Spark で Azure Machine Learning ノートブックを使用する方法
重要
現在、この機能はプレビュー段階にあります。 ベータ版、プレビュー版、または一般提供としてまだリリースされていない Azure の機能に適用されるその他の法律条項については、「Microsoft Azure プレビューの追加の使用条件」に記載されています。 この特定のプレビューについては、Azure HDInsight on AKS のプレビュー情報に関する記事を参照してください。 質問や機能の提案については、詳細を記載した要求を AskHDInsight で送信してください。また、その他の更新情報については、Azure HDInsight コミュニティをフォローしてください。
機械学習は成長を遂げているテクノロジであり、これによってコンピューターは過去のデータから自動的に学習することができます。 機械学習では、さまざまなアルゴリズムを使用して、数学モデルを構築し、履歴データまたは情報に基づいて予測を行います。 定義済みのモデルといくつかのパラメータが用意されています。学習はコンピューター プログラムによって実行され、トレーニング データまたはエクスペリエンスを使ってモデルのパラメータが最適化されます。 モデルは、将来の予測を行う予測モデルか、データからナレッジを取得する記述的モデルのいずれかです。
次のチュートリアル ノートブックでは、表形式データに対する機械学習モデルのトレーニングの例が示されています。 このノートブックをインポートして、自分で実行できます。
CSV をストレージにアップロードする
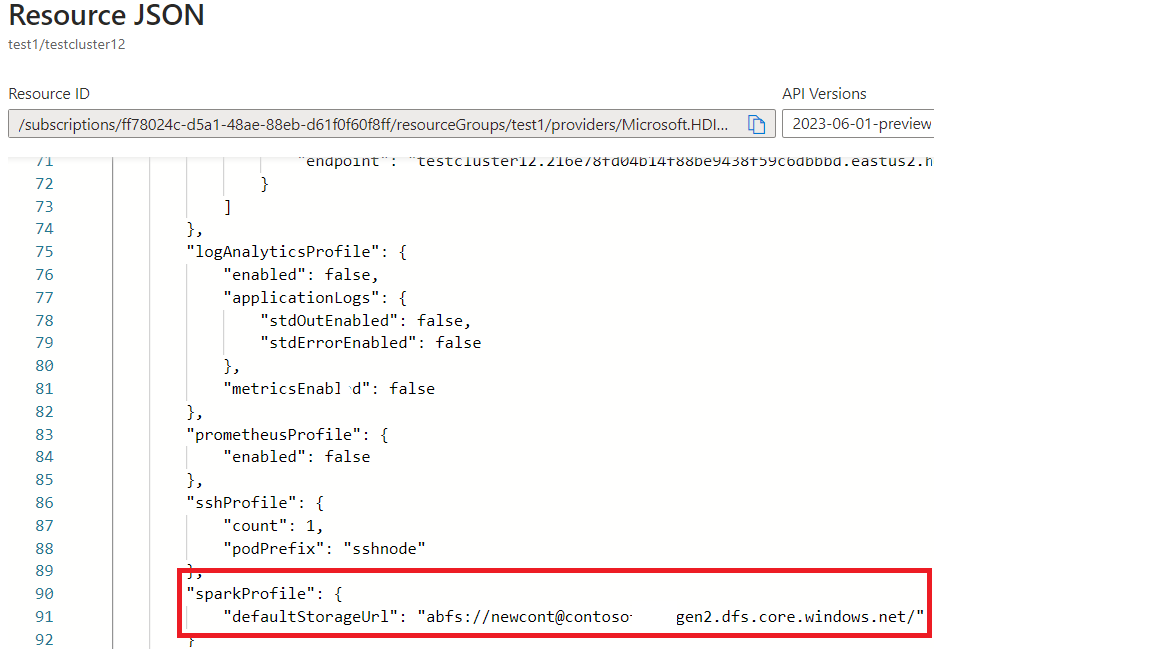
ポータルの JSON ビューでご使用のストレージとコンテナーの名前を見つけます
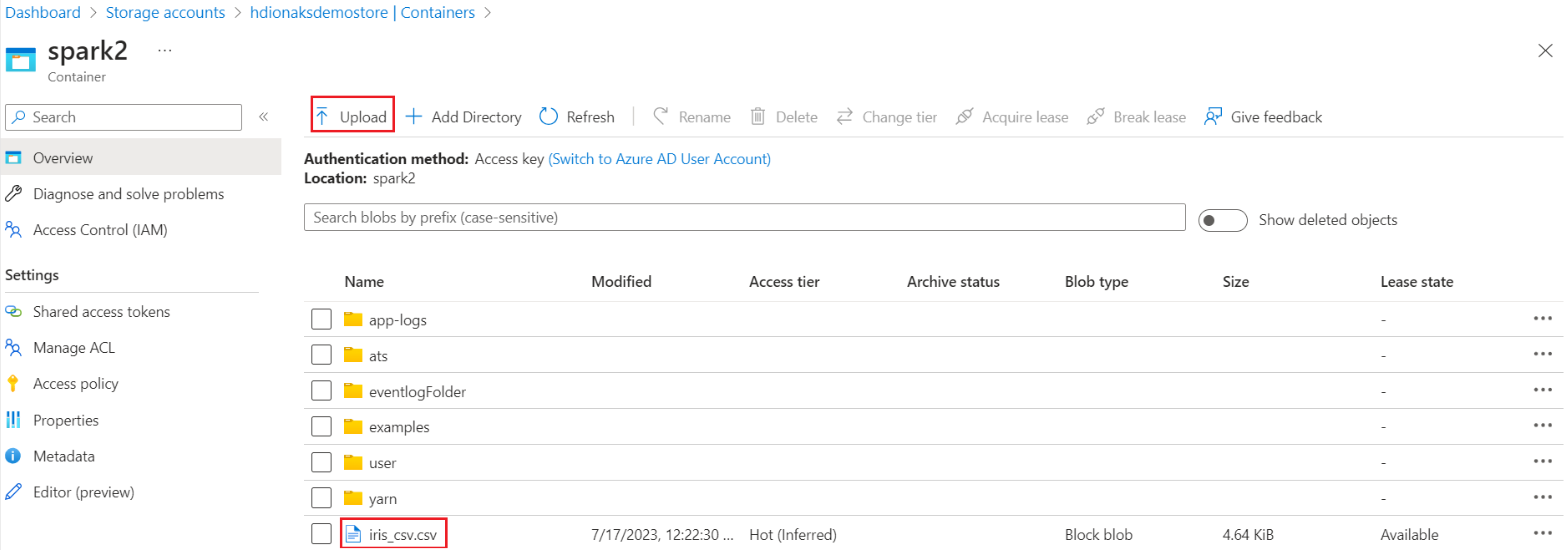
プライマリ HDI ストレージ > コンテナー > ベース フォルダーに移動し > CSV をアップロードします
クラスターにログインし、Jupyter Notebook を開きます
Spark MLlib ライブラリをインポートして、パイプラインを作成します
import pyspark from pyspark.ml import Pipeline, PipelineModel from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import VectorAssembler, StringIndexer, IndexToString
Spark データフレームに CSV を読み込みます
df = spark.read.("abfss:///iris_csv.csv",inferSchema=True,header=True)データをトレーニング用とテスト用に分割します
iris_train, iris_test = df.randomSplit([0.7, 0.3], seed=123)パイプラインを作成してモデルをトレーニングします
assembler = VectorAssembler(inputCols=['sepallength', 'sepalwidth', 'petallength', 'petalwidth'],outputCol="features",handleInvalid="skip") indexer = StringIndexer(inputCol="class", outputCol="classIndex", handleInvalid="skip") classifier = LogisticRegression(featuresCol="features", labelCol="classIndex", maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[assembler,indexer,classifier]) model = pipeline.fit(iris_train) # Create a test `dataframe` with predictions from the trained model test_model = model.transform(iris_test) # Taking an output from the test dataframe with predictions test_model.take(1)
モデルの精度を評価します
import pyspark.ml.evaluation as ev evaluator = ev.MulticlassClassificationEvaluator(labelCol='classIndex') print(evaluator.evaluate(test_model,{evaluator.metricName: 'accuracy'}))





フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示