geo レプリケーション (パブリック プレビュー)
Azure Event Hubs には、geo ディザスター リカバリーを提供する機能が 2 つ存在します。
- geo ディザスター リカバリー (メタデータ DR) は、メタデータのみのレプリケーションを提供します。
- geo レプリケーション (パブリック プレビュー) は、メタデータとデータの両方のレプリケーションを提供します。
これらの機能を Availability Zones と混同しないでください。 どちらの地理的リカバリー機能も、米国東部と米国西部などの複数の Azure リージョン間での回復性を提供します。 可用性ゾーンのサポートは、米国東部などの特定の地理的リージョン内での回復性を提供します。 可用性ゾーンと VM の詳細については、Event Hubs における可用性ゾーンのサポートに関するページを参照してください。
重要
- この機能は現在パブリック プレビュー段階であるため、運用環境のシナリオでは使用しないでください。
- 現在、パブリック プレビューでは以下のリージョンがサポートされています。
| 米国 | ヨーロッパ |
|---|---|
| 米国中部 EUAP | イタリア北部 |
| スペイン中部 | |
| ノルウェー東部 |
メタデータのディザスター リカバリーとメタデータとデータの geo レプリケーション
メタデータ DR 機能は、名前空間の構成情報をプライマリ名前空間からセカンダリ名前空間にレプリケートします。 セカンダリ リージョンへの 1 回限りのフェールオーバーをサポートします。 お客様が開始したフェールオーバー中に、名前空間のエイリアス名がセカンダリ名前空間に再割り当てされ、ペアリングは解除されます。 構成情報以外のデータはレプリケートされず、アクセス許可の割り当てもレプリケートされません。
より新しい geo レプリケーション機能は、構成情報とすべてのデータをプライマリ名前空間から 1 つ以上のセカンダリ名前空間にレプリケートします。 フェールオーバーが実行されると、選択されたセカンダリがプライマリになり、以前のプライマリがセカンダリになります。 ユーザーは、必要に応じて元のプライマリへのフェールオーバーを実行できます。
この記事の残りの部分では、geo レプリケーション機能に焦点を当てます。 メタデータ DR 機能の詳細については、「メタデータのための Event Hubs geo ディザスター リカバリー」を参照してください。
geo レプリケーション
geo レプリケーション機能のパブリック プレビューがサポートされているのは、Event Hubs セルフサービス スケーリング専用クラスターの名前空間に対してです。 この機能は、専用のセルフサービス クラスター内の新規または既存の名前空間で使用できます。 geo レプリケーションでは以下に示す機能はサポートされていません。
- カスタマー マネージド キー (CMK)
- キャプチャ用のマネージド ID
- 仮想ネットワーク機能 (サービス エンドポイントやプライベート エンドポイント)
- 大きなメッセージのサポート (現状のパブリック プレビューにおいて)
- Kafka トランザクション (現状のパブリック プレビューにおいて)
geo データ レプリケーション パブリック プレビューの主な特徴の一部を以下に示します。
- プライマリ セカンダリ レプリケーション モデル – geo レプリケーションはプライマリ セカンダリ レプリケーション モデルを基にしています。このモデルでは、どのような時にもイベント プロデューサーとイベント コンシューマーにサービスを提供するプライマリ名前空間は 1 つしか存在しません。
- Event Hubs は、構成された整合性レベルを使用して、複数のセカンダリにわたってメタデータ、イベント データ、コンシューマー オフセットのフル マネージド バイト間レプリケーションを実行します。
- 安定した名前空間の完全修飾ドメイン名 (FQDN) – 昇格の実行時に FQDN を変更する必要はありません。
- レプリケーションの整合性 - レプリケーションの整合性の設定には同期と非同期の 2 つが存在します。
- セカンダリを新しいプライマにするユーザーによって管理される昇格。
セカンダリの新しいプライマリへの変更は、以下の 2 つの方法で実行されます。
- 計画済み: 新しいプライマリが以前のプライマリ インスタンスによって保持されていたすべてのデータに追いつくまでトラフィックが処理されないセカンダリのプライマリへの昇格。
- 強制: セカンダリが可能な限り早くプライマリになるフェールオーバーとして。 geo レプリケーション機能は、プライマリ リージョンから選択されたセカンダリ リージョンへとすべてのデータとメタデータをレプリケートします。 名前空間 FQDN は常にプライマリ リージョンを指します。
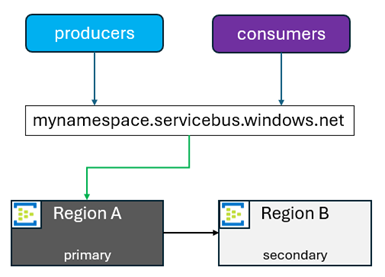
セカンダリの昇格を開始すると、FQDN は新しいプライマリとするために選択されたリージョンを指すようになります。 その後、古いプライマリはセカンダリになります。 フェールオーバー以外の理由でも、セカンダリを新しいプライマリに昇格させることができます。 この理由は、アプリケーションのアップグレード、フェールオーバーのテスト、その他のどのようなことであっても構いません。 そのような状況では、それらのアクティビティが完了したら、元通りに切り替えを行うことが一般的です。
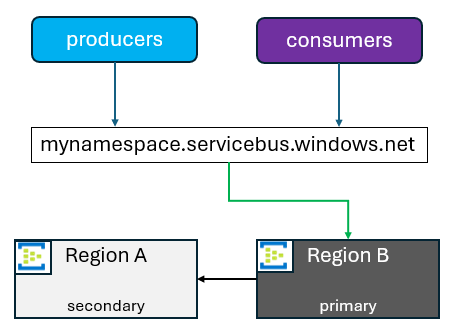
セカンダリ リージョンは、利用者の判断で追加されたり削除されたりします。 現状、以下のようないくつかの制限事項に注意する必要があります。
- セカンダリ リージョンでの読み取り専用ビューをサポートする機能は存在しません。
- 自動昇格/フェールオーバー機能は存在しません。 すべての昇格は、利用者によって開始されます。
- セカンダリ リージョンは、プライマリ リージョンとは異なる必要があります。 同じリージョン内の別の専用クラスターを選択することはできません。
- パブリック プレビューでサポートされているのは 1 つのセカンダリだけです。
レプリケーションの整合性
レプリケーションの整合性の構成には、同期と非同期の 2 つが存在します。 これら 2 つの構成はアプリケーションとデータの整合性に影響を与えるので、これらの違いを理解しておくことが重要です。
非同期レプリケーション
非同期レプリケーションが有効になっている場合、すべてのメッセージはプライマリにコミットされた後、セカンダリに送信されます。 ユーザーは、セカンダリがキャッチアップする必要があるラグ タイムの許容可能量を構成できます。 アクティブなセカンダリのラグがユーザー ラグ構成より大きい場合、プライマリ リージョンは受信発行要求を調整します。
同期に近いレプリケーション
同期レプリケーションが有効になっている場合、発行されたイベントはセカンダリにレプリケートされ、プライマリにコミットされるには、メッセージを確認する必要があります。 同期レプリケーションにおいて、アプリケーションは発行、レプリケーション、確認、コミットを行うのにかかる速度で発行を行います。 これはまた、アプリケーションが両方のリージョンの可用性とも関係することを意味します。 セカンダリ リージョンがダウンすると、メッセージを確認したりコミットすることができません。
レプリケーションの整合性の比較
同期レプリケーションでは:
- 分散コミットにより待機時間が長くなります。
- 可用性は、2 つのリージョンの可用性に関係します。 1 つのリージョンがダウンすると、名前空間は利用できなくなります。
- 受信データは、常に少なくとも 2 つのリージョン内に存在します (初期パブリック プレビューでサポートされているリージョンは 2 つだけです)。
同期レプリケーションは、データが安全であることの最大の保証を提供します。 同期レプリケーションが設定されている状態で、コミットが行われると、geo レプリケーションが構成されたすべてのリージョンでコミットが行われます。 ただし、同期レプリケーションを有効にすると、アプリケーションの可用性は、両方のリージョンの可用性が原因で低下する可能性があります。
非同期レプリケーションを有効にしても待機時間に大きな影響はなく、サービスの可用性はセカンダリ リージョンの喪失の影響を受けません。 非同期レプリケーションでは、同期レプリケーションのようにコミットされる前にすべてのリージョンにデータが含まれるという絶対的な保証はありません。 また、受信トラフィックが調整されるまでセカンダリが非同期になり得る時間を設定することもできます。 この設定は 5 分から 1,440 分 (1 日) にすることができます。 お互いの間の距離が大きいリージョンを使用することを予定している場合は、おそらく非同期レプリケーションが最適な選択肢となります。
レプリケーションの整合性の構成は、geo レプリケーションの構成後に変更することができます。 同期から非同期、または非同期から同期に変更することができます。 同期から非同期に変更する場合、待機時間とアプリケーションの可用性が改善されます。 非同期から同期に変更する場合、セカンダリはラグがゼロになった後に同期の構成になります。 何らかの理由で継続的なラグを伴って実行されている場合は、ラグをゼロにしてモードを同期へと切り替え可能にするためにパブリッシャーを一時停止することが必要な場合があります。
同期レプリケーションを有効にする一般的な理由は、データの重要性、具体的なビジネス ニーズ、コンプライアンス上の理由などに関係します。 主要な目的がデータの保証ではなくアプリケーションの可用性である場合は、おそらく非同期整合性が最適な選択肢となります。
セカンダリ リージョンの選択
geo レプリケーション機能を有効にするには、geo レプリケーション機能が有効になっているプライマリ リージョンとセカンダリ リージョンを使用する必要があります。 また、プライマリ リージョンとセカンダリ リージョンの両方の中に Event Hubs クラスターが既に存在している必要があります。
geo レプリケーション機能は、発行されたイベントをプライマリからセカンダリ リージョンにレプリケートできることに依存しています。 セカンダリ リージョンが別の大陸にある場合、プライマリからセカンダリ リージョンへのレプリケーション ラグには大きな影響が生じます。 可用性と信頼性の理由で geo レプリケーションを使用する場合は、可能な限りはセカンダリ リージョンを少なくとも同じ大陸に配置することをお勧めします。 地理的な距離によって引き起こされる待機時間の理解を深めるには、「Azure ネットワーク ラウンドトリップ待機時間の統計情報 | Microsoft Learn」で詳細を確認してください。
geo レプリケーションの管理
geo レプリケーション機能によって、構成とデータのレプリケーション先のセカンダリ リージョンを構成できます。 次のことを実行できます。
- geo レプリケーションの構成 - セカンダリ リージョンは、geo レプリケーション機能セットが有効になっているリージョン内のセルフサービス専用クラスター内の既存の名前空間上で構成できます。 これは同じ専用クラスターでの名前空間の作成時に構成することもできます。 セカンダリ リージョンを選択するには、そのセカンダリ リージョン内に利用可能な専用クラスターが存在している必要があり、そのセカンダリ リージョンではそのリージョンに対して geo レプリケーション機能セットが有効になっている必要もあります。
- レプリケーションの整合性の構成 - 同期および非同期レプリケーションは geo レプリケーションの構成時に設定されますが、後で切り替えることもできます。 非同期整合性では、セカンダリ リージョンで許容されるラグの時間を構成できます。
- 昇格/フェールオーバーのトリガー - すべての昇格またはフェールオーバーは利用者によって開始されます。 昇格の際には、それを最初から強制にすることを選択したり、昇格の開始後に気を変えて強制にすることもできます。
- セカンダリの削除 - プライマリとセカンダリ リージョンの間の geo ペアリングを削除することが必要になった場合は、いつでもそれを行うことが可能で、セカンダリ リージョン内のデータは削除されます。
データ レプリケーションの監視
ユーザーは、アプリケーション メトリック ログのレプリケーション ラグ メトリックを監視することで、レプリケーション ジョブの進行状況を監視できます。
「Azure Event Hubs の監視 - Azure Event Hubs | Microsoft Learn」に従って Event Hubs 名前空間のアプリケーション メトリック ログを有効にします。
アプリケーション メトリック ログが有効になったら、ログが確認できるようになるまで数分間にわたって名前空間からデータを生成してそれを消費する必要があります。
アプリケーション メトリック ログを表示するには、Event Hubs ページの [監視] セクションに移動し、左側にあるメニューの [ログ] を選択します。 次のクエリを使用することで、プライマリとセカンダリ名前空間の間のレプリケーション ラグ (秒単位) を確認することができます。
AzureDiagnostics | where TimeGenerated > ago(1h) | where Category == "ApplicationMetricsLogs" | where ActivityName_s == "ReplicationLagcount_d列は、プライマリとセカンダリ リージョン間の秒単位のレプリケーション ラグを表しています。
データのパブリッシュ
イベント発行アプリケーションは、geo レプリケートされた名前空間の安定した名前空間 FQDN を介して、geo レプリケートされた名前空間にデータを発行できます。 このイベント発行方法は非 geo DR のケースと同じであり、クライアント アプリケーションに対する変更は必要ありません。
イベントの発行は、以下の状況では利用できない場合があります。
- フェールオーバーの猶予期間中、既存のプライマリ リージョンはイベント ハブに発行された新しいイベントをすべて拒否します。
- プライマリとセカンダリ リージョン間のレプリケーション ラグが最大レプリケーション ラグ期間に達すると、パブリッシャーのイングレス ワークロードが調整される場合があります。 パブリッシャー アプリケーションは、セカンダリ リージョン内の名前空間に直接アクセスすることができません。
データの使用
イベント消費アプリケーションは、geo レプリケートされた名前空間の安定した名前空間 FQDN を使用してデータを消費できます。 フェールオーバーが開始されてから完了するまでの間のコンシューマー操作はサポートされません。
チェックポイント機能/オフセット管理
イベント消費アプリケーションは、単一の名前空間で行う場合と同様に、オフセット管理を維持し続けることができます。
Kafka
オフセットは Event Hubs に直接コミットされるため、オフセットは複数のリージョンにわたってレプリケートされます。 そのため、コンシューマーはプライマリ リージョンで中断した場所から消費を開始できます。
Event Hubs SDK/AMQP
Event Hubs SDK を使用するクライアントは、2024 年 4 月バージョンの SDK にアップグレードする必要があります。 Event Hubs SDK の最新バージョンは、フェールオーバーをサポートし、チェックポイントに対する更新を含んでいます。 このチェックポイントは、Azure Blob Storage やカスタム ストレージ ソリューションなどのチェックポイント ストアを使用してユーザーによって管理されます。 フェールオーバーがある場合は、クライアントがチェックポイント データを取得してメッセージの損失を回避できるように、セカンダリ リージョンからチェックポイント ストアを利用できる必要があります。
価格
Event Hubs 専用クラスターは、geo レプリケーションとは別に価格が設定されます。 Event Hubs Dedicated で geo レプリケーションを使用するには、少なくとも 2 つの専用クラスターを別々のリージョンに配置する必要があります。 geo レプリケーションのセカンダリ インスタンスとして使用される専用クラスターは、その他のワークロードでも使用できます。 geo レプリケーションの料金は、発行帯域幅 * セカンダリ リージョンの数に基づいて計算されます。 geo レプリケーションの料金は、早期パブリック プレビューでは発生しません。
関連するコンテンツ
geo レプリケーション機能の使用方法については、「geo レプリケーションの使用方法」を参照してください。
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示