ノートブックのサーバーレス コンピューティング
この記事では、ノートブックでサーバーレス コンピューティングを使用する方法について説明します。 ジョブでサーバーレス コンピューティングを使用する方法については、「ワークフローでサーバーレス コンピューティングを使用して Azure Databricks ジョブを実行する」を参照してください。
価格情報については、「Databricks の価格」を参照してください。
要件
ワークスペースは、Unity Catalog に対して有効にする必要があります。
ワークスペースはサポートされているリージョン内に存在する必要があります。 「Azure Databricks のリージョン」を参照してください。
アカウントでサーバーレス コンピューティングが有効になっている必要があります。 「サーバーレス コンピューティングを有効にする」をご覧ください。
ノートブックをサーバーレス コンピューティングにアタッチする
ワークスペースでサーバーレス対話型コンピューティングが有効になっている場合、ワークスペース内のすべてのユーザーは、ノートブックでサーバーレス コンピューティングにアクセスできます。 追加のアクセス許可は必要ありません。
サーバーレス コンピューティングにアタッチするには、ノートブックの [接続] ドロップダウン メニューをクリックし、[サーバーレス] を選択します。 新しいノートブックの場合、他のリソースが選択されていないと、アタッチされたコンピューティングは、コードの実行時に自動的に既定のサーバーレスに設定されます。
クエリの分析情報を表示する
ノートブックとジョブのサーバーレス コンピューティングでは、クエリ分析情報を使用して Spark の実行パフォーマンスを評価します。 ノートブックでセルを実行した後は、[パフォーマンスの表示] リンクをクリックして、SQL および Python クエリに関連する分析情報を表示できます。
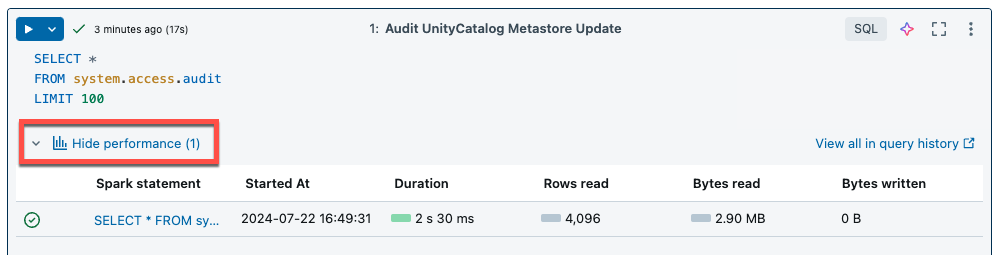
任意の Spark ステートメントをクリックして、クエリ メトリックを表示できます。 そこから、[クエリ プロファイルの表示] をクリックして、クエリ実行の視覚化を表示できます。 クエリ プロファイルの詳細については、「クエリ プロファイル」を参照してください。
Note
ジョブ実行のパフォーマンス分析情報を表示するには、「ジョブ実行クエリ分析情報の表示」を参照してください。
クエリの履歴
サーバーレス コンピューティングで実行されるすべてのクエリは、ワークスペースのクエリの履歴ページにも記録されます。 クエリの履歴の詳細については、「クエリの履歴」を参照してください。
クエリ分析情報の制限事項
- クエリ プロファイルは、クエリの実行が終了した後にのみ使用できます。
- メトリックはライブで更新されますが、実行中にクエリ プロファイルは表示されません。
- 対象となるクエリの状態は、RUNNING、CANCELED、FAILED、FINISHED のみです。
- クエリの履歴ページから実行中のクエリを取り消すことはできません。 ノートブックまたはジョブで取り消すことができます。
- 詳細メトリックは使用できません。
- クエリ プロファイルのダウンロードは使用できません。
- Spark UI へのアクセスは使用できません。
- ステートメント テキストには、実行された最後の行のみが含まれます。 ただし、この行の前に、同じステートメントの一部として実行された行が複数存在する可能性があります。