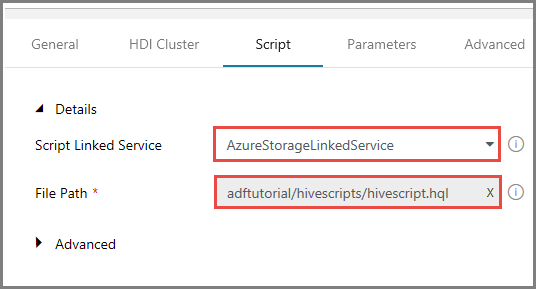
[スクリプト] タブで、 [詳細] セクションを展開します。
[パラメーター] の [Auto-fill from script](スクリプトから自動入力) をクリックします。
[出力] パラメーターの値を
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/形式で入力します。 (例:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/)。![[スクリプトの引数]](media/tutorial-transform-data-using-hive-in-vnet-portal/script-arguments.png)
アーティファクトを Data Factory に公開するために、 [発行] をクリックします。
パイプラインの実行をトリガーする
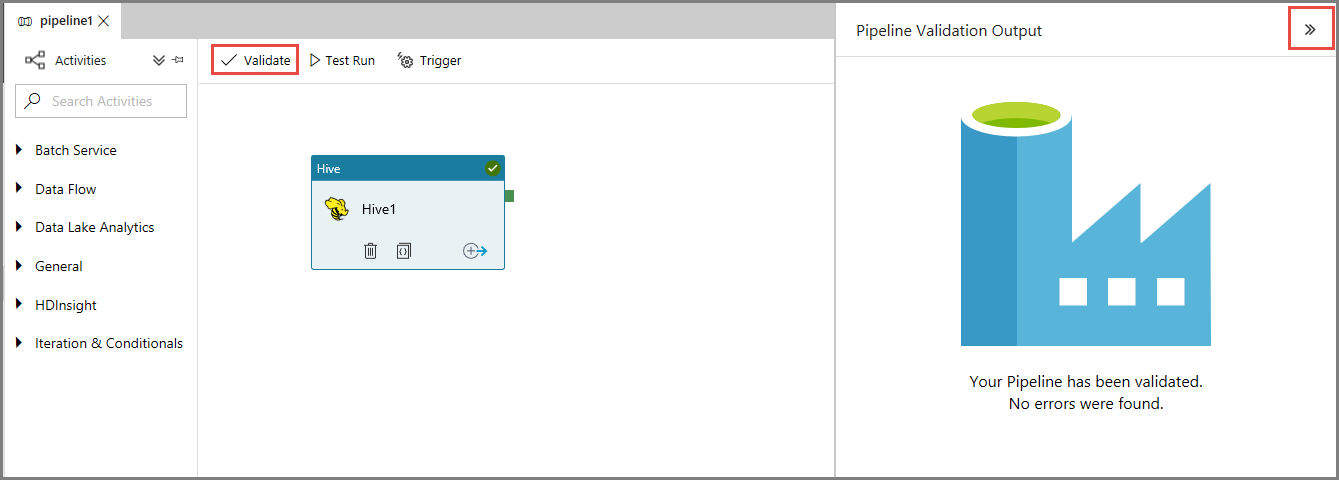
最初に、ツール バーの [検証] ボタンをクリックして、パイプラインを検証します。 右矢印 (>>) をクリックして [Pipeline Validation Output](パイプラインの検証の出力) ウィンドウを閉じます。
パイプラインの実行をトリガーするために、ツール バーの [トリガー] をクリックし、[Trigger Now](今すぐトリガー) をクリックします。
![[Trigger Now]\(今すぐトリガー\)](media/tutorial-transform-data-using-hive-in-vnet-portal/trigger-now-menu.png)
パイプラインの実行を監視します
左側で [監視] タブに切り替えます。 [Pipeline Runs](パイプラインの実行) の一覧にパイプライン実行が表示されます。
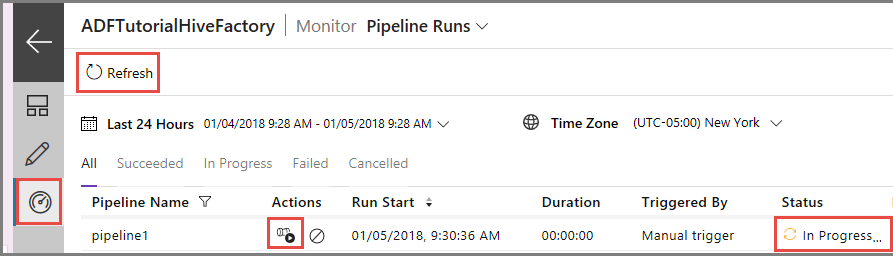
一覧を更新するには、 [最新の情報に更新] をクリックします。
パイプライン実行に関連付けられているアクティビティの実行を表示するために、 [アクション] 列の [View Activity Runs](アクティビティの実行の表示) をクリックします。 これ以外に、パイプラインを停止および再実行するためのアクション リンクがあります。
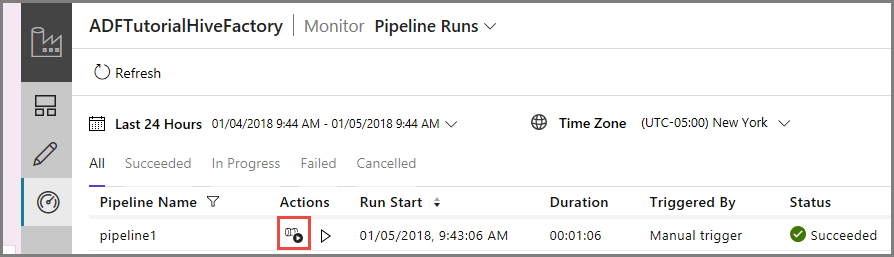
HDInsightHive タイプのパイプラインにはアクティビティが 1 つしかないため、表示されるアクティビティ実行は 1 つのみです。 前のビューに戻るために、上部の [パイプライン] リンクをクリックします。
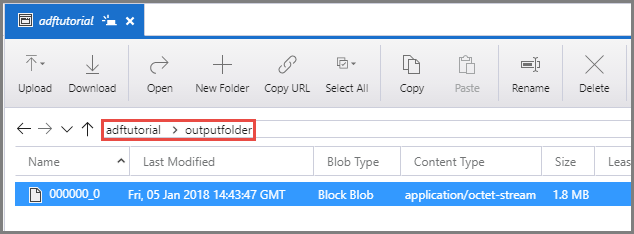
adftutorial コンテナーの outputfolder に出力ファイルがあることを確認します。
関連するコンテンツ
このチュートリアルでは、以下の手順を実行しました。
- データ ファクトリを作成します。
- 自己ホスト型統合ランタイムを作成する
- Azure Storage および Azure HDInsight のリンクされたサービスを作成する
- Hive アクティビティを含むパイプラインを作成する。
- パイプラインの実行をトリガーする。
- パイプラインの実行を監視します
- 出力を検証する
次のチュートリアルに進み、Azure 上の Spark クラスターを使ってデータを変換する方法について学習しましょう。