カスタム モデル サービング エンドポイントを作成する
この記事では、Databricks Model Serving を使用してカスタム モデルを提供するモデル サービング エンドポイントの作成方法について説明します。
Model Serving には、提供エンドポイントの作成に関する次のオプションが用意されています。
- 提供 UI
- REST API
- MLflow デプロイ SDK
生成型 AI モデルを提供するエンドポイントの作成については、「エンドポイントにサービスを提供する基盤モデル
要件
- ワークスペースはサポートされているリージョン内に存在する必要があります。
- モデルでカスタム ライブラリまたはプライベート ミラー サーバーのライブラリを使用する場合は、モデル エンドポイントを作成する前に、「Model Serving でのカスタム Python ライブラリの使用」を参照してください。
- MLflow デプロイ SDK を使用してエンドポイントを作成するには、MLflow デプロイ クライアントをインストールする必要があります。 インストールするには、以下を実行します。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
アクセス制御
エンドポイント管理用のモデル サービング エンドポイントのアクセス制御オプションについては、「モデル サービング エンドポイントに対するアクセス許可の管理」を参照してください。
環境変数を追加して、モデル提供の資格情報を格納することもできます。 「モデル サービング エンドポイントからリソースへのアクセスを構成する」を参照してください
エンドポイントの作成
提供 UI
Serving UI を使用してモデル提供のエンドポイントを作成することができます。
サイドバーの [Serving] をクリックして、Serving UI を表示します。
[提供エンドポイントの作成] をクリックします。
![Databricks UI の [モデル提供] ペイン](../../_static/images/machine-learning/serving-pane.png)
ワークスペース モデル レジストリに登録されているモデル、または Unity Catalog 内のモデルの場合:
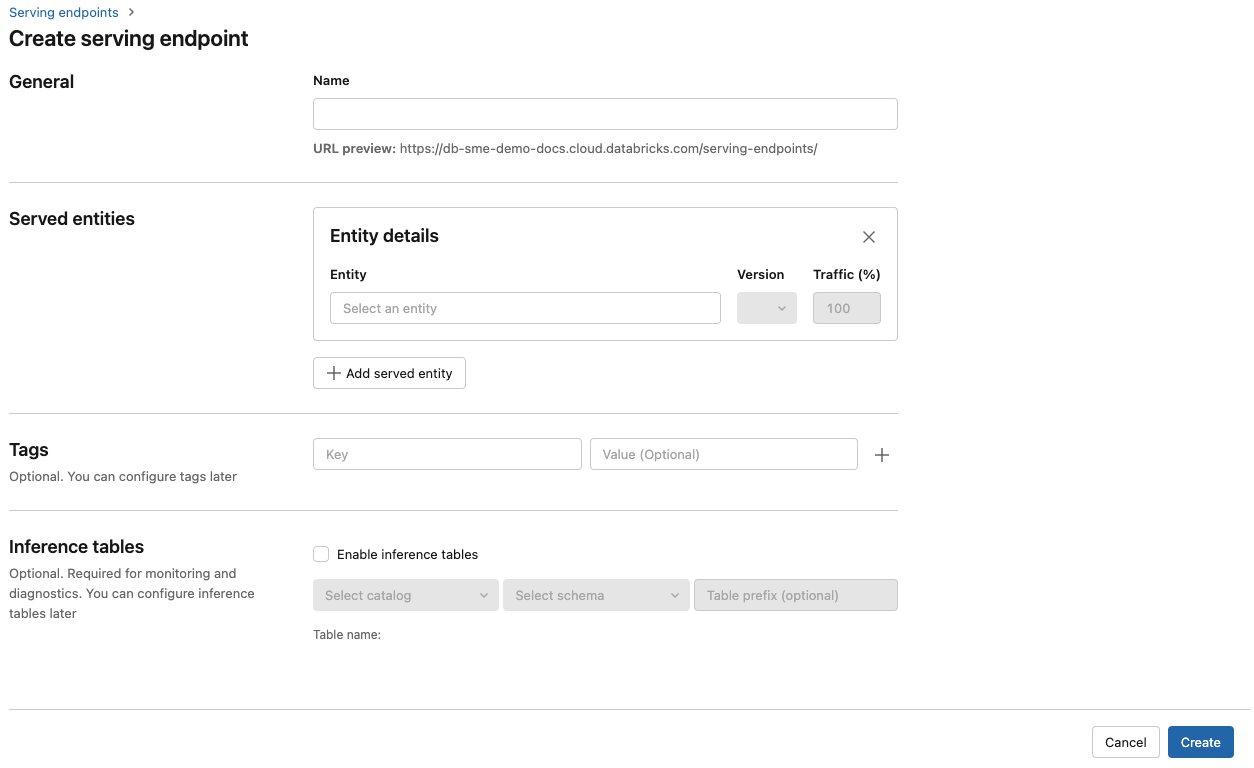
[名前] フィールドに、エンドポイントの名前を指定します。
[Served entities] (提供されるエンティティ) セクションで、次のようにします。
- [エンティティ] フィールドをクリックして、[Select served entity] (提供されるエンティティの選択) フォームを開きます。
- 提供するモデルの種類を選択します。 フォームは、選択内容に基づいて動的に更新されます。
- 提供したいモデルとモデルのバージョンを選択します。
- 提供されるモデルにルーティングするトラフィックの割合を選択します。
- 使用するコンピューティングのサイズを選択します。 ワークロードには CPU または GPU コンピューティングを使用できます。 使用可能な GPU コンピューティングの詳細については、「GPU ワークロードの種類」を参照してください。
- 使用するコンピューティングのサイズを選択します。 ワークロードには CPU または GPU コンピューティングを使用できます。 使用可能な GPU コンピューティングの詳細については、「GPU ワークロードの種類」を参照してください。
- [Compute Scale-out] (コンピューティング スケールアウト) で、この提供されるモデルが同時に処理できる要求の数に対応するコンピューティング スケールアウトのサイズを選択します。 この数値は、QPS にモデル実行時間を掛けた値とほぼ同じである必要があります。
- 使用可能なサイズは、Small (要求数が 0 から 4 個の場合)、Medium (要求数が 8 から 16 個の場合)、Large (要求数が 16 から 64 個の場合) です。
- 使用しないときにエンドポイントをゼロにスケールダウンする必要があるかどうかを指定します。
Create をクリックしてください。 [提供エンドポイントの状態] が Not Ready となっている [提供エンドポイント] ページが表示されます。
REST API
REST API を使ってエンドポイントを作成できます。 エンドポイントの構成パラメーターについては、POST /api/2.0/serving-endpoints を参照してください。
次の例では、Unity カタログ モデル レジストリに登録されている ads1 モデルの最初のバージョンを提供するエンドポイントを作成します。 Unity Catalog からモデルを指定するには、catalog.schema.example-model などの親カタログとスキーマを含む完全なモデル名を指定します。
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
応答の例を次に示します。 エンドポイントの config_update 状態は NOT_UPDATING であり、提供されるモデルは READY 状態にあります。
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "catalog.schema.my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow デプロイ SDK
MLflow Deployments には、作成、更新、削除のタスク用の API が用意されています。 これらのタスクの API は、提供エンドポイントの REST API と同じパラメーターを受け取ります。 エンドポイントの構成パラメーターについては、POST /api/2.0/serving-endpoints を参照してください。
次の例では、Unity カタログ モデル レジストリに登録されている my-ads-model モデルの 3 番目のバージョンを提供するエンドポイントを作成します。 親カタログやスキーマを含む完全なモデル名を指定する必要があります (例: catalog.schema.example-model)。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
次のこともできます。
推論テーブルを有効にして、受信した要求と、エンドポイントを提供するモデルへの送信応答を自動的にキャプチャします。
GPU ワークロードの種類
GPU デプロイは、次のパッケージ バージョンと互換性があります。
- Pytorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 移行
GPU を使用してモデルをデプロイするには、workload_type中にエンドポイント構成に フィールドを含めるか、API を使用したエンドポイント構成の更新としてフィールドを含めます。 サービス UI を使用して GPU ワークロードのエンドポイントを構成するには、[Compute Type] (コンピューティングの種類) ドロップダウンから目的の GPU の種類を選択します。
{
"served_entities": [{
"entity_name": "catalog.schema.ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
次の表は、サポートされる使用可能な GPU ワークロードの種類をまとめたものです。
| GPU ワークロードの種類 | GPU インスタンス | GPU メモリ |
|---|---|---|
GPU_SMALL |
1xT4 | 16GB |
GPU_LARGE |
1xA100 | 80GB |
GPU_LARGE_2 |
2xA100 | 160GB |
カスタム モデル エンドポイントを変更する
カスタム モデル エンドポイントを有効化すると、必要に応じてコンピューティング構成を更新できます。 特にモデルのリソースを増やす必要が生じた場合に、この構成を有効活用できます。 モデルを提供するためのリソース割り当てには、ワークロードのサイズとコンピューティング構成が重要な役割を果たします。
新しい構成の準備ができるまでは、古い構成が予測トラフィックを提供し続けます。 更新が進行中の間は、別の更新を行うことはできません。 ただし、進行中の更新は、Serving UI から取り消すことができます。
提供 UI
モデル エンドポイントを有効にしたら、[エンドポイントの編集] を選択して、エンドポイントのコンピューティング構成を変更します。
次の操作を実行できます。
- いくつかあるワークロード サイズから選択すると、自動スケーリングはそのワークロード サイズ内で自動的に構成されます。
- 使用しない場合にエンドポイントを 0 にスケールダウンする必要があるかどうかを指定します。
- 提供されるモデルにルーティングするトラフィックの割合を変更します。
エンドポイントの詳細ページの右上にある [更新のキャンセル] を選択することで、進行中である構成の更新をキャンセルできます。 この機能は、Serving UI でのみ使用できます。
REST API
REST API を使用したエンドポイント構成の更新例を次に示します。 PUT /api/2.0/serving-endpoints/{name}/config を参照してください。
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow デプロイ SDK
MLflow デプロイ SDK は REST API と同じパラメータを使用します。要求と応答のスキーマの詳細については、PUT /api/2.0/serving-endpoints/{name}/config を参照してください。
次のコード サンプルでは、Unity カタログのモデル レジストリのモデルを使用します。
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
モデル エンドポイントのスコアリング
モデルのスコアを付けるには、モデル サービング エンドポイントに要求を送信します。
- 「カスタム モデルのエンドポイントを提供するクエリ」をご覧ください。
- クエリ基盤モデルを参照してください。
その他のリソース
- モデル サービング エンドポイントを管理する。
- Mosaic AI Model Serving の外部モデル。
- Python を使用する場合は、Databricks リアルタイムサービス Python SDKを使用できます。
ノートブックの例
以下のノートブックには、モデル サービング エンドポイントを起動して実行するために使用できるさまざまな Databricks の登録モデルが含まれています。 その他の例については、「チュートリアル: カスタム モデルをデプロイしてクエリを実行する」を参照してください。
「ノートブックをインポートする」の指示に従ってモデルの例をワークスペースにインポートできます。 いずれかの例からモデルを選択して作成した後、Unity カタログに登録 しモデルを提供するための UI ワークフロー の手順に従います。