クイック スタート:Azure portal を使用して Azure HDInsight 内に Apache Kafka クラスターを作成する
Apache Kafka は、オープンソースの分散ストリーミング プラットフォームです。 発行/サブスクライブ メッセージ キューと同様の機能を備えているため、メッセージ ブローカーとして多く使われています。
このクイックスタートでは、Azure portal を使用して Apache Kafka クラスターを作成する方法について説明します。 Apache Kafka を使って、付属のユーティリティでメッセージを送受信する方法についても説明します。 使用できる構成の詳細については、HDInsight でクラスターを設定する方法に関するページを参照してください。 ポータルを使用したクラスター作成の詳細については、ポータルでクラスターを作成する方法に関するページを参照してください。
警告
HDInsight クラスターの料金は、そのクラスターを使用しているかどうかに関係なく、分単位で課金されます。 使用後は、クラスターを必ず削除してください。 「HDInsight クラスターを削除する方法」をご覧ください。
Apache Kafka API は、同じ仮想ネットワーク内のリソースによってのみアクセスできます。 このクイックスタートでは、SSH を使って直接クラスターにアクセスします。 他のサービス、ネットワーク、または仮想マシンを Apache Kafka に接続するには、まず、仮想ネットワークを作成してから、ネットワーク内にリソースを作成する必要があります。 詳しくは、仮想ネットワークを使用した Apache Kafka への接続に関するドキュメントをご覧ください。 HDInsight に使用する仮想ネットワークの計画全般の情報については、Azure HDInsight 用仮想ネットワークの計画に関する記事を参照してください。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
SSH クライアント 詳細については、SSH を使用して HDInsight (Apache Hadoop) に接続する方法に関するページを参照してください。
Apache Kafka クラスターを作成する
HDInsight で Apache Kafka クラスターを作成するには、次の手順に従います。
Azure portal にサインインします。
上部のメニューで、 [+ リソースの作成] を選択します。
[分析]>[Azure HDInsight] の順に選択して [HDInsight クラスターの作成] ページに移動します。
[基本] タブで次の情報を指定します。
プロパティ 説明 サブスクリプション ドロップダウン リストから、このクラスターに使用する Azure サブスクリプションを選択します。 Resource group リソース グループを作成するか、既存のリソース グループを選択します。 リソース グループとは、Azure コンポーネントのコンテナーです。 この場合、リソース グループには、HDInsight クラスターおよび依存する Azure ストレージ アカウントが含まれています。 クラスター名 グローバルに一意の名前を入力します。 この名前は、文字、数字、ハイフンを含む最大 59 文字で構成できます。 名前の先頭と末尾の文字をハイフンにすることはできません。 リージョン クラスターの作成先となるリージョンをドロップダウン リストから選択します。 パフォーマンスを向上させるため、お近くのリージョンを選択してください。 クラスターの種類 [クラスターの種類の選択] を選択して一覧を開きます。 その一覧から、クラスターの種類として [Kafka] を選択します。 Version クラスターの種類には、既定のバージョンが指定されます。 異なるバージョンを指定したい場合は、ドロップダウン リストから選択してください。 クラスター ログイン ユーザー名とパスワード 既定のログイン名は adminです。 パスワードは 10 文字以上で、数字、大文字、小文字、英数字以外の文字 (' ` "を除く) が少なくとも 1 つずつ含まれる必要があります。Pass@word1などのよく使われるパスワードを指定しないようにしてください。Secure Shell (SSH) ユーザー名 既定のユーザー名は sshuserです。 SSH ユーザー名に別の名前を指定できます。SSH にクラスター ログイン パスワードを使用する クラスター ログイン ユーザーに指定したのと同じパスワードを SSH ユーザーに使用する場合は、このチェック ボックスをオンにします。 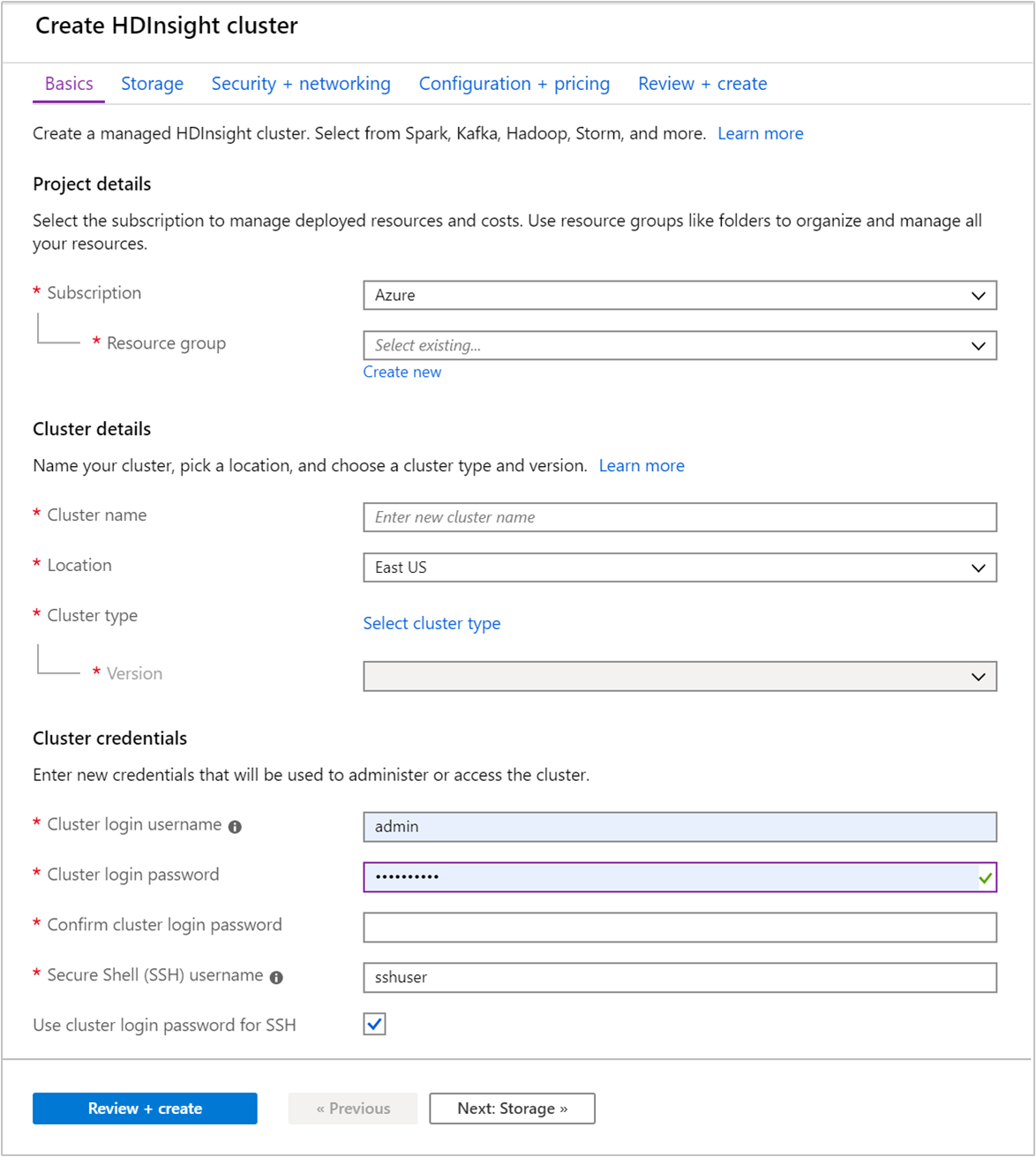
各 Azure リージョン (場所) は "障害ドメイン" を提供します。 障害ドメインとは、Azure データ センター内にある基になるハードウェアの論理的なグループです。 各障害ドメインは、一般的な電源とネットワーク スイッチを共有します。 HDInsight クラスター内のノードを実装する仮想マシンと管理ディスクは、これらの障害ドメインに分散されます。 このアーキテクチャにより、物理的なハードウェア障害の潜在的な影響が制限されます。
データの高可用性を実現するために、3 つの障害ドメイン を含むリージョン (場所) を選択します。 リージョン内の障害ドメインの数については、Linux 仮想マシンの可用性に関するトピックを参照してください。
ページの下部にある [次へ: ストレージ >>] タブを選択して、ストレージの設定に進みます。
[ストレージ] タブから次の値を指定します。
プロパティ 説明 プライマリ ストレージの種類 既定値の [Azure Storage] を使用します。 メソッドの選択 既定値の [一覧から選択する] を使用します。 プライマリ ストレージ アカウント ドロップダウン リストを使用して既存のストレージ アカウントを選択するか、または [新規作成] を選択します。 新しいアカウントの作成時には、名前の長さは 3 から 24 文字とし、数字と小文字のみを使用できます コンテナー 自動入力されている値を使用します。 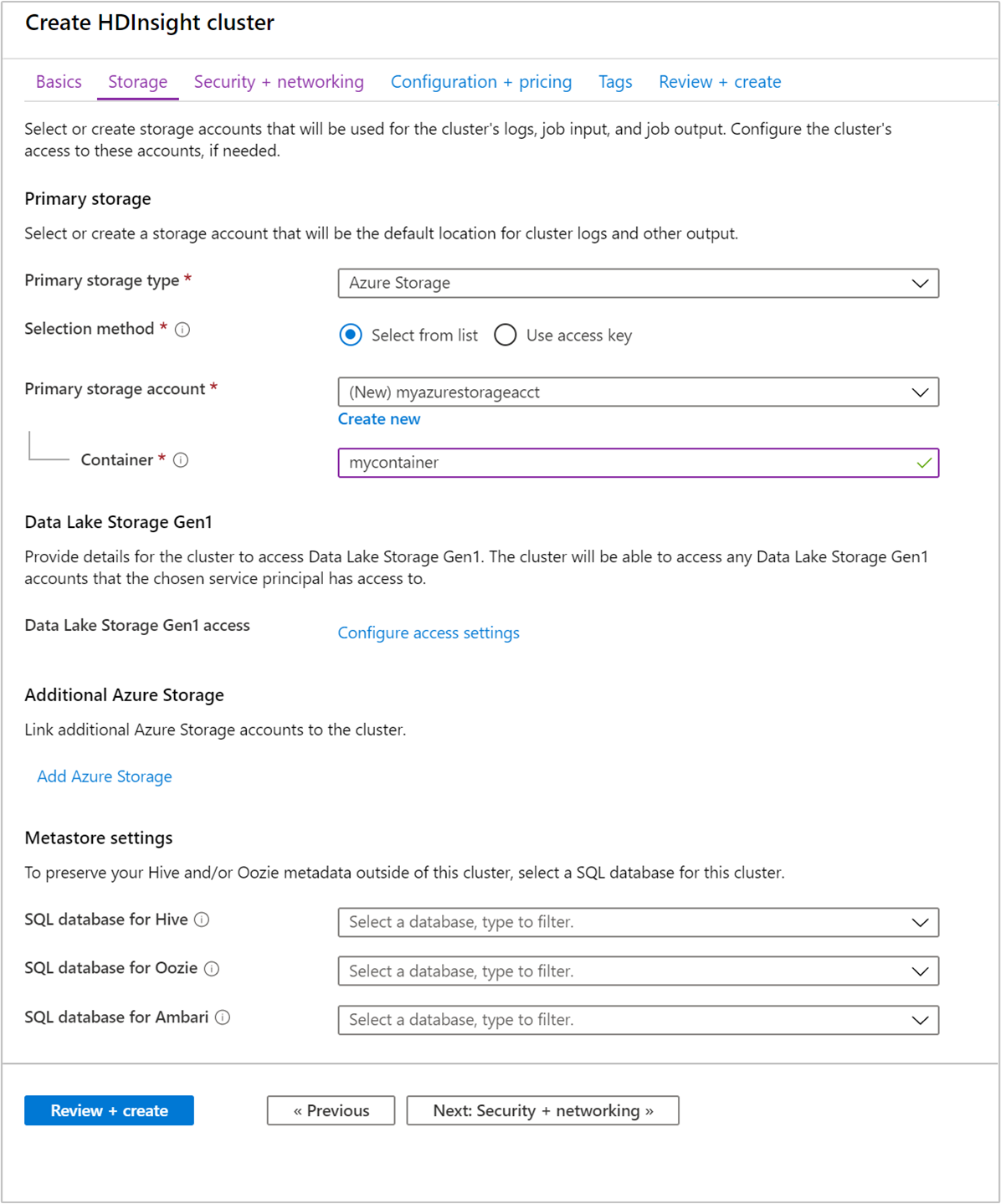
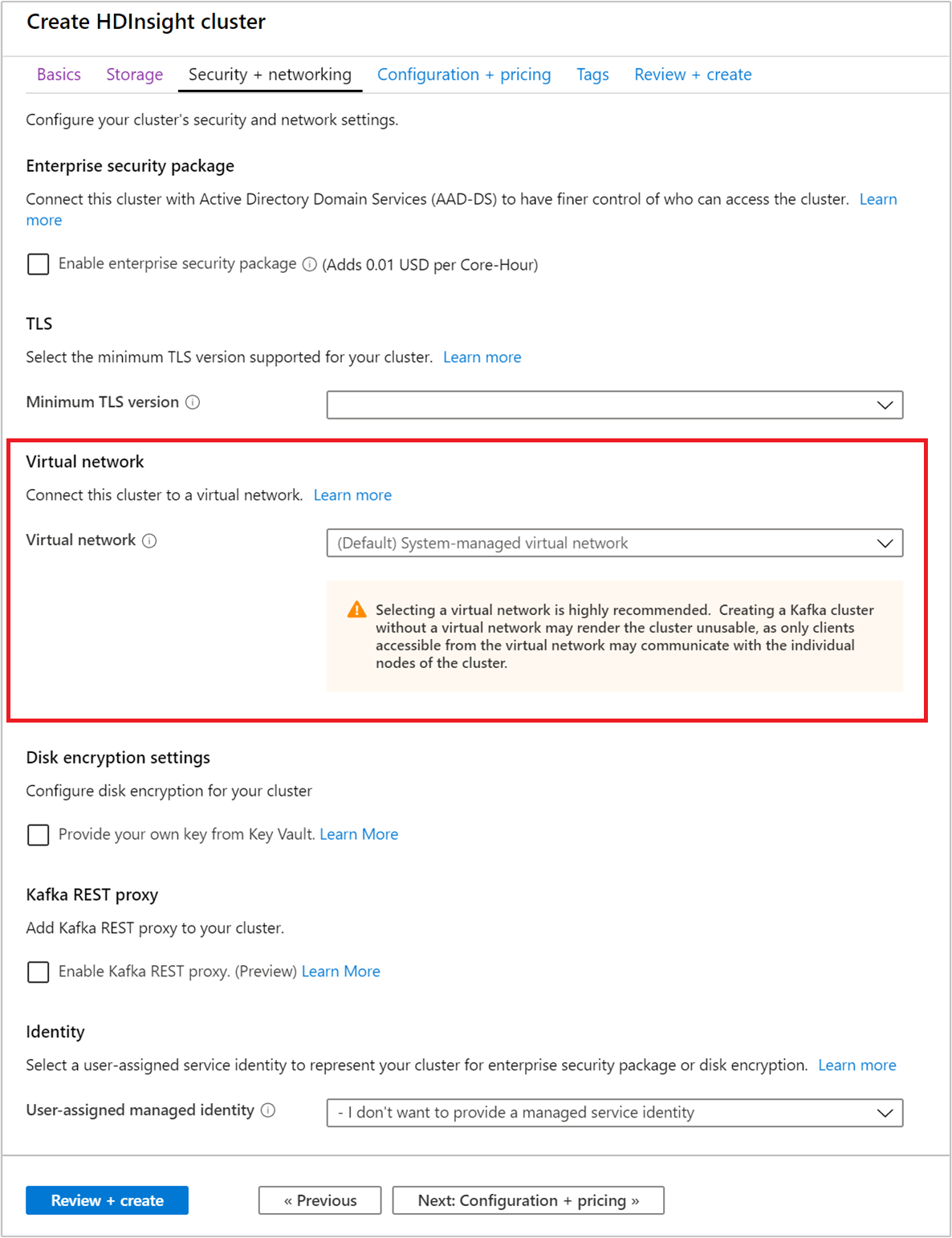
[セキュリティとネットワーク] タブを選択します。
このクイックスタートでは、既定のセキュリティ設定をそのまま使用します。 Enterprise セキュリティ パッケージの詳細については、Microsoft Entra Domain Services を使用して、Enterprise セキュリティ パッケージで HDInsight クラスターを構成する方法に関する記事を参照してください。 Apache Kafka ディスク暗号化に独自のキーを使用する方法については、「お客様が管理するキー ディスクの暗号化」を参照してください
クラスターを仮想ネットワークに接続したい場合は、 [仮想ネットワーク] ボックスの一覧からいずれかの仮想ネットワークを選択します。
[Configuration + pricing](構成と価格) タブを選択します。
HDInsight 上の Apache Kafka の可用性を確保するため、 [ワーカー ノード] の [ノード数] エントリを 3 以上に設定する必要があります。 既定値は 4 ですが、
[Standard disks per worker node](ワーカー ノードごとの標準ディスク数) は、HDInsight における Apache Kafka のスケーラビリティを構成する項目です。 HDInsight 上の Apache Kafka は、クラスターの仮想マシンのローカル ディスクを使って、データを保存します。 Apache Kafka は I/O が多いため、Azure Managed Disks を使ってノードごとに高いスループットと多くの記憶域を提供します。 マネージド ディスクの種類は、Standard (HDD) または Premium (SSD) です。 ディスクの種類は、ワーカー ノード (Apache Kafka ブローカー) によって使われる VM のサイズによって異なります。 DS および GS シリーズの VM では、Premium ディスクが自動的に使われます。 他の種類の VM はすべて Standard を使います。
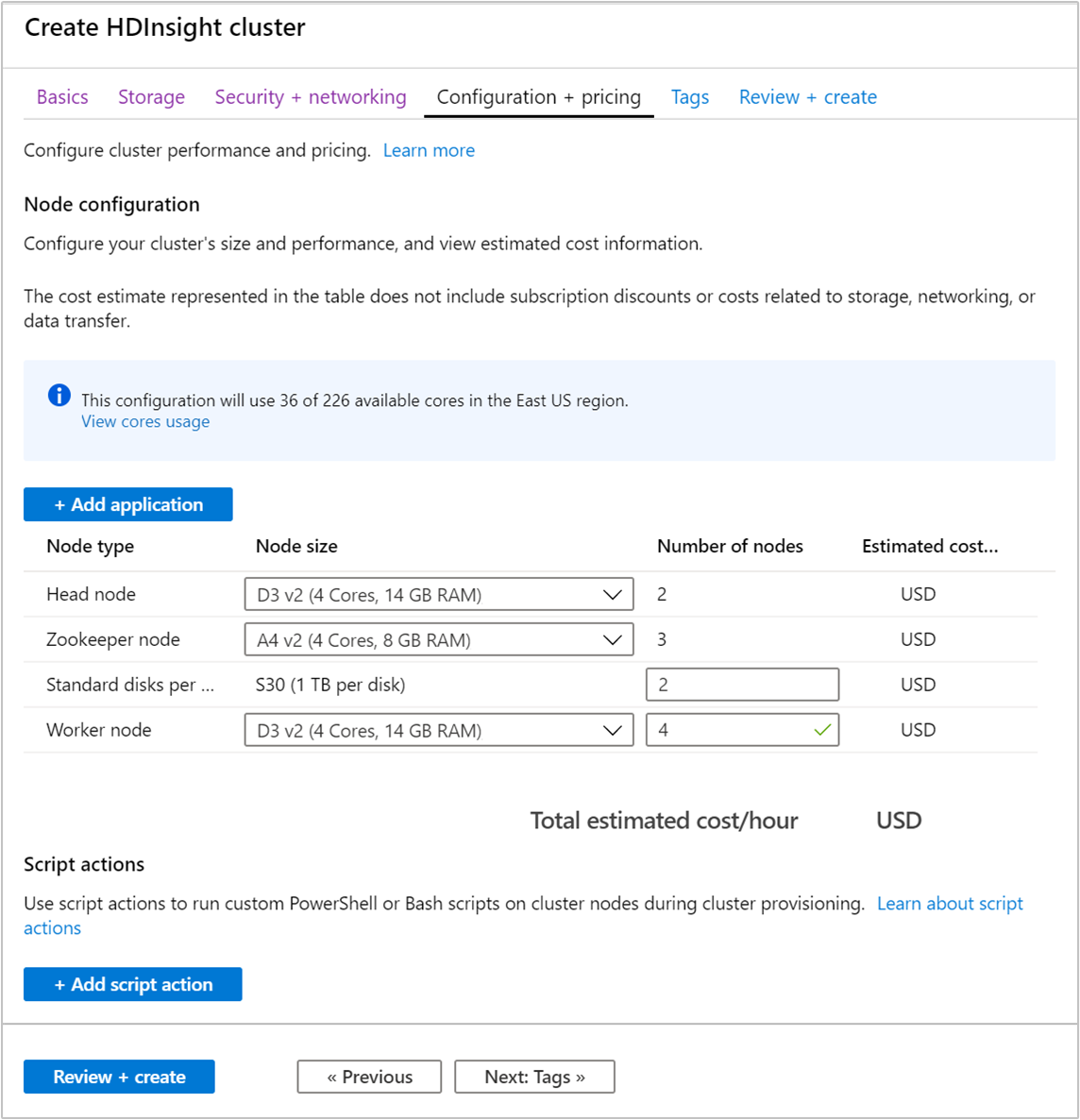
[確認および作成] タブを選択します。
クラスターの構成を確認します。 正しくない設定があれば変更します。 最後に、 [作成] を選択してクラスターを作成します。
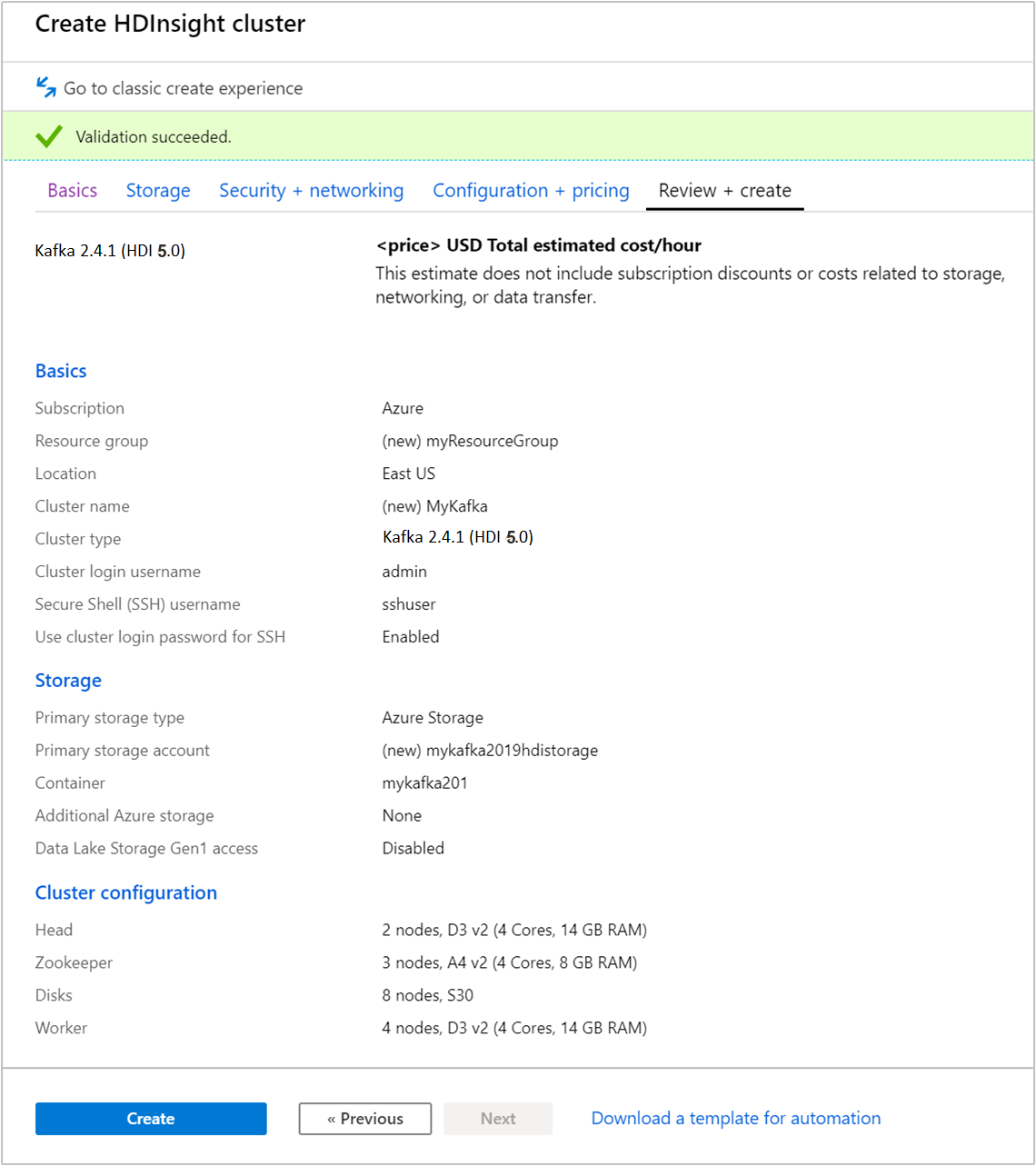
クラスターの作成には最大で 20 分かかります。
クラスターに接続する
ssh コマンドを使用してクラスターに接続します。 次のコマンドを編集して CLUSTERNAME をクラスターの名前に置き換えてから、そのコマンドを入力します。
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netメッセージが表示されたら、SSH ユーザーのパスワードを入力します。
接続されると、次のテキストのような情報が表示されます。
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Apache Zookeeper およびブローカーのホスト情報を取得する
Kafka を使うときは、Apache Zookeeper ホストと "ブローカー" ホストについて理解しておく必要があります。 これらのホストは、Apache Kafka の API や、Kafka に付属するユーティリティの多くで使用されます。
このセクションでは、クラスターで Apache Ambari REST API からホスト情報を取得します。
コマンド ライン JSON プロセッサの jq をインストールします。 このユーティリティは JSON ドキュメントを解析するためのものであり、ホスト情報の解析に役立ちます。 開いた SSH 接続から次のコマンドを入力して、
jqをインストールします。sudo apt -y install jqパスワード変数を設定します。
PASSWORDをクラスターのログイン パスワードに置き換えてから、次のコマンドを入力します。export PASSWORD='PASSWORD'大文字と小文字が正しく区別されたクラスター名を抽出します。 クラスターの作成方法によっては、クラスター名の実際の大文字小文字の区別が予想と異なる場合があります。 このコマンドは、実際の大文字小文字の区別を取得し、変数に格納します。 次のコマンドを入力します。
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Note
クラスターの外部からこのプロセスを実行している場合は、クラスター名を格納するための別の手順があります。 Azure portal からクラスター名を小文字で取得します。 その後、次のコマンドの
<clustername>をクラスター名に置き換えて、export clusterName='<clustername>'を実行します。Zookeeper ホスト情報で環境変数を設定するには、次のコマンドを使用します。 このコマンドはすべての Zookeeper ホストを取得してから、最初の 2 つのエントリのみを返します。 これは、1 つのホストに到達できない場合に、いくらかの冗長性が必要なためです。
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Note
このコマンドでは、Ambari アクセスが必要です。 クラスターが NSG の背後にある場合は、Ambari にアクセスできるコンピューターからこのコマンドを実行します。
環境変数が正しく設定されていることを確認するには、次のコマンドを使用します。
echo $KAFKAZKHOSTSこのコマンドでは、次のテキストのような情報が返されます。
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Apache Kafka ブローカー ホスト情報で環境変数を設定するには、次のコマンドを使用します。
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Note
このコマンドでは、Ambari アクセスが必要です。 クラスターが NSG の背後にある場合は、Ambari にアクセスできるコンピューターからこのコマンドを実行します。
環境変数が正しく設定されていることを確認するには、次のコマンドを使用します。
echo $KAFKABROKERSこのコマンドでは、次のテキストのような情報が返されます。
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Apache Kafka トピックの管理
Kafka は、"トピック" にデータのストリームを格納します。 kafka-topics.sh ユーティリティを使って、トピックを管理できます。
トピックを作成するには、SSH 接続で次のコマンドを使います。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSこのコマンドは、
$KAFKABROKERSに格納されているホスト情報を使ってブローカーに接続します。 次に、test という名前の Apache Kafka トピックが作成されます。このトピックに格納されるデータは、8 つのパーティションに分割されます。
各パーティションは、クラスター内の 3 つのワーカー ノード間でレプリケートされます。
3 つの障害ドメインを提供する Azure リージョンにクラスターを作成した場合は、3 のレプリケーション係数を使います。 そうでない場合は、4 のレプリケーション係数を使います。
3 つの障害ドメインがあるリージョンでは、3 のレプリケーション係数により、レプリカを障害ドメインに分散できます。 2 つの障害ドメインのリージョンでは、4 のレプリケーション係数により、ドメイン全体に均等にレプリカが分散されます。
リージョン内の障害ドメインの数については、Linux 仮想マシンの可用性に関するトピックを参照してください。
Apache Kafka は、Azure 障害ドメインを認識しません。 トピック用にパーティションのレプリカを作成すると、レプリカが適切に分散されず、高可用性が実現しない場合があります。
高可用性を確保するには、Apache Kafka パーティション再調整ツールを使用してください。 このツールは、Apache Kafka クラスターのヘッド ノードへの SSH 接続から実行する必要があります。
Apache Kafka データの最高の可用性のために、次のときにトピックのパーティションのレプリカを再調整する必要があります。
新しいトピックまたはパーティションの作成
クラスターのスケールアップ
トピックの一覧を表示するには、次のコマンドを使います。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSこのコマンドは、Apache Kafka クラスターで使用可能なトピックの一覧を表示します。
トピックを削除するには、次のコマンドを使います。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSこのコマンドは、
topicnameという名前のトピックを削除します。警告
前に作成した
testトピックを削除した場合は、再作しなおす必要があります。 このドキュメントの後半で使います。
kafka-topics.sh ユーティリティで使用可能なコマンドの詳細については、次のコマンドを使用します。
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
レコードの生成および消費
Kafka では、トピック内にレコードが格納されます。 レコードは、プロデューサーによって生成され、コンシューマーによって消費されます。 プロデューサーとコンシューマーは "Kafka ブローカー" サービスと通信します。 HDInsight クラスターの各ワーカー ノードが、Apache Kafka ブローカー ホストです。
先ほど作成した test トピックにレコードを格納し、コンシューマーを使用してそれらを読み取るには、次の手順に従います。
トピックにレコードを書き込むには、SSH 接続から
kafka-console-producer.shユーティリティを使用します。/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testこのコマンドの後ろには空の行があります。
空の行にテキスト メッセージを入力して、Enter キーを押します。 このようにメッセージをいくつか入力してから、Ctrl + C キーを使用して通常のプロンプトに戻ります。 各行が、個別のレコードとして Apache Kafka トピックに送信されます。
トピックからレコードを読み取るには、SSH 接続から
kafka-console-consumer.shユーティリティを使用します。/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningこのコマンドにより、レコードがトピックから取得され、表示されます。
--from-beginningを使用することで、すべてのレコードが取得されるように、コンシューマーにストリームの先頭から開始するように指示しています。以前のバージョンの Kafka を使っている場合、
--bootstrap-server $KAFKABROKERSを--zookeeper $KAFKAZKHOSTSに置き換えます。Ctrl+C キーを使用してコンシューマーを停止します。
プロデューサーとコンシューマーをプログラムから作成することもできます。 この API の使用例については、HDInsight における Apache Kafka Producer API と Consumer API に関するドキュメントを参照してください。
リソースをクリーンアップする
このクイックスタートで作成したリソースをクリーンアップするために、リソース グループを削除できます。 リソース グループを削除すると、関連付けられている HDInsight クラスター、およびリソース グループに関連付けられているその他のリソースも削除されます。
Azure Portal を使用してリソース グループを削除するには:
- Azure Portal で左側のメニューを展開してサービスのメニューを開き、 [リソース グループ] を選択して、リソース グループの一覧を表示します。
- 削除するリソース グループを見つけて、一覧の右側にある [詳細] ボタン ([...]) を右クリックします。
- [リソース グループの削除] を選択し、確認します。
警告
HDInsight 上の Apache Kafka クラスターを削除すると、Kafka に格納されているすべてのデータが削除されます。