Delta テーブルのストリーミング読み取りと書き込み
Delta Lake は、readStream および writeStream を介して Spark の構造化ストリーミングと深く統合されています。 Delta Lake では、ストリーミング システムおよびファイルに関連する一般的な制限の多くを克服しています。次に例を示します。
- 低待機時間の取り込みによって生成される小さなファイルを結合する。
- 複数のストリーム (または同時バッチ ジョブ) により "厳密に 1 回" の処理を維持する。
- ファイルをストリームのソースとして使用するときに新しいファイルを効率的に検出する。
Note
この記事では、ストリーミング ソースとシンクとして Delta Lake テーブルを使用する方法について説明します。 Databricks SQL でストリーミング テーブルを使用してデータを読み込む方法については、「Databricks SQL でストリーミング テーブルを使用してデータを読み込む」を参照してください。
Delta Lake によるストリーム静的結合の詳細については、ストリーム静的結合に関するページを参照してください。
ソースとしての Delta テーブル
構造化ストリーミングでは、Delta テーブルの増分読み取りが実行されます。 Delta テーブルに対してストリーミング クエリがアクティブである間、新しいテーブル バージョンがソース テーブルにコミットされると、新しいレコードがべき等に処理されます。
次のコード例は、テーブル名またはファイル パスのいずれかを使用してストリーミング読み取りを構成する方法を示しています。
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
重要
Delta テーブルに対してストリーミング読み取りが開始した後にテーブルのスキーマが変更された場合、クエリは失敗します。 ほとんどのスキーマ変更では、ストリームを再開してスキーマの不一致を解決し、処理を続行できます。
Databricks Runtime 12.2 LTS 以前では、列マッピングが有効になっており、列の名前変更や削除のように追加を伴わないスキーマの展開が行われた Delta テーブルからはストリーミングを行えません。 詳細については、「列マッピングとスキーマの変更が伴うストリーミング」を参照してください。
入力レートを制限する
マイクロバッチを制御するために、次のオプションを使用できます。
maxFilesPerTrigger: すべてのマイクロバッチで考慮される新しいファイルの数。 既定値は 1000 です。maxBytesPerTrigger: 各マイクロバッチで処理されるデータの量。 このオプションにより "ソフト最大値" が設定されます。これは、最小の入力単位がこの制限を超える場合にストリーミング クエリを進めるために、バッチでほぼこの量のデータが処理され、制限を超える処理が行われる可能性があることを意味します。 これは既定では設定されません。
maxBytesPerTrigger を maxFilesPerTrigger と組み合わせて使用すると、マイクロバッチでは maxFilesPerTrigger または maxBytesPerTrigger の制限に達するまでデータを処理します。
Note
logRetentionDuration 構成によって ソース テーブル トランザクションがクリーンアップされ、ストリーミング クエリがそれらのバージョンの処理を試みる場合、既定では、クエリはデータ損失を回避できません。 オプション failOnDataLoss を false に設定すると、失われたデータを無視して処理を続行できます。
Delta Lake の変更データ キャプチャ (CDC) フィードをストリーミングする
Delta Lake の変更データ フィードでは、更新や削除などの、Delta テーブルへの変更が記録されます。 有効にすると、変更データ フィードからストリーミングし、挿入、更新、および削除を処理するロジックをダウンストリーム テーブルに書き込むことができます。 変更データ フィードのデータ出力は、それが記述する Delta テーブルとは若干異なりますが、これにより、メダリオン アーキテクチャのダウンストリーム テーブルに増分変更を伝達するソリューションが提供されます。
重要
Databricks Runtime 12.2 LTS 以前では、列マッピングが有効になっており、列の名前変更や削除のように追加を伴わないスキーマの展開が行われた Delta テーブルの変更データ フィードからはストリーミングを行えません。 「列マッピングとスキーマの変更が伴うストリーミング」を参照してください。
更新と削除を無視する
構造化ストリーミングでは、ソースとして使用されているテーブルに変更が発生した場合、追加ではない入力は処理せず、例外をスローします。 ダウンストリームに自動的に反映できない変更を処理するための主な戦略は 2 つあります。
- 出力とチェックポイントを削除し、最初からストリームを再起動できます。
- これらの 2 つのオプションのいずれかを設定できます。
ignoreDeletes: パーティション境界のデータを削除するトランザクションを無視します。skipChangeCommits: 既存のレコードを削除または変更するトランザクションを無視します。skipChangeCommitsはignoreDeletesを含みます。
Note
Databricks Runtime 12.2 LTS 以降の skipChangeCommits では、以前の設定 ignoreChanges が非推奨になります。 Databricks Runtime 11.3 LTS 以前では、ignoreChanges のみがサポートされているオプションです。
ignoreChanges のセマンティクスは skipChangeCommits とは大きく異なります。 ignoreChanges を有効にすると、ソース テーブル内の書き換えられたデータ ファイルは、UPDATE、MERGE INTO、DELETE (パーティション内)、OVERWRITE などのデータ変更操作の後に再出力されます。 変更されていない行は、多くの場合、新しい行と共に出力されるため、ダウンストリームのコンシューマーが重複を処理できる必要があります。 削除はダウンストリームには反映されません。 ignoreChanges は ignoreDeletes を含みます。
skipChangeCommits では、ファイルの変更操作は完全に無視されます。 UPDATE、MERGE INTO、DELETE、OVERWRITE などのデータ変更操作のためにソース テーブルで書き換えられたデータ ファイルは完全に無視されます。 アップストリームのソース テーブルでの変更を反映するには、これらの変更を伝達するための個別のロジックを実装する必要があります。
ignoreChanges を使用して構成されたワークロードは引き続き既知のセマンティクスを使用して動作しますが、Databricks では、すべての新しいワークロードに skipChangeCommits を使用することをお勧めします。 ignoreChanges を使用してワークロードを skipChangeCommits に移行するには、リファクタリング ロジックが必要です。
例
たとえば、date によってパーティション分割された date、user_email、action 列を持つテーブル user_events があるとします。 user_events テーブルからストリーム出力し、GDPR のためにテーブルからデータを削除する必要があります。
パーティションの境界 (つまり、WHERE がパーティション列にある) で削除すると、ファイルは既に値でセグメント化されています。そのため、削除によってメタデータからそれらのファイルが削除されるだけになります。 データのパーティション全体を削除する場合は、次を使用できます。
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
複数のパーティション (この例では user_email でのフィルター処理) のデータを削除する場合は、次の構文を使用します。
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
user_email を UPDATE ステートメントで更新すると、問題の user_email を含むファイルが書き換えられます。 変更されたデータ ファイルを無視するには、skipChangeCommits を使用します。
初期位置を指定する
次のオプションを使用すると、テーブル全体を処理せずに Delta Lake ストリーミング ソースの開始点を指定できます。
startingVersion: 対象となる最初の Delta Lake バージョン。 Databricks では、ほとんどのワークロードに対してこのオプションを省略することを推奨しています。 設定されていない場合、ストリームは、テーブルのその時点で完全なスナップショットなど、使用可能な最新のバージョンから開始されます。指定されている場合、ストリームでは、指定されたバージョン (これを含む) 以降の、Delta テーブルに対するすべての変更が読み取られます。 指定されたバージョンが使用できなくなっている場合、ストリームは開始できません。 コミット バージョンは、DESCRIBE HISTORY コマンド出力の
version列から取得できます。最新の変更のみを返すには、
latestを指定します。startingTimestamp: 対象となる最初のタイムスタンプ。 このタイムスタンプと同時点またはそれ以降にコミットされたすべてのテーブル変更は、ストリーミングの閲覧者によって読み取られます。 指定されたタイムスタンプがすべてのテーブル コミットよりも前である場合、ストリーミングの読み取りは、取得可能な最も古いタイムスタンプから始まります。 次のいずれか:- タイムスタンプ文字列。 たとえば、「
"2019-01-01T00:00:00.000Z"」のように入力します。 - 日付文字列。 たとえば、「
"2019-01-01"」のように入力します。
- タイムスタンプ文字列。 たとえば、「
両方のオプションを同時に設定することはできません。 これらは、新しいストリーミング クエリを開始するときにのみ有効になります。 ストリーミング クエリが開始され、進行状況がチェックポイントに記録されている場合、これらのオプションは無視されます。
重要
指定したバージョンまたはタイムスタンプからストリーミング ソースを開始することもできますが、ストリーミング ソースのスキーマは常に Delta テーブルの最新のスキーマです。 指定したバージョンまたはタイムスタンプの後に Delta テーブルに対する互換性のないスキーマ変更がないことを確認する必要があります。 そうしないと、スキーマが正しくないデータを読み取る際に、ストリーミング ソースから正しくない結果が返される可能性があります。
例
たとえば、user_events というテーブルがあるとします。 バージョン 5 以降の変更を読み取る場合は、次を使用します。
spark.readStream
.option("startingVersion", "5")
.table("user_events")
2018-10-18 以降の変更を読み取る場合は、次を使用します。
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
データが削除されないようにして初期スナップショットを処理する
Note
この機能は、Databricks Runtime 11.3 LTS 以降で使用できます。 この機能はパブリック プレビュー段階にあります。
Delta テーブルをストリーム ソースとして使用する場合、クエリでは最初に、テーブルにあるすべてのデータを処理します。 このバージョンの Delta テーブルが、初期スナップショットと呼ばれます。 既定では、Delta テーブルのデータ ファイルは、最後に変更されたファイルに基づいて処理されます。 ただし、最後の変更時刻は、必ずしもレコードのイベント時間順序を表すわけではありません。
ウォーターマークが定義されているステートフル ストリーミング クエリでは、変更時刻によってファイルを処理すると、レコードが間違った順序で処理される可能性があります。 これにより、レコードがウォーターマークによって遅延イベントとして削除されるおそれがあります。
データ削除の問題を防ぐには、次のオプションを有効にします。
- withEventTimeOrder: 初期スナップショットをイベント時間の順序で処理する必要があるかどうか。
イベント時間の順序を有効にすると、初期スナップショット データのイベント時間範囲がタイム バケットに分割されます。 各マイクロ バッチでは、その時間範囲内のデータをフィルター処理して 1 つのバケットを処理します。 この場合も、マイクロバッチ サイズを制御するために maxFilesPerTrigger と maxBytesPerTrigger 構成オプションを適用できますが、処理の性質上、方法はおおまかなものとなります。
次の図は、このプロセスを示しています。
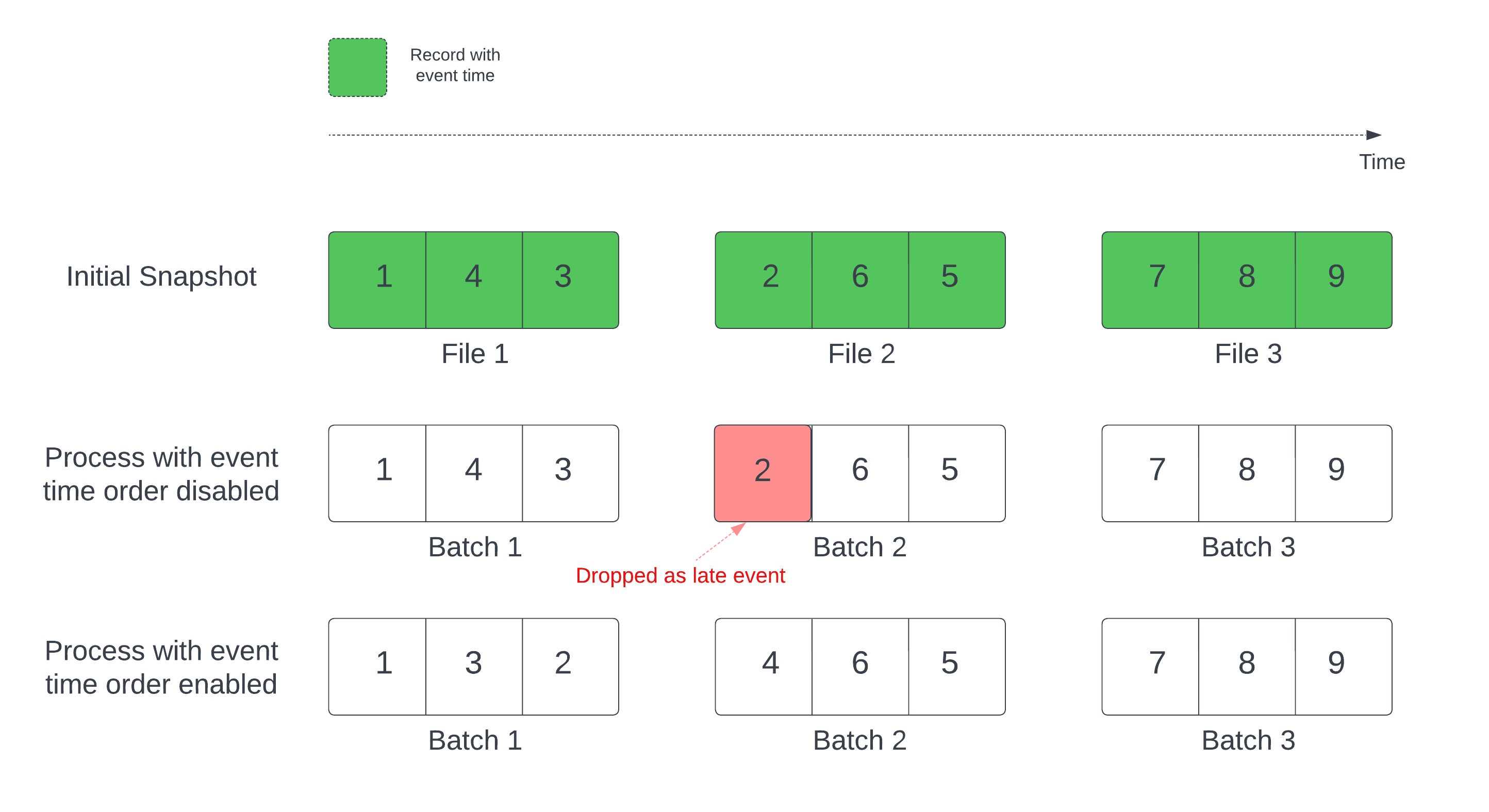
この機能に関して注意が必要な情報を次に示します。
- データ削除の問題は、ステートフル ストリーミング クエリの最初の Delta スナップショットが既定の順序で処理された場合にだけ発生します。
withEventTimeOrderは、初期スナップショットの処理中にストリーム クエリを開始した後は変更できません。withEventTimeOrderを変更して再起動するには、チェックポイントを削除する必要があります。- withEventTimeOrder を有効にしてストリーム クエリを実行している場合、初期スナップショットの処理が完了するまでは、この機能をサポートしない DBR バージョンにダウングレードすることはできません。 ダウングレードが必要な場合は、初期スナップショットが完了するのを待つか、チェックポイントを削除してクエリを再起動できます。
- この機能は、次のような一般的でないシナリオではサポートされません。
- イベント時間列が生成された列であり、Delta ソースとウォーターマークの間に非プロジェクション変換が存在する。
- ストリーム クエリに複数の Delta ソースを含むウォーターマークがある。
- イベント時間順序を有効にすると、Delta 初期スナップショットの処理のパフォーマンスが低下するおそれがあります。
- 各マイクロ バッチでは、初期スナップショットをスキャンして、対応するイベント時間範囲内のデータをフィルター処理します。 フィルター アクションを高速にするには、データ スキップを適用できるように (いつ適用できるかについては「Delta Lake に対するデータのスキップ」を参照してください)、Delta ソース列をイベント時間として使用することをお勧めします。 さらに、イベント時間列に沿ってテーブルをパーティション分割すると、処理がさらに高速になります。 Spark UI を調べると、特定のマイクロ バッチでスキャンされた Delta ファイルの数を確認できます。
例
event_time 列を含むテーブル user_events があるとします。 ストリーミング クエリは集計クエリです。 初期スナップショットの処理中にデータが削除されないようにする場合は、次を使用できます。
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
注意
これは、すべてのストリーミング クエリ spark.databricks.delta.withEventTimeOrder.enabled true に適用される、クラスター上の Spark 構成で有効にすることもできます。
シンクとしてのデルタ テーブル
構造化ストリーミングを使用して、Delta テーブルにデータを書き込むこともできます。 トランザクション ログによって、テーブルに対して他のストリームやバッチ クエリが同時に実行されている場合でも、Delta Lake では厳密に 1 回の処理を保証できます。
注意
Delta Lake の VACUUM 関数は、Delta Lake で管理されていないすべてのファイルを削除しますが、_ で始まるディレクトリはスキップします。 <table-name>/_checkpoints などのディレクトリ構造を使用して、Delta テーブルの他のデータおよびメタデータと共にチェックポイントを安全に保存できます。
メトリック
ストリーミング クエリ プロセスでまだ処理されていないバイト数とファイル数を numBytesOutstanding および numFilesOutstanding メトリックとして確認できます。 その他のメトリックは次のとおりです。
numNewListedFiles: このバッチのバックログを計算するために一覧表示された Delta Lake ファイルの数。backlogEndOffset: バックログの計算に使用されたテーブル バージョン。
ノートブックでストリームを実行している場合、これらのメトリックは、ストリーミング クエリの進行状況ダッシュボードの [生データ] タブに表示されます。
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
追加モード
既定では、ストリームは追加モードで実行され、新しいレコードがテーブルに追加されます。
次の例のように、テーブルにストリーミングする場合は、 toTable メソッドを使用します。
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
完全モード
構造化ストリーミングを使用して、テーブル全体をバッチに置き換えることもできます。 使用例の 1 つに、集計を使用して概要を計算する場合があります。
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
上記の例では、顧客別のイベントの集計数を含むテーブルが継続的に更新されます。
待ち時間の要件が比較的緩いアプリケーションでは、1 回限りのトリガーを使用してコンピューティング リソースを節約できます。 これらを使用して、特定のスケジュールでサマリー集計テーブルを更新し、前回の更新以降に到着した新しいデータのみを処理します。
foreachBatch を使用したストリーミング クエリからの upsert
merge と foreachBatch の組み合わせを使用して、ストリーミング クエリから Delta テーブルに複雑な upsert を書き込むことができます。 foreachBatch を使用した任意のデータ シンクへの書き込みに関するページを参照してください。
このパターンには、次のような多くのアプリケーションがあります。
- 更新モードでストリーミング集計を書き込む: これは、完全モードよりもはるかに効率的です。
- データベース変更のストリームを Delta テーブルに書き込む: 変更データを書き込むマージ クエリを
foreachBatchで使用して、変更のストリームを Delta テーブルに継続的に適用できます。 - 重複排除を使用して Delta テーブルにデータ ストリームを書き込む: 重複排除のための挿入専用マージ クエリを
foreachBatchで使用すると、自動的に重複排除しながらデータを Delta テーブルに (重複を含めて) 継続的に書き込むことができます。
注意
- ストリーミング クエリを再起動すると、同じデータのバッチに対して操作を複数回適用できるので、
foreachBatch内のmergeステートメントがべき等である必要があります。 foreachBatchでmergeを使用している場合、ストリーミング クエリのデータ入力速度 (StreamingQueryProgressを介してレポートされ、ノートブックの速度グラフで表示されます) は、ソースでデータが生成される実際の速度の倍数として報告されることがあります。 これは、mergeが入力データを複数回読み取り、入力メトリックが乗算されたためです。 これがボトルネックである場合は、mergeの前にバッチ DataFrame をキャッシュしてから、mergeの後でキャッシュを解除できます。
foreachBatch 内で SQL を使用してこのタスクを実行する方法を次の例に示します。
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
次の例のように、Delta Lake API を使用して upsert のストリーミングを実行することもできます。
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
foreachBatch でのべき等テーブルの書き込み
Note
Databricks では、更新するシンクごとに個別のストリーミング書き込みを構成することを推奨しています。 foreachBatch を使用して複数のテーブルに書き込むと、書き込みがシリアル化されるため、並列処理が減少し、全体的な待機時間が長くなります。
Delta テーブルでは、foreachBatch 内の複数のテーブルへの書き込みをべき等にするための次の DataFrameWriter オプションがサポートされています。
txnAppId: 各 DataFrame 書き込み時に渡すことができる一意の文字列。 たとえば、StreamingQuery ID をtxnAppIdとして使用できます。txnVersion: トランザクション バージョンとして機能する単調に増加する数値。
Delta Lake では、txnAppId と txnVersion の組み合わせを使用して重複する書き込みを識別し、それらを無視します。
バッチ書き込みがエラーで中断された場合、バッチを再実行すると、同じアプリケーションとバッチ ID が使用されます。これは、重複する書き込みをランタイムで正しく識別して無視するのに役立ちます。 アプリケーション ID (txnAppId) は、ユーザーが生成した一意の文字列にすることができ、ストリーム ID に関連付ける必要はありません。 foreachBatch を使用した任意のデータ シンクへの書き込みに関するページを参照してください。
警告
ストリーミング チェックポイントを削除し、新しいチェックポイントでクエリを再起動する場合、別の txnAppIdを指定する必要があります。 新しいチェックポイントは、バッチ ID 0 で始まります。 Delta Lake では、バッチ ID と txnAppIdを一意のキーとして使用し、既に確認されている値を持つバッチをスキップします。
次のコード例は、このパターンを示しています。
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}