Google Cloud Storage に接続する
この記事では、Google Cloud Storage (GCS) に格納されているテーブルとデータの読み取りと書き込みを行うために、Azure Databricks からの接続を構成する方法について説明します。
GCS バケットから読み取りまたは書き込みを行うには、アタッチされたサービス アカウントを作成し、バケットをそのサービス アカウントに関連付ける必要があります。 サービス アカウント用に生成したキーを使用してバケットに直接接続します。
Google クラウド サービス アカウント キーを使用して GCS バケットに直接アクセスする
バケットの読み取りと書き込みを直接行うには、Spark の構成で定義されているキーを構成します。
手順 1: Google Cloud Console を使用して Google Cloud サービス アカウントを設定する
Azure Databricks クラスターのサービス アカウントを作成する必要があります。 Databricks では、タスクを実行するために必要な最小限の特権をこのサービス アカウントに付与することをお勧めします。
左側のナビゲーション ウィンドウで [IAM and Admin](IAM と管理) をクリックします。
[サービス アカウント] をクリックします。
[+ CREATE SERVICE ACCOUNT](サービス アカウントの作成) をクリックします。
サービス アカウント名と説明を入力します。
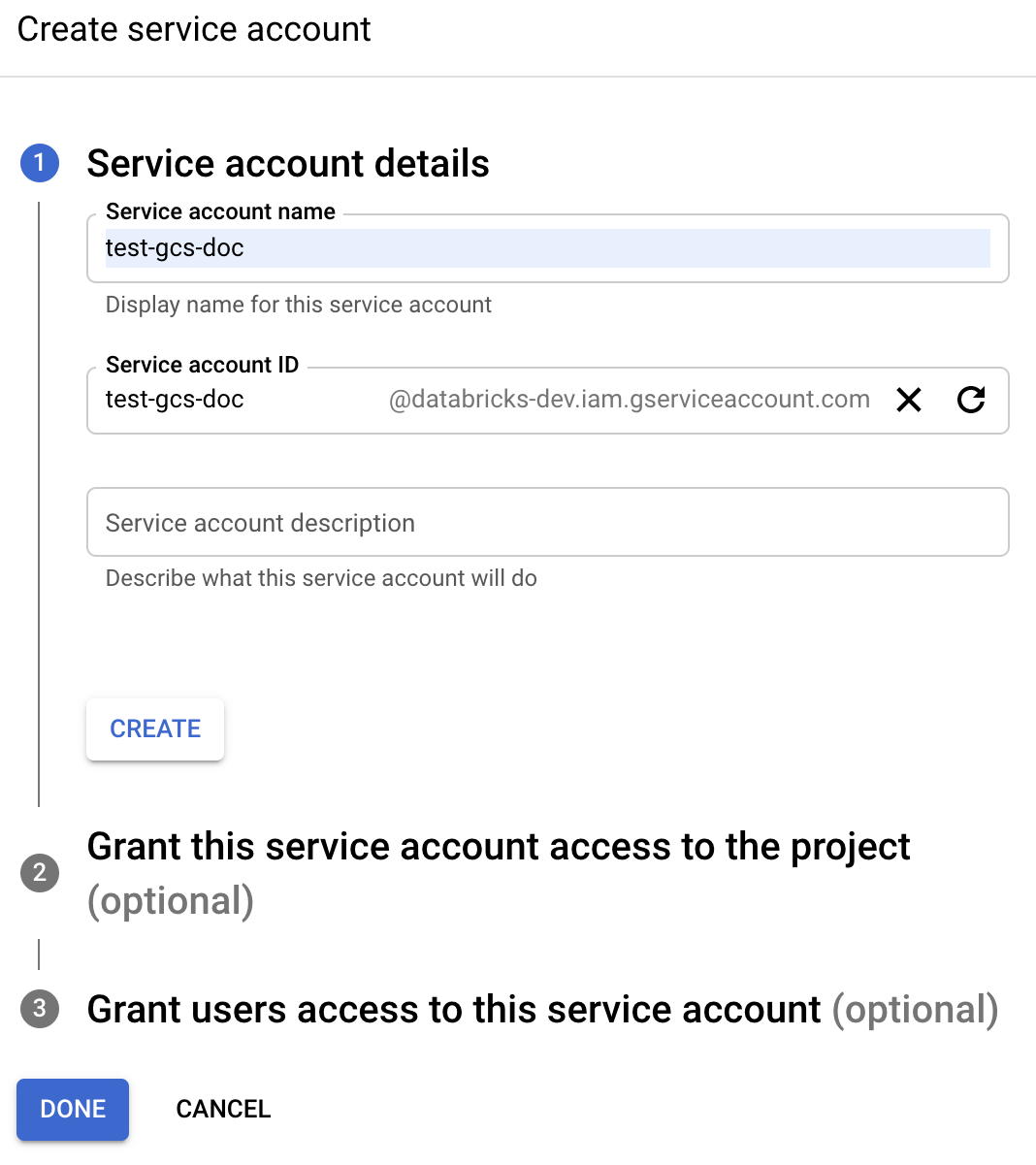
[作成] をクリックします。
[続行] をクリックします。
[完了] をクリックします。
ステップ 2: GCS バケットに直接アクセスするためのキーを作成する
警告
サービス アカウント用に生成する JSON キーは秘密キーであり、Google Cloud アカウント内のデータセットとリソースへのアクセスを制御するため、承認されたユーザーとのみ共有する必要があります。
- Google Cloud コンソールのサービス アカウントの一覧で、新しく作成したアカウントをクリックします。
- [キー] セクションで、[ADD KEY](キーの追加)>[新しいキーを作成する] をクリックします。
- JSON キーの種類をそのまま使用します。
- [作成] をクリックします。 キー ファイルがコンピューターにダウンロードされます。
ステップ 3: GCS バケットを構成する
バケットを作成する
まだバケットがない場合は、バケットを作成します。
左側のナビゲーション ウィンドウで [ストレージ] をクリックします。
[CREATE BUCKET](バケットの作成) をクリックします。
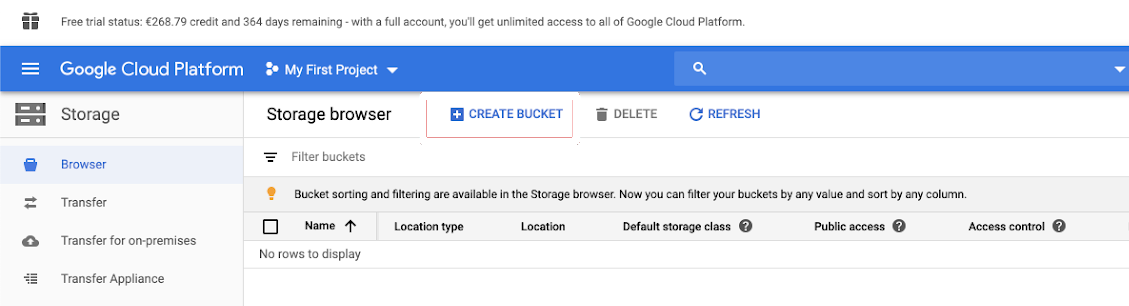
[作成] をクリックします。
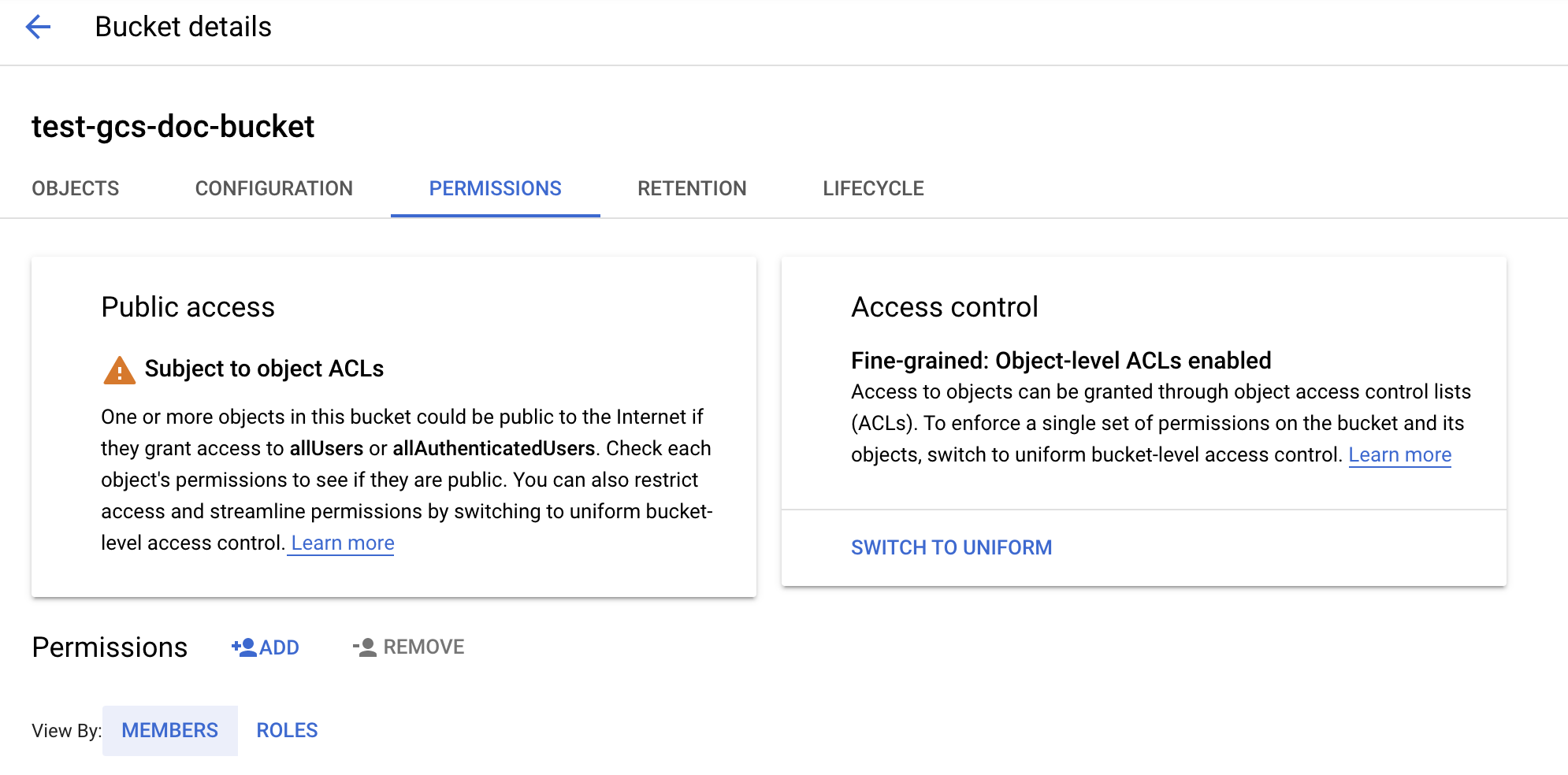
バケットを構成する
バケットの詳細を構成します。
[Permissions] タブをクリックします。
[アクセス許可] ラベルの横にある [追加] をクリックします。
Cloud Storage ロールから、バケット上のサービス アカウントにストレージ管理アクセス許可を付与します。
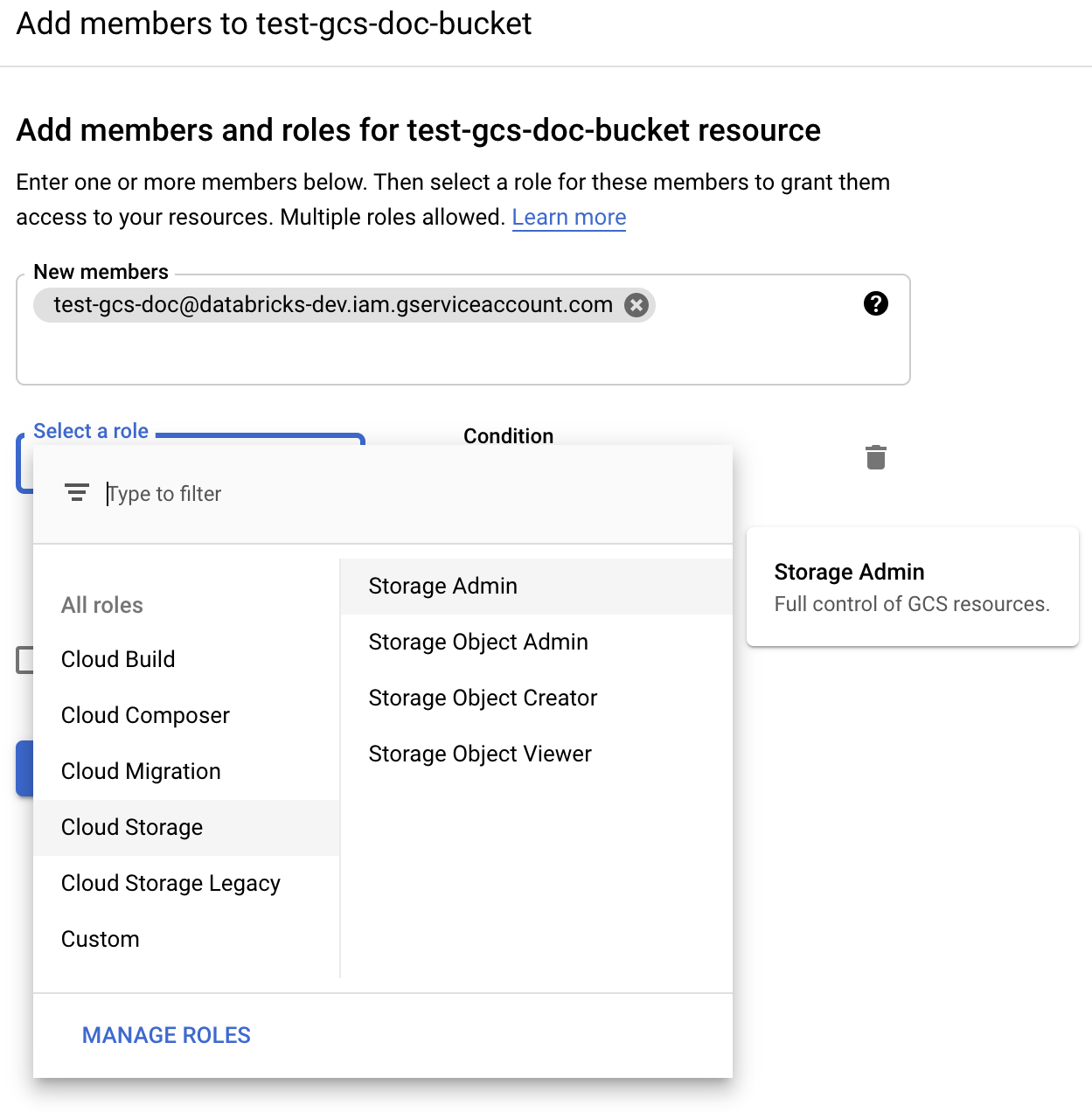
[保存] をクリックします。
ステップ 4: Databricks シークレットにサービス アカウント キーを配置する
Databricks では、すべての資格情報の格納にシークレット スコープを使うことをお勧めします。 キー JSON ファイルから Databricks シークレット スコープに秘密キーと秘密キー ID を配置できます。 ワークスペース内のユーザー、サービス プリンシパル、グループにシークレット スコープを読み取るアクセス権を付与することができます。 これにより、ユーザーが GCS にアクセスできるようにしながら、アカウント キー キーが保護されます。 シークレット スコープを作成するには、 管理シークレットを参照してください。
ステップ 5: Azure Databricks クラスターを構成する
[Spark Config] タブで、グローバル構成またはバケットごとの構成を設定します。 次の例では、Databricks シークレットとして格納されている値を使用してキーを設定します。
Note
サービス アカウントと GCS バケット内のデータへのアクセスを保護するには、クラスターのアクセス制御とノートブックのアクセス制御を使用します。 「コンピューティングのアクセス許可」と「Databricks ノートブックを使用して共同作業する」をご覧ください。
グローバル構成
指定された認証情報を使用してすべてのバケットにアクセスする必要がある場合は、この構成を使用します。
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
<client-email>、<project-id> を、キー JSON ファイルの正確なフィールド名の値に置き換えます。
バケットごとの構成
特定のバケットの認証情報を構成する必要がある場合は、この構成を使用します。 バケットごとの構成の構文では、次の例のように、各構成の末尾にバケット名が追加されます。
重要
グローバルな設定に加え、バケットごとの構成も使用できます。 バケットごとの構成を指定すると、グローバル構成よりも優先されます。
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
<client-email>、<project-id> を、キー JSON ファイルの正確なフィールド名の値に置き換えます。
ステップ 6: GCS から読み取る
GCS バケットから読み取る場合は、次の例のように、サポートされている任意の形式で Spark の読み取りコマンドを使用します。
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
GCS バケットに書き込む場合は、次の例のように、サポートされている任意の形式で Spark の書き込みコマンドを使用します。
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
<bucket-name> は、「ステップ 3: GCS バケットを構成する」で作成したバケットの名前に置き換えます。