特徴エンジニアリングとサービス提供
このページでは、Unity Catalog が有効になっているワークスペースの特徴エンジニアリング機能および特徴量提供機能について説明します。 ワークスペースで Unity Catalog が有効になっていない場合は、「ワークスペース特徴量ストア (レガシ)」を参照してください。
Databricks を特徴量ストアとして使用する理由は?
Databricks Data Intelligence Platform では、以下のモデル トレーニング ワークフロー全体が 1 つのプラットフォーム上で実行されます。
- 生データの取り込み、特徴量テーブルの作成、モデルのトレーニング、バッチ推論の実行を行うデータ パイプライン。 Unity Catalog 内で特徴エンジニアリングを使用してモデルのトレーニングとログを行うと、モデルは特徴量メタデータと共にパッケージ化されます。 バッチ スコアリングまたはオンライン推論にモデルを使用すると、モデルは自動的に特徴量値を取得します。 呼び出し元は、それらについて把握したり、新しいデータをスコア付けするために特徴量を検索または結合するためのロジックを含めたりする必要はありません。
- シングルクリックで利用可能で待機時間が数ミリ秒であるモデルと特徴量の提供エンドポイント。
- データとモデルの監視。
さらに、このプラットフォームには以下のものが用意されています。
- 特徴量検出。 Databricks UI で特徴量を参照および検索できます。
- ガバナンス。 特徴量テーブル、関数、モデルはすべて Unity Catalog によって管理されます。 モデルをトレーニングすると、モデルはトレーニング対象のデータからアクセス許可を継承します。
- 系列。 Azure Databricks で特徴量テーブルを作成すると、特徴量テーブルの作成に使用されたデータ ソースが保存され、アクセスできるようになります。 特徴量テーブル内の各特徴量について、その特徴量を使用しているモデル、ノートブック、ジョブ、エンドポイントにアクセスすることもできます。
- クロスワークスペース アクセス。 特徴量テーブル、関数、およびモデルは、カタログにアクセスできる任意のワークスペース内で自動的に利用可能になります。
要件
- ワークスペースは、Unity Catalog に対して有効にする必要があります。
- Unity Catalog 内の特徴エンジニアリングには、Databricks Runtime 13.3 LTS 以上が必要です。
ワークスペースがこれらの要件を満たしていない場合は、「ワークスペース特徴量ストア (レガシ)」でワークスペース特徴量ストアの使用方法を確認してください。
Databricks 上の特徴エンジニアリングのしくみは?
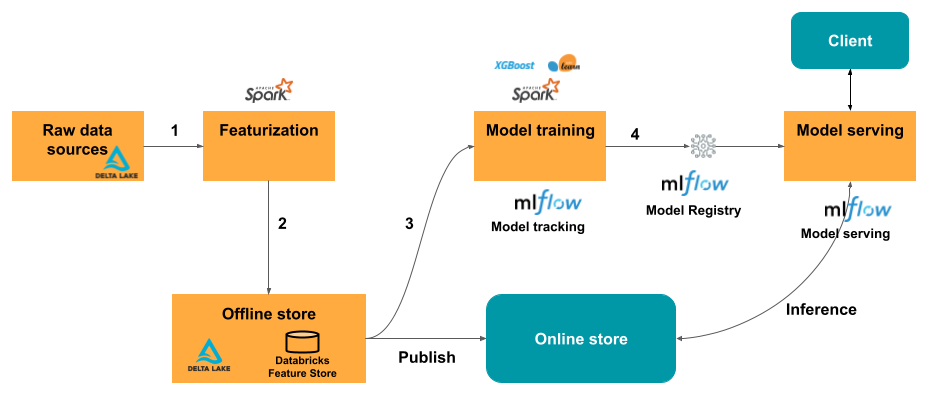
Databricks で特徴エンジニアリングを使用する一般的な機械学習ワークフローが従うパスは以下のとおりです。
- 生データを機能に変換し、目的の機能を含む Spark DataFrame を作成するコードを記述します。
- Unity Catalog 内に Delta テーブルを作成します。 主キーを持つ Delta テーブルは、自動的に特徴量テーブルになります。
- 特徴量テーブルを使用してモデルをトレーニングしてログします。 これを行うと、トレーニングに使用された特徴量の仕様がモデルに格納されます。 モデルが推論に使用されると、適切な特徴量テーブルから特徴量が自動的に結合されます。
- モデル レジストリにモデルを登録します。
これで、モデルを使用して新しいデータで予測を行うことができます。 バッチ ユース ケースの場合は、モデルが必要な特徴量を Feature Store から自動的に取得します。
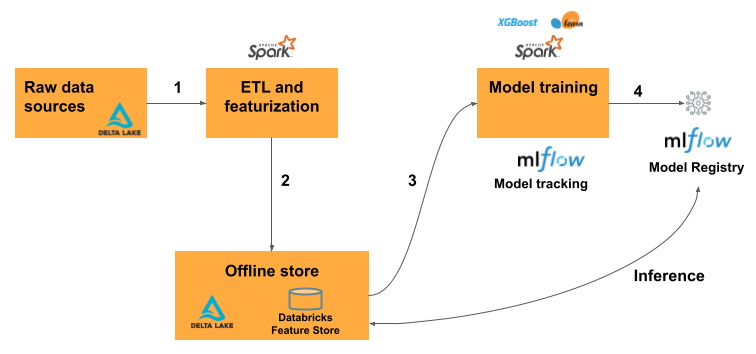
リアルタイムに提供するユース ケースの場合は、オンライン テーブルに特徴量を公開します。 サードパーティのオンライン ストアもサポートされています。 「サード パーティのオンライン ストア」を参照してください。
推論時に、モデルがオンライン ストアから事前計算された特徴量を読み取って、モデル提供エンドポイントに対するクライアント要求で提供されたデータと結合します。
特徴エンジニアリングの使用を開始する — ノートブック例
手始めに、以下のノートブック例を試してください。 この基本的なノートブックでは、特徴量テーブルを作成し、それを使用してモデルをトレーニングした後、自動特徴量検索を使用してバッチ スコアリングを実行する方法について説明しています。 また、特徴エンジニアリング UI について紹介し、それを使って特徴を検索する方法に加え、特徴がどのように作成および使用されるかについて説明します。
Unity Catalog における基本的な特徴エンジニアリングのノートブック例
ノートブックのタクシーの例では、特徴の作成と更新に加え、モデル トレーニングとバッチ推論での特徴の使用のプロセスについて説明しています。
Unity Catalog での基本的な特徴エンジニアリングのノートブックのタクシーの例
サポートされるデータ型
Unity Catalog 内の特徴エンジニアリングとワークスペース特徴量ストアでは以下の PySpark データ型がサポートされています。
IntegerTypeFloatTypeBooleanTypeStringTypeDoubleTypeLongTypeTimestampTypeDateTypeShortTypeArrayTypeBinaryType[1]DecimalType[1]MapType[1]StructType[2]
[1] BinaryType、DecimalType、MapType は、Unity Catalog のすべてのバージョンの特徴エンジニアリングとワークスペース Feature Store v0.3.5 以上でサポートされています。
[2] StructType は Feature Engineering v0.6.0 以上でサポートされています。
上記のデータ型は、機械学習アプリケーションで一般的な機能の種類をサポートしています。 次に例を示します。
- 高密度ベクトル、テンソル、埋め込みを
ArrayTypeのように格納できます。 - スパース ベクトル、テンソル、埋め込みを
MapTypeのように格納できます。 - テキストを
StringTypeのように格納できます。
オンライン ストアに公開された場合、ArrayType および MapType 特徴は JSON 形式で格納されます。
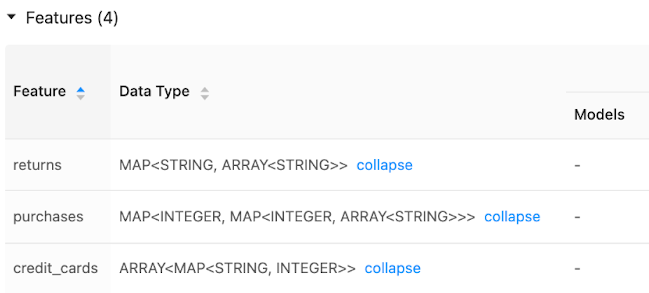
Feature Store UI には、特徴データ型のメタデータが表示されます。
詳細
ベスト プラクティスの詳細が必要な場合は、「特徴量ストアの包括的なガイド」をダウンロードしてください。