データ ラングリングを使用してデータを準備する
適用対象:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
データ ファクトリのデータ ラングリングを使用すると、対話型の Power Query マッシュアップを ADF でネイティブに構築し、ADF パイプライン内で大規模に実行することができます。
Power Query アクティビティを作成する
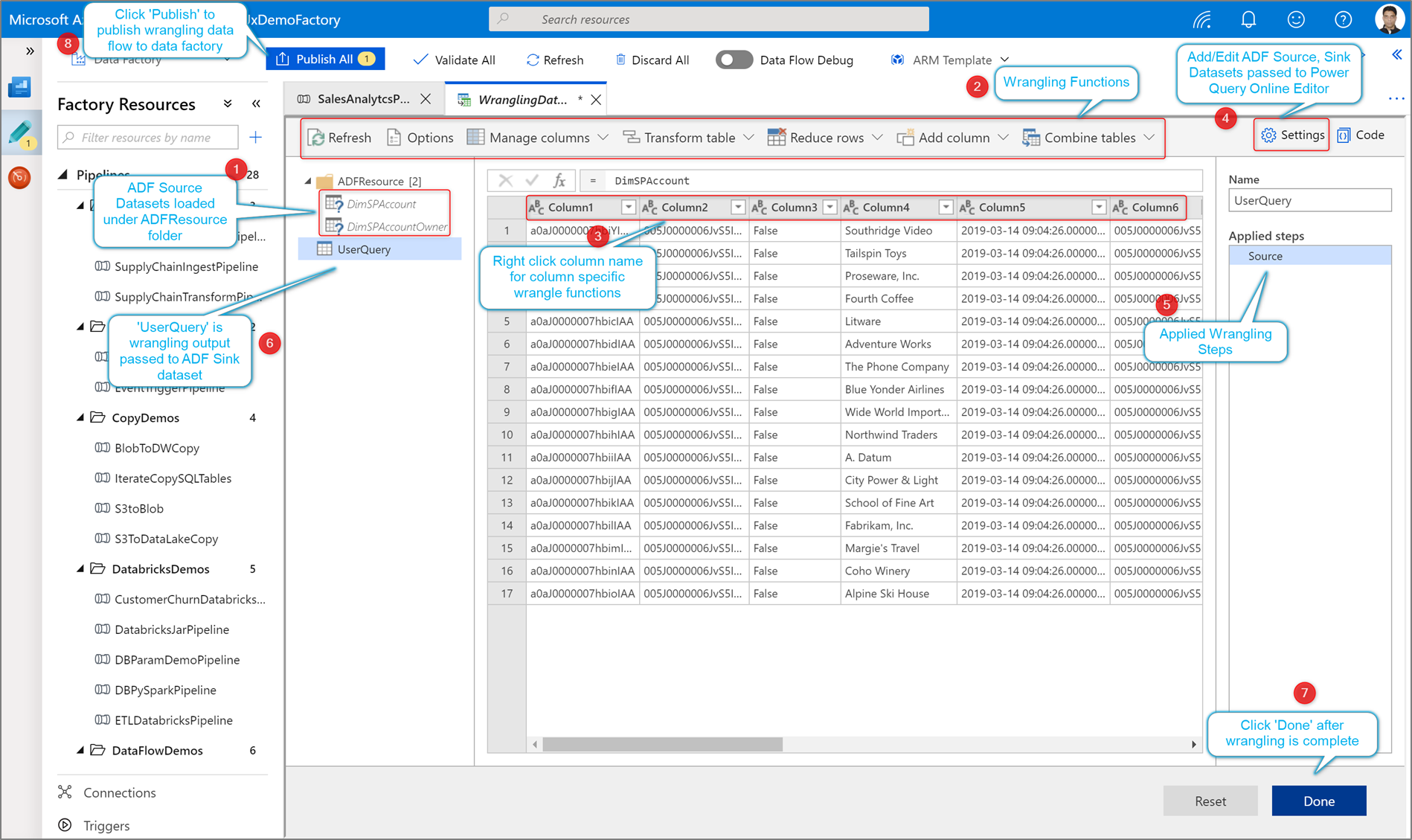
Azure Data Factory に Power Query を作成するには、2 つの方法があります。 1 つの方法は、プラス記号アイコンをクリックし、ファクトリ リソース ペインで [Power Query] を選択することです。
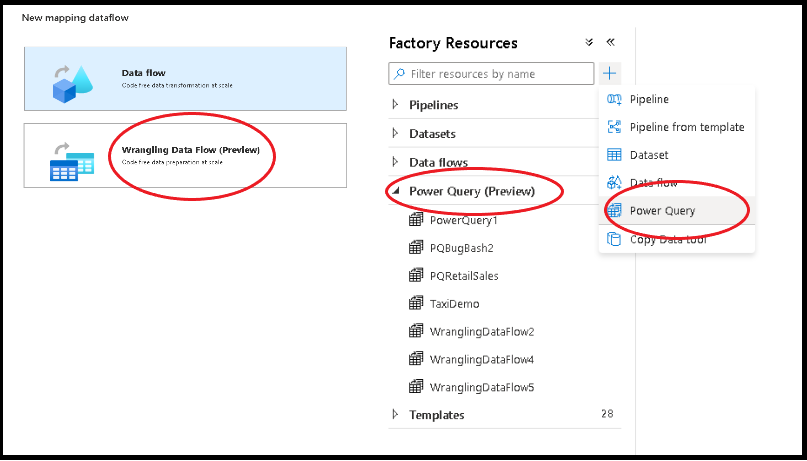
もう 1 つの方法は、パイプライン キャンバスのアクティビティ ウィンドウで行います。 Power Query アコーディオンを開き、Power Query アクティビティをキャンバスにドラッグします。
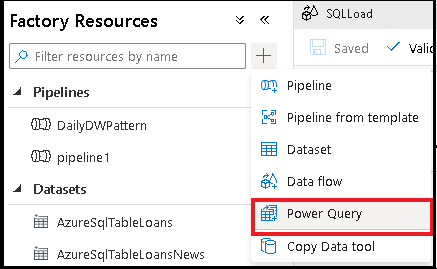
Power Query データ ラングリング アクティビティを作成する
Power Query マッシュアップのソース データセットを追加します。 既存のデータセットを選択するか、新しいデータセットを作成することができます。 マッシュアップを保存した後、パイプラインを作成し、Power Query データ ラングリング アクティビティをそのパイプラインに追加し、シンク データセットを選択して、データを格納する場所を ADF に通知できます。 1 つ以上のソース データセットを選択できますが、現時点では 1 つのシンクのみが許可されます。 シンク データセットの選択は省略可能ですが、少なくとも 1 つのソース データセットが必要です。
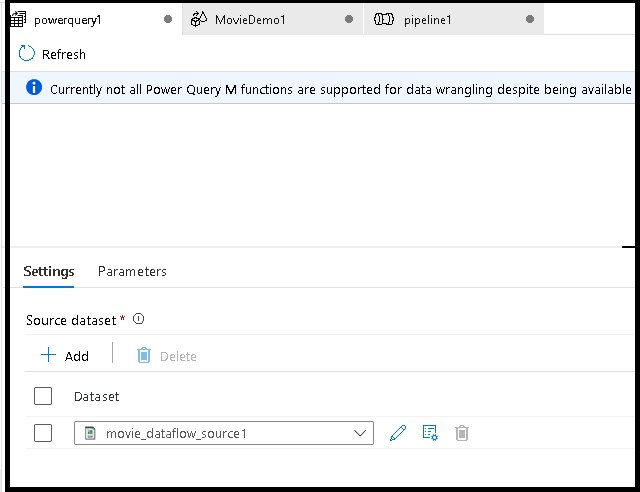
[作成] をクリックして、Power Query Online マッシュアップ エディターを開きます。
まず、マッシュアップ エディターのデータセット ソースを選択します。
Power Query の作成が完了したら、それを保存し、パイプラインを作成できます。 マッシュアップをアクティビティとしてパイプラインに追加する必要があります。 これは、シンク データセットを作成または選択してデータを格納する場合です。 また、シンク データセットの右側の 2 つ目のボタンをクリックすることで、シンク データセットのプロパティを設定できます。 1 つの出力ファイルのみ取得する場合は、必ず [最適化] の下の [partition option] (パーティション オプション) を [単一パーティション] に変更してください。
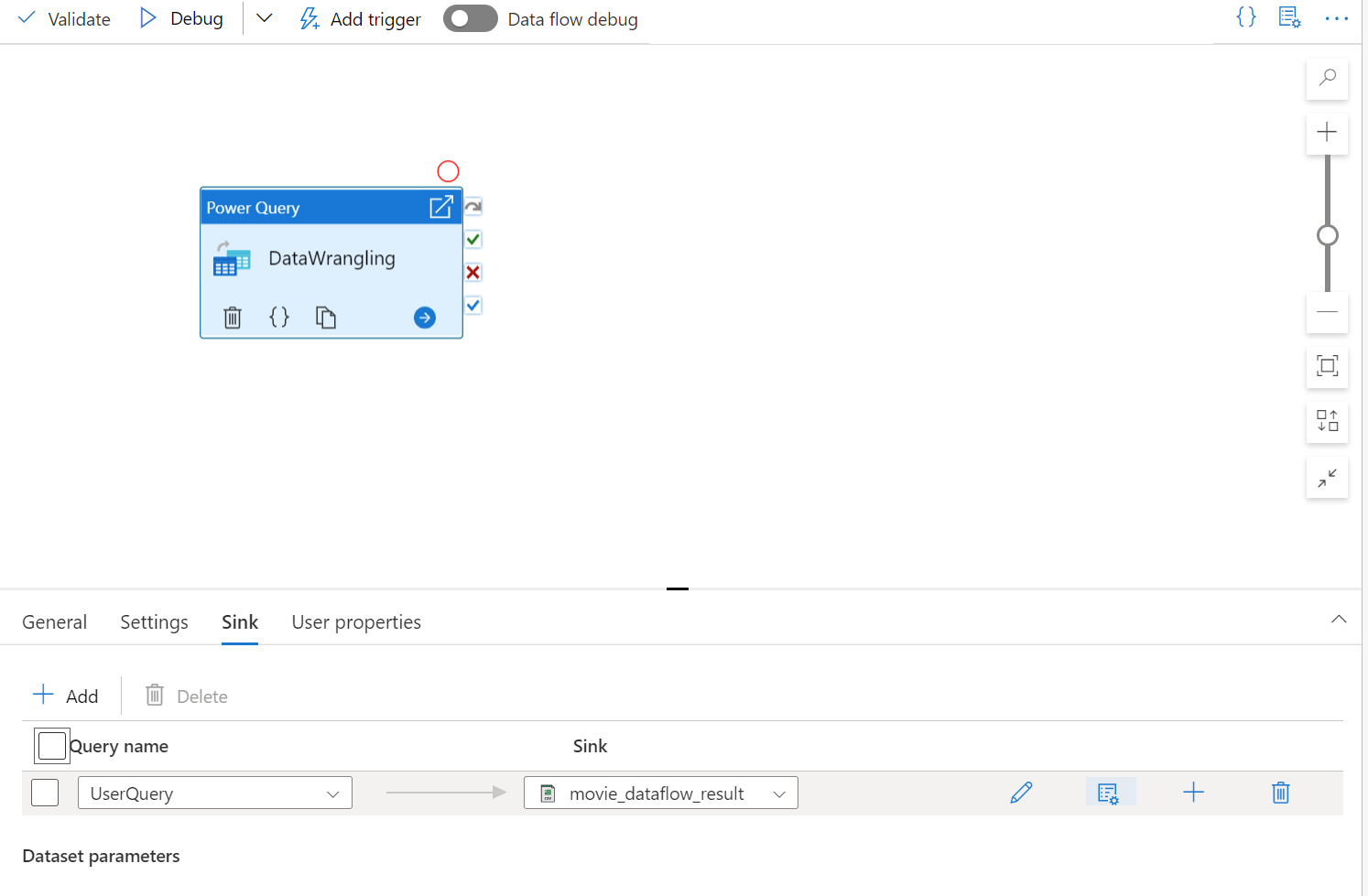
コーディング不要のデータ準備を使用して、ラングリング Power Query を作成します。 使用できる関数の一覧については、変換関数に関するページを参照してください。 ADF は、M スクリプトをデータ フロー スクリプトに変換し、Azure Data Factory データ フロー Spark 環境を使用して大規模に Power Query を実行できるようにします。
Power Query データ ラングリング アクティビティの実行と監視
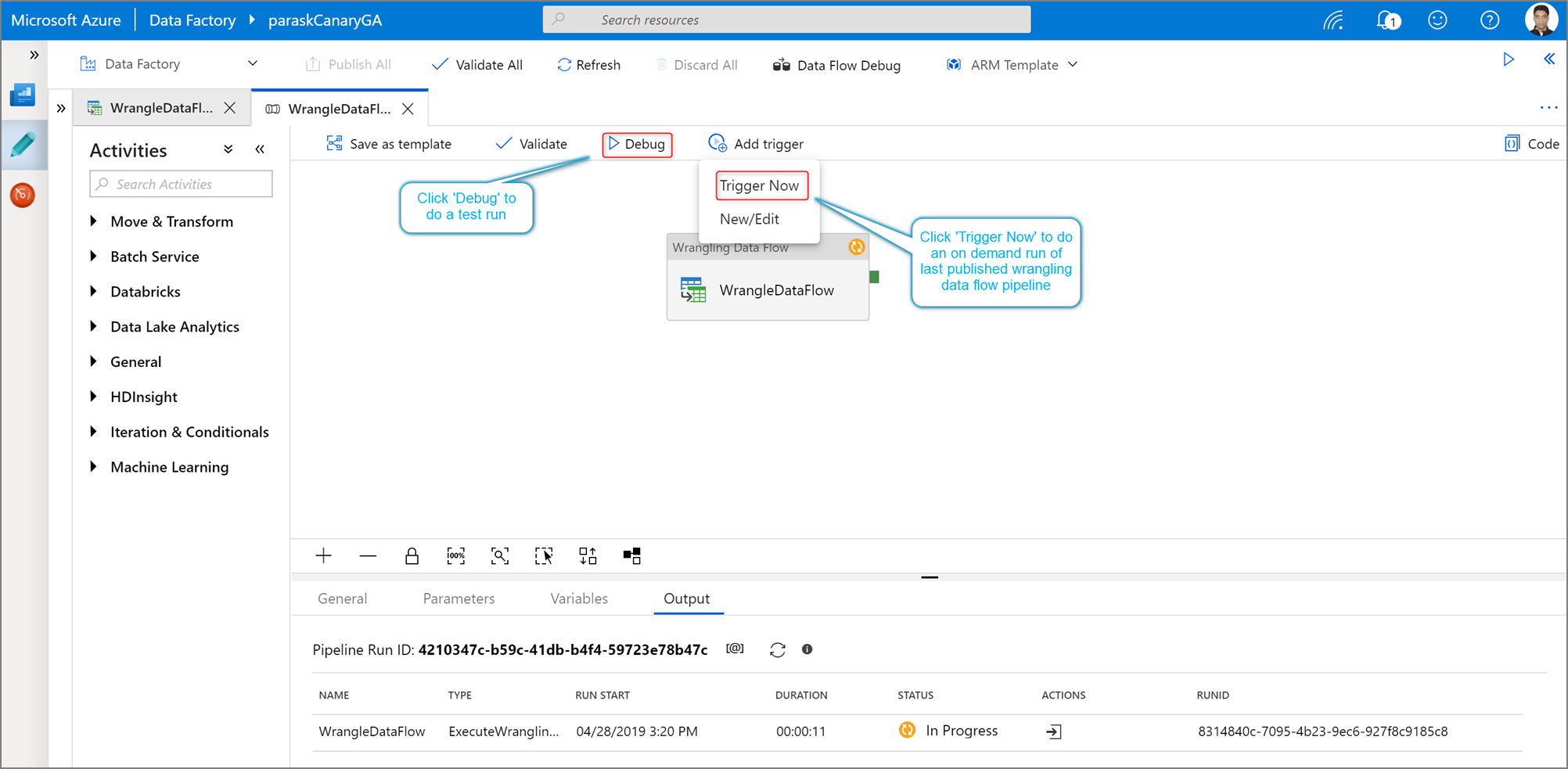
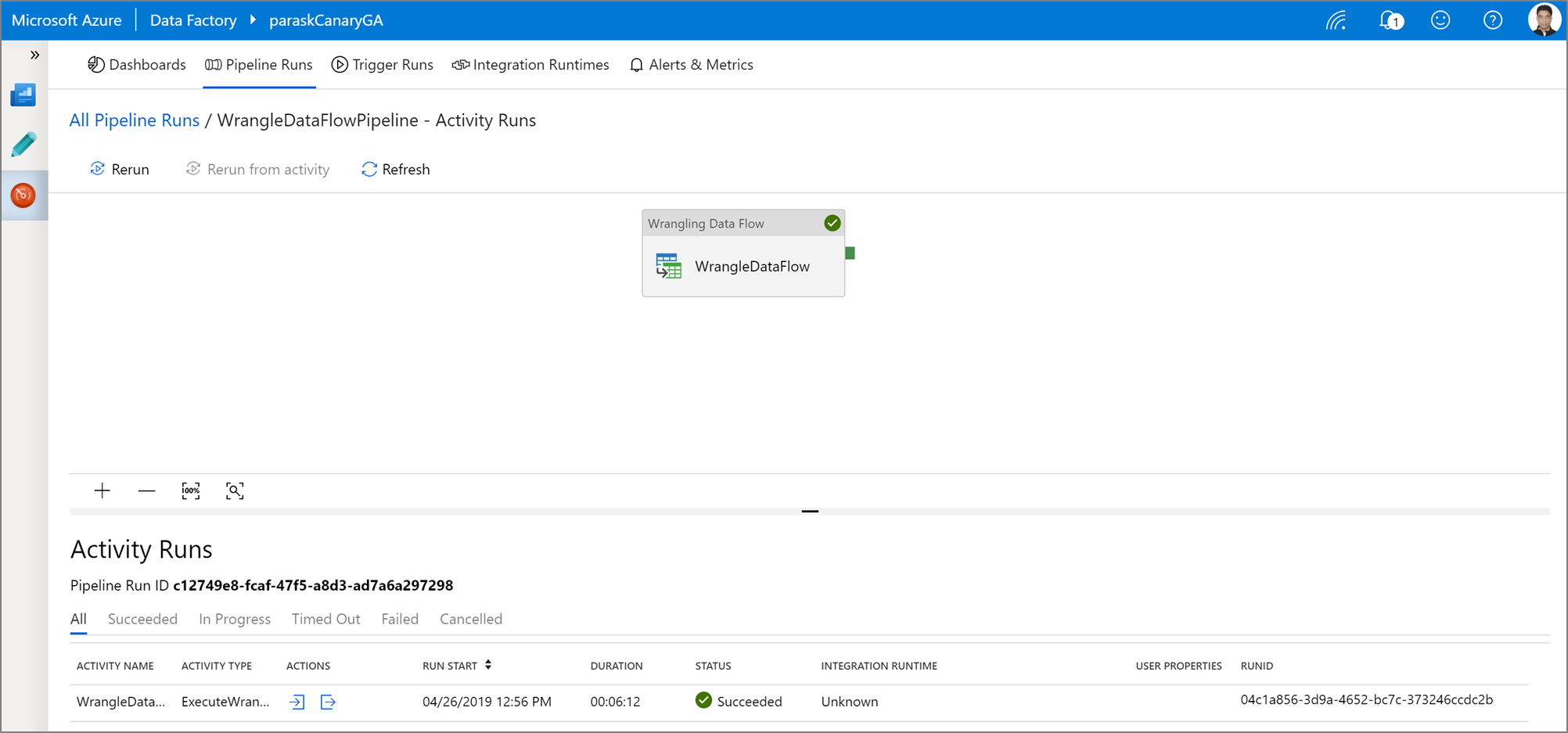
Power Query アクティビティのパイプライン デバッグ実行を実行するには、パイプラインキャンバスの [デバッグ] をクリックします。 パイプラインを発行すると、 [Trigger Now](今すぐトリガー) によって、最後に発行されたパイプラインのオンデマンド実行が実行されます。 Power Query パイプラインは、既存のすべての Azure Data Factory トリガーを使用してスケジュールできます。
[モニター] タブにアクセスして、トリガーされた Power Query アクティビティの実行の出力を視覚化します。
関連するコンテンツ
マッピング データ フローの作成方法について確認します。