Azure HDInsight の Apache Hadoop の概要
Apache Hadoop は本来、クラスターでのビッグ データ セットの分散処理および分析のためのオープンソース フレームワークでした。 Hadoop エコシステムには、Apache Hive、Apache HBase、Spark、Kafka、その他の多くの関連するソフトウェアおよびユーティリティが含まれます。
Azure HDInsight は、フル マネージドの、全範囲に対応した、クラウド上のオープンソースのエンタープライズ向け分析サービスです。 Azure HDInsight の Apache Hadoop クラスター タイプでは、Apache Hadoop 分散ファイル システム (HDFS)、Apache Hadoop YARN によるリソース管理、シンプルな MapReduce プログラミング モデルを使用して、バッチ データを並列に処理して分析することができます。 HDInsight の Hadoop クラスターは、Azure Data Lake Storage Gen2 と互換性があります。
HDInsight で利用可能な Hadoop テクノロジ スタック コンポーネントを確認するには、HDInsight で利用可能なコンポーネントとバージョンに関する記事を参照してください。 HDInsight の Hadoop については、HDInsight 向けの Azure の機能に関するページを参照してください。
MapReduce とは
Apache Hadoop MapReduce は、膨大なデータを処理するジョブを記述するためのソフトウェア フレームワークです。 入力データは、独立したチャンクに分割されます。 各チャンクは、クラスター内のノード全体で並列に処理されます。 MapReduce ジョブは次の 2 つの関数で構成されます。
Mapper: 入力データを使用して分析し (通常はフィルターと並べ替え操作を使用)、タプル (キーと値のペア) を出力します。
Reducer: Mapper で出力されるタプルを使用して、Mapper データから、より小さい結合結果を作成する要約操作を実行します。
次の図では、基本的なワード カウント MapReduce ジョブの例を示します。
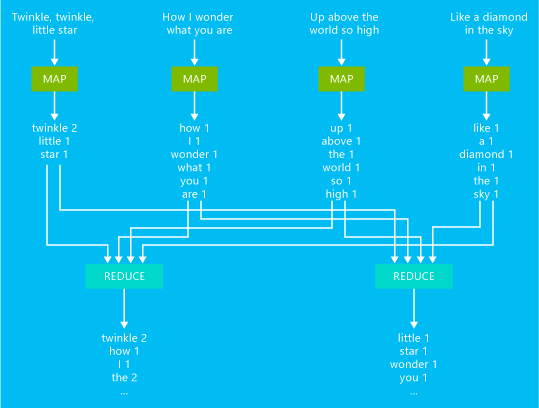
このジョブの出力は、テキストでの各単語の出現回数です。
- まず、Mapper が入力テキストから各行を読み込み、単語に分解して、 単語が出現するたびにキーと値のペア (キーは単語、値は 1) が出力されます。 出力は reducer に送信する前に並べ替えられます。
- reducer は、各単語の個々のカウントを合計し、単語とその後に続く合計出現回数から成る単一のキーと値のペアを出力します。
さまざまな言語で MapReduce を実装することができます。 Java は最も一般的な実装で、このドキュメントでのデモンストレーションのために使用されます。
開発言語
Java や Java 仮想マシンに基づく言語またはフレームワークは、MapReduce ジョブとして直接実行できます。 このドキュメントで使用されている例は、Java MapReduce アプリケーションです。 C# や Python などの Java 以外の言語、またはスタンドアロンの実行可能ファイルでは Hadoop ストリーミングを使用する必要があります。
Hadoop ストリーミングは、STDIN と STDOUT 上で mapper や reducer と通信します。 mapper と reducer は、STDIN から一度に 1 行ずつデータを読み取り、STDOUT に出力を書き込みます。 mapper と reducer によって読み取りまたは出力が行われる各行は、以下のように、タブ文字で区切られたキーと値のペアの形式である必要があります。
[key]\t[value]
詳細については、「 Hadoop ストリーミング」を参照してください。
HDInsight での Hadoop ストリーミングの使用例については、以下のドキュメントを参照してください。
どこから始めるか
- クイック スタート:Azure portal を使用して Azure HDInsight 内に Apache Hadoop クラスターを作成する
- チュートリアル: HDInsight で Apache Hadoop ジョブを送信する
- HDInsight 上の Apache Hadoop 用の Java MapReduce プログラムを開発する
- 抽出、変換、読み込み (ETL) ツールとして Apache Hive を使用する
- 大規模な抽出、変換、および読み込み (ETL)
- データ分析パイプラインを運用化する