Azure Firewall のメトリックとアラート
Azure Monitor において、メトリックは特定の時点におけるシステムの何らかの側面を表す数値です。 メトリックは 1 分ごとに収集され、頻繁にサンプリングできるためアラート発信に役立ちます。 アラートは比較的シンプルなロジックで迅速に発生させることができます。
ファイアウォール メトリック
Azure Firewall では、次のメトリックを利用できます。
[Application rules hit count](アプリケーション規則のヒット数) - アプリケーション規則がヒットした回数。
単位: カウント
[Network rules hit count](ネットワーク規則のヒット数) - ネットワーク規則がヒットした回数。
単位: カウント
[処理済みデータ] - 所与の時間枠内でファイアウォールを通過したデータの合計。
単位: バイト
[スループット] - 1 秒間にファイアウォールを通過したデータの率。
[単位]: 1 秒あたりのビット数
[Firewall health state](ファイアウォール正常性状態) - SNAT ポートの可用性に基づいて、ファイアウォールの正常性を示します。
単位: パーセント
このメトリックには次の 2 つのディメンションがあります。
状態:値は [Healthy] (正常)、 [Degraded] (低下)、 [Unhealthy] (異常) のいずれかになります。
理由:ファイアウォールの対応する状態の理由を示します。
SNAT ポートの使用率が > 95% の場合、使い果たされたと見なされ、正常性は 50% で、状態 = 低下、および理由 = SNAT ポート になります。 ファイアウォールによってトラフィックの処理が継続され、既存の接続に影響はありません。 ただし、新しい接続は断続的に確立されない可能性があります。
SNAT ポートの使用率が 95% 未満の場合、ファイアウォールは正常と見なされ、正常性は 100% として表示されます。
SNAT ポートの使用が報告されない場合、正常性は 0% として表示されます。
[SNAT port utilization](SNAT ポート使用率) - ファイアウォールによって使用されている SNAT ポートの割合。
単位: パーセント
ファイアウォールにパブリック IP アドレスを追加すると、より多くの SNAT ポートが使用可能になり、SNAT ポートの使用率が低下します。 さらに、さまざまな理由 (CPU やスループットなど) に応じてファイアウォールをスケールアウトすると、追加の SNAT ポートも使用できるようになります。 実際には、サービスがスケールアウトされると、パブリック IP アドレスを追加しなくても、SNAT ポートの使用率の割合が低下する可能性があります。使用可能なパブリック IP アドレスの数を直接制御して、ファイアウォールで使用可能なポートを増やすことができます。 ただし、ファイアウォールのスケーリングを直接制御することはできません。
ファイアウォールで SNAT ポートの枯渇が起きている場合は、少なくとも 5 つのパブリック IP アドレスを追加する必要があります。 これにより、使用可能な SNAT ポートの数が増えます。 詳細については、Azure Firewall の機能に関するページをご覧ください。
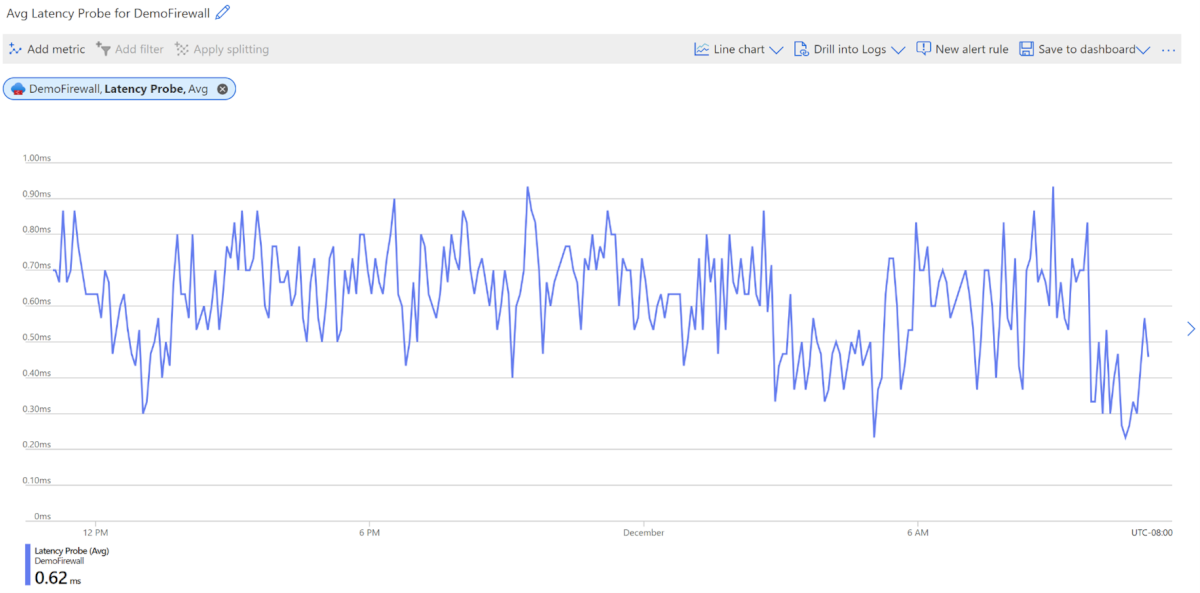
AZFW 待機時間プローブ - Azure Firewall の平均待機時間を推定します。
単位: ms
このメトリックでは、Azure Firewall の全体的または平均的な待機時間をミリ秒単位で測定します。 管理者は、次の目的でこのメトリックを使用できます。
ネットワークの待機時間の原因が Azure Firewall にあるかどうかを診断する
待機時間やパフォーマンスの問題があるかどうかを監視してアラートを生成し、IT チームが積極的に関与できるようにする。
さまざまな理由により、Azure Firewall で待機時間が長くなることがあります。 たとえば、CPU 使用率やスループットが高い、またはネットワークの問題が発生している可能性があります。
このメトリックを使用しても、特定のネットワーク パスのエンドツーエンドの待機時間は測定されません。 言い換えると、この待機時間の正常性プローブを使用しても、Azure Firewall で追加される待機時間は測定されません。
待機時間メトリックが想定どおりに機能していない場合は、メトリック ダッシュボードに値 0 が表示されます。
参考までに、ファイアウォールの想定される平均待機時間は、約 1 ms です。 これは、デプロイのサイズと環境によって異なる場合があります。
待機時間プローブは、Microsoft の Ping Mesh テクノロジに基づいています。 そのため、待機時間メトリックには断続的なスパイクが予想されます。 これらのスパイクは正常であり、Azure Firewall に関する問題を示しているわけではありません。 これらは、システムをサポートする標準のホスト ネットワーク セットアップの一部です。
その結果、一般的なスパイクよりも長時間続く一貫した長い待機時間が発生する場合は、サポートを受けられるようサポート チケットを提出することを検討してください。
Azure Firewall メトリックに関するアラート
メトリックは、リソースの正常性を追跡するための重要なシグナルを提供します。 そのため、リソースのメトリックを監視し、異常がないか注意することが重要です。 しかし、Azure Firewall メトリックのフローが停止した場合はどうすればよいですか? これは、潜在的な構成の問題や、障害のようなもっと険悪なものを示している可能性があります。 メトリックが見つからない原因は、Azure Firewall によるメトリックのアップロードをブロックする既定のルートの発行や、正常なインスタンスの数が 0 に減ったことである可能性があります。 このセクションでは、Log Analytics ワークスペースにメトリックを構成し、メトリックの欠落に関するアラートを生成する方法について説明します。
Log Analytics ワークスペースに対してメトリックを構成する
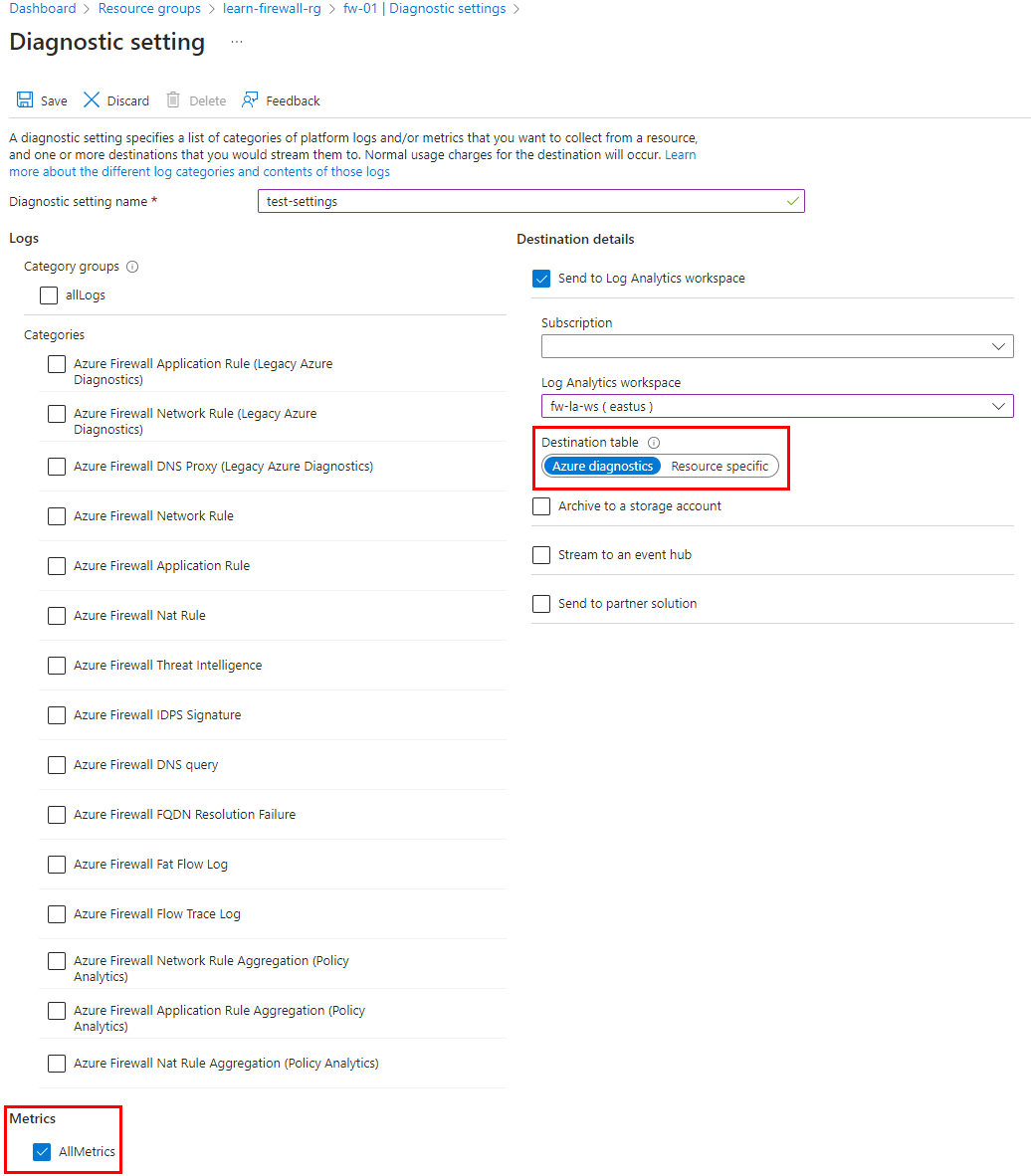
最初の手順では、ファイアウォールの診断設定を使用して、Log Analytics ワークスペースに対するメトリックの可用性を構成します。
次のスクリーンショットに示すように、Azure Firewall リソース ページを参照して診断設定を構成します。 これにより、構成されたワークスペースにファイアウォール メトリックがプッシュされます。
Note
メトリックの診断設定は、ログとは別の構成である必要があります。 ファイアウォール ログは、Azure Diagnostics またはリソース固有を使用するように構成できます。 ただし、ファイアウォール メトリックでは常に Azure Diagnostics を使用する必要があります。
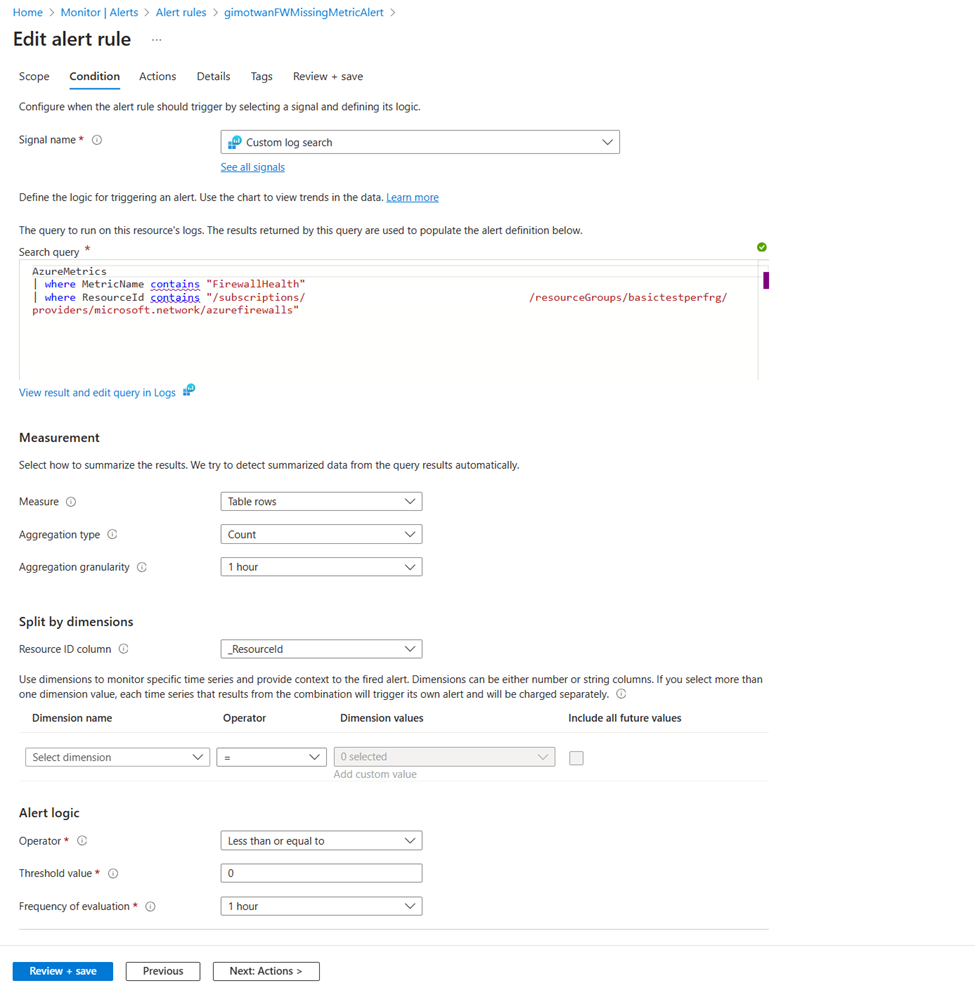
アラートを作成して、エラーなしでファイアウォール メトリックの受信を追跡する
メトリック診断設定で構成されているワークスペースを参照します。 次のクエリを使用して、メトリックが使用可能かどうかを確認します。
AzureMetrics
| where MetricName contains "FirewallHealth"
| where ResourceId contains "/SUBSCRIPTIONS/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/RESOURCEGROUPS/PARALLELIPGROUPRG/PROVIDERS/MICROSOFT.NETWORK/AZUREFIREWALLS/HUBVNET-FIREWALL"
| where TimeGenerated > ago(30m)
次に、60 分間を超えるメトリックの欠落に対するアラートを作成します。 Log Analytics ワークスペースのアラート ページを参照して、メトリックの欠落に関する新しいアラートを設定します。