Unity Catalog を使用したデータ系列のキャプチャと表示
この記事では、カタログ エクスプローラー、データ系列システム テーブル、および REST API を使用して、データ系列をキャプチャして視覚化する方法について説明します。
Unity Catalog を使用すると、Azure Databricks に対して実行されたクエリを対象にランタイム データ系列をキャプチャできます。 系列はすべての言語でサポートされ、列レベルまでキャプチャされます。 系列データには、クエリに関連するノートブック、ジョブ、ダッシュボードが含まれます。 系列は、カタログ エクスプローラーでほぼリアルタイムで視覚化でき、系列システム テーブルと Databricks REST API を使用してプログラムで取得できます。
系列は、Unity Catalog メタストアにアタッチされているすべてのワークスペースにわたって集約されます。 つまり、あるワークスペースでキャプチャされた系列は、そのメタストアを共有する他のすべてのワークスペースに表示されます。 系列データを表示するためには、適切なアクセス許可がユーザーに付与されている必要があります。 系列データは 1 年間保持されます。
次の図は、系列グラフのサンプルです。 具体的なデータ系列の機能と例については、この記事の後半で説明します。
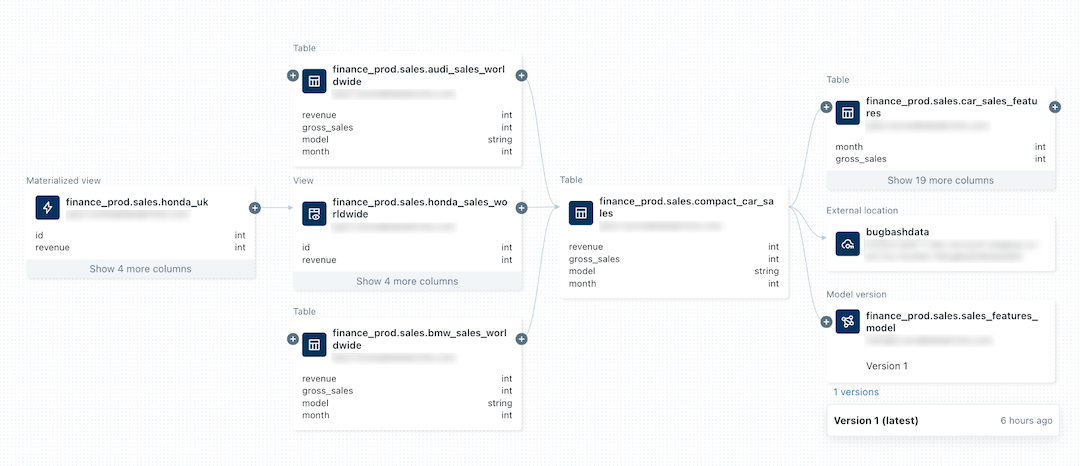
機械学習モデルの系列の追跡については、「Unity Catalog でモデルのデータ系列を追跡する」を参照してください。
要件
Unity Catalog を使ってデータ系列を取得するための要件は次のとおりです。
ワークスペースで Unity カタログが有効になっている必要があります。
テーブルは Unity Catalog メタストアに登録する必要があります。
クエリでは、Spark DataFrame (DataFrame を返す Spark SQL 関数など) または Databricks SQL インターフェイスを使用する必要があります。 Databricks SQL クエリと PySpark クエリの例については、「例」を参照してください。
テーブルまたはビューの系列を表示するには、少なくとも、そのテーブルまたはビューの親カタログに対する
BROWSE権限がユーザーに付与されている必要があります。 親カタログにもワークスペースからアクセスできる必要があります。 「特定のワークスペースにカタログ アクセスを制限する」を参照してください。ノートブック、ジョブ、またはダッシュボードの系列情報を表示するには、ワークスペースのアクセス制御設定で定義されているこれらのオブジェクトに対するアクセス許可がユーザーに付与されている必要があります。 「系列のアクセス許可」を参照してください。
Unity カタログ対応パイプラインの系列を表示するには、パイプラインに対する
CAN_VIEWアクセス許可が必要です。Delta テーブル間のストリーミングの系列追跡には、Databricks Runtime 11.3 LTS 以降が必要です。
Delta Live Tables ワークロードの列系列の追跡には、Databricks Runtime 13.3 LTS 以降が必要です。
Azure Databricks コントロール プレーンの Event Hubs エンドポイントへの接続を許可するために、送信ファイアウォール規則の更新が必要になる場合があります。 通常、これは、Azure Databricks ワークスペースが独自の VNet (VNet インジェクションとも呼ばれます) にデプロイされている場合に適用されます。 ワークスペース リージョンの Event Hubs エンドポイントを取得するには、「メタストア、成果物 BLOB ストレージ、システム テーブル ストレージ、ログ BLOB ストレージ、Event Hubs エンドポイントの IP アドレス」を参照してください。 Azure Databricks のユーザー定義ルート (UDR) の設定については、「Azure Databricks のユーザー定義ルート設定」を参照してください。
例
注意
以下の例では、
lineage_dataというカタログ名とlineagedemoというスキーマ名を使用しています。 異なるカタログとスキーマを使用する場合は、例の中で用いられている名前を変更してください。この例をすべて実行するには、スキーマに対する
CREATE権限とUSE SCHEMA権限が必要です。 これらの特権は、メタストア管理者、カタログ所有者、スキーマ所有者が付与できます。 たとえば、グループ 'data_engineers' のすべてのユーザーに、lineage_dataカタログ内のlineagedemoスキーマにテーブルを作成する権限を付与するには、上記のいずれかの権限またはロールを持つユーザーが次のクエリを実行できます。CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
系列をキャプチャして探索する
系列データをキャプチャするには:
Azure Databricks のランディング ページに移動し、サイド バーの
 [新規] をクリックし、メニューから [ノートブック] を選択します。
[新規] をクリックし、メニューから [ノートブック] を選択します。ノートブックの名前を入力し、[既定の言語] で [SQL] を選択します。
[クラスター] で、Unity Catalog にアクセスできるクラスターを選択します。
Create をクリックしてください。
1 つ目のノートブック セルに、次のクエリを入力します。
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuクエリを実行するには、セル内をクリックして Shift + Enter キーを押すか、
 をクリックして [セルの実行] を選択します。
をクリックして [セルの実行] を選択します。
これらのクエリによって生成された系列をカタログ エクスプローラーを使用して表示するには、次の手順に従います:
Azure Databricks ワークスペースの上部バーの [検索] ボックスで、
lineage_data.lineagedemo.dinnerテーブルを検索して選択します。[データ系列] タブを選択します。系列パネルが表示され、関連テーブルが表示されます (この例では
menuテーブルです)。データ系列のインタラクティブ グラフを表示するには、[See Lineage Graph] (系列グラフの表示) をクリックします。 既定では、1 つのレベルがグラフに表示されます。 ノードの
 アイコンをクリックすると、使用可能な接続があれば、さらに表示されます。
アイコンをクリックすると、使用可能な接続があれば、さらに表示されます。系列グラフ内の各ノードを接続する矢印をクリックして、[系列接続] パネルを開きます。 [系列接続] パネルには、その接続に関する詳細情報 (接続元と接続先のテーブル、ノートブック、ジョブなど) が表示されます。
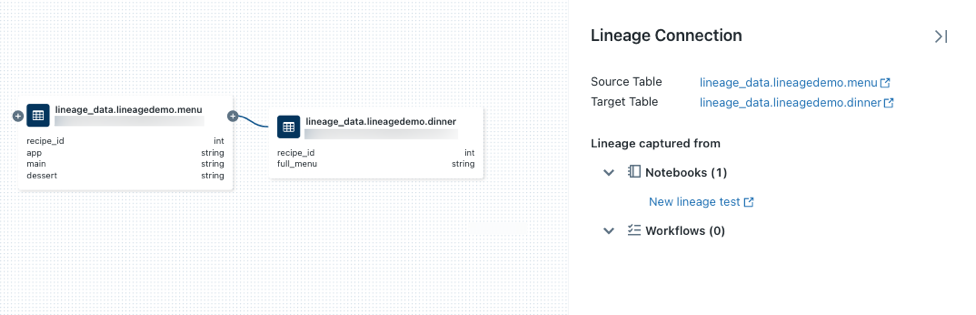
dinnerテーブルに関連付けられているノートブックを表示するには、[Lineage connection] (系列接続) パネルでノートブックを選択するか、系列グラフを閉じて [Notebooks] (ノートブック) をクリックします。 新しいタブでノートブックを開くには、ノートブック名をクリックします。列レベルの系列を表示するには、グラフ内の列をクリックして、関連する列へのリンクを表示します。 たとえば、"full_menu" 列をクリックすると、列の派生元のアップストリームの列が表示されます。
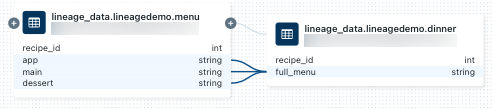
Python など、別の言語を使用して系列を表示するには:
先ほど作成したノートブックを開き、新しいセルを作成して、次の Python コードを入力します。
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")セル内をクリックして Shift + Enter キーを押すか、
をクリックし [セルの実行] を選択して、セルを実行します。Azure Databricks ワークスペースの上部バーの [検索] ボックスで、
lineage_data.lineagedemo.priceテーブルを検索して選択します。[系列] タブを選択し、[系列グラフの表示] を選択します。
アイコンをクリックすると、クエリで生成されたデータ系列を調べることができます。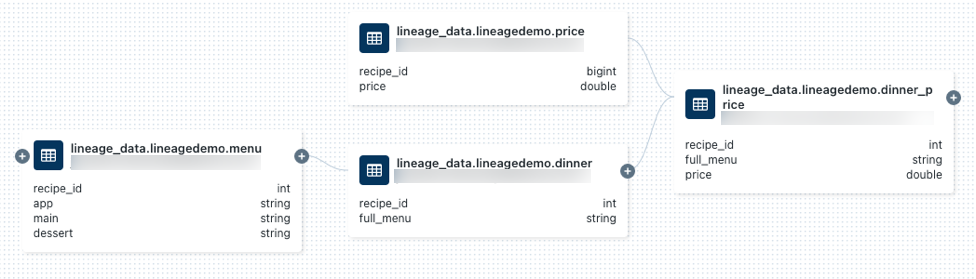
系列グラフ内の各ノードを接続する矢印をクリックして、[系列接続] パネルを開きます。 [系列接続] パネルには、その接続に関する詳細情報 (接続元と接続先のテーブル、ノートブック、ジョブなど) が表示されます。
ワークフロー系列をキャプチャして表示する
系列は、Unity Catalog に対して読み取りまたは書き込みを行うワークフローに対してもキャプチャされます。 Azure Databricks ワークフローの系列を表示するには:
サイド バーの
[新規] をクリックし、メニューから [ノートブック] を選択します。ノートブックの名前を入力し、[既定の言語] で [SQL] を選択します。
Create をクリックしてください。
1 つ目のノートブック セルに、次のクエリを入力します。
SELECT * FROM lineage_data.lineagedemo.menu上部のバーの [スケジュール] をクリックします。 スケジュール ダイアログで、[手動] を選択し、Unity Catalog にアクセスできるクラスターを選択して、[作成] をクリックします。
[今すぐ実行] をクリックします。
Azure Databricks ワークスペースの上部バーの [検索] ボックスで、
lineage_data.lineagedemo.menuテーブルを検索して選択します。[系列] タブで、[ワークフロー] をクリックし、[ダウンストリーム] タブを選択します。ジョブ名は、
menuテーブルのコンシューマーとして [ジョブ名] の下に表示されます。
ダッシュボードの系列をキャプチャして表示する
ダッシュボードを作成し、そのデータ系列を表示するには:
Azure Databricks のランディング ページに移動し、サイドバーの [カタログ] をクリックして Catalog Explorer を開いてください。
カタログ名をクリックし、[lineagedemo] をクリックして、
menuテーブルを選択します。 上部のバーの [検索] ボックスを使用してmenuテーブルを検索することもできます。[ダッシュボードで開く] をクリックします。
ダッシュボードに追加する列を選択し、[作成] をクリックします。
ダッシュボードを公開します。
公開済みのダッシュボードのみがデータ系列で追跡されます。
上部バーの [検索] ボックスで、
lineage_data.lineagedemo.menuテーブルを検索して選択します。[系列] タブで、[ダッシュボード] をクリックします。 ダッシュボードが、メニュー テーブルのコンシューマーとして [ダッシュボード名] に表示されます。
系列のアクセス許可
系列グラフは、Unity Catalog と同じ アクセス許可モデル を共有します。 テーブルに対する BROWSE または SELECT 権限を持っていないユーザーが系列を調べることはできません。 また、ユーザーが見ることができるのは、そのユーザーに表示のアクセス許可が付与されているノートブック、ジョブ、ダッシュボードのみです。 たとえば、非管理者ユーザー userA に対して次のコマンドを実行したとします。
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
userA が lineage_data.lineagedemo.menu テーブルの系列グラフを表示すると、menu テーブルが表示されます。 ダウンストリーム lineage_data.lineagedemo.dinner テーブルなど、関連付けられているテーブルに関する情報を表示することはできません。 userA に対する表示では、dinner テーブルが masked ノードとして表示されます。userA がグラフを展開して、自分に権限がないテーブルのダウンストリーム テーブルを表示することはできません。
次のコマンドを実行して、管理者以外のユーザー userB に BROWSE アクセス許可を付与する場合:
GRANT BROWSE on lineage_data to `userA@company.com`;
userB は、lineage_data スキーマ内の任意のテーブルの系列グラフを表示できるようになりました。
Unity Catalog でセキュリティ保護可能なオブジェクトへのアクセスを管理する方法の詳細については、「Unity Catalog の特権の管理」を参照してください。 ノートブック、ジョブ、ダッシュボードなどのワークスペース オブジェクトへのアクセスの管理の詳細については、「アクセス制御リスト」を参照してください。
系列データを削除する
警告
次の手順では、Unity Catalog に格納されているオブジェクトがすべて削除されます。 必要な場合にのみ実行するようにしてください。 たとえば、コンプライアンス要件を満たすために実行します。
系列データを削除するには、Unity Catalog オブジェクトを管理しているメタストアを削除する必要があります。 メタストアの削除の詳細については、「メタストアを削除する」を参照してください。 データは 90 日以内に削除されます。
システム テーブルを使用して系列データに対するクエリを実行する
系列システム テーブルを使用して、プログラムで系列データのクエリを実行できます。 詳細な手順については、「システム テーブルで使用状況を監視する」と「系列システム テーブル参照」を参照してください。
ワークスペースが系列システム テーブルをサポートしていないリージョンにある場合は、代わりに Data Lineage REST API を使用して、系列データをプログラムで取得できます。
Data Lineage REST API を使用して系列を取得する
データ系列 API を使用すると、テーブルと列の系列を取得できます。 ただし、ワークスペースが系列システム テーブルをサポートするリージョンにある場合は、REST API ではなくシステム テーブル クエリを使用する必要があります。 システム テーブルは、系列データをプログラムで取得するためのより優れたオプションです。 ほとんどのリージョンでは、系列システム テーブルがサポートされています。
重要
Databricks REST API にアクセスするには、認証する必要があります。
テーブルの系列を取得する
この例では、dinner テーブルの系列データを取得します。
要求
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
<workspace-instance> を置き換えます。
この例では、.netrc ファイルを使用します。
Response
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
列の系列を取得する
この例では、dinner テーブルの列データを取得します。
要求
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
<workspace-instance> を置き換えます。
この例では、.netrc ファイルを使用します。
回答
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
制限事項
- 系列は 1 年間のローリング ウィンドウで計算されるため、1 年よりも前に収集された系列は表示されません。 たとえば、ジョブまたはクエリでテーブル A からデータを読み取り、テーブル B に書き込んだ場合、テーブル A とテーブル B の間のリンクは 1 年間だけ表示されます。 系列データは、1 年以内の時間枠でフィルター処理することができます。
- Jobs API
runs submit要求を使用するジョブは、系列を表示するときに対象外となります。runs submit要求の使用時もテーブル レベルと列レベルの系列はキャプチャされますが、実行へのリンクはキャプチャされません。 - Unity Catalog は、可能な限り列レベルに系列を取り込みます。 ただし、列レベルの系列を取り込むことができない場合があります。
- 列の系列は、ソースとターゲットの両方がテーブル名で参照されている場合にのみサポートされます (例:
select * from <catalog>.<schema>.<table>)。 ソースまたはターゲットがパスでアドレス指定されている場合、列の系列をキャプチャできません (例:select * from delta."s3://<bucket>/<path>")。 - テーブルまたはビューの名前が変わった場合、名前が変わったテーブルまたはビューの系列は取り込まれません。
- スキーマまたはカタログの名前が変更された場合、名前が変更されたカタログまたはスキーマのテーブルとビューの系列はキャプチャされません。
- Spark SQL データセットのチェックポイントを使用する場合、系列はキャプチャされません。
- Unity Catalog でキャプチャされる系列は、ほとんどの場合、Delta Live Tables パイプラインからのものです。 ただし、パイプラインで APPLY CHANGES API や TEMPORARY テーブルが使用されている場合などは、完全な系列カバレッジを保証できないことがあります。
- 系列では、Stack 関数はキャプチャされません。
- グローバル一時ビューは系列でキャプチャされません。
system.information_schema下のテーブルは系列にキャプチャされません。