Mosaic AI モデル トレーニングの API を使用してトレーニングの実行を作成する
重要
この機能は、次のリージョンでパブリック プレビュー段階です: 、、centralus、eastus、eastus2、northcentralus、westcentralus、westus、westus3。 パブリック プレビューに登録する場合は、Databricks アカウント チームにお問い合わせください。
このページでは、Mozaic AI モデル トレーニング (旧称 Foundation Model Training) の API を使ってトレーニングの実行を作成および構成する方法と、API 呼び出しで使用されるすべてのパラメーターについて説明します。 UI を使用して実行を作成することもできます。 手順については、「Mosaic AI モデル トレーニングの UI を使用してトレーニングの実行を作成する」を参照してください。
要件
「 要件」を参照してください。
トレーニングの実行を作成する
プログラムでトレーニングの実行を作成するには、create() 関数を使用します。 この関数では、指定されたデータセットのモデルをトレーニングし、最終的な Composer チェックポイントを推論用の Hugging Face 形式のチェックポイントに変換します。
必要な入力は、トレーニングするモデル、トレーニング データセットの場所、モデルを登録する場所です。 また、評価を実行し、実行のハイパーパラメーターを変更できる省略可能なフィールドもあります。
実行が完了すると、完了した実行と最終チェックポイントが保存され、モデルがクローンされ、そのクローンが推論用のモデル バージョンとして Unity Catalog に登録されます。
(Unity Catalog 内のクローンされたモデル バージョンではなく) 完了した実行のモデルと Composer チェックポイントと Hugging Face チェックポイントが MLflow に保存されます。 Composer チェックポイントは、継続的な微調整タスクに使用できます。
create() 関数の引数の詳細については、「トレーニングの実行を構成する」を参照してください。
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
トレーニングの実行を構成する
次の表は、create() 関数のフィールドをまとめたものです。
| フィールド | 必須 | タイプ | 説明設定 |
|---|---|---|---|
model |
x | str | 使用するモデルの名前。 「サポートされているモデル」を参照してください。 |
train_data_path |
x | str | トレーニング データの場所。 これは、Unity Catalog 内の場所 (<catalog>.<schema>.<table> または dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl)、あるいは HuggingFace データセットにすることができます。INSTRUCTION_FINETUNE の場合、データは、prompt と response フィールドを含む各行で書式設定する必要があります。CONTINUED_PRETRAIN の場合、これは .txt ファイルのフォルダーです。 受け入れられるデータ形式については「Mosaic AI モデル トレーニング用にデータを準備する」を、推奨されるデータ サイズについては「モデル トレーニングの推奨されるデータ サイズ」を参照してください。 |
register_to |
x | str | 簡単にデプロイできるようにトレーニング後にモデルが登録される Unity Catalog のカタログとスキーマ (<catalog>.<schema> または <catalog>.<schema>.<custom-name>)。 custom-name が指定されていない場合、これは既定で実行名になります。 |
data_prep_cluster_id |
str | Spark データ処理に使用するクラスターのクラスター ID。 これは、トレーニング データが Delta テーブルにある教師ありトレーニング タスクに必要です。 クラスター ID を見つける方法については、「クラスター ID の取得」を参照してください。 | |
experiment_path |
str | トレーニング実行の出力 (メトリックとチェックポイント) が保存される MLflow 実験へのパス。 既定では、ユーザーの個人用ワークスペース内の実行名になります (つまり、/Users/<username>/<run_name>)。 |
|
task_type |
str | 実行するタスクの種類。 INSTRUCTION_FINETUNE (既定値)、CHAT_COMPLETION、または CONTINUED_PRETRAIN にすることができます。 |
|
eval_data_path |
str | 評価データのリモートの場所 (存在する場合)。 train_data_path と同じ形式に従う必要があります。 |
|
eval_prompts |
str | 評価中に応答を生成するプロンプト文字列の一覧。 既定値は None (プロンプトを生成しない) です。 モデルがチェックポイント処理されるたびに、結果が実験に記録されます。 次の生成パラメーターを持つすべてのモデル チェックポイントで生成が行われます: max_new_tokens: 100、temperature: 1、top_k: 50、top_p: 0.95、do_sample: true。 |
|
custom_weights_path |
str | トレーニング用のカスタム モデル チェックポイントのリモートの場所。 既定値は None です。これは、選択したモデルの元の事前トレーニング済みの重みから実行が開始されていることを意味します。 カスタムの重みが指定されている場合、モデルの元の事前トレーニング済みの重みではなく、これらの重みが使用されます。 これらの重みは Composer チェックポイントである必要があり、指定された model のアーキテクチャと一致している必要があります |
|
training_duration |
str | 実行の合計期間。 既定値は 1 エポック (1ep) です。 複数のエポック (10ep) または複数のトークン (1000000tok) で指定できます。 |
|
learning_rate |
str | モデル トレーニングの学習率。 既定値は 5e-7 です。 オプティマイザーは DecoupledLionW で、ベータ値は 0.99 および 0.95、重み減衰はありません。 学習率スケジューラは LinearWithWarmupSchedule で、ウォームアップはトレーニング期間全体の 2%、最終的な学習率の乗数は 0 です。 |
|
context_length |
str | データ サンプルの最大シーケンス長。 これは、長すぎるデータを切り捨て、短いシーケンスをまとめてパッケージ化して効率を高めるために使用されます。 既定値は、8192 トークンか、指定されたモデルの最大コンテキスト長のいずれか小さい方です。 このパラメーターを使用してコンテキスト長を構成できますが、各モデルの最大コンテキスト長を超える構成はサポートされていません。 各モデルでサポートされるコンテキストの最大長については、「サポートされているモデル」を参照してください。 |
|
validate_inputs |
Boolean | トレーニング ジョブを送信する前に、入力パスへのアクセスを検証するかどうか。 既定値は True です。 |
カスタム モデルの重みを基にする
Mosaic AI モデル トレーニングでは、省略可能なパラメーター custom_weights_path. を使用するカスタムの重みから始まるサポートされているモデルのトレーニングがサポートされます
たとえば、カスタム データを使用してドメイン固有のモデルを作成し、さらにトレーニングするための入力として目的のチェックポイントを渡すことができます。
トレーニングのために前の実行から Composer チェックポイントにリモートの場所を指定できます。 チェックポイント パスは、前の MLflow 実行の [成果物] タブにあり、シンボリック リンク拡張子が省略可能な dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/<checkpoint_folder>[.symlink] という形式です。 このチェックポイント フォルダー名は、特定のスナップショットのバッチとエポックに対応します (ep29-ba30/ など)。 最終的なスナップショットには、シンボリック リンク latest-sharded-rank0.symlink を使用してアクセスできます。
![前の MLflow 実行の [成果物] タブ](../../_static/images/large-language-models/checkpoint-path.png)
その後、パスを構成の custom_weights_path パラメーターに渡すことができます。
model = 'meta-llama/Llama-2-7b-chat-hf'
custom_weights_path = 'your/checkpoint/path'
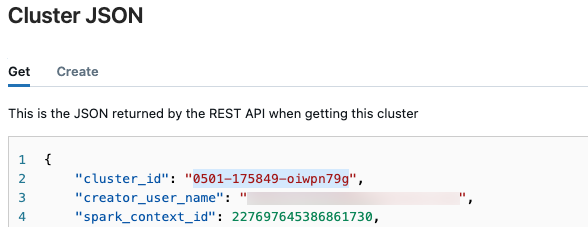
クラスター ID を取得する
クラスター ID を取得するには:
Databricks ワークスペースの左側のナビゲーション バーで、[コンピューティング] をクリックします。
テーブルで、クラスターの名前をクリックします。
右上隅にある [
![[その他] ボタン](../../_static/images/large-language-models/more-button.png) ] をクリックし、ドロップダウン メニューから [JSON の表示] を選択します。
] をクリックし、ドロップダウン メニューから [JSON の表示] を選択します。クラスター JSON ファイルが表示されます。 ファイルの最初の行であるクラスター ID をコピーします。
実行の状態を取得する
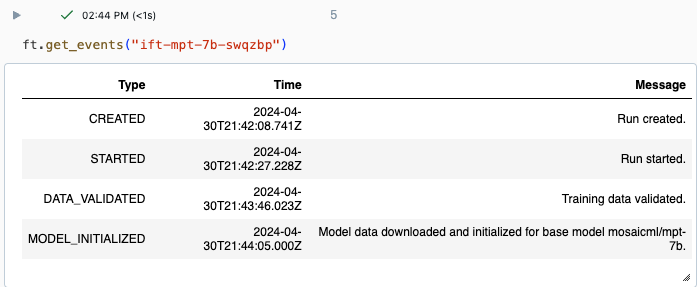
実行の進行状況は、Databricks UI の実験ページまたは API コマンド get_events() を使用して追跡できます。 詳細については、「Mosaic AI モデル トレーニングの実行を表示、管理、分析する」を参照してください。
get_events() からの出力例:
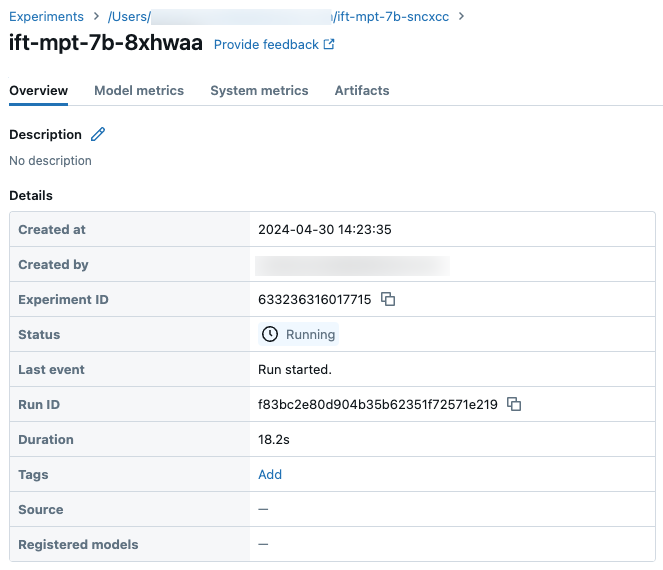
実験ページのサンプルの実行の詳細:
次のステップ
トレーニングの実行が完了した後、MLflow でメトリックを確認し、推論のためにモデルをデプロイできます。 「チュートリアル: Mosaic AI モデル トレーニングの実行を作成してデプロイする」の手順 5 から 7 を参照してください。
データの準備、トレーニング実行の構成のファインチューニング、デプロイの手順を示す手順ファインチューニングの例については、「手順ファインチューニング: 固有表現認識」デモ ノートブックを参照してください。
ノートブックの例
次のノートブックは、Meta Llama 3.1 405B Instruct モデルを使用して合成データを生成し、そのデータを使用してモデルをファインチューニングする方法の例を示しています。