AKS 上の HDInsight 上の Apache Flink® クラスターにおける Table API と SQL
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加使用条件」に記載されています。 この特定のプレビューの詳細については、「Azure HDInsight on AKS のプレビュー情報」を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティのフォローをお願いいたします。
Apache Flink には、統合ストリームとバッチ処理用の 2 つのリレーショナル API (Table API と SQL) が用意されています。 Table API は、選択、フィルター、結合などの関係演算子からのクエリを直感的に構成できる、統合言語クエリ API です。 Flinkの SQL サポートは、SQL 標準を実装する Apache Calcite に基づいています。
Table API と SQL のインターフェイスは、相互に、および Flink の DataStream API とシームレスに統合されています。 これらに基づいて構築されている、すべての API とライブラリを簡単に切り替えることができます。
Apache Flink SQL
他の SQL エンジンと同様に、Flink クエリはテーブル上で動作します。 Flink では保存データがローカルで管理されず、代わりに、そのクエリは外部テーブルに対して継続的に動作するため、従来のデータベースとは異なります。
Flink データ処理パイプラインは、ソース テーブルで始まり、シンク テーブルで終わります。 ソース テーブルでは、クエリの実行中に操作される行が生成されます。これらは、クエリの FROM 句で参照されるテーブルです。 コネクタには、HDInsight Kafka、HDInsight HBase、Azure Event Hubs、データベース、ファイルシステム、またはクラスパスにコネクタがあるその他のシステムの種類を使用できます。
AKS クラスターでの HDInsight での Flink SQL クライアントの使用
Azure portal で Secure Shell から CLI を使用する方法についてのこの記事を参照できます。 開始する方法の簡単なサンプルを次に示します。
SQL クライアントを起動する
./bin/sql-client.shsql-client と共に実行する初期化 SQL ファイルを渡す
./sql-client.sh -i /path/to/init_file.sqlsql-client で構成を設定する
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL では、次の CREATE ステートメントがサポートされます
- CREATE TABLE
- CREATE DATABASE
- CREATE CATALOG
jdbc コネクタを使用して MSSQL に接続するソース テーブルを定義する構文の例を次に示します。CREATE TABLE ステートメントの列の id、name を使用します
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABASE :
CREATE DATABASE students;
CREATE CATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
これらのテーブル上で連続クエリを実行できます
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
ソース テーブルからシンク テーブルに書き出します。
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
依存関係の追加
JAR ステートメントは、ユーザー jar をクラスパスに追加したり、ユーザー jar をクラスパスから削除したり、クラスパスに追加された jar をランタイムで表示したりするために使用されます。
Flink SQL では、次の JAR ステートメントがサポートされます。
- ADD JAR
- SHOW JARS
- REMOVE JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
AKS 上の HDInsight 上の Apache Flink® クラスターの Hive メタストア
カタログでは、データベース、テーブル、パーティション、ビュー、関数などのメタデータと、データベースまたは他の外部システムに格納されているデータにアクセスするために必要な情報を提供します。
HDInsight on AKS の Flink では、2 つのカタログ オプションがサポートされています。
GenericInMemoryCatalog
GenericInMemoryCatalog は、カタログのメモリ内実装です。 すべてのオブジェクトは、SQL セッションの有効期間中のみ使用できます。
HiveCatalog
HiveCatalog は 2 つの目的を果たします。つまり、純粋な Flink メタデータ用の永続的ストレージとして、および既存の Hive メタデータの読み取りと書き込みのインターフェイスとして使用できます。
Note
AKS クラスター上の HDInsight には、Apache Flink 用の Hive メタストアの統合オプションが付属しています。 クラスターの作成時に Hive メタストアを選択できます
Flink データベースを作成してカタログに登録する方法
Azure portal で Secure Shell から CLI を使用して Flink SQL クライアントを開始する方法についてのこの記事を参照できます。
sql-client.shセッションを開始します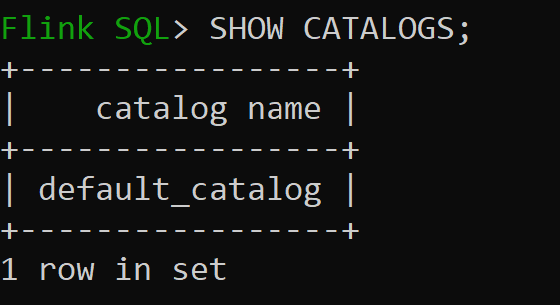
default_catalog は既定のメモリ内カタログです
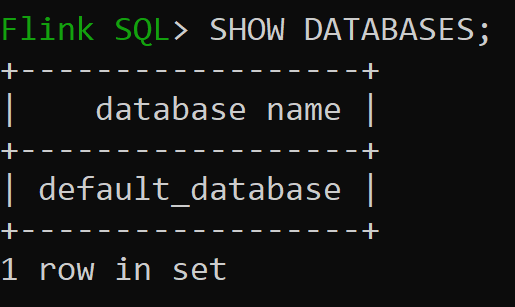
メモリ内カタログの既定のデータベースを確認します
バージョン 3.1.2 の Hive カタログを作成して使用します
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Note
AKS 上の HDInsight では、Hive 3.1.2 と Hadoop 3.3.2 がサポートされています。
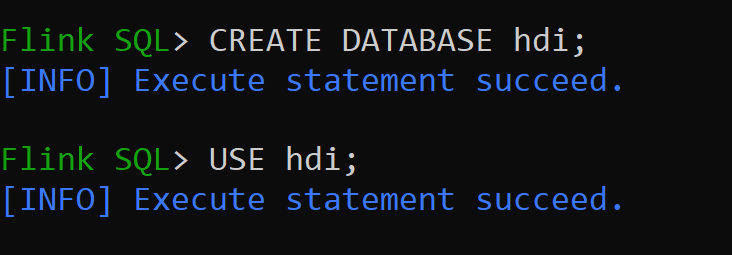
hive-conf-dirは場所/opt/hive-confに設定されますHive カタログにデータベースを作成し、セッションの既定にします (変更されない限り)。
Hive テーブルを作成して Hive カタログに登録する方法
「Flink データベースを作成してカタログに登録する方法」の手順に従います
パーティションのない、コネクタの種類が Hive の Flink テーブルを作成します
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');データを hive_table に挿入します
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';hive_table からデータを読み取ります
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsNote
Hive Warehouse ディレクトリは、Apache Flink クラスターの作成時に選択されたストレージ アカウントの指定されたコンテナーにあり、ディレクトリ hive/warehouse/ から見つけることができます
パーティションのある、コネクタの種類が Hive の Flink テーブルを作成します
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
重要
Apache FLink には既知の制限事項があります。 最後 ‘n’ 列は、ユーザー定義のパーティション列に関係なく、パーティション用に選択されます。 FLINK-32596 Flink 言語を使用して Hive テーブルを作成するときにパーティション キーが間違っています。
リファレンス
- Apache Flink Table API および SQL
- Apache、Apache Flink、Flink、および 関連するオープン ソース プロジェクト名は、Apache Software Foundation (ASF) の商標です。