HDInsight on AKS の Spark クラスターを作成する (プレビュー)
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、Azure HDInsight on AKS のプレビュー情報に関する記事を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティをフォローしてください。
サブスクリプションの前提条件とリソースの前提条件の手順を完了し、クラスター プールがデプロイされたら、引き続き Azure portal を使って Spark クラスターを作成します。 Azure portal を使用して、クラスター プールに Apache Spark クラスターを作成できます。 その後、Jupyter Notebook を作成し、それを使用して、Apache Hive のテーブルに対する Spark SQL クエリを実行することができます。
Azure portal でクラスター プールを入力し、クラスター プールを選択してクラスター プールのページに移動します。 クラスター プールのページで、新しい Spark クラスターを追加できるクラスター プールを選択します。
特定のクラスター プールのページで、[+ New cluster] (+ 新しいクラスター) をクリックします。
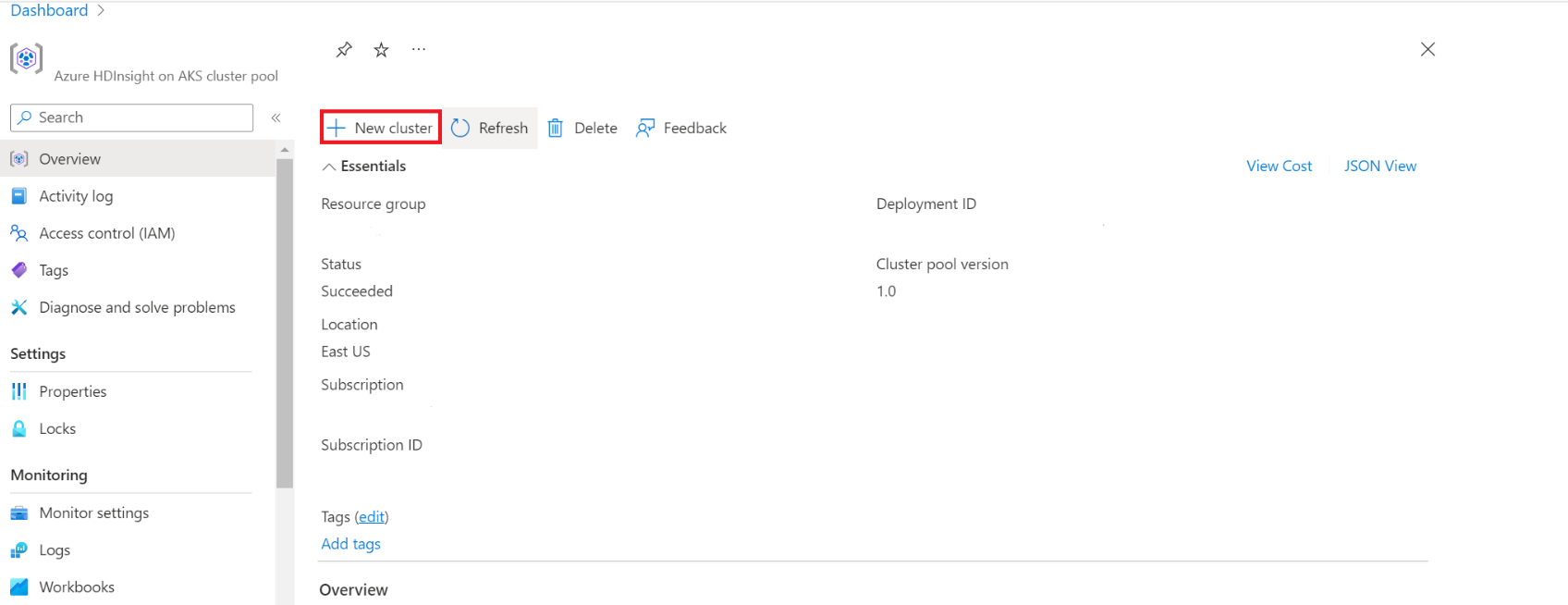
この手順で、クラスターの作成ページが開きます。
![クラスターの作成の [基本] ページを示すスクリーンショット。](media/create-spark-cluster/create-cluster-basic-page.png)
プロパティ 説明 サブスクリプション 前提条件セクションで HDInsight on AKS で使用するために登録された Azure サブスクリプションが事前に設定されます リソース グループ クラスター プールと同じリソース グループが事前に設定されます リージョン クラスター プールと同じリージョンと仮想リージョンが事前に設定されます クラスター プール クラスター プールの名前が事前に設定されます HDInsight プールのバージョン クラスター プールのバージョンは、プール作成の選択から事前に設定されます HDInsight on AKS のバージョン HDI on AKS のバージョンを指定します クラスターの種類 ドロップダウン リストから、Spark を選択します クラスターのバージョン 使用する画像のバージョンのバージョンを選択します クラスター名 新しいクラスターの名前を入力します ユーザー割り当てマネージド ID ストレージとの接続文字列として機能するユーザー割り当てマネージド ID を選択します ストレージ アカウント クラスターのプライマリ ストレージとして使用する事前に作成したストレージ アカウントを選択します コンテナー名 事前に作成したコンテナー名 (一意) を選択するか、新しいコンテナーを作成します Hive カタログ (省略可能) 事前に作成した Hive メタストア (Azure SQL DB) を選択します Hive 用の SQL Database ドロップダウン リストから、hive-metastore テーブルを追加する SQL データベースを選択します。 SQL 管理ユーザー名 SQL 管理者ユーザー名を入力します Key Vault ドロップダウン リストから、SQL 管理者ユーザー名のパスワードとシークレットが含まれる Key Vault を選択します SQL パスワード シークレット名 SQL DB パスワードが格納されている Key Vault からシークレット名を入力します Note
- 現在、HDInsight では MS SQL Server データベースのみがサポートされています。
- Hive の制限により、メタストアのデータベース名で "-" (ハイフン) 文字はサポートされていません。
[Next: Configuration + pricing] (次へ: 構成と価格) を選択して、続行します。
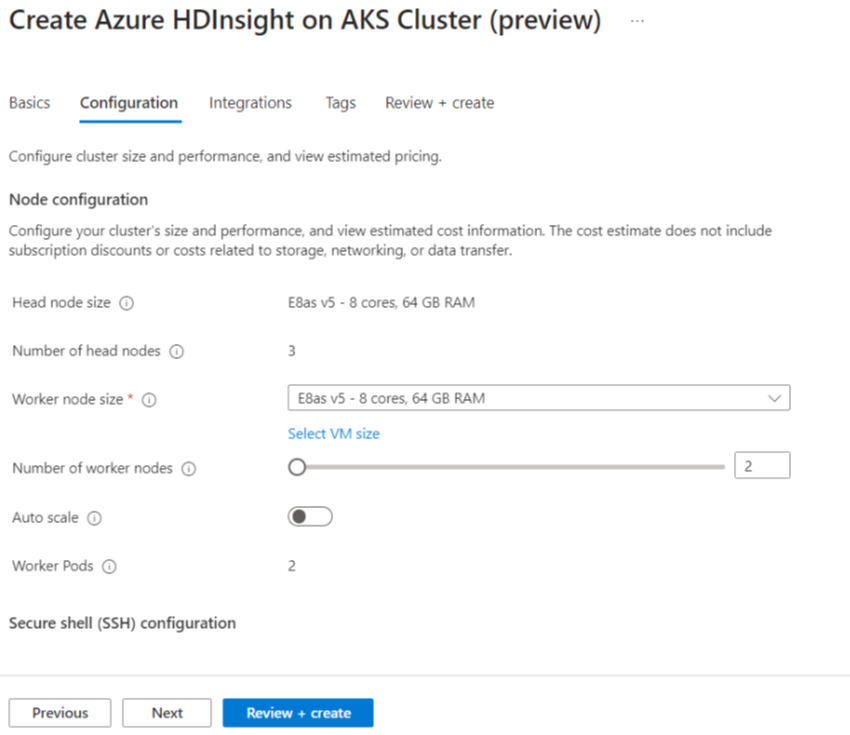
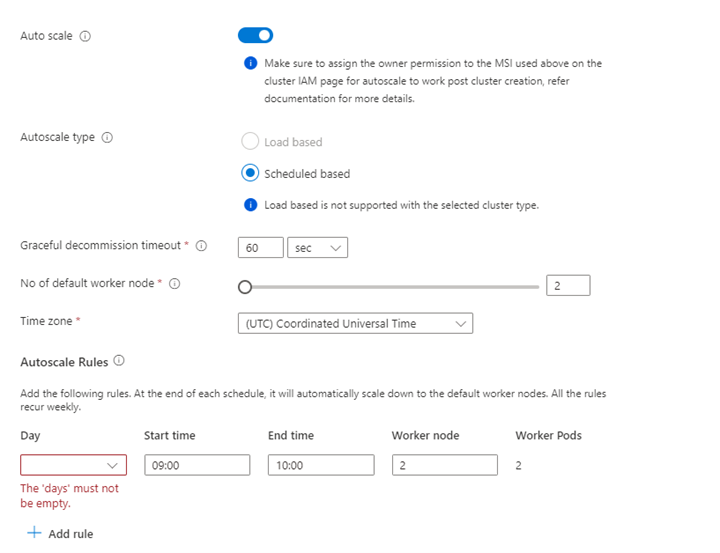
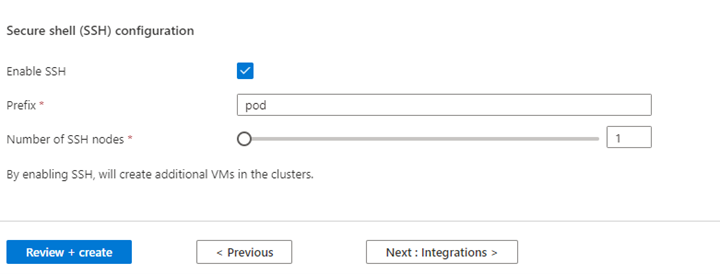
プロパティ 説明 ノード サイズ Spark ノードに使用するノード サイズを選択します ワーカー ノードの数 Spark クラスターのノード数を選択します。 そのうち、3 つのノードはコーディネーターおよびシステム サービス用に予約されており、残りのノードは Spark ワーカー専用で、ノードごとに 1 つのワーカーが割り当てられています。 たとえば、5 ノード クラスターには 2 つのワーカーがあります 自動スケール トグル ボタンをクリックすると Autoscale が有効になります 自動スケールの種類 負荷ベースまたはスケジュール ベースの自動スケーリングを選択します グレースフル使用停止タイムアウト グレースフル使用停止タイムアウトを指定します 既定のワーカー ノードの数 自動スケーリングのノード数を選択します タイム ゾーン タイム ゾーンを選択します 自動スケール ルール 日、開始時刻、終了時刻、ワーカー ノード数を選択します SSH を有効にする 有効になっている場合は、プレフィックスと SSH ノード数を定義できます [Next : Integrations] (次へ: 統合) をクリックして、ログ記録用の Log Analytics を有効にし選択します。
監視とメトリック用の Azure Prometheus は、クラスターの作成後に有効にすることができます。
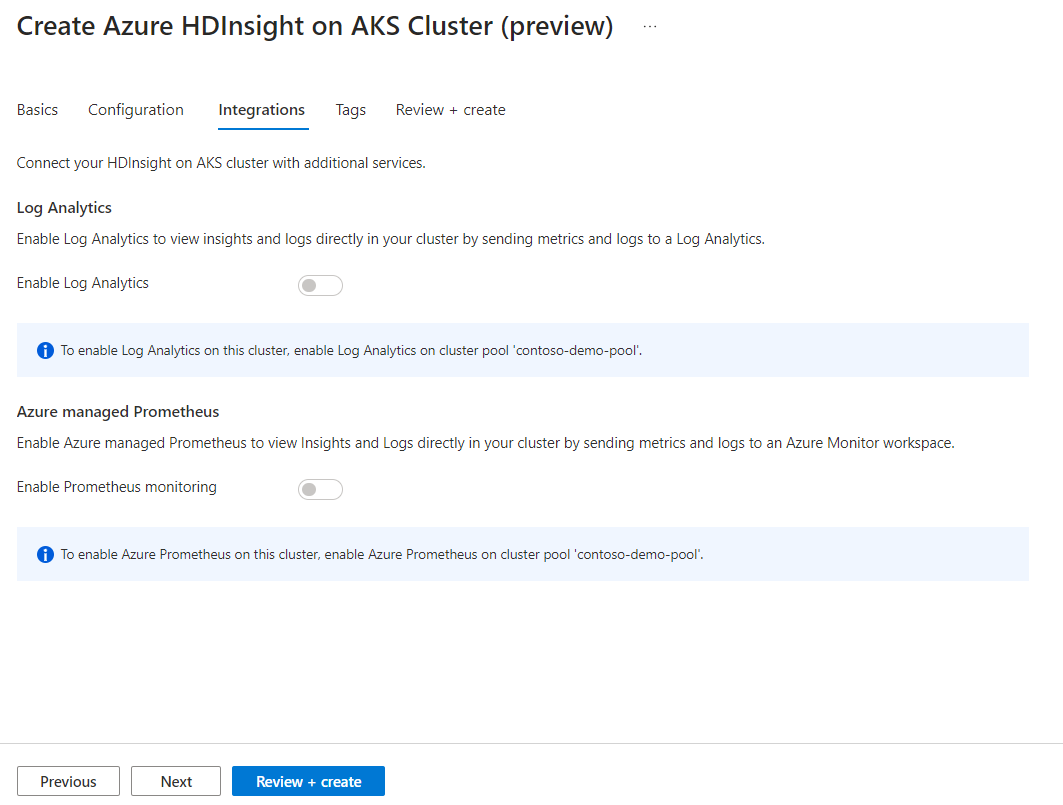
[Next: Tags] (次へ: タグ) をクリックして、次のページに進みます。
![[タグ] タブを示すスクリーンショット。](media/create-spark-cluster/tags-tab.png)
[タグ] ページで、リソースに追加するタグを入力します。
プロパティ 内容 名前 省略可能。 リソースに関連付けられているすべてのリソースを簡単に識別するために、HDInsight on AKS プライベート プレビューなどの名前を入力します 値 空白のままにします リソース [All resources selected] (すべてのリソースを選択する) を選択します [次: 確認および作成] をクリックします。
[確認と作成] ページで、ページの上部にある [検証が成功しました] というメッセージを探し、[作成] をクリックします。
クラスターが作成されている間、[Deployment is in process]\(デプロイが処理中です\) ページが表示されます。 クラスターの作成には 5 分から 10 分かかります。 クラスターが作成されると、[デプロイが完了しました] というメッセージが表示されます。 ページから移動する場合は、[通知] で状態を確認できます。
クラスターの [概要] ページに移動すると、エンドポイント リンクが確認できます。
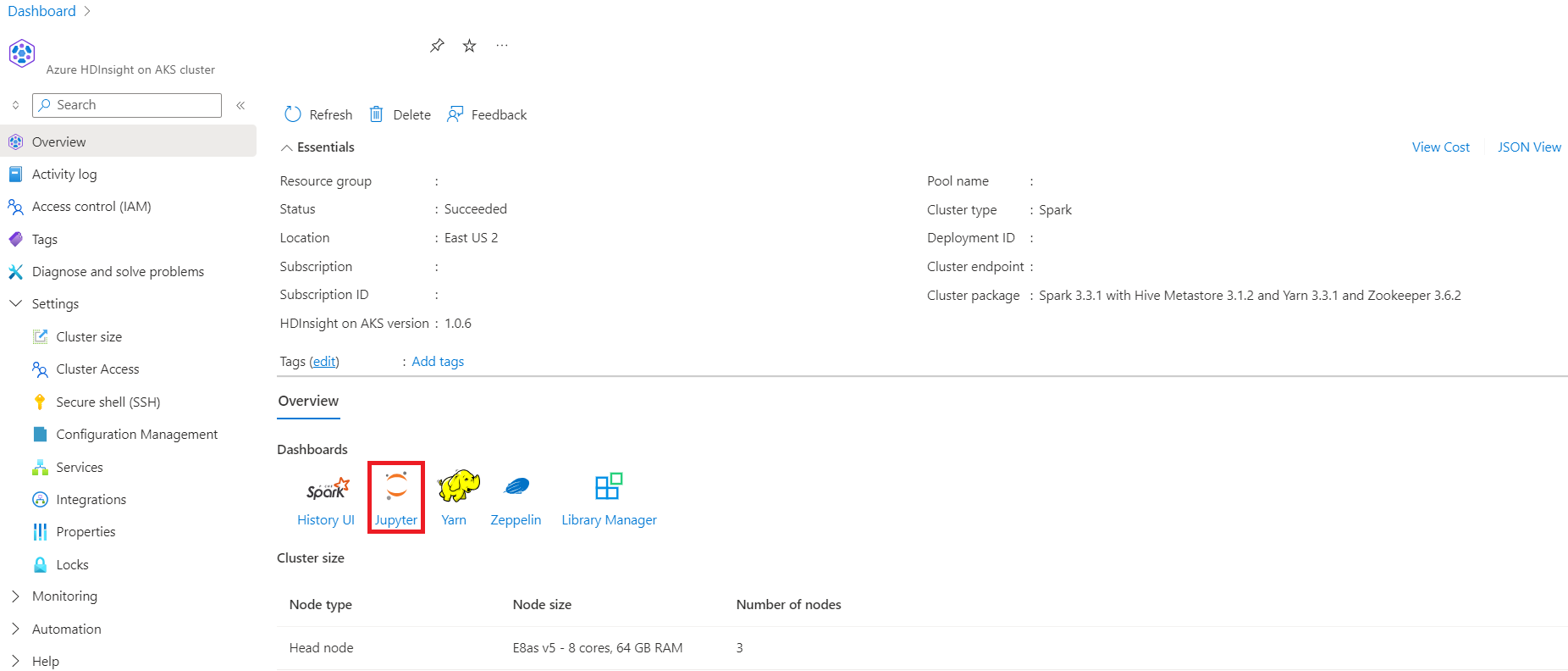

![クラスターの作成の [基本] ページを示すスクリーンショット。](media/create-spark-cluster/create-cluster-basic-page.png#lightbox)




![[タグ] タブを示すスクリーンショット。](media/create-spark-cluster/tags-tab.png#lightbox)

フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示