HDInsight 4.0 の大幅なバージョン変更と利点
HDInsight 4.0 には、HDInsight 3.6 よりも優れた点がいくつかあります。 以下は、Azure HDInsight 4.0 の新機能の概要です。
| # | OSS コンポーネント | HDInsight 4.0 バージョン | HDInsight 3.6 バージョン |
|---|---|---|---|
| 1 | Apache Hadoop | 3.1.1 | 2.7.3 |
| 2 | Apache HBase | 2.1.6 | 1.1.2 |
| 3 | Apache Hive | 3.1.0 | 1.2.1, 2.1 (LLAP) |
| 4 | Apache Kafka | 2.1.1、2.4 (GA) | 1.1 |
| 5 | Apache Phoenix | 5 | 4.7.0 |
| 6 | Apache Spark | 2.4.4、3.0.0 (プレビュー) | 2.2 |
| 7 | Apache TEZ | 0.9.1 | 0.7.0 |
| 8 | Apache ZooKeeper | 3.4.6 | 3.4.6 |
| 9 | Apache Kafka | 2.1.1、2.4.1 (プレビュー) | 1.1 |
| 10 | Apache Ranger | 1.1.0 | 0.7.0 |
ワークロードと機能
Hive
- 高度な機能:
- 低待機時間の分析処理 (LLAP) ワークロード管理。
- Java Database Connectivity (JDBC)、Druid、Kafka コネクタの LLAP サポート。
- SQL 機能の向上 (制約と既定値)。
- 代理キー。
- 情報スキーマ。
- パフォーマンスの利点:
- 結果のキャッシュ。 クエリ結果をキャッシュすることで、以前に計算されたクエリ結果を再利用できます。
- 動的な具体化されたビューと概要の事前計算。
- ストレージ形式と実行エンジンの両方における原子性、一貫性、分離性、持続性 (ACID) V2 のパフォーマンスが向上しました。
- セキュリティ:
- Apache Hive トランザクションで GDPR コンプライアンスが有効になりました。
- Ranger での Hive ユーザー定義関数 (UDF) の実行認可。
hbase
- 高度な機能:
- Procedure V2 (procv2)、複数ステップの HBase 管理操作を実行するための更新されたフレームワーク。
- 完全にオフヒープの読み取り/書き込みパス。
- メモリ内圧縮。
- Azure Data Lake Storage Gen2 Premium レベルの HBase クラスターのサポート。
- パフォーマンスの利点:
- Azure Premium SSD マネージド ディスクを使用した書き込みの高速化により、Apache HBase 先書きログ (WAL) のパフォーマンスが向上します。
- セキュリティ:
- ローカルとグローバルを含む両方のセカンダリ インデックスの強化。
Kafka
- 高度な機能:
- Azure 障害ドメインでの Kafka パーティション分散。
- Zstandard (zstd) 圧縮のサポート。
- Kafka コンシューマー インクリメンタル リバランス。
- MirrorMaker 2.0 のサポート。
- パフォーマンスの利点:
- Kafka Streams でのウィンドウ集計パフォーマンスの向上。
- メッセージ変換のメモリ占有領域を削減することでブローカーの回復性を向上。
- 高速リーダー フェールオーバーのレプリケーション プロトコルの改善。
- セキュリティ:
- 特定のトピックまたはトピック プレフィックスを作成するためのアクセス制御。
- Secure Sockets Layer (SSL) 構成の中間者攻撃の防止に役立つホスト名検証。
- トランスポート層セキュリティ (TLS) と CRC32C 実装の高速化による暗号化のサポートの強化。
Spark
- 高度な機能:
- ORC の構造化ストリーミングのサポート。
- 新しいメタストア カタログ機能と統合する機能。
- Hive Streaming ライブラリの構造化ストリーミングのサポート。
- Hive ウェアハウスへの透過的な書き込み。
- Spark 用の自動計算再利用システムである SparkCruise。
- パフォーマンスの利点:
- 結果のキャッシュ。 クエリ結果をキャッシュすることで、以前に計算されたクエリ結果を再利用できます。
- 動的な具体化されたビューと概要の事前計算。
- セキュリティ:
- Spark トランザクションに対する GDPR コンプライアンスの有効化。
Hive パーティションの検出と修復
Hive は、Hive メタストア (HMS) 内のパーティションのメタデータを自動的に検出して同期します。
discover.partitions テーブル プロパティは、パーティションのあるファイル システムの同期を有効または無効にします。 外部パーティション テーブルでは、このプロパティは既定で有効 (true) です。
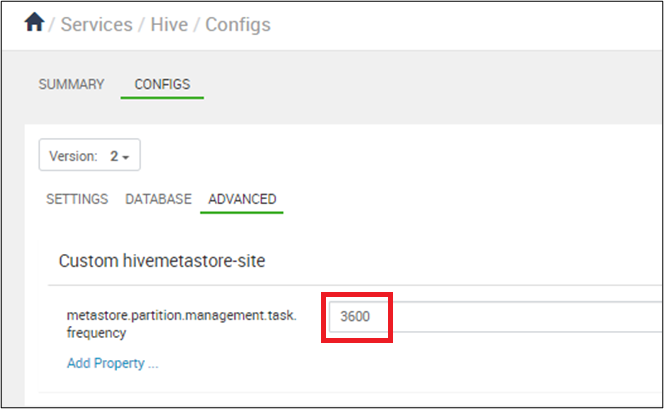
Hive メタストアがリモート サービス モードで開始されると、定期的なバックグラウンド スレッド (PartitionManagementTask) が 300 秒ごとにスケジュールされます (metastore.partition.management.task.frequency config で構成可能)。 スレッドは、discover.partitions テーブル プロパティが true に設定されているテーブルを検索し、同期モードで msck 修復を実行します。
テーブルがトランザクション テーブルの場合、スレッドは、msck 修復を実行する前に、そのテーブルの排他ロックを取得します。 このテーブル プロパティを使用すると、MSCK REPAIR TABLE table_name SYNC PARTITIONS を手動で実行する必要がなくなりました。
パーティション検出をサポートしていないバージョンの Hive を使用して作成した外部テーブルがある場合は、テーブルのパーティション検出を有効にします。
ALTER TABLE exttbl SET TBLPROPERTIES ('discover.partitions' = 'true');
パーティションの同期が 10 分ごとに行われるように設定します (秒単位)。 [Ambari]>[Hive]>[Configs] で、metastore.partition.management.task.frequency を 3600 以上に設定します。
警告
management.task を 10 分ごとに実行すると、SQL Server データベース トランザクション ユニット (DTU) に負荷がかかります。
Azure portal からの出力を確認できます。
Hive は、保持期間の後に作成されたパーティション内のメタデータと対応するデータを削除します。 保持時間は、数字と次の文字を使用して表します。
ms (milliseconds)
s (seconds)
m (minutes)
d (days)
パーティションの保持期間を 1 週間に構成するには、次のコマンドを使用します。
ALTER TABLE employees SET TBLPROPERTIES ('partition.retention.period'='7d');
Hive での従業員のパーティション メタデータと実際のデータは、1 週間後に自動的に削除されます。
Hive 3 で使用可能なパフォーマンスの最適化
OLAP ベクター化
オンライン分析処理 (OLAP) ベクター化により、Hive は一度に 1 行ずつ処理するのではなく、行を一括処理することができます。 通常、各バッチはプリミティブ型の配列です。 操作は列ベクトル全体に対して実行されるため、命令パイプラインとキャッシュの使用が向上します。
この機能には、パーティション テーブル関数 (PTF)、ロールアップ、グループ化セットのベクター化された実行が含まれます。
動的な半結合の削減
動的な semijoin の削減により、選択的結合のパフォーマンスが大幅に向上します。 結合の一方の側からブルーム フィルターを構築し、もう一方の側から行をフィルター処理します。 スキャンをスキップし、結合に適さない行をさらに評価します。
LLAP を使用したベクター化に対する Parquet のサポート
ベクター化されたクエリ実行は、次のような一般的なクエリ操作の CPU 使用率を大幅に削減する機能です。
- スキャン
- フィルター
- Aggregate
- Join
ベクター化は、ORC 形式にも実装されます。 Spark 2.0 以降、whole-stage code generation とこのベクター化 (Parquet の場合) も Spark により使用されます。 LLAP には、Parquet のベクター化と書式設定のためのタイム スタンプ列が追加されています。
警告
タイム スタンプからゾーン時間に変換すると、Parquet の書き込みが遅くなります。 詳細については、Apache Hive サイトで問題の詳細に関するページを参照してください。
自動クエリ キャッシュ
自動クエリ キャッシュに関する考慮事項をいくつか示します。
hive.query.results.cache.enabled=trueを使用すると、Hive 3 で実行されるすべてのクエリは、その結果をキャッシュに格納します。- 入力テーブルが変更されると、Hive はキャッシュから無効なデータを削除します。 たとえば、集計を実行してベース テーブルが変更された場合、最も頻繁に実行するクエリはキャッシュに残りますが、古いクエリは削除されます。
- クエリ結果キャッシュは、Hive が外部テーブルへの変更を追跡できないため、マネージド テーブルでのみ機能します。
- 外部テーブルとマネージド テーブルを結合すると、Hive は完全なクエリの実行にフォールバックします。 クエリ結果キャッシュは ACID テーブルで動作します。 ACID テーブルを更新すると、Hive によってクエリが自動的に再実行されます。
- クエリ結果キャッシュは、コマンド ラインから有効または無効にすることができます。 これを行ってクエリをデバッグすることもできます。
hive.query.results.cache.enabled=falseを設定することで、クエリ結果キャッシュを無効にできます。- Hive は、クエリ結果キャッシュを
/tmp/hive/__resultcache__/に格納します。 既定では、Hive はクエリ結果キャッシュに 2 GB を割り当てます。 この設定を変更するには、パラメーターhive.query.results.cache.max.sizeをバイト単位で構成します。 - クエリ処理の変更: クエリのコンパイル中に、結果キャッシュを調べて、クエリ結果が既に存在するかどうかを確認します。 キャッシュ ヒットがある場合、クエリ プランはキャッシュされた場所から読み取る
FetchTaskに設定されます。
クエリの実行中、Parquet DataWriteableWriter は NanoTimeUtils を利用してタイム スタンプ オブジェクトをバイナリ値に変換します。 このクエリはタイム スタンプ オブジェクトに対して toString() を呼び出し、文字列を解析します。
このクエリに結果キャッシュを使用できる場合:
- クエリは
FetchTaskで、キャッシュされた結果のディレクトリから読み取ります。 - クラスター タスクは必要ありません。
結果キャッシュを使用できない場合は、通常どおりクラスター タスクを実行します。
- 計算されたクエリ結果が結果キャッシュに追加できるかどうかを確認します。
- 結果をキャッシュできる場合、クエリに対して生成された一時的な結果は結果キャッシュに保存されます。 クエリのクリーンアップによってクエリ結果ディレクトリが削除されないように、手順を実行する必要がある場合があります。
SQL 機能
Apache Hive 3.0.0 で導入された最初の実装では、具体化されたビューの導入と、プロジェクト内のそれらの具体化に基づく自動クエリの書き換えに焦点を当てています。 具体化されたビューは、Hive または他のカスタム ストレージ ハンドラー (ORC) にネイティブに格納でき、LLAP アクセラレーションなどの新しい Hive 機能を利用できます。
詳細については、Hive の具体化されたビューに関する Azure ブログ記事を参照してください。
代理キー
組み込みの SURROGATE_KEY UDF を使用して、テーブルにデータを入力するときに行の数値 ID を自動的に生成します。 生成された代理キーは、幅広い複数の複合キーと置き換えることができます。
Hive は、ACID テーブルに対してのみ代理キーをサポートします。 代理キーを使用して結合するテーブルには、キャストが必要な列の型を含めることはできません。 これらのデータ型は、INT や STRING などのプリミティブである必要があります。
生成されたキーを使用する結合は、文字列を使用する結合より高速です。 生成されたキーを使用しても、行番号でデータが 1 つのノードに強制的に挿入されることはありません。 キーは、自然キーの抽象化として生成できます。 代理キーには、低速で確率的な汎用一意識別子 (UUID) よりも優れた利点があります。
SURROGATE_KEY UDF は、テーブルに挿入するすべての行に対して一意の ID を生成します。 これは、分散システムの実行環境に基づいてキーを生成し、次のような多くの要素が含まれます。
- 内部データ構造
- テーブルの状態
- 最後のトランザクション ID
代理キーの生成には、コンピューティング タスク間の調整は必要ありません。 UDF は引数をとらないか、次の 2 つの引数をとります。
- 書き込み ID ビット
- タスク ID ビット
制約
SQL 制約は、データの整合性を強制し、パフォーマンスを向上させるのに役立ちます。 オプティマイザーは制約情報を使用して、スマートな意思決定を行います。 制約を使用すると、データを予測しやすく、簡単に見つけることができます。
| 制約 | 説明 |
|---|---|
Check |
列に配置できる値の範囲を制限します。 |
PRIMARY KEY |
一意識別子を使用して、テーブル内の各行を特定します。 |
FOREIGN KEY |
一意識別子を使用して、別のテーブル内の行を特定します。 |
UNIQUE KEY |
列に格納されている値が異なっていることを確認します。 |
NOT NULL |
列を NULL に設定できないようにします。 |
ENABLE |
すべての受信データが制約に準拠していることを保証します。 |
DISABLE |
すべての受信データが制約に準拠していることを保証しません。 |
VALIDATEC |
テーブル内のすべての既存のデータが制約に準拠していることを確認します。 |
NOVALIDATE |
テーブル内のすべての既存のデータが制約に準拠しているかどうかは確認しません。 |
ENFORCED |
ENABLE NOVALIDATE にマップされます。 |
NOT ENFORCED |
DISABLE NOVALIDATE にマップされます。 |
RELY |
制約に従うことを指定します。 オプティマイザーはこれを使用して、さらに最適化を適用します。 |
NORELY |
制約に従わないことを指定します。 |
詳細については、Apache Hive サイトの「Supported Features: Apache Hive 3.1 (サポートされている機能: Apache Hive 3.1)」を参照してください。
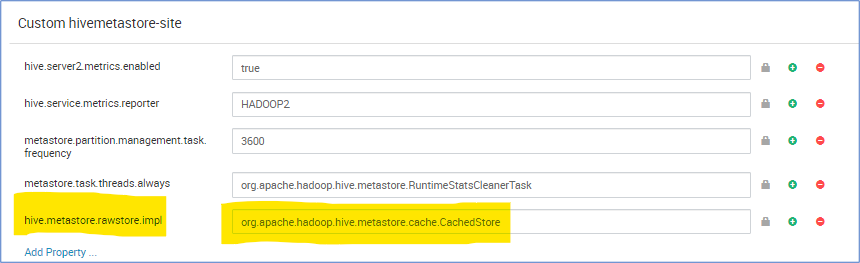
メタストアの CachedStore
Hive メタストアの操作には時間がかかり、Hive のコンパイルが遅くなります。 極端な場合には、実際のクエリの実行時間よりも長い時間がかかります。
特に、クラウド データベースの待機時間が長く、クエリ ランタイムの合計の 90% がメタストア SQL データベースの操作を待機していることがわかります。 この観察に基づいて、データベース クエリ結果をキャッシュするメモリ構造がある場合、Hive メタストア操作のパフォーマンスを向上させることができます。
hive.metastore.rawstore.impl=org.apache.hadoop.hive.metastore.cache.CachedStore
関連情報
詳細については、次のリリース ノートを参照してください。