プロビジョニング スループット Foundation Model API
この記事では、プロビジョニング スループットで Foundation Model API を使用してモデルをデプロイする方法について説明します。 Databricks では、運用環境のワークロードに対してプロビジョニング スループットが推奨され、パフォーマンスが保証された基盤モデルの最適化された推論が提供されます。
サポートされるモデル アーキテクチャの一覧については、プロビジョニング スループット Foundation Model API に関する記事を参照してください。
要件
「要件」を参照してください。 ファインチューニングされた基盤モデルの展開については、「ファインチューニングされた基盤モデルを展開する」を参照してください。
[推奨] Unity カタログから基盤モデルをデプロイする
重要
この機能はパブリック プレビュー段階にあります。
Databricks では、Unity カタログにプレインストールされている基盤モデルを使用することをお勧めします。 これらのモデルは、スキーマ ai (system.ai) のカタログ system の下にあります。
基盤モデルをデプロイするには:
- カタログ エクスプローラーで
system.aiに移動します。 - デプロイするモデルの名前をクリックします。
- モデル ページで、[Serve this model] (このモデルを提供する) ボタンをクリックします。
- [Create serving endpoint] (サービス エンドポイントの作成) ページが表示されます。 「UI を使用してプロビジョニング スループット エンドポイントを作成する」を参照してください。
Databricks Marketplace から基盤モデルをデプロイする
または、Databricks Marketplace から Unity カタログに基盤モデルをインストールすることもできます。
モデル ファミリを検索し、モデル ページから [アクセスの取得] を選び、ログイン資格情報を指定してモデルを Unity Catalog にインストールできます。
モデルを Unity Catalog にインストールした後、Serving UI を使用してモデルの提供のエンドポイントを作成できます。
DBRX モデルをデプロイする
Databricks では、ワークロードに対して DBRX Instruct モデルを提供することが推奨されます。 プロビジョニングされたスループットを使用して DBRX Instruct モデルを提供するには、[推奨] Unity カタログから基盤モデルをデプロイするのガイダンスに従います。
これらの DBRX モデルを提供する場合、プロビジョニング スループットでは最大 16k のコンテキスト長がサポートされます。
DBRX モデルでは、次の既定のシステム プロンプトを使用して、モデル応答の関連性と正確性が確保されます。
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
ファインチューニングされた基盤モデルを展開する
system.ai スキーマでモデルを使用できない場合、または Databricks Marketplace からモデルをインストールできない場合は、Unity カタログにログ記録することで、微調整された基盤モデルをデプロイできます。 これ以降のセクションでは、MLflow モデルを Unity Catalog にログし、UI または REST API を使用してプロビジョニングされたスループット エンドポイントを作成するようにコードを設定する方法について説明します。
要件
- ファインチューニングされた基盤モデルの展開は、MLflow 2.11 以上でのみサポートされます。 Databricks Runtime 15.0 ML 以上では、互換性のある MLflow バージョンがプレインストールされます。
- 埋め込みエンドポイントの場合、そのモデルは小規模または大規模な BGE 埋め込みモデル アーキテクチャである必要があります。
- Databricks では、大規模なモデルのアップロードとダウンロードを高速化するために、Unity Catalog でモデルを使うことを推奨しています。
カタログ、スキーマ、モデル名を定義する
ファインチューニングされた基盤モデルを展開するには、ターゲットの Unity Catalog のカタログ、スキーマ、任意のモデル名を定義します。
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
モデルをログに記録する
モデル エンドポイントのプロビジョニングされたスループットを有効にするには、MLflow transformers フレーバーを使用してモデルをログし、次のオプションから適切なモデルの種類のインターフェイスで task 引数を指定する必要があります。
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
これらの引数では、モデル サービング エンドポイントに使用される API シグネチャを指定します。 これらの task と対応する入出力スキーマの詳細については、MLflow のドキュメントを参照してください。
MLflow を使用してログされたテキスト補完言語モデルを、ログする方法の例を次に示します。
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency
save_pretrained=False
)
Note
2.12 より前の MLflow を使用している場合は、代わりに同じ mlflow.transformer.log_model() 関数の metadata パラメーター内で task を指定する必要があります。
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
プロビジョニングされたスループットでは、小規模および大規模な BGE 埋め込みモデルのどちらもサポートします。 プロビジョニングされたスループットを使用して提供できるように、BAAI/bge-small-en-v1.5 モデルをログする方法の例を次に示します。
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-small-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "bge-large" # Or "bge-small"
}
)
このモデルが Unity Catalog 内にログされたら、「UI を使用してプロビジョニングされたスループット エンドポイントを作成する」に進んで、プロビジョニングされたスループットでモデル サービング エンドポイントを作成します。
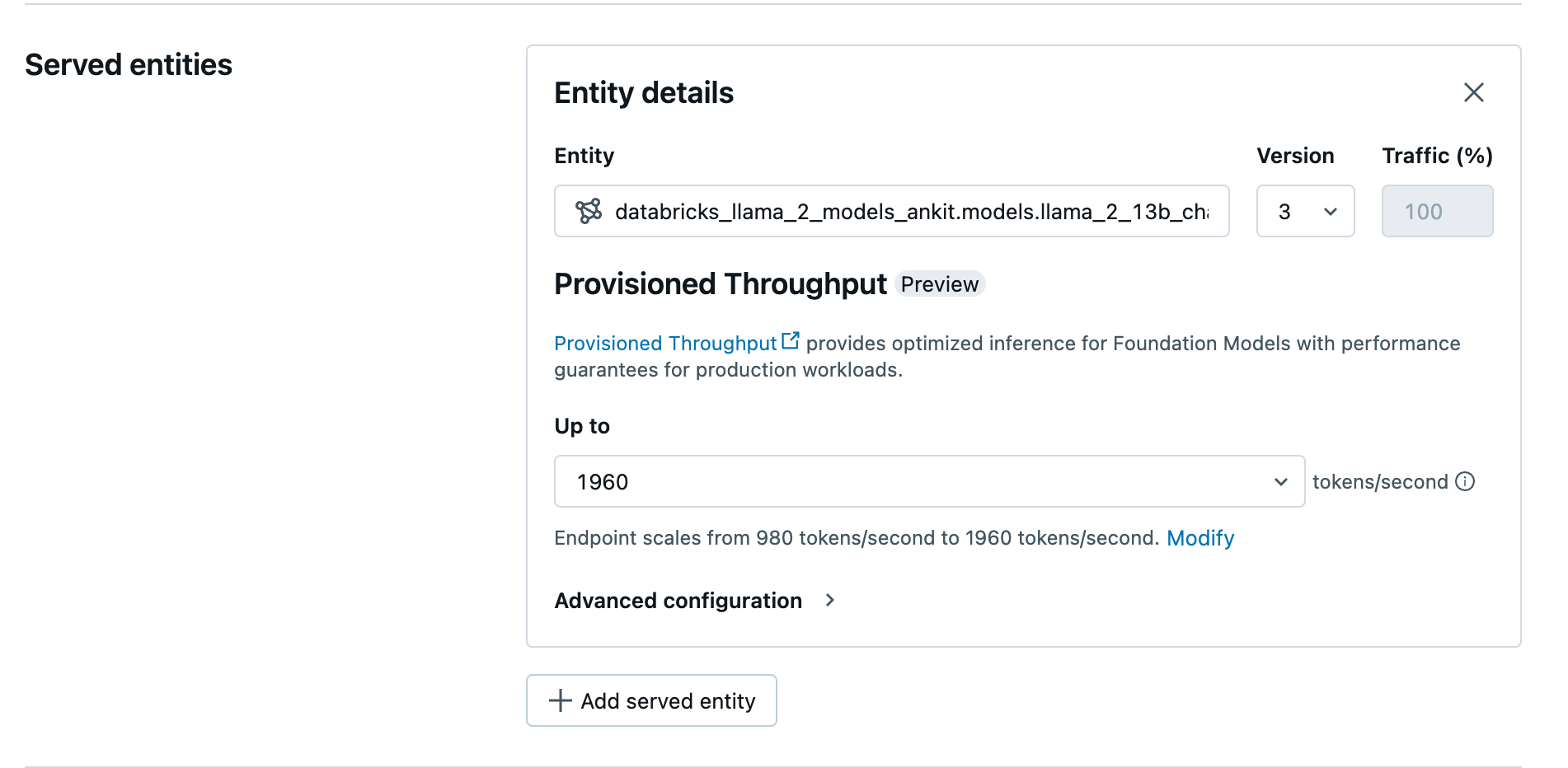
UI を使用してプロビジョニング スループット エンドポイントを作成する
Unity Catalog でモデルをログしたら、次の手順でプロビジョニング スループットの提供のエンドポイントを作成します。
- ワークスペース内の [提供 UI] に移動します。
- [提供エンドポイントの作成] を選択します。
- [エンティティ] フィールドで、Unity Catalog からモデルを選択します。 対象モデルの場合、提供されるエンティティの UI にはプロビジョニング スループット画面が表示されます。
- [最大] ドロップダウンで、エンドポイントの最大トークン/秒のスループットを構成できます。
- プロビジョニング スループット エンドポイントは自動的にスケーリングするため、[変更] を選択すると、エンドポイントがスケールダウンできる 1 秒あたりの最小トークンを表示できます。
REST API を使用してプロビジョニング スループット エンドポイントを作成する
REST API を使用してプロビジョニング スループット モードでモデルをデプロイするには、要求で min_provisioned_throughput と max_provisioned_throughput の各フィールドを指定する必要があります。
お使いのモデルに適したプロビジョニング スループットの範囲を特定するには、「プロビジョニング スループットを増分で取得する」を参照してください。
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
プロビジョニング スループットを増分で取得する
プロビジョニング スループットは、モデルによって異なる特定の増分を含む 1 秒あたりのトークンの増分で利用可能です。 お客様のニーズに適した範囲を特定するために、Databricks はプラットフォーム内のモデル最適化情報 API を使用することを推奨します。
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
API からの応答の例を次に示します。
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
ノートブックの例
次のノートブックは、プロビジョニング スループット Foundation Model API を作成する方法の例を示しています。
Llama2 モデル ノートブックのプロビジョニング スループット提供
Mistral モデル ノートブックのプロビジョニング スループット提供
BGE モデル ノートブックのプロビジョニング スループット提供
制限事項
- エンドポイントの作成または更新中にタイムアウトが発生する GPU 容量の問題により、モデル デプロイに失敗する場合があります。 解決のお手伝いが必要な場合は、Databricks アカウント チームにお問い合わせください。
- Foundation Models API の自動スケーリングは、CPU モデル提供よりも低速です。 Databricks では、要求のタイムアウトを回避するために、過剰なプロビジョニングを推奨しています。