レコメンダー モデルをトレーニングする
この記事には、Azure Databricks におけるディープラーニングベースのレコメンデーション モデルの例が 2 つ含まれています。 ディープ ラーニング モデルでは、従来のレコメンデーション モデルよりも質の高い結果を得られるほか、スケーリングによってより多くのデータに対応できます。 これらのモデルが進化を続ける中、Databricks には、大規模なレコメンデーション モデルを効果的にトレーニングするためのフレームワークが用意されており、数億人のユーザーを処理することができます。
一般的なレコメンデーション システムは、次の図に示すステージを含むファネルとして捉えることができます。
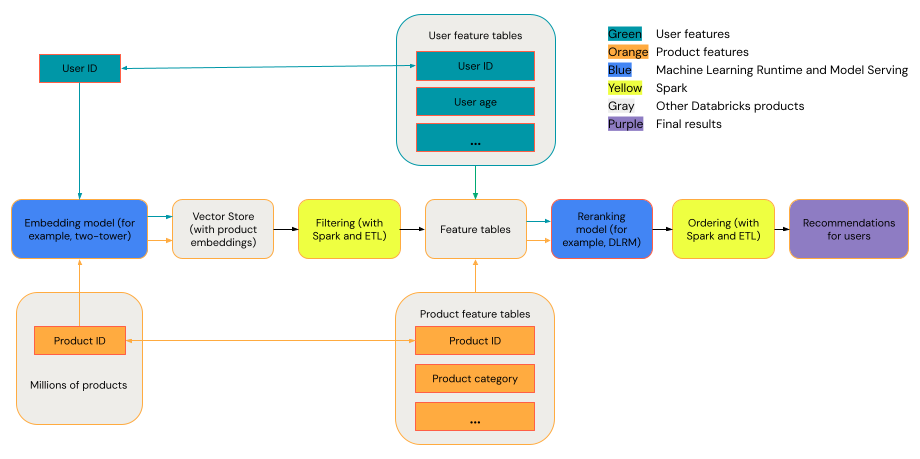
2 タワー モデルなど、一部のモデルは、取得モデルとして優れたパフォーマンスを発揮します。 このようなモデルは小さく、何百万ものデータ ポイントで効果的に動作できます。 DLRM や DeepFM など、再ランク付けモデルとして優れたパフォーマンスを発揮するモデルもあります。 こうしたモデルは、より多くのデータを取り込むことができます。サイズも大きく、きめ細かなレコメンデーションを提供できます。
要件
Databricks Runtime 14.3 LTS ML
ツール
この記事の例では、次のツールを使用しています。
- TorchDistributor: TorchDistributor は、大規模な PyTorch モデル トレーニングを、Databricks で実行できるようにするフレームワークです。 オーケストレーションに Spark を使用して、クラスターで使用可能な数の GPU にスケーリングできます。
- Mosaic StreamingDataset: StreamingDataset は、プリフェッチやインターリーブなどの機能を使用して、Databricks 上の大規模なデータセットに対するトレーニングのパフォーマンスとスケーラビリティを向上させます。
- MLflow: Mlflow を使用すると、パラメーター、メトリック、およびモデル チェックポイントを追跡できます。
- TorchRec: 最新のレコメンダー システムでは、埋め込みルックアップ テーブルを使用することで、何百万ものユーザーと項目を処理し、高品質のレコメンデーションを生成します。 埋め込みサイズを大きくすると、モデルのパフォーマンスが向上しますが、大量の GPU メモリとマルチ GPU の設定が必要になります。 TorchRec には、複数の GPU 間でレコメンデーション モデルとルックアップ テーブルをスケーリングするフレームワークが用意されており、大規模な埋め込みに最適です。
例: 2 タワー モデル アーキテクチャを使用した映画のレコメンデーション
2 タワー モデルは、ユーザーデータと項目データを個別に処理してから組み合わせることで、大規模なパーソナル化タスクを処理するように設計されています。 これは、数百または数千の十分な品質のレコメンデーションを、効率的に生成することができます。 このモデルでは一般的に 3 つの入力、つまり user_id 特徴、product_id 特徴、そして <user, product> インタラクションが肯定的だったか (ユーザーが製品を購入)、否定的だったか (ユーザーが製品に星 1 つとして評価) を定義するバイナリ ラベルが想定されています。 モデルの出力は、ユーザーと項目の両方の埋め込みであり、一般的にはこれを組み合わせて (多くの場合、ドット積またはコサインの類似度を使用)、ユーザーと項目のインタラクションを予測します。
2 タワー モデルでは、ユーザーと製品の両方に対して埋め込みが提供されるため、こうした埋め込みをベクトル データベース (Databricks Vector Store など) に配置し、類似性検索のような操作をユーザーと項目に対して実行できます。 たとえば、すべての項目をベクトル ストアに配置し、そのベクトル ストアに対してユーザーごとにクエリを実行して、埋め込みがユーザーのものと類似している上位 100 件の項目を見つけることができます。
次のノートブックの例では、"Learning from Sets of Items" データセットを使用して、2 タワー モデル トレーニングを実装し、ユーザーが特定の映画を高く評価する可能性を予測します。 分散データの読み込みには Mosaic StreamingDataset、分散モデル トレーニングには TorchDistributor、モデルの追跡とログには Mlflow が使用されます。
2 タワー レコメンダー モデル ノートブック
このノートブックは、Databricks Marketplace でも使用できます: 2 タワー モデル ノートブック
Note
- two-tower モデルの入力は、ほとんどの場合、カテゴリ特徴量である user_id と product_id となります。 このモデルは、ユーザーと製品の両方に対する複数の特徴量ベクトルをサポートするように変更できます。
- two-tower モデルの出力は、通常、ユーザーが製品を操作した感想が肯定的であるか否定的であるかを示すバイナリ値です。 このモデルは、回帰、多クラス分類、(無視や購入などの) 複数のユーザー アクションの確率などのその他の応用向けに変更できます。 目標が競合すると、モデルによって生成される埋め込みの品質が低下する可能性があります。このため複雑な出力は慎重に実装する必要があります。
例: 合成データセットを使用して DLRM アーキテクチャをトレーニングする
DLRM は、パーソナル化とレコメンデーション システム専用に設計された最先端のニューラル ネットワーク アーキテクチャです。 これはカテゴリ入力と数値入力を組み合わせて、ユーザーと項目のインタラクションを効果的にモデル化し、ユーザーの好みを予測します。 一般的に、DLRM では、スパース特徴 (ユーザー ID、項目 ID、地理的な場所、製品カテゴリなど) と高密度特徴 (ユーザーの年齢や品目の価格など) の両方を含む入力が想定されます。 DLRM の出力は、通常、クリックスルー率や購入の可能性など、ユーザー エンゲージメントの予測です。
DLRM は、大規模なデータを処理できる高度にカスタマイズ可能をフレームワークを提供しており、さまざまなドメインにわたる複雑なレコメンデーション タスクに適しています。 2 タワー アーキテクチャよりも大きなモデルであるため、再ランク付けステージでよく使用されます。
次のノートブック例では、高密度 (数値) 特徴量とスパース (カテゴリ) 特徴量を使用してバイナリ ラベルを予測する DLRM モデルを構築します。 モデルのトレーニングには合成データセット、分散データ読み込みには Mosaic StreamingDataset、分散モデル トレーニングには TorchDistributor、モデル追跡とログには Mlflow が使用されます。
DLRM ノートブック
このノートブックは、Databricks Marketplace でも使用できます: DLRM ノートブック。
2 タワーモデルと DLRM モデルの比較
次の表に、使用するレコメンダー モデルを選択するためのガイドラインをいくつか示します。
| モデル タイプ | トレーニングに必要なデータセット サイズ | モデルのサイズ | サポートされている入力の種類 | サポートされている出力の種類 | ユース ケース |
|---|---|---|---|---|---|
| 2 タワー | 縮小 | 縮小 | 通常は 2 つの特徴 (user_id、product_id) | 主にバイナリ分類と埋め込みの生成 | 数百または数千の考えられるレコメンデーションの生成 |
| DLRM | 大きい | 大きい | さまざまなカテゴリ別特徴と高密度特徴 (user_id、gender、geographic_location、product_id、product_category など) | 多クラス分類、回帰、その他 | きめ細かな取得 (関連性の高い数十の項目のレコメンデーション) |
まとめると、2 タワー モデルは、質の高い何千ものレコメンデーションを非常に効率よく生成するのに最適です。 例としては、ケーブル プロバイダーからの映画のレコメンデーションなどが考えられます。 DLRM モデルは、より多くのデータに基づいて非常に具体的なレコメンデーションを生成するのに適しています。 例としては、顧客に対して、その顧客が購入する可能性の高い少数の品目を提示したいと考えている小売業者などが考えられます。