ジョブのコンピューティングを構成する
この記事には、Databricks ジョブのコンピューティングを構成するための推奨事項とリソースが含まれています。
重要
ジョブのサーバーレス コンピューティングには次のような制限事項があります。
- 継続的スケジューリングはサポートされません。
- 構造化ストリーミングでは、既定または時間ベースの間隔トリガーはサポートされません。
制限事項の詳細については、「サーバーレス コンピューティングの制限事項」を参照してください。
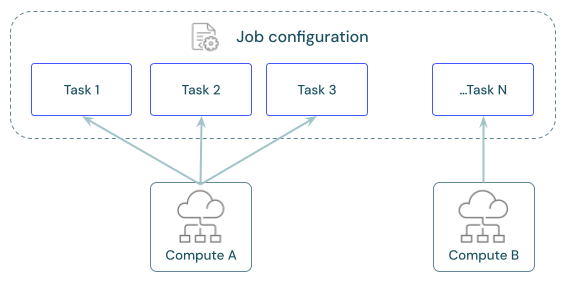
各ジョブには、1 つ以上のタスクを含めることができます。 各タスクのコンピューティング リソースを定義します。 同じジョブに対して定義された複数のタスクで、同じコンピューティング リソースを使用できます。
各タスクに推奨されるコンピューティングは何ですか?
次の表は、各タスクの種類に対して推奨されるコンピューティングの種類とサポートされているコンピューティングの種類を示しています。
Note
ジョブのサーバーレス コンピューティングには制限があり、すべてのワークロードをサポートしているわけではありません。 「サーバーレス コンピューティングの制限事項」を参照してください。
| タスク | 推奨されるコンピューティング | サポートされているコンピューティング |
|---|---|---|
| ノートブック | サーバーレス ジョブ | サーバーレス ジョブ、クラシック ジョブ、クラシック汎用 |
| Python スクリプト | サーバーレス ジョブ | サーバーレス ジョブ、クラシック ジョブ、クラシック汎用 |
| Python ホイール | サーバーレス ジョブ | サーバーレス ジョブ、クラシック ジョブ、クラシック汎用 |
| SQL | サーバーレス SQL ウェアハウス | サーバーレス SQL ウェアハウス、プロ SQL ウェアハウス |
| Delta Live Tables パイプライン | サーバーレス パイプライン | サーバーレス パイプライン、クラシック パイプライン |
| dbt | サーバーレス SQL ウェアハウス | サーバーレス SQL ウェアハウス、プロ SQL ウェアハウス |
| dbt CLI コマンド | サーバーレス ジョブ | サーバーレス ジョブ、クラシック ジョブ、クラシック汎用 |
| JAR | クラシック ジョブ | クラシック ジョブ、クラシック 汎用 |
| Spark Submit | クラシック ジョブ | クラシック ジョブ |
ジョブの価格は、タスクの実行に使用されるコンピューティングに関連付けられています。 詳細については、「Databricks の価格」を参照してください。
ジョブのコンピューティングはどのように構成しますか?
クラシック ジョブ コンピューティングは Databricks ジョブ UI から直接構成できます。これらの構成はジョブ定義の一部となります。 その他の使用可能なコンピューティングの種類はすべて、その構成を他のワークスペース アセットと共に格納します。 次の表に詳細を示します。
| コンピューティングの種類 | 詳細 |
|---|---|
| クラシック ジョブ コンピューティング | 汎用コンピューティングで使用できるのと同じ UI と設定を使用して、クラシック ジョブのコンピューティングを構成します。 「コンピューティング構成リファレンス」を参照してください。 |
| ジョブのサーバーレス コンピューティング | サーバーレスコンピューティングは、対応するすべてのタスクにおいて既定の計算方法です。 Databricks がサーバーレス コンピューティングのコンピューティング設定を管理します。 「ワークフローでサーバーレス コンピューティングを使用して Azure Databricks ジョブを実行する」を参照してください。 nn このオプションを表示するには、ワークスペース管理者がサーバーレス コンピューティングを有効にする必要があります。 「サーバーレス コンピューティングを有効にする」をご覧ください。 |
| SQL ウェアハウス | サーバーレスおよびプロ SQL ウェアハウスは、無制限のクラスター作成特権を持つワークスペース管理者またはユーザーによって構成されます。 既存の SQL ウェアハウスに対して実行するタスクを構成します。 「SQL ウェアハウスに接続する」を参照してください。 |
| Delta Live Tables パイプライン コンピューティング | パイプラインの構成中に Delta Live Tables パイプラインのコンピューティング設定を構成します。 デルタ ライブ テーブル パイプライン コンピューティングの構成を参照してください。 nn Azure Databricks は、サーバーレス Delta Live Tables パイプラインのコンピューティング リソースを管理します。 サーバーレス Delta Live Tables パイプラインの構成を参照してください。 |
| All-Purpose Compute | 必要に応じて、クラシック汎用コンピューティングを使用してタスクを構成できます。 Databricks では、運用環境の場合、この構成はお勧めしません。 「コンピューティング構成リファレンス」と「ジョブには常に汎用コンピューティングを使用した方がよいでしょうか?」を参照してください。 |
タスク間でコンピューティングを共有する
複数のタスクのオーケストレーションを行うジョブでリソースの使用量を最適化するために、同じジョブ コンピューティング リソースを使用するようにタスクを構成します。 タスク間でコンピューティングを共有すると、起動時間に関連する待機時間を短縮できます。
1 つのジョブ コンピューティング リソースを使用して、ジョブの一部であるすべてのタスク、または特定のワークロード用に最適化された複数のジョブ リソースを実行できます。 ジョブの一部として構成されたジョブ コンピューティングは、ジョブ内の他のすべてのタスクで使用できます。
次の表は、1 つのタスク用に構成されたジョブ コンピューティングと、タスク間で共有されるジョブ コンピューティングの違いを示しています。
| 1 つのタスク | タスク間で共有 | |
|---|---|---|
| Start | タスクの実行が開始されたとき。 | コンピューティング リソースを使用するように構成された最初のタスクの実行が開始されたとき。 |
| Terminate | タスクの実行後。 | コンピューティング リソースを使用するように構成された最後のタスクが実行された後。 |
| アイドル状態のコンピューティング | 該当なし。 | コンピューティング リソースを使用していないタスクの実行中も、コンピューティングはオンのままでアイドル状態になります。 |
共有ジョブ クラスターのスコープは 1 つのジョブ実行に設定され、同じジョブの他のジョブまたは実行では使用できません。
ライブラリを共有ジョブ クラスター構成で宣言することはできません。 依存ライブラリはタスク設定に追加する必要があります。
ジョブ コンピューティングを確認、構成、およびスワップする
[ジョブの詳細] パネルの [コンピューティング] セクションには、現在のジョブのタスク用に構成されているすべてのコンピューティングが一覧表示されます。
コンピューティング仕様にマウス ポインターを合わせると、コンピューティング リソースを使用するように構成されたタスクがタスク グラフで強調表示されます。
[スワップ] ボタンを使用して、コンピューティング リソースに関連付けられているすべてのタスクのコンピューティングを変更します。
クラシック ジョブ コンピューティング リソースには、構成オプションがあります。 その他のコンピューティング リソースには、コンピューティング構成の詳細を表示および変更するためのオプションがあります。
クラシック ジョブ コンピューティングの構成に関する推奨事項
このセクションでは、一部のワークフローに役立つ機能と構成に関する一般的な推奨事項について説明します。 コンピューティング リソースのサイズと種類を構成するための具体的な推奨事項は、ワークロードによって異なります。
Databricks では、Photon Acceleration を有効にし、最新の Databricks Runtime バージョンを使用し、Unity カタログ用に構成されたコンピューティングを使用することをお勧めします。
ジョブのサーバーレス コンピューティングでは、以下の事項を考慮しなくてもよいように、すべてのインフラストラクチャが管理されます。 「ワークフローでサーバーレス コンピューティングを使用して Azure Databricks ジョブを実行する」を参照してください。
Note
構造化ストリーミング ワークフローには、特定の推奨事項があります。 「構造化ストリーミングの運用に関する考慮事項」を参照してください。
共有アクセス モードを使用する
Databricks では、ジョブに共有アクセス モードを使用することをお勧めします。 「アクセス モード」を参照してください。
Note
共有アクセス モードでは、一部のワークロードと機能はサポートされていません。 Databricks では、これらのワークロードに単一ユーザー アクセス モードをお勧めします。 Unity Catalog のコンピューティング アクセス モードの制限事項に関する記事を参照してください。
クラスター ポリシーの使用
Databricks では、ワークスペース管理者がジョブのクラスター ポリシーを定義し、ジョブの構成を行うすべてのユーザーに対してこれらのポリシーを適用することをお勧めします。
クラスター ポリシーを使用すると、ワークスペース管理者はコスト制御を設定し、ユーザーの構成オプションを制限できます。 クラスター ポリシー構成の詳細については、「コンピューティング ポリシーの作成と管理」を参照してください。
Azure Databricks には、ジョブ用に構成された既定のポリシーが用意されています。 管理者は、このポリシーを他のワークスペース ユーザーが使用できるようにできます。 「ジョブ コンピューティング」を参照してください。
自動スケーリングを使用する
実行時間の長いタスクがジョブの実行中にワーカー ノードを動的に追加および削除できるように、自動スケールを構成します。 「自動スケールの有効化」を参照してください。
プールを使用してクラスターの起動時間を短縮する
コンピューティング プールを使用すると、クラウド プロバイダーのコンピューティング リソースを予約できます。 プールは、新しいジョブ クラスターの開始時間を短縮し、コンピューティング リソースの可用性を確保するのに役立ちます。 「プール構成リファレンス」を参照してください。
スポット インスタンスを使用する
コストを最適化するために待機時間の要件が緩いワークロードのスポット インスタンスを構成します。 「スポット インスタンス」を参照してください。
ジョブには常に汎用コンピューティングを使用した方がよいでしょうか?
Databricks では、ジョブに汎用コンピューティングの使用を推奨しない理由が次のように多数あります。
- Azure Databricks では、汎用コンピューティングに対してジョブ コンピューティングとは異なるレートで課金されます。
- ジョブ コンピューティングは、ジョブの実行が完了すると自動的に終了します。 汎用コンピューティングでは、自動終了がサポートされます。これは、ジョブの実行の終了ではなく、非アクティブに関連付けられています。
- 汎用コンピューティングは、多くの場合、ユーザーのチーム間で共有されます。 多くの場合、汎用コンピューティングに対してスケジュールされたジョブは、コンピューティング リソースの競合により待機時間が長くなります。
- ジョブ コンピューティングの構成を最適化するための多くの推奨事項は、アドホック クエリの種類には適していません。また、対話型ワークロードは汎用コンピューティングで実行されます。
ジョブに対して汎用コンピューティングを使用する場合のユース ケースを次に示します。
- 新しいジョブを繰り返し開発またはテストする場合。 ジョブ コンピューティングの起動に時間がかかるため、反復開発が面倒になる場合があります。 汎用コンピューティングを使用すると、変更を適用してジョブをすばやく実行できます。
- 頻繁に実行したり、特定のスケジュールで実行したりする必要がある、短時間のジョブがある場合。 現在実行中の汎用コンピューティングは、起動時間を必要としません。 ただし、このパターンを使用する場合は、アイドル時間に関連するコストを考慮してください。
汎用コンピューティングで実行することが不適当と考えられるタスクの種類のほとんどについて、代替としてジョブのサーバーレス コンピューティングをお勧めします。