HDInsight で Azure Monitor ログを使用してクラスターの可用性を監視する方法
HDInsight クラスターには、クエリ可能なメトリックとログ、および構成可能なアラートを提供する Azure Monitor ログ統合が含まれています。 この記事では、Azure Monitor を使用してクラスターを監視する方法について説明します。
Azure Monitor ログの統合
Azure Monitor ログでは、HDInsight クラスターなどの複数のリソースによって生成されたデータを 1 つの場所に収集して集計し、統合された監視エクスペリエンスを実現できます。
前提条件として、収集されたデータを格納するための Log Analytics ワークスペースが必要になります。 まだ作成していない場合は、次の記事の手順に従います:「Azure ポータルで Log Analytics ワークスペースを作成する」
HDInsight Azure Monitor ログの統合を有効にする
ポータルの HDInsight クラスター リソースのページから、 [Azure Monitor] を選択します。 次に、 [有効] を選択して、ドロップダウンから Log Analytics ワークスペースを選択します。
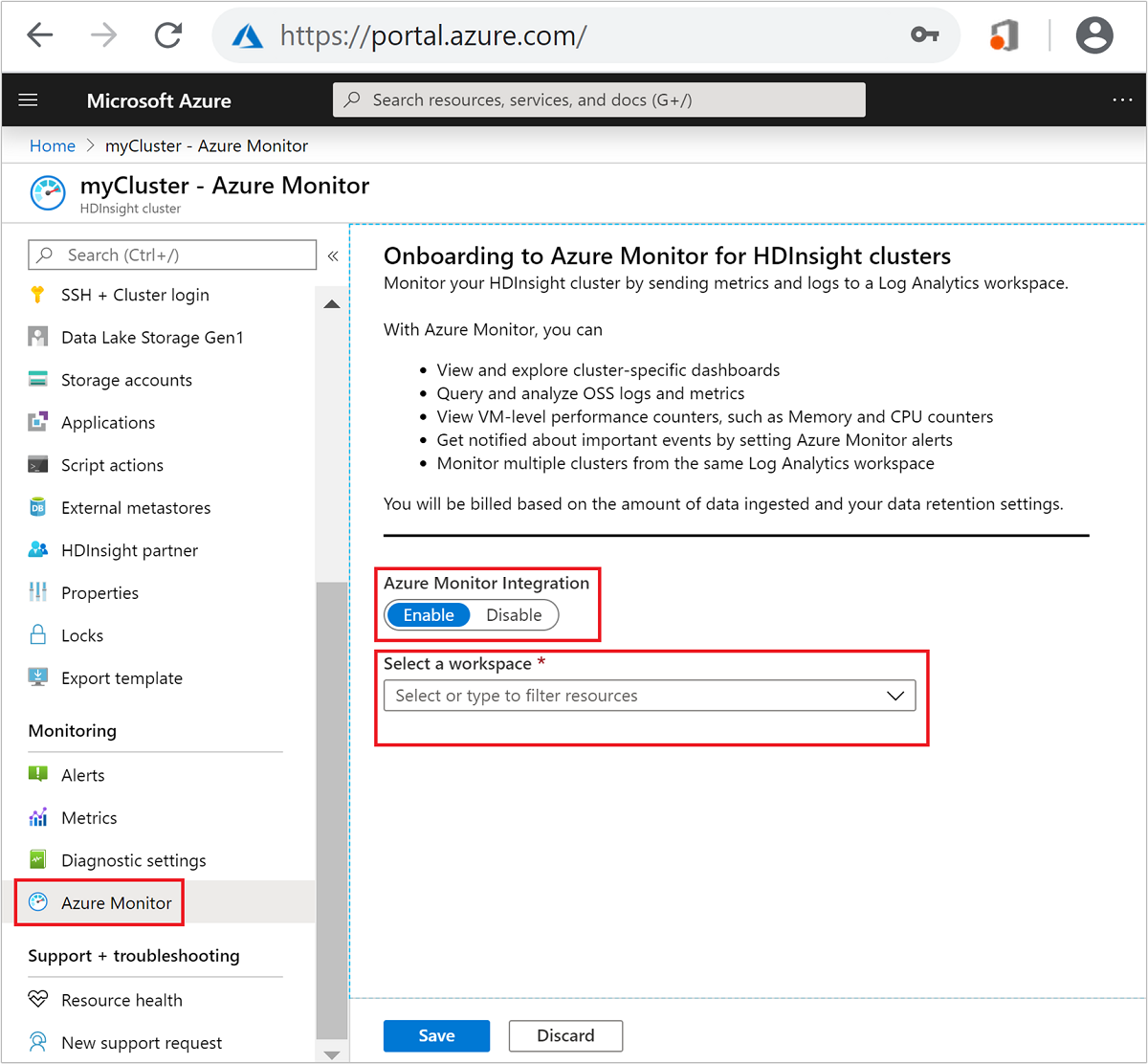
既定では、これによって、エッジ ノードを除くすべてのクラスター ノードに OMS エージェントがインストールされます。 クラスター エッジ ノードには OMS エージェントがインストールされていないため、Log Analytics に既定で存在するエッジ ノードにはテレメトリがありません。
メトリックとログ テーブルにクエリを実行する
Azure Monitor ログの統合が有効になったら (これには数分かかる場合があります)、 [Log Analytics ワークスペース] リソースに移動して、 [ログ] を選択します。
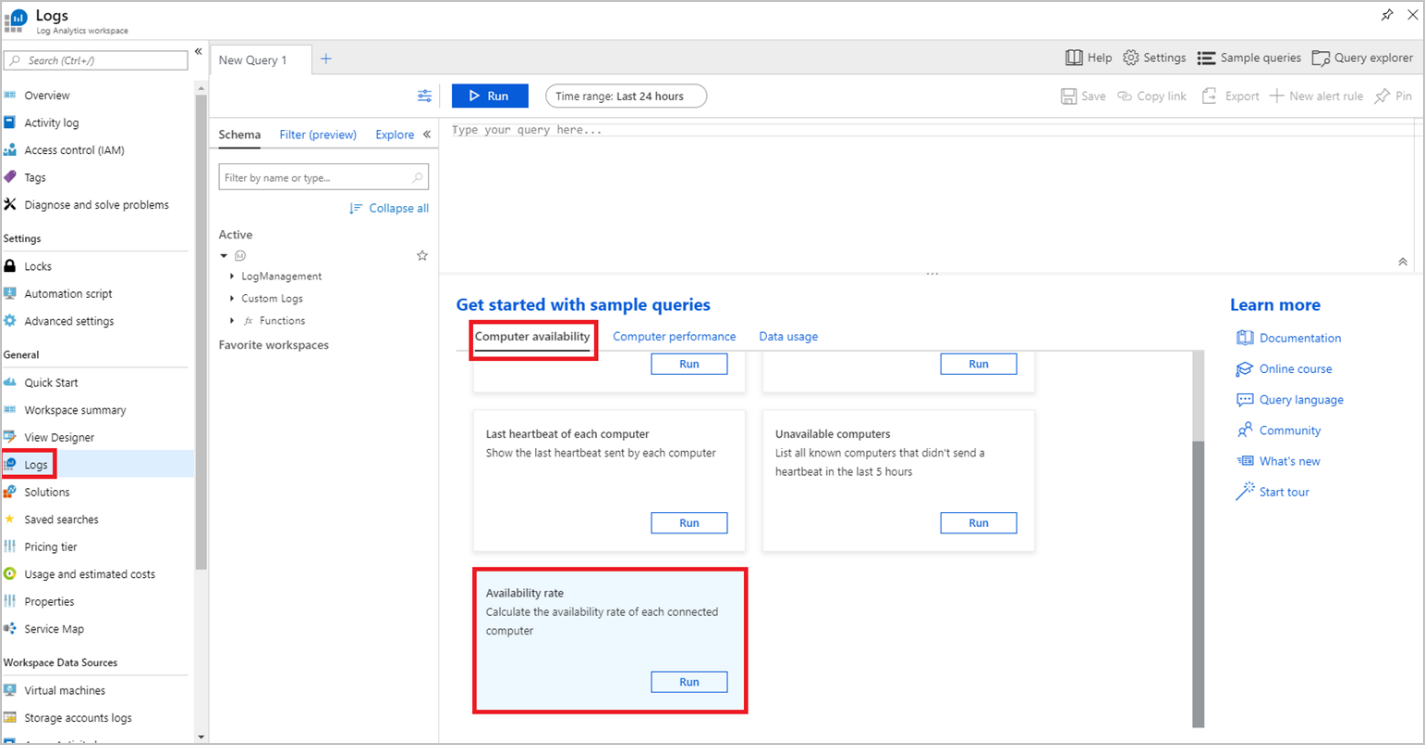
[ログ] には、次のような多数のサンプル クエリが一覧表示されます。
| クエリ名 | 説明 |
|---|---|
| 今日のコンピューターの可用性 | 1 時間ごとに、ログを送信するコンピューター数をグラフにする |
| ハートビードの一覧表示 | 過去 1 時間のすべてのコンピューターのハートビートを一覧表示する |
| 各コンピューターの最新のハートビート | 各コンピューターから送信された最新のハートビートを表示する |
| 利用できないコンピューター | 過去 5 時間以内にハートビートを送信しなかったすべての既知のコンピューターを一覧表示する |
| 可用性率 | 接続されている各コンピューターの可用性率を計算する |
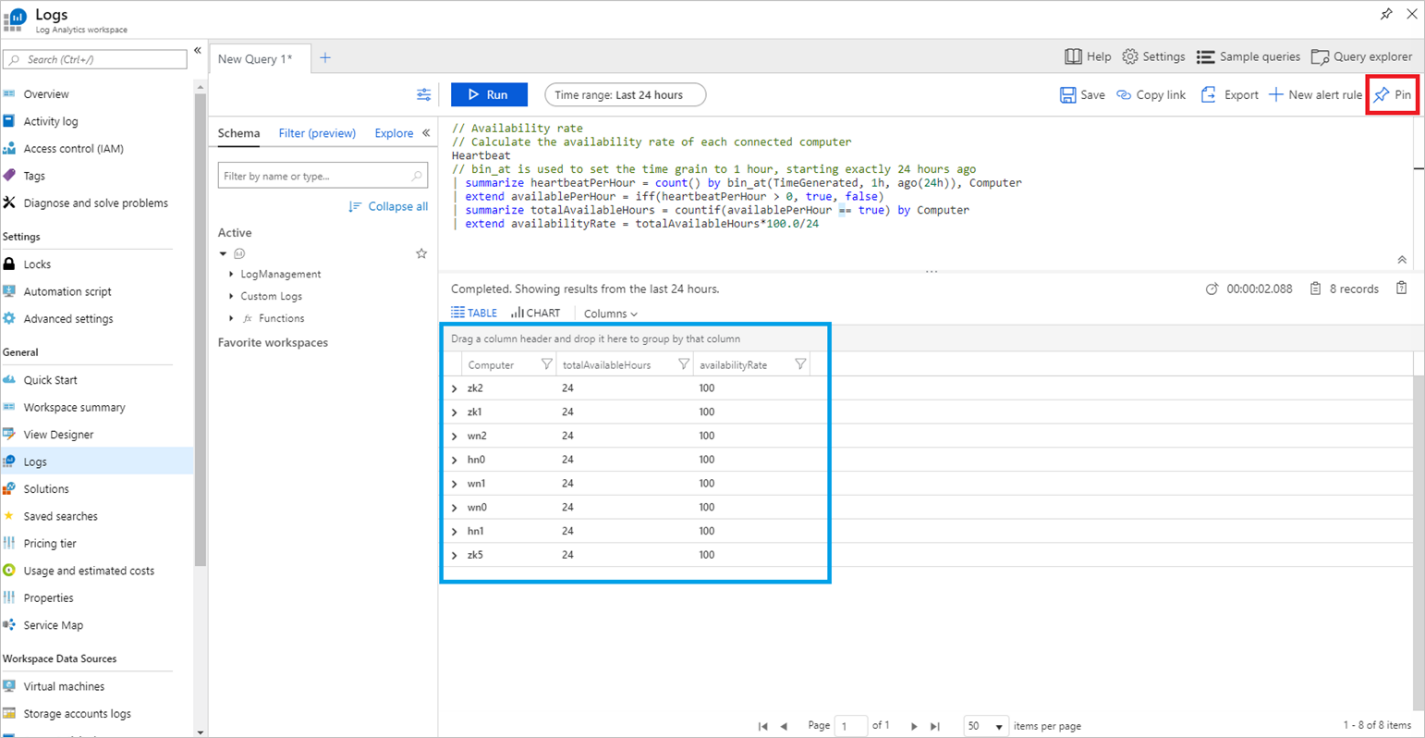
例として、上記のスクリーンショットに示すように、可用性率のサンプル クエリ上の [実行] を選択して、そのクエリを実行します。 これにより、クラスター内にある各ノードの可用性率が割合として表示されます。 複数の HDInsight クラスターを有効にしてメトリックを同じ Log Analytics ワークスペースに送信した場合、表示されているそれらのクラスター内のすべてのノード (エッジ ノードを除く) に対する可用性率が表示されます。
Note
可用性率は 24 時間の期間に測定されるので、正確な可用性率を表示するには、それまでに少なくとも 24 時間、クラスターが実行される必要があります。
右上隅にある [固定] をクリックして、共有のダッシュボードにこのテーブルを固定表示することが可能です。 書き込み可能な共有のダッシュボードがない場合は、次の記事で作成方法を確認できます:「Azure portal でのダッシュボードの作成と共有」
Azure Monitor アラート
メトリックの値またはクエリの結果が特定の条件に合った場合にトリガーする Azure Monitor アラートを設定することも可能です。 例として、1 つまたは複数のノードが 5 時間以内にハートビートを送信しなかった (つまり、利用できないと推定される) 場合に電子メールを送信するアラートを作成しましょう。
以下に示すように、 [ログ] から、利用できないコンピューターのサンプル クエリ上の [実行] を選択して、そのクエリを実行します。
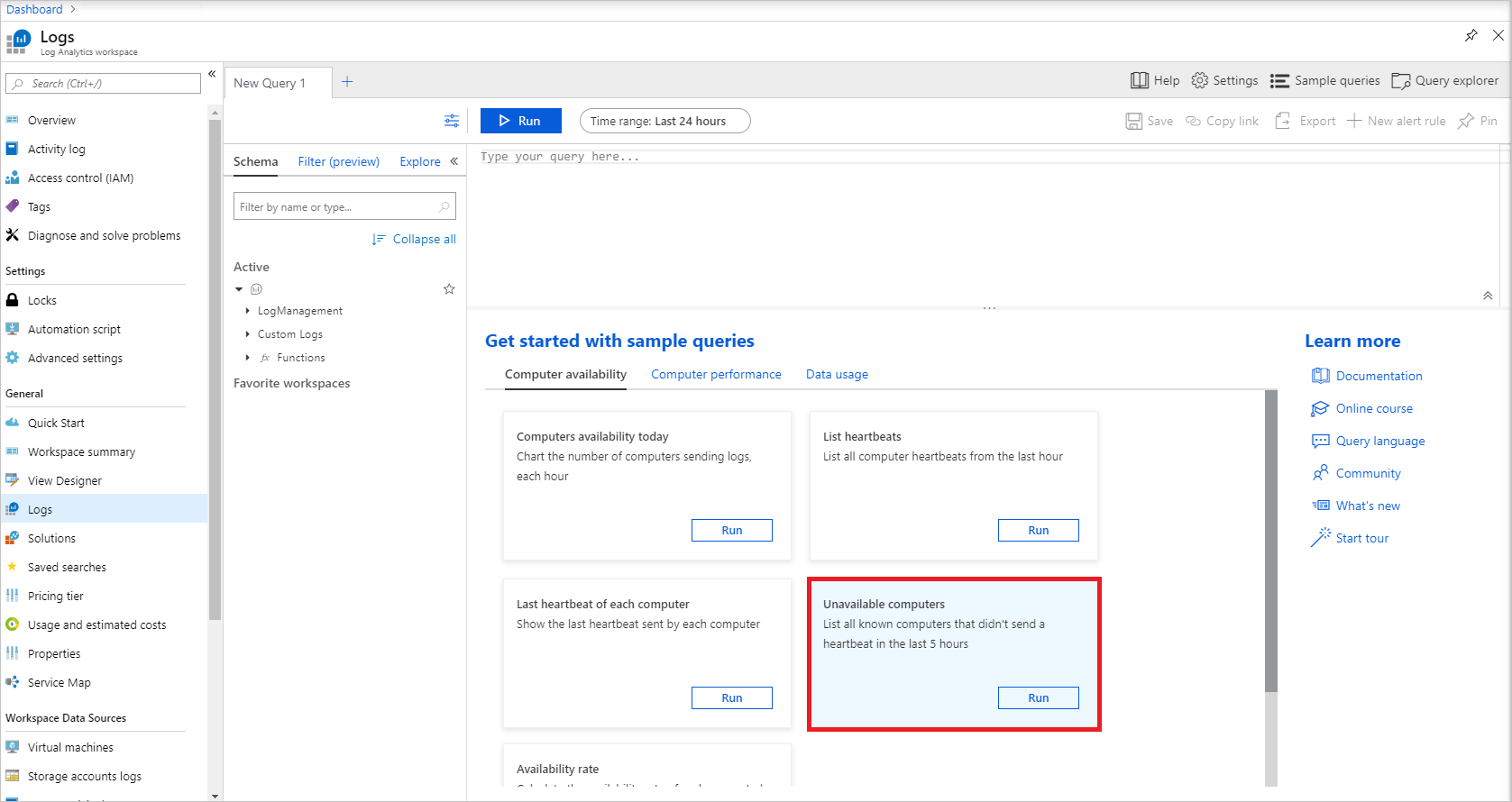
すべてのノードが利用可能な場合、このクエリは今のところ、0 の結果を返すはずです。 [新しいアラート ルール] をクリックして、このクエリでのアラートの構成を開始します。
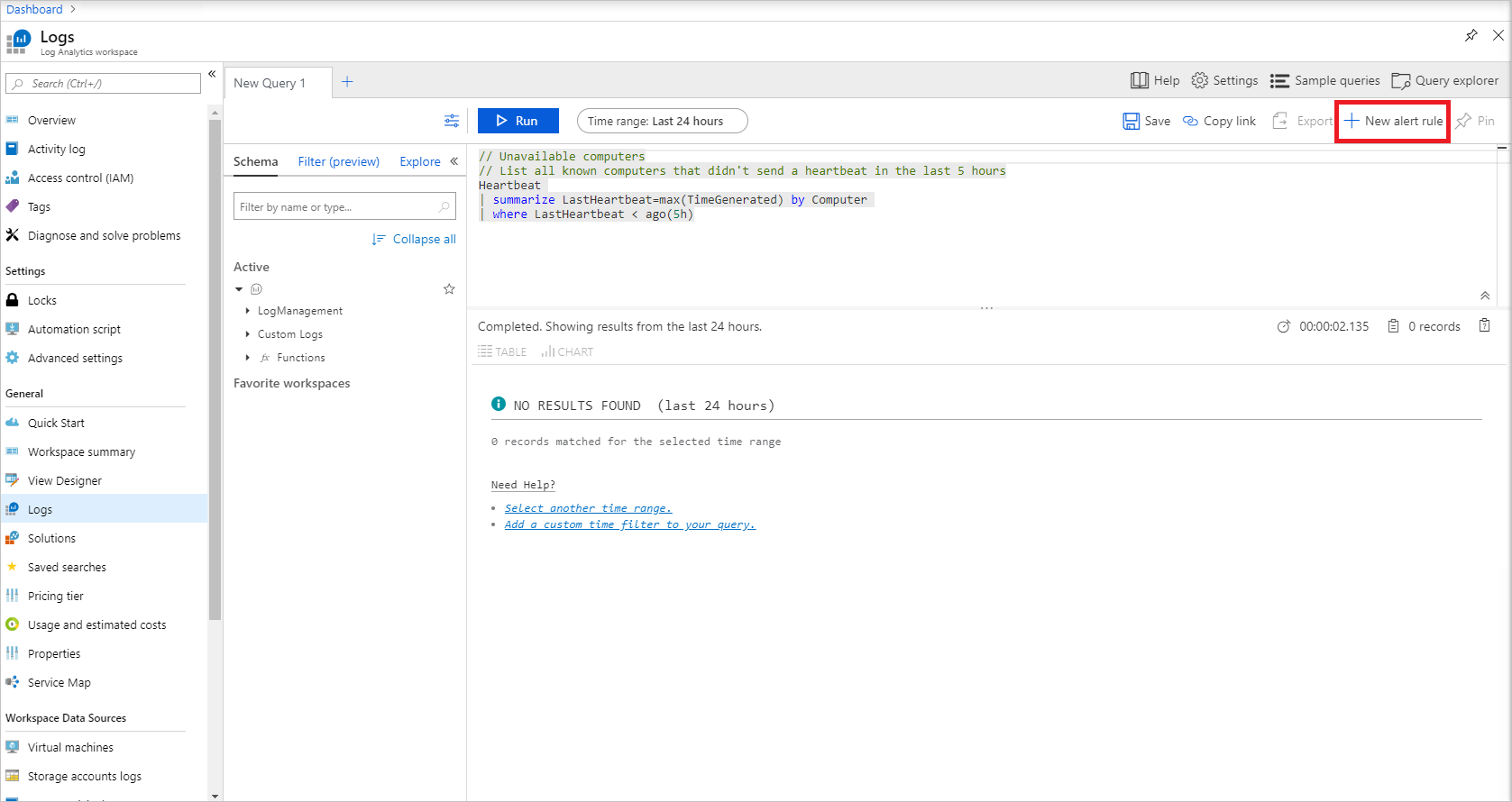
アラートに対しては、3 つのコンポーネントがあります。ルールの作成対象とするリソース (この場合、Log Analytics ワークスペース)、アラートをトリガーする条件、アラートがトリガーされたときに発生する動作を決定するアクション グループです。 以下に示すように条件のタイトルをクリックして、シグナル ロジックの構成を完了します。
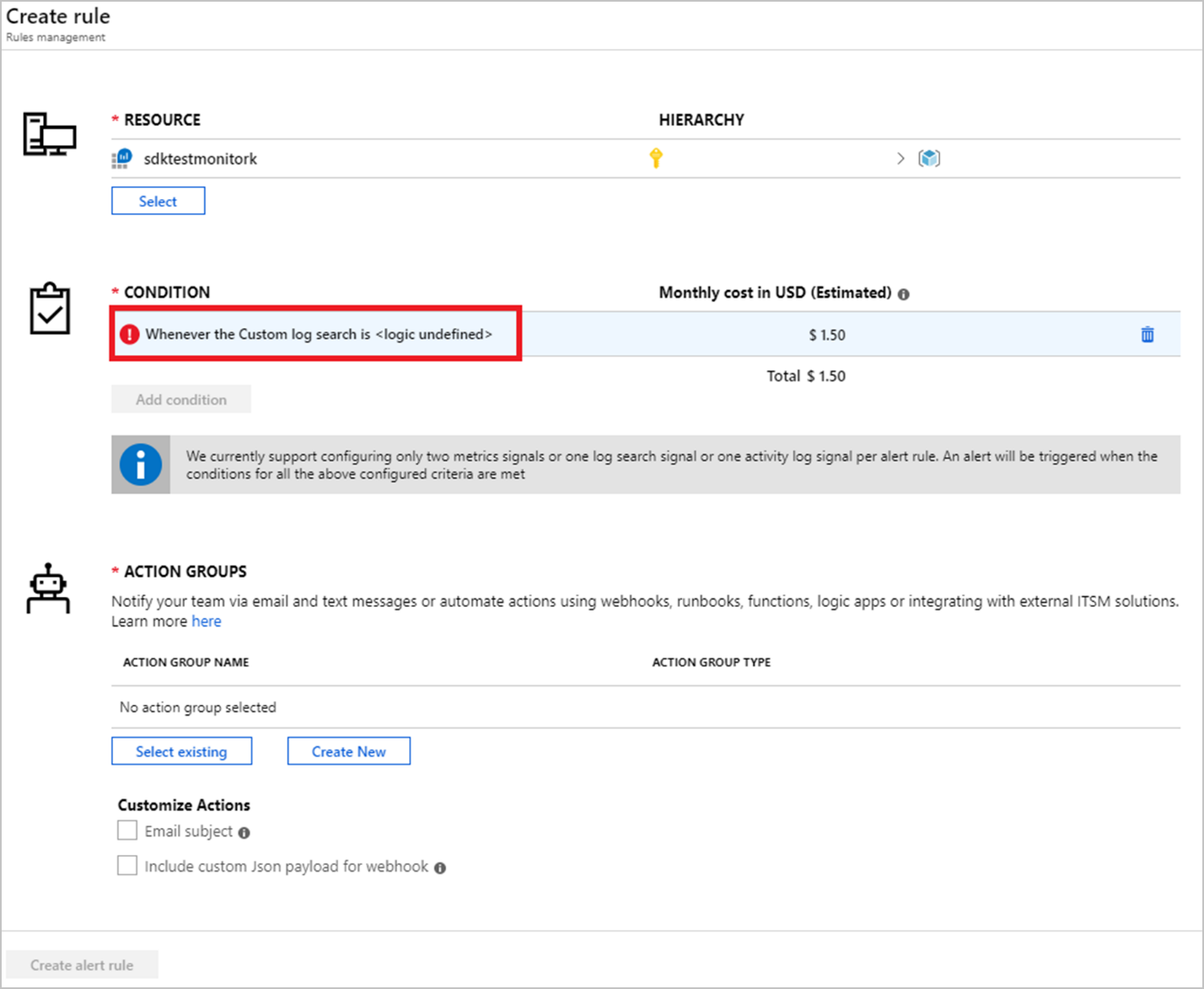
これにより、 [シグナル ロジックの構成] が開かれます。
[アラート ロジック] セクションを次のように設定します。
"基準:結果の数、条件:より大きい、しきい値:0"
このクエリでは、利用できないノードだけを結果として返すので、結果の数が 0 より大きい場合、必ずアラートが発生します。
[評価基準] セクションで、利用できないノードについてチェックする頻度に基づいて、 [期間] および [頻度] を設定します。
このアラートの目的のために、必ず [期間] = [頻度] にすることをお勧めします。期間、頻度、およびその他のアラート パラメーターに関する詳細は、こちらで確認できます。
シグナル ロジックの構成が終わったら、 [完了] を選択します。
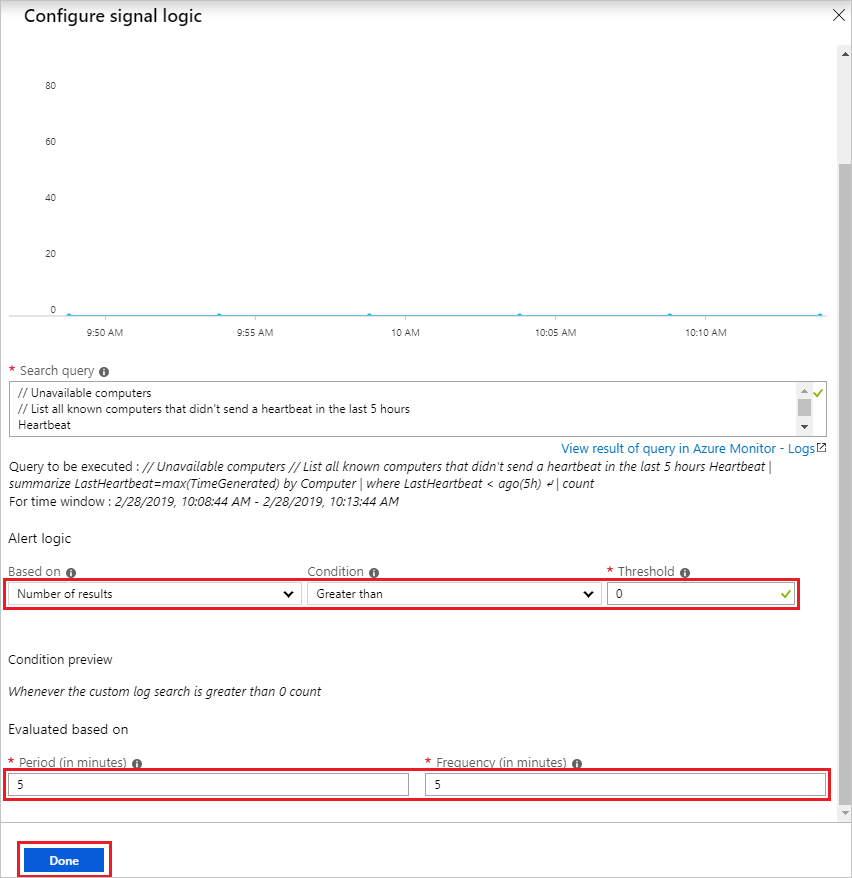
既存のアクション グループがまだない場合は、 [アクション グループ] セクション下にある [新規作成] をクリックします。
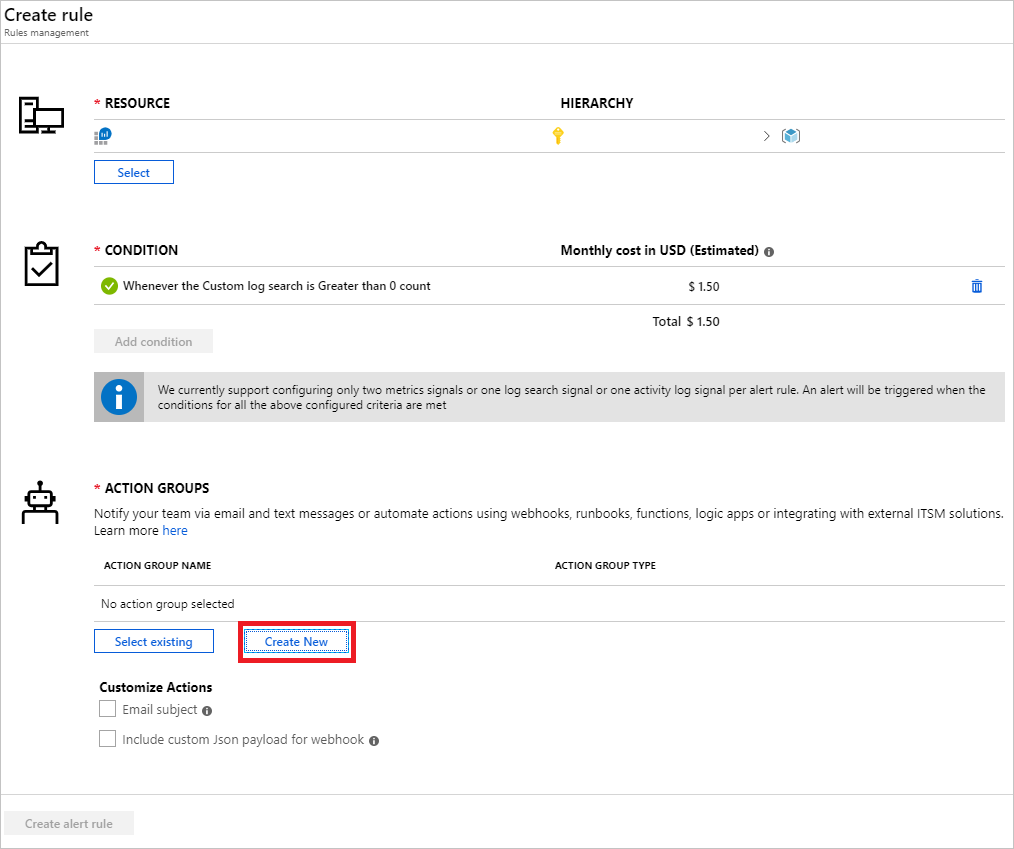
これにより、 [アクション グループの追加] が開きます。 [アクション グループ名]、[短い名前]、[サブスクリプション]、[リソース グループ] を選択します。[アクション] セクションで [アクション名] を選択し、[アクションの種類] として [メール/SMS/プッシュ/音声] を選択します。
注意
[Email/SMS/Push/Voice](電子メール/SMS/プッシュ/音声) 以外にも、Azure Function、LogicApp、Webhook、ITSM、および Automation Runbook など、アラートがトリガーできる他のアクションが複数あります。 詳細を確認してください。
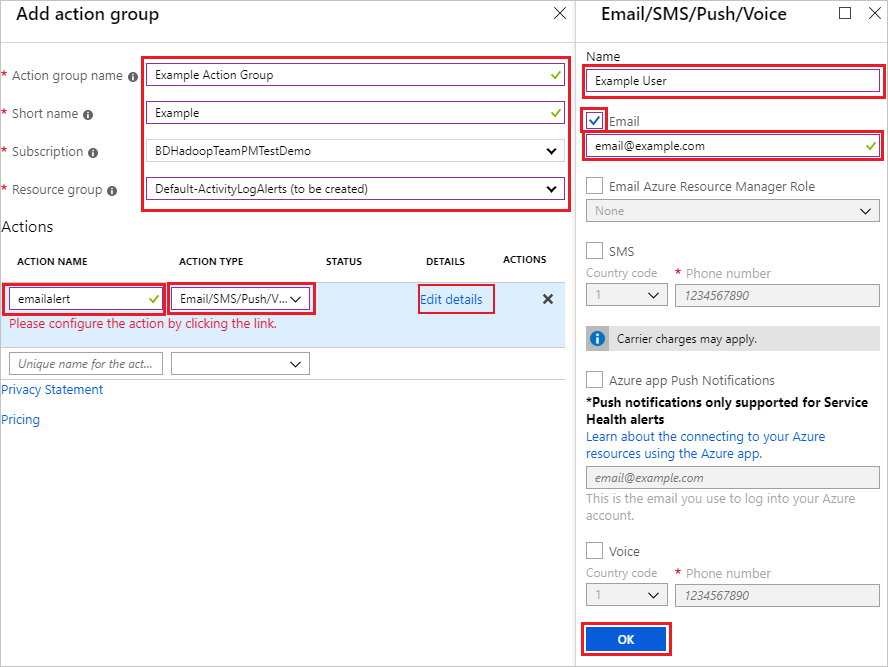
これにより、 [Email/SMS/Push/Voice](電子メール/SMS/プッシュ/音声) が開きます。 受信者の [名前] を選択し、 [電子メール] チェック ボックスをオンにして、アラートの送信先になる電子メール アドレスを入力します。 [メール/SMS/プッシュ/音声]、次に [アクション グループの追加] で [OK] を選択して、アクション グループの構成を終えます。
これらのブレードを閉じた後、 [アクション グループ] セクション下にアクション グループが一覧表示されていることを確認できます。 最後に、 [アラート ルール名] と [説明] を入力して、 [重大度] を選択し、 [アラートの詳細] セクションを完成させます。 [アラート ルールの作成] をクリックして完了します。
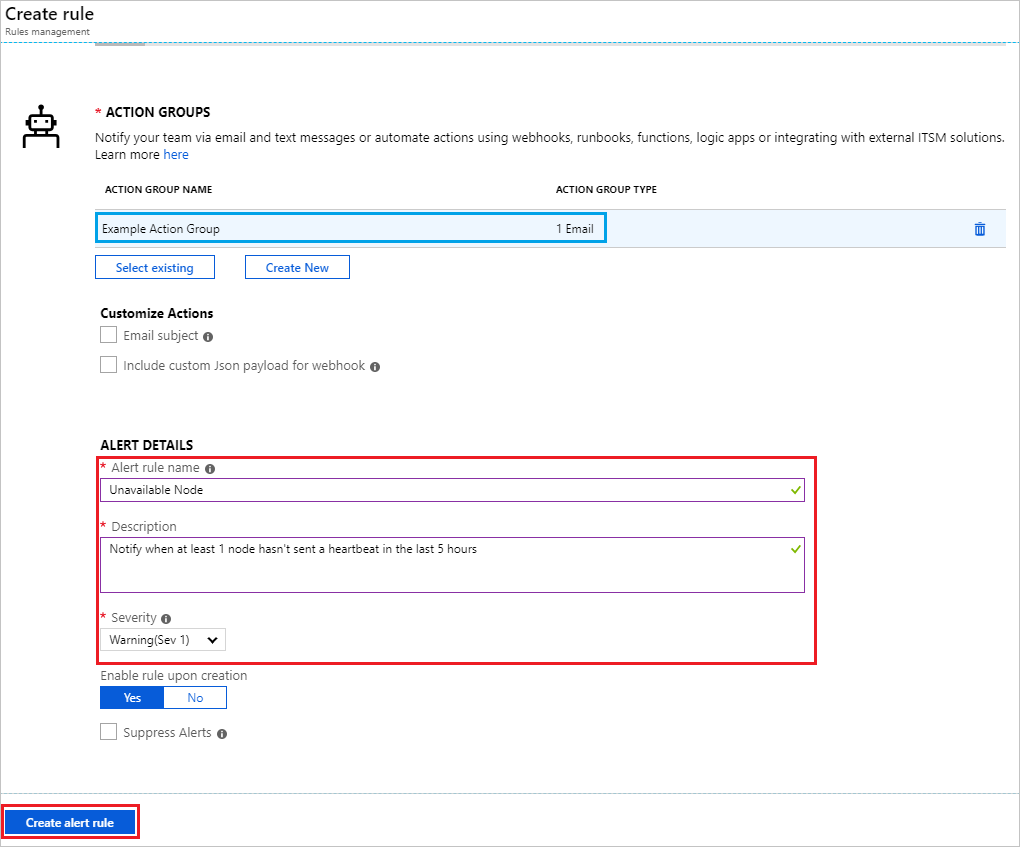
ヒント
[重大度] を指定する機能は、複数のアラートを作成する場合に使用できる優れたツールとなります。 たとえば、単一のヘッド ノードがダウンした場合に [警告] (重大度 1) を発生させる 1 つのアラートを作成し、両方のヘッド ノードがダウンするという想定外のイベントには [クリティカル] (重大度 1) を発生させるもう 1 つのアラートを作成することが可能です。
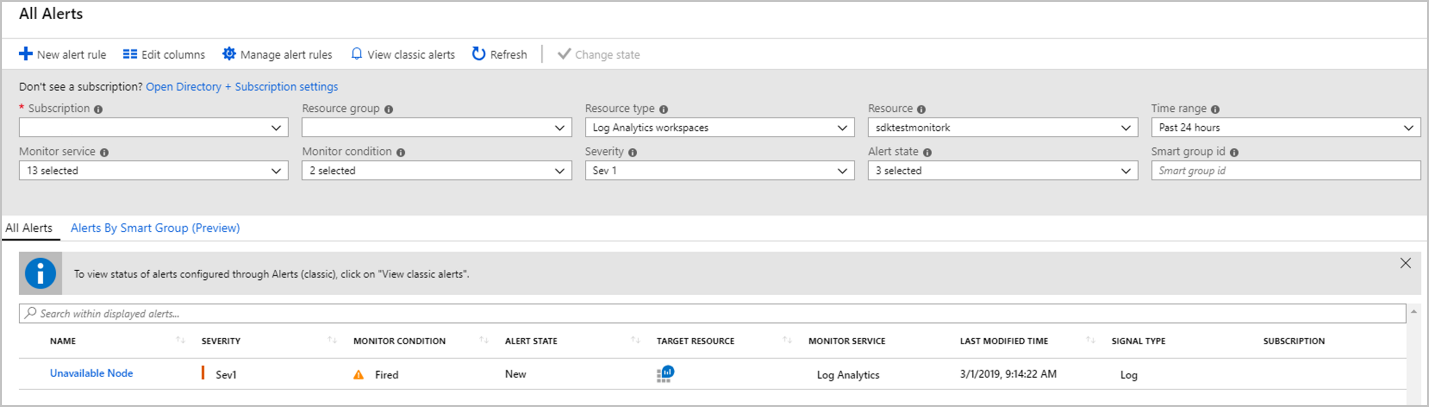
このアラートの条件と一致した場合、アラートが発生し、次のようなアラートの詳細を含む電子メールを受信します。
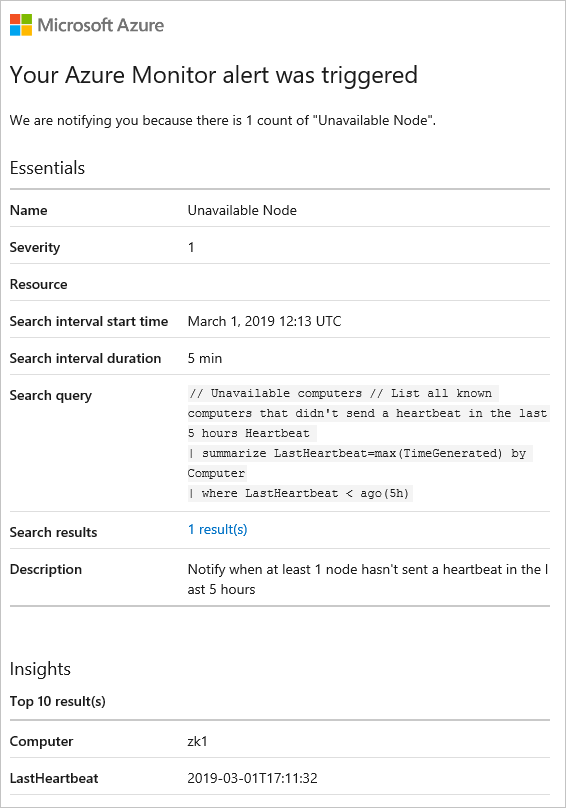
また、Log Analytics ワークスペースの [アラート] に移動して、発生したすべてのアラートを重大度別にグループ化して表示することもできます。
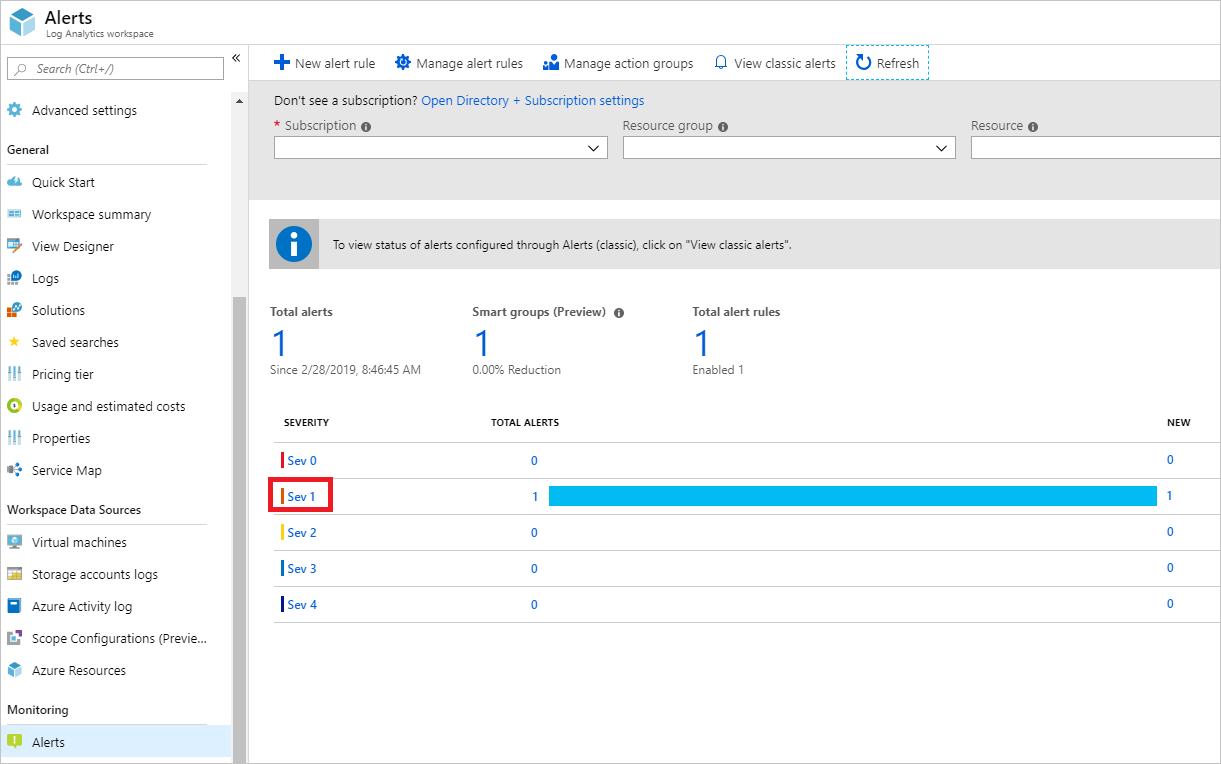
重要度グループ (上の例で言えば強調表示されている [重大度 1]) を選択すると、以下のように発生したその重大度の全アラートのレコードが表示されます。