Azure Toolkit for IntelliJ を使用して HDInsight クラスター向けの Apache Spark アプリケーションを作成する
この記事では、IntelliJ IDE 用の Azure Toolkit プラグインを使用して Azure HDInsight 上の Apache Spark アプリケーションを開発する方法について説明します。 Azure HDInsight は、クラウドでのオープンソースのマネージド分析サービスです。 このサービスでは、Hadoop、Apache Spark、Apache Hive、Apache Kafka などのオープンソース フレームワークを使用できます。
Azure Toolkit プラグインには、次のような使い方があります。
- Scala Spark アプリケーションを開発して HDInsight Spark クラスターに送信する。
- Azure HDInsight Spark クラスター リソースにアクセスする。
- Scala Spark アプリケーションをローカルで開発して実行する。
この記事では、次のことについて説明します。
- Azure Toolkit for IntelliJ プラグインを使用する
- Apache Spark アプリケーションを開発する
- Azure HDInsight クラスターにアプリケーションを送信する
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。 パブリック クラウド内の HDinsight クラスターだけがサポートされ、他のセキュリティで保護されたクラウドの種類 (政府機関向けクラウドなど) はサポートされていません。
Oracle Java Development Kit。 この記事では、Java バージョン 8.0.202 を使用します。
IntelliJ IDEA。 この記事では、 IntelliJ のアイデア Community 2018.3.4を使用します。
Azure Toolkit for IntelliJ。 「Azure Toolkit for IntelliJ のインストール」を参照してください。
IntelliJ IDEA 用の Scala プラグインをインストールする
Scala プラグインをインストールする手順:
IntelliJ IDEA を開きます。
ようこそ画面で [構成]>[プラグイン] の順に移動し、 [プラグイン] ウィンドウを開きます。
新しいウィンドウに表示される Scala プラグインの [インストール] を選択します。
プラグインが正常にインストールされたら、IDE を再起動する必要があります。
HDInsight Spark クラスター向けの Spark Scala アプリケーションの作成
IntelliJ IDEA を起動し、 [Create New Project](新しいプロジェクトの作成) を選択して、 [New Project](新しいプロジェクト) ウィンドウを開きます。
左側のウィンドウの [Azure Spark/HDInsight] を選択します。
メイン ウィンドウで [Spark Project (Scala)](Spark プロジェクト (Scala)) を選択します。
[Build tool](ビルド ツール) ドロップダウン リストで、次のいずれかのオプションを選択します。
Scala プロジェクト作成ウィザードをサポートする場合は Maven。
依存関係を管理し、Scala プロジェクトをビルドする場合は SBT。
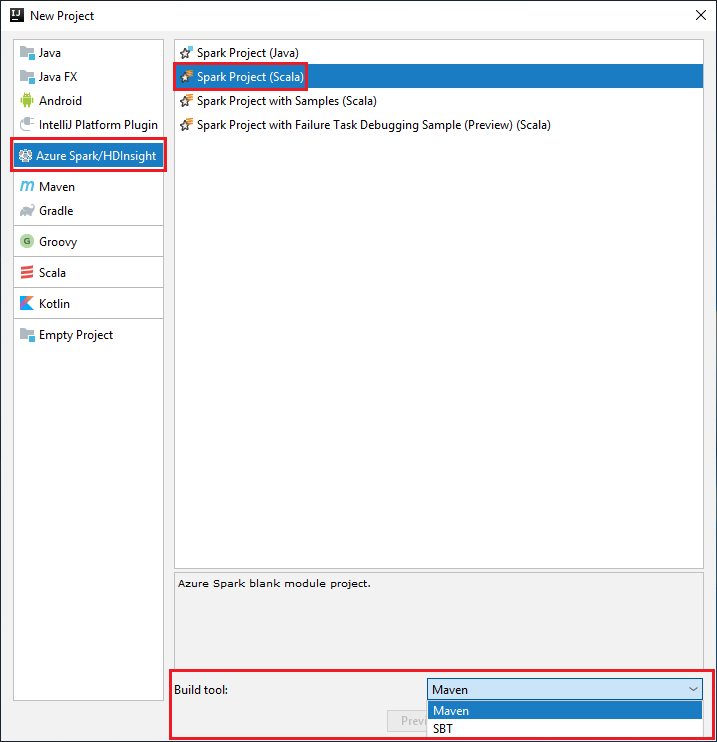
[次へ] を選択します。
[New Project](新しいプロジェクト) ウィンドウで、次の情報を指定します。
プロパティ 説明 プロジェクト名 名前を入力します。 この記事では、 myAppを使用します。プロジェクトの場所 プロジェクトを保存する場所を入力します。 Project SDK (プロジェクト SDK) IDEA を初めて使用するとき、このフィールドは空白の場合があります。 [New](新規作成) を選択し、自分の JDK に移動します。 Spark バージョン 作成ウィザードにより、Spark SDK と Scala SDK の適切なバージョンが統合されます。 Spark クラスターのバージョンが 2.0 より前の場合は、 [Spark 1.x] を選択します。 それ以外の場合は、 [Spark2.x] を選択します。 この例では、Spark 2.3.0 (Scala 2.11.8) を使用します。 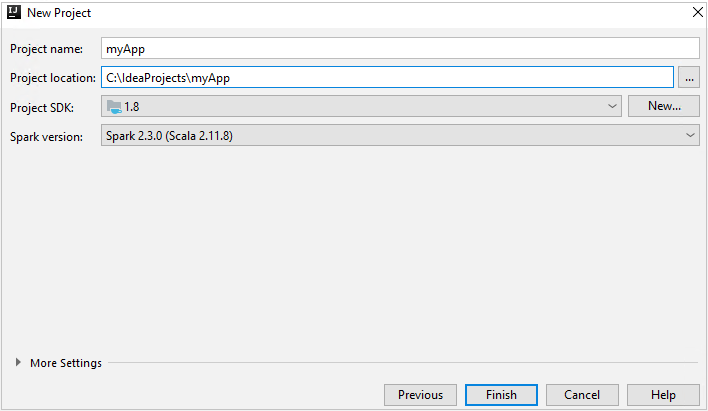
[完了] を選びます。 プロジェクトが使用可能になるまで数分かかる場合があります。
Spark プロジェクトによって自動的に成果物が作成されます。 成果物を表示するには、次の手順を実行します。
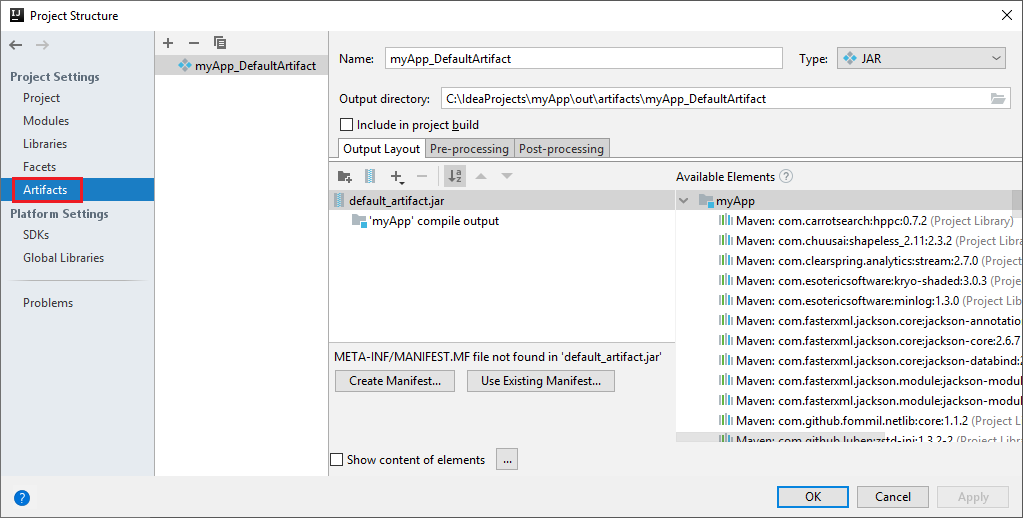
a. メニュー バーから、 [ファイル]>[プロジェクトの構造...] に移動します。
b. [プロジェクトの構造] ウィンドウで、 [アーティファクト] を選択します。
c. 成果物の表示後、 [キャンセル] をクリックします。
次の手順を行って、アプリケーション ソース コードを追加します。
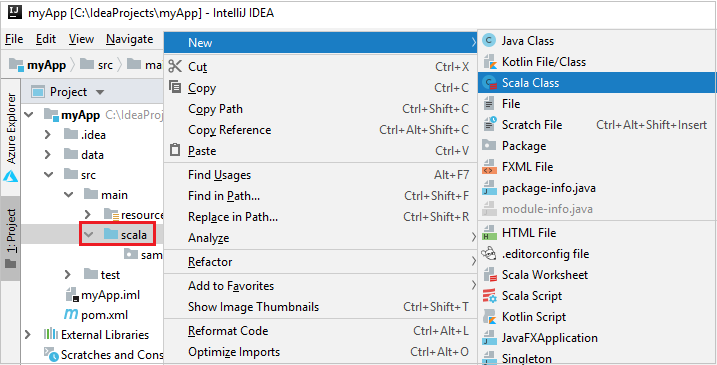
a. [プロジェクト] から、 [myApp]>[src]>[main]>[scala] に移動します。
b. [scala] を右クリックし、 [新規作成]>[Scala Class](Scala クラス) に移動します。
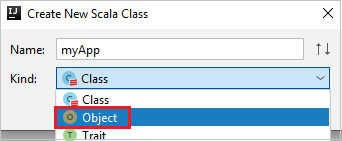
c. [Create New Scala Class](新規 Scala クラスの作成) ダイアログ ボックスで、名前を指定し、 [Kind](種類) ドロップダウン リストで [Object](オブジェクト) を選択して、 [OK] をクリックします。
d. myApp.scala ファイルがメイン ビューで開きます。 既定のコードを次のコードに置き換えます。
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }このコードは HVAC.csv (すべての HDInsight Spark クラスターで使用可能) からデータを読み取り、CSV ファイルの 7 番目の列に 1 桁の数字のみが含まれる行を取得し、出力をクラスター用の既定のストレージ コンテナーの下にある
/HVACOutに書き込みます。
HDInsight クラスターに接続する
ユーザーは、Azure サブスクリプションにサインインするか、HDInsight クラスターをリンクすることができます。 Ambari のユーザー名とパスワードまたはドメイン参加済みの資格情報を使用して、HDInsight クラスターに接続します。
Azure サブスクリプションにサインインします。
メニュー バーから、 [表示]>[ツール ウィンドウ]>[Azure Explorer] に移動します。
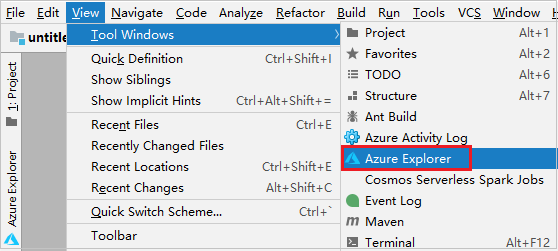
Azure Explorer から、 [Azure] ノードを右クリックし、 [サインイン] を選択します。
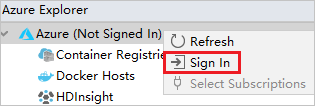
[Azure Sign In](Azure サインイン) ダイアログ ボックスで、 [デバイスのログイン] を選択してから、 [サインイン] を選択します。
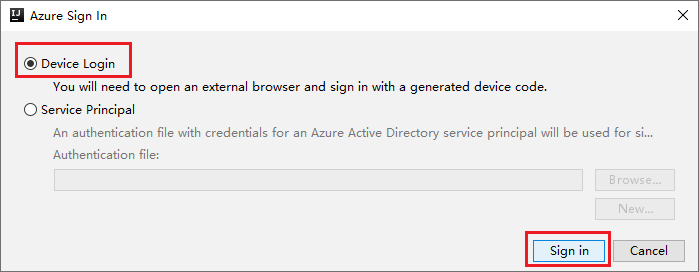
[Azure Device Login]\(Azure デバイスのログイン\) ダイアログ ボックスで [Copy&Open]\(コピーして開く\) をクリックします。
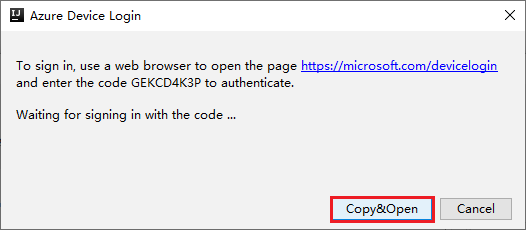
ブラウザー インターフェイスで、コードを貼り付けて [次へ] をクリックします。
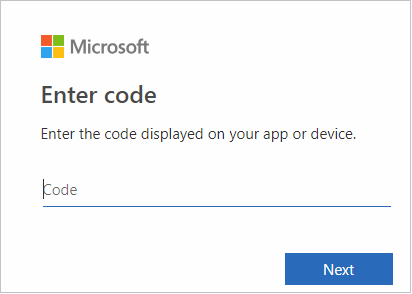
自分の Azure 資格情報を入力して、ブラウザーを閉じます。
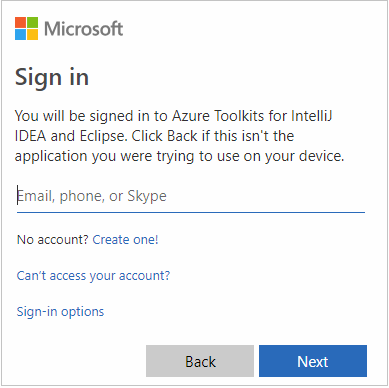
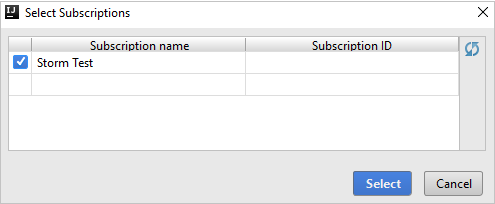
サインイン後、 [Select Subscriptions](サブスクリプションの選択) ダイアログ ボックスに、その資格情報に関連付けられているすべての Azure サブスクリプションの一覧が表示されます。 サブスクリプションを選択してから [選択] ボタンを選択します。
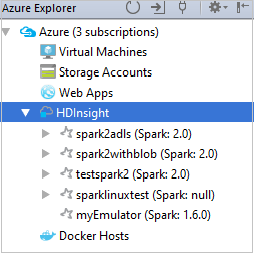
Azure Explorer から、 [HDInsight] を展開し、自分のサブスクリプションにある HDInsight Spark クラスターを表示します。
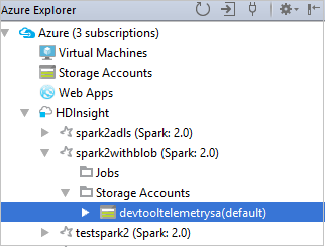
クラスターに関連付けられているリソース (ストレージ アカウントなど) を表示するには、クラスター名ノードをさらに展開します。
クラスターのリンク
Apache Ambari マネージド ユーザー名を使用して、HDInsight クラスターをリンクできます。 同様に、ドメイン参加済み HDInsight クラスターでは、user1@contoso.com などのドメインとユーザー名を使用して、リンクできます。 Livy Service クラスターをリンクすることもできます。
メニュー バーから、 [表示]>[ツール ウィンドウ]>[Azure Explorer] に移動します。
Azure Explorer から、 [HDInsight] ノードを右クリックし、 [Link A Cluster](クラスターのリンク) を選択します。
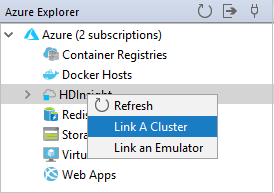
[Link A Cluster](クラスターのリンク) ウィンドウで使用可能なオプションは、 [Link Resource Type](リンクのリソースの種類) ドロップダウン リストから選択する値によって異なります。 値を入力して [OK] を選択します。
HDInsight クラスター
プロパティ 値 リンクのリソースの種類 ドロップダウン リストから [HDInsight クラスター] を選択します。 クラスター名/URL クラスター名を入力します。 認証の種類 [基本認証] のままにします [ユーザー名] クラスターのユーザー名を入力します。既定値は admin です。 Password ユーザー名のパスワードを入力します。 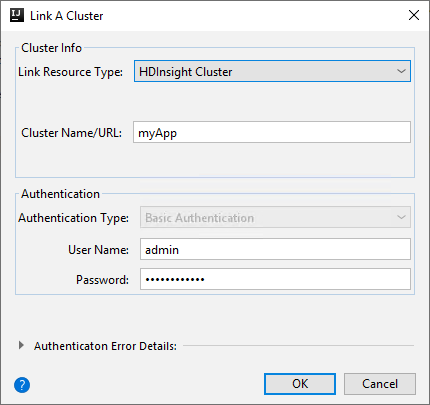
Livy サービス
プロパティ 値 リンクのリソースの種類 ドロップダウン リストから [Livy Service](Livy サービス) を選択します。 Livy エンドポイント Livy エンドポイントを入力します クラスター名 クラスター名を入力します。 Yarn エンドポイント 省略可能。 認証の種類 [基本認証] のままにします [ユーザー名] クラスターのユーザー名を入力します。既定値は admin です。 Password ユーザー名のパスワードを入力します。 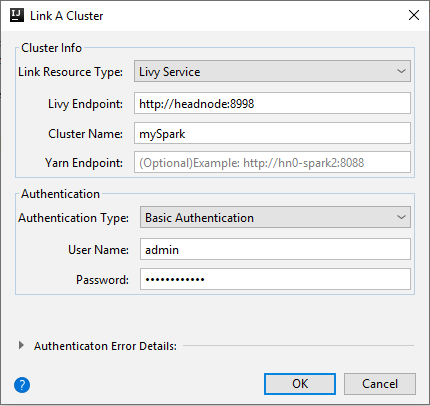
HDInsight ノードからリンクされたクラスターを確認できます。
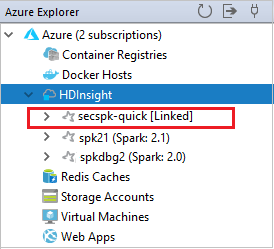
また、Azure 用エクスプローラーからクラスターのリンクを解除することもできます。
HDInsight Spark クラスターでの Spark Scala アプリケーションの実行
Scala アプリケーションを作成した後に、クラスターに送信できます。
[Project](プロジェクト) から myApp>src>main>scala>myApp に移動します。 [myApp] を右クリックし、 [Submit Spark Application](Spark アプリケーションの送信) を選択します (多くの場合、リストの最下部にあります)。
[Submit Spark Application](Spark アプリケーションの送信) ダイアログ ウィンドウで、 [1.Spark on HDInsight](HDInsight 上の Spark) を選択します。
[構成の編集] ウィンドウで、次の値を指定して [OK] を選択します。
プロパティ 値 Spark クラスター (Linux のみ) アプリケーションを実行する HDInsight Spark クラスターを選択します。 送信するアーティファクトの選択 既定の設定のままにします。 メイン クラス名 既定値は、選択したファイルのメイン クラスです。 クラスを変更するには、省略記号 ( ... ) をクリックし、別のクラスを選択します。 ジョブの構成 既定のキーと値のどちらかまたは両方を変更できます。 詳細については、Apache Livy REST API に関するページを参照してください。 コマンド ライン引数 必要に応じて、main クラスの引数をスペースで区切って入力できます。 参照される JAR と参照されるファイル 参照されている Jar およびファイルのパスを入力できます (存在する場合)。 現在 ADLS Gen 2 クラスターのみをサポートする Azure 仮想ファイル システム内のファイルを参照することもできます。 詳細情報:Apache Spark 構成。 リソースをクラスターにアップロードする方法に関するページも参照してください。 ジョブ アップロード ストレージ 展開して追加のオプションを表示します。 ストレージ型 ドロップダウン リストから [Use Azure Blob to upload](Azure BLOB を使用してアップロード) を選択します。 ストレージ アカウント ストレージ アカウントを入力します。 ストレージ キー ストレージ キーを入力します。 ストレージ コンテナー [ストレージ アカウント] と [ストレージ キー] の入力後、ドロップダウン リストからストレージ コンテナーを選択します。 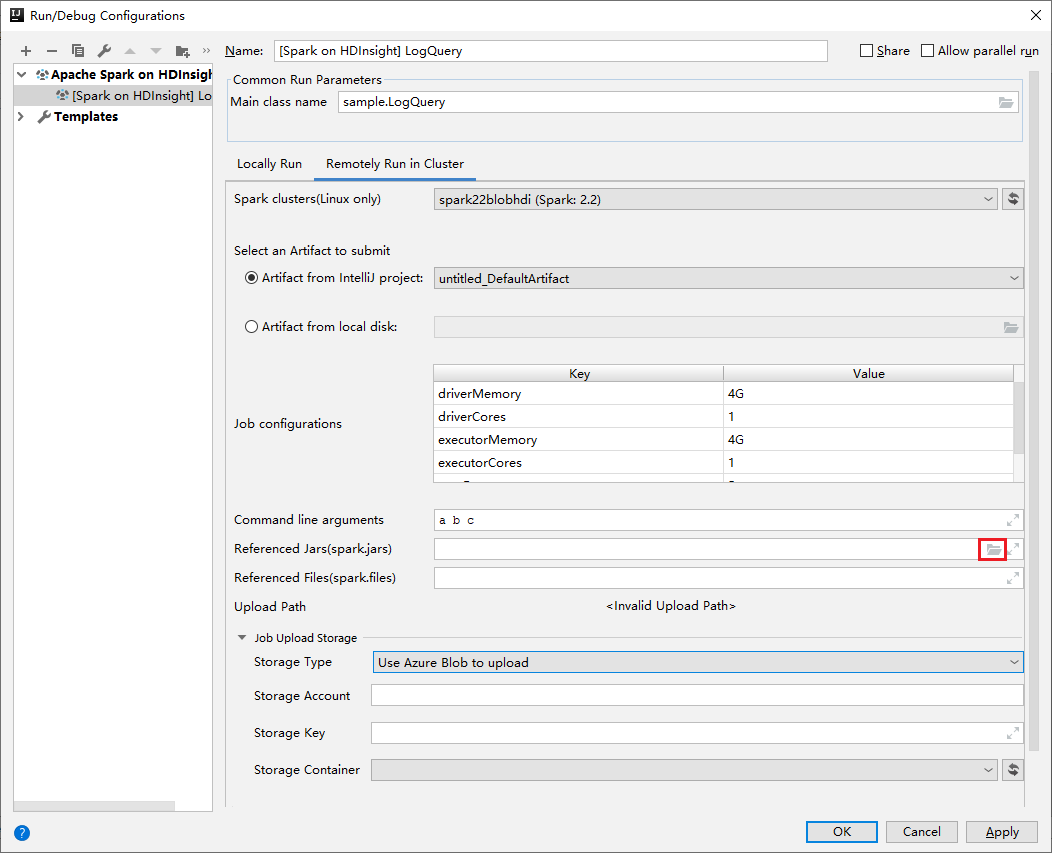
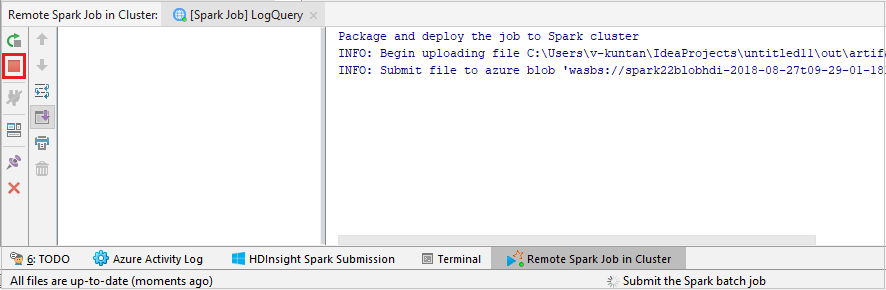
[SparkJobRun] を選択して、選択したクラスターにプロジェクトを送信します。 [Remote Spark Job in Cluster](クラスターのリモート Spark ジョブ) タブの下部には、ジョブの実行の進行状況が表示されます。 赤いボタンをクリックすると、アプリケーションを停止できます。
HDInsight クラスターで Apache Spark アプリケーションをローカルまたはリモートでデバッグする
クラスターに Spark アプリケーションを送信するお勧めの方法はほかにもあります。 それは、実行/デバッグ構成の IDE でパラメーターを設定する方法です。 Azure Toolkit for IntelliJ を使用した HDInsight クラスター上での SSH による Apache Spark アプリケーションのローカルまたはリモートでのデバッグに関するページを参照してください。
Azure Toolkit for IntelliJ を使用して HDInsight Spark クラスターにアクセスして管理する
Azure Toolkit for IntelliJ を使用してさまざまな操作を行うことができます。 ほとんどの操作は Azure Explorer から開始されます。 メニュー バーから、 [表示]>[ツール ウィンドウ]>[Azure Explorer] に移動します。
ジョブ ビューにアクセスする
Azure Explorer から、[HDInsight]><対象のクラスター>>[ジョブ] に移動します。
右側のウィンドウの [Spark Job View (Spark ジョブ ビュー)] タブに、クラスター上で実行されていたすべてのアプリケーションが表示されます。 詳細情報を確認したいアプリケーションの名前を選択します。
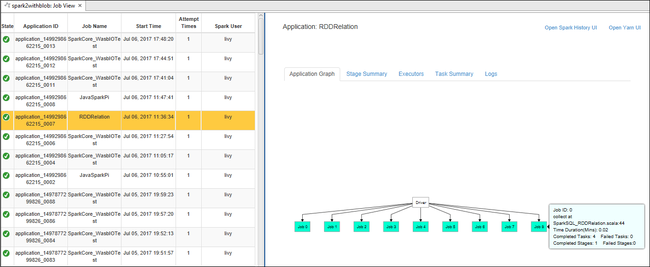
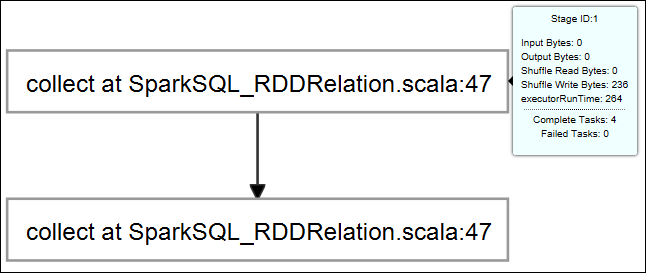
実行中のジョブの基本情報が表示するには、ジョブ グラフにマウス ポインターを合わせます。 各ジョブについて生成されるステージのグラフと情報を確認するには、ジョブ グラフ上のノードを選択します。
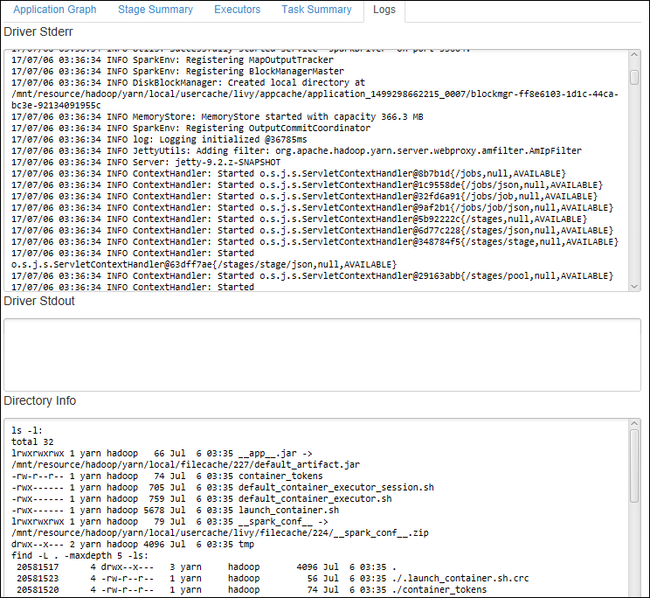
Driver Stderr、Driver Stdout、Directory Info などの頻繁に使用されるログを表示するには、 [Log](ログ) タブを選択します。
Spark 履歴 UI と YARN UI を (アプリケーション レベルで) 表示できます。 ウィンドウ上部のリンクを選択します。
Spark 履歴サーバーにアクセスする
Azure Explorer から、 [HDInsight] を展開します。Spark クラスター名を右クリックし、 [Open Spark History UI](Spark 履歴 UI を開く) を選択します。
入力を求められたら、クラスターの管理者資格情報 (クラスターの設定時に指定したもの) を入力します。
Spark 履歴サーバーのダッシュボードでは、実行が終了したばかりのアプリケーションをアプリケーション名を使って探すことができます。 上記のコードでは、
val conf = new SparkConf().setAppName("myApp")を使用してアプリケーション名を設定しました。 ご利用の Spark アプリケーション名は myApp です。
Ambari ポータルを起動する
Azure Explorer から、 [HDInsight] を展開します。Spark クラスター名を右クリックし、 [Open Cluster Management Portal (Ambari)](クラスター管理ポータルを開く (Ambari)) を選択します。
入力を求められたら、クラスターの管理者資格情報を入力します。 これらの資格情報は、クラスターの設定プロセス中に指定したものです。
Azure サブスクリプションの管理
Azure Toolkit for IntelliJ の既定では、すべての Azure サブスクリプションからの Spark クラスターが一覧表示されます。 必要に応じて、アクセスするサブスクリプションを指定できます。
Azure Explorer から、 [Azure] ルート ノードを右クリックし、 [サブスクリプションの選択] を選択します。
[サブスクリプションの選択] ウィンドウから、アクセスしないサブスクリプションのチェック ボックスをオフにして [閉じる] を選択します。
Spark コンソール
Spark Local Console(Scala) を実行するか、Spark Livy Interactive Session Console(Scala) を実行することができます。
Spark Local Console(Scala)
WINUTILS.EXE の前提条件を満たしていることを確実にします。
メニュー バーから、 [Run](実行)>[Edit Configurations](構成の編集) に移動します。
[Run/Debug Configurations](実行/デバッグ構成) ウィンドウから、左側のウィンドウで、 [Apache Spark on HDInsight](HDInsight 上の Apache Spark)>[Spark on HDInsight] myApp を選択します。
メイン ウィンドウで、 [
Locally Run] タブを選択します。次の値を指定し、 [OK] を選択します。
プロパティ 値 ジョブのメイン クラス 既定値は、選択したファイルのメイン クラスです。 クラスを変更するには、省略記号 ( ... ) をクリックし、別のクラスを選択します。 環境変数 HADOOP_HOME の値が正しいことを確認します。 WINUTILS.exe の場所 パスが正しいことを確認します。 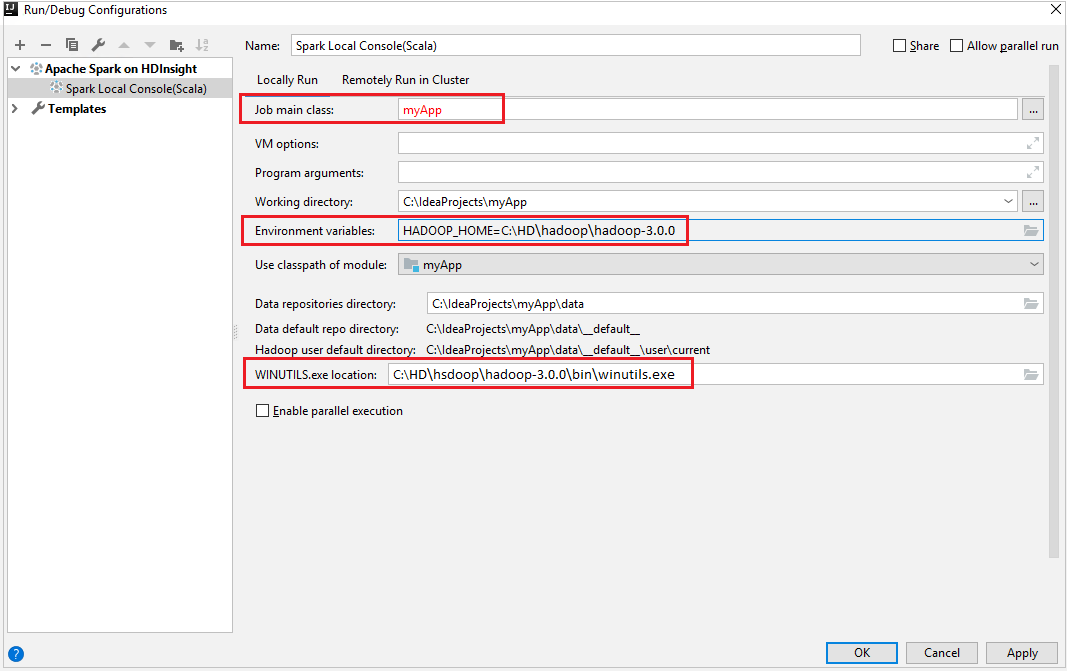
[Project](プロジェクト) から myApp>src>main>scala>myApp に移動します。
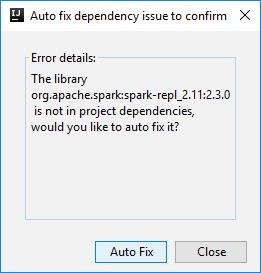
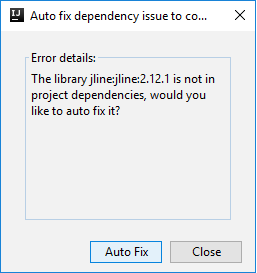
メニュー バーから、 [Tools](ツール)>[Spark Console](Spark コンソール)>[Run Spark Local Console(Scala)](Spark Local Console(Scala) の実行) に移動します。
次に、依存関係を自動修正するかどうかを確認する 2 つのダイアログ ボックスが表示されます。 そうする場合は、 [Auto Fix](自動修正) を選択します。
コンソールは次の図のようになります。 コンソール ウィンドウに「
sc.appName」と入力し、Ctrl + Enter キーを押します。 結果が表示されます。 赤いボタンをクリックすると、ローカル コンソールを終了できます。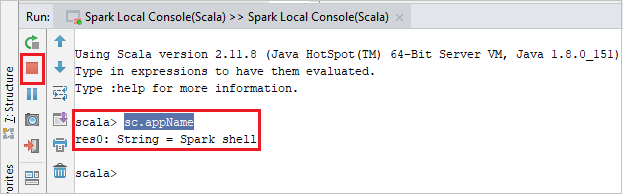
Spark Livy Interactive Session Console(Scala)
メニュー バーから、 [Run](実行)>[Edit Configurations](構成の編集) に移動します。
[Run/Debug Configurations](実行/デバッグ構成) ウィンドウから、左側のウィンドウで、 [Apache Spark on HDInsight](HDInsight 上の Apache Spark)>[Spark on HDInsight] myApp を選択します。
メイン ウィンドウで、 [
Remotely Run in Cluster] タブを選択します。次の値を指定し、 [OK] を選択します。
プロパティ 値 Spark クラスター (Linux のみ) アプリケーションを実行する HDInsight Spark クラスターを選択します。 メイン クラス名 既定値は、選択したファイルのメイン クラスです。 クラスを変更するには、省略記号 ( ... ) をクリックし、別のクラスを選択します。 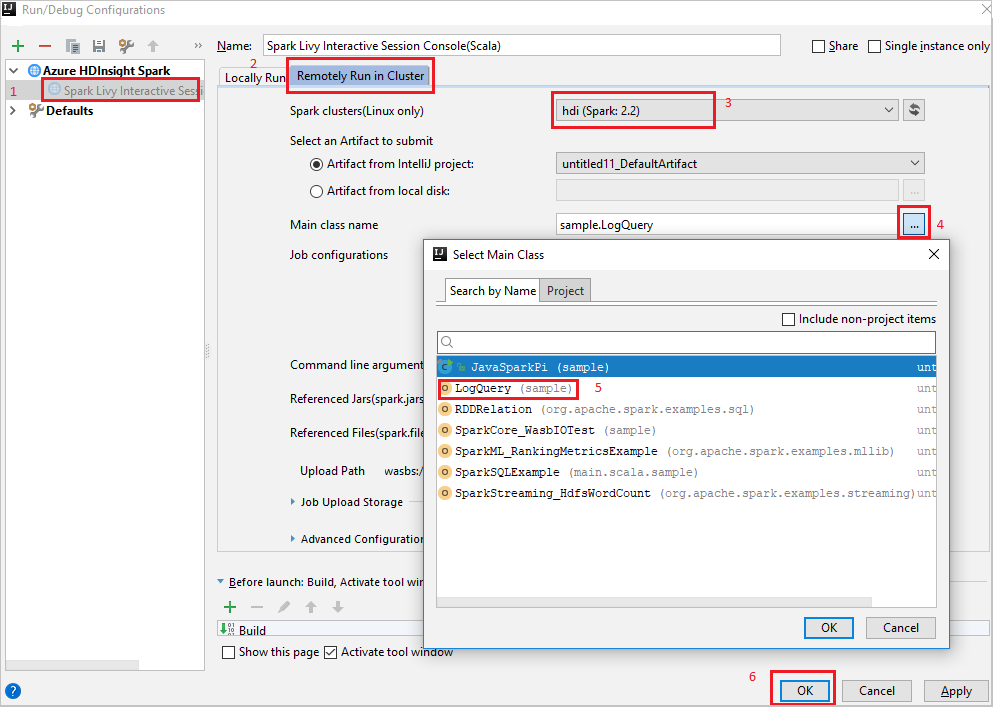
[Project](プロジェクト) から myApp>src>main>scala>myApp に移動します。
メニュー バーで、 [Tools](ツール)>[Spark Console](Spark コンソール)>[Run Spark Livy Interactive Session Console(Scala)](Spark Livy Interactive Session Console(Scala) の実行) に移動します。
コンソールは次の図のようになります。 コンソール ウィンドウに「
sc.appName」と入力し、Ctrl + Enter キーを押します。 結果が表示されます。 赤いボタンをクリックすると、ローカル コンソールを終了できます。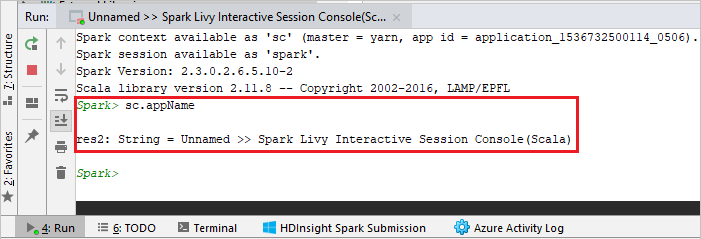
選択項目の Spark コンソールへの送信
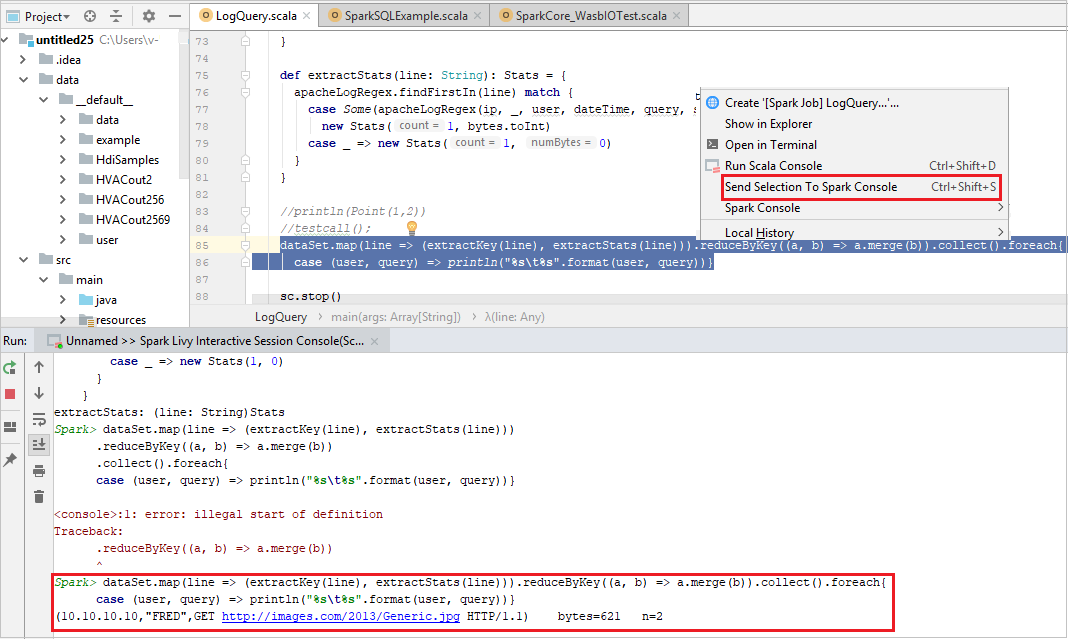
一部のコードをローカルのコンソールまたは Livy Interactive Session Console(Scala) に送信して、スクリプトの結果を事前に確認すると便利です。 Scala ファイル内の一部のコードを強調表示し、 [Send Selection To Spark Console](選択内容を Spark コンソールに送信) を右クリックします。 選択したコードがコンソールに送信されます。 結果は、コンソールのコードの後に表示されます。 コンソールでは、エラーが存在するかどうかがチェックされます。
HDInsight Identity Broker (HIB) との統合
HDInsight ESP cluster with ID Broker (HIB) に接続する
HDInsight ESP cluster with ID Broker (HIB) に接続するには、通常の手順に従って Azure サブスクリプションにサインインします。 サインインすると、Azure Explorer にクラスターの一覧が表示されます。 詳細な手順については、「HDInsight クラスターに接続する」を参照してください。
HDInsight ESP cluster with ID Broker (HIB) 上での Spark Scala アプリケーションを実行する
HDInsight ESP cluster with ID Broker (HIB) にジョブを送信するには、通常の手順に従います。 詳細な手順については、「HDInsight Spark クラスターでの Spark Scala アプリケーションの実行」を参照してください。
必要なファイルは、ご利用のサインイン アカウントが名前になっているフォルダーにアップロードしてあります。アップロード パスは、構成ファイル内で確認できます。

HDInsight ESP cluster with ID Broker (HIB) 上の Spark コンソール
HDInsight ESP cluster with ID Broker (HIB) 上で、Spark Local Console(Scala) を実行したり、Spark Livy Interactive Session Console(Scala) を実行したりすることができます。 詳細な手順については、「Spark コンソール」を参照してください。
Note
HDInsight ESP cluster with Id Broker (HIB) では、現在、クラスターのリンクとリモートでの Apache Spark アプリケーションのデバッグはサポートされていません。
読み取り専用ロール
ユーザーが読み取り専用ロールのアクセス許可を使用してジョブをクラスターに送信する場合、Ambari の資格情報が必要です。
コンテキスト メニューからクラスターをリンクする
読み取り専用ロールのアカウントでサインインします。
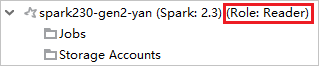
Azure Explorer で [HDInsight] を展開し、自分のサブスクリプションにある HDInsight クラスターを表示します。 "Role:Reader" とマークされているクラスターには、読み取り専用ロールのアクセス許可しかありません。
読み取り専用ロールのアクセス許可があるクラスターを右クリックします。 コンテキスト メニューで [Link this cluster](このクラスターをリンク) を選択して、クラスターをリンクします。 Ambari のユーザー名とパスワードを入力します。
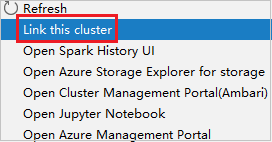
クラスターが正常にリンクされると、HDInsight が更新されます。 クラスターのステージはリンク状態になります。
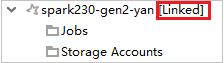
ジョブ ノードを展開してクラスターをリンクする
Jobs ノードをクリックします。 [Cluster Job Access Denied](拒否されたクラスター ジョブ アクセス) ウィンドウが表示されます。
[Link this cluster](このクラスターをリンク) をクリックして、クラスターをリンクします。

[Run/Debug Configurations](実行/デバッグ構成) ウィンドウからクラスターをリンクする
HDInsight 構成を作成します。 次に、 [Remotely Run in Cluster](クラスターでリモート実行) を選択します。
[Spark clusters(Linux only)](Spark クラスター (Linux のみ)) で、読み取り専用ロールのアクセス許可があるクラスターを選択します。 警告メッセージが表示されます。 [Link this cluster](このクラスターをリンク) をクリックして、クラスターをリンクできます。
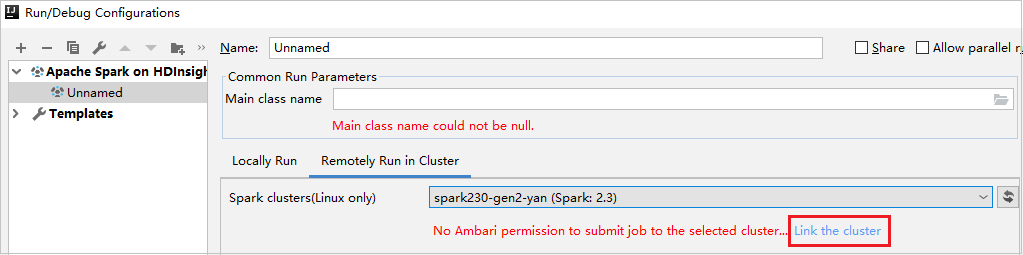
ストレージ アカウントを表示する
読み取り専用ロールのアクセス許可があるクラスターで、Storage Accounts ノードをクリックします。 [Storage Access Denied](拒否されたストレージ アクセス) ウィンドウが表示されます。 [Azure Storage Explorer を開く] をクリックして Storage Explorer を開くことができます。
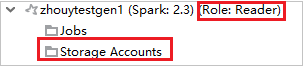

リンクされたクラスターで、Storage Accounts ノードをクリックします。 [Storage Access Denied](拒否されたストレージ アクセス) ウィンドウが表示されます。 [Azure Storage Explorer を開く] をクリックして Storage Explorer を開くことができます。

Azure Toolkit for IntelliJ を使用できるように既存の IntelliJ IDEA アプリケーションを変換する
IntelliJ IDEA で作成した既存の Spark Scala アプリケーションを、Azure Toolkit for IntelliJ に対応するように変換することができます。 その後、プラグインを使用して、そのアプリケーションを HDInsight Spark クラスターに送信できます。
IntelliJ IDEA で作成した既存の Spark Scala アプリケーションの、関連付けられている
.imlファイルを開きます。ルート レベルに、次のテキストのような module 要素があります。
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">module 要素が次のテキストのようになるように、この要素を編集して
UniqueKey="HDInsightTool"を追加します。<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">変更を保存します。 これで、アプリケーションは Azure Toolkit for IntelliJ との互換性を持つようになります。 これをテストするには、[プロジェクト] でプロジェクト名を右クリックします。 これで、ポップアップ メニューで、 [Submit Spark Application to HDInsight](HDInsight への Spark アプリケーションの送信) を選択できるようになります。
リソースをクリーンアップする
このアプリケーションを引き続き使用しない場合は、次の手順で作成したクラスターを削除します。
Azure portal にサインインします。
上部の検索ボックスに「HDInsight」と入力します。
[サービス] の下の [HDInsight クラスター] を選択します。
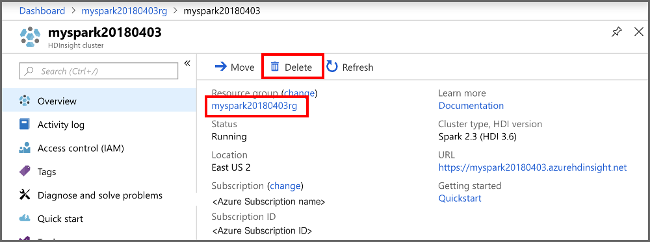
表示される HDInsight クラスターの一覧で、この記事用に作成したクラスターの横にある [...] を選択します。
[削除] を選択します。 はいを選択します。
エラーと解決策
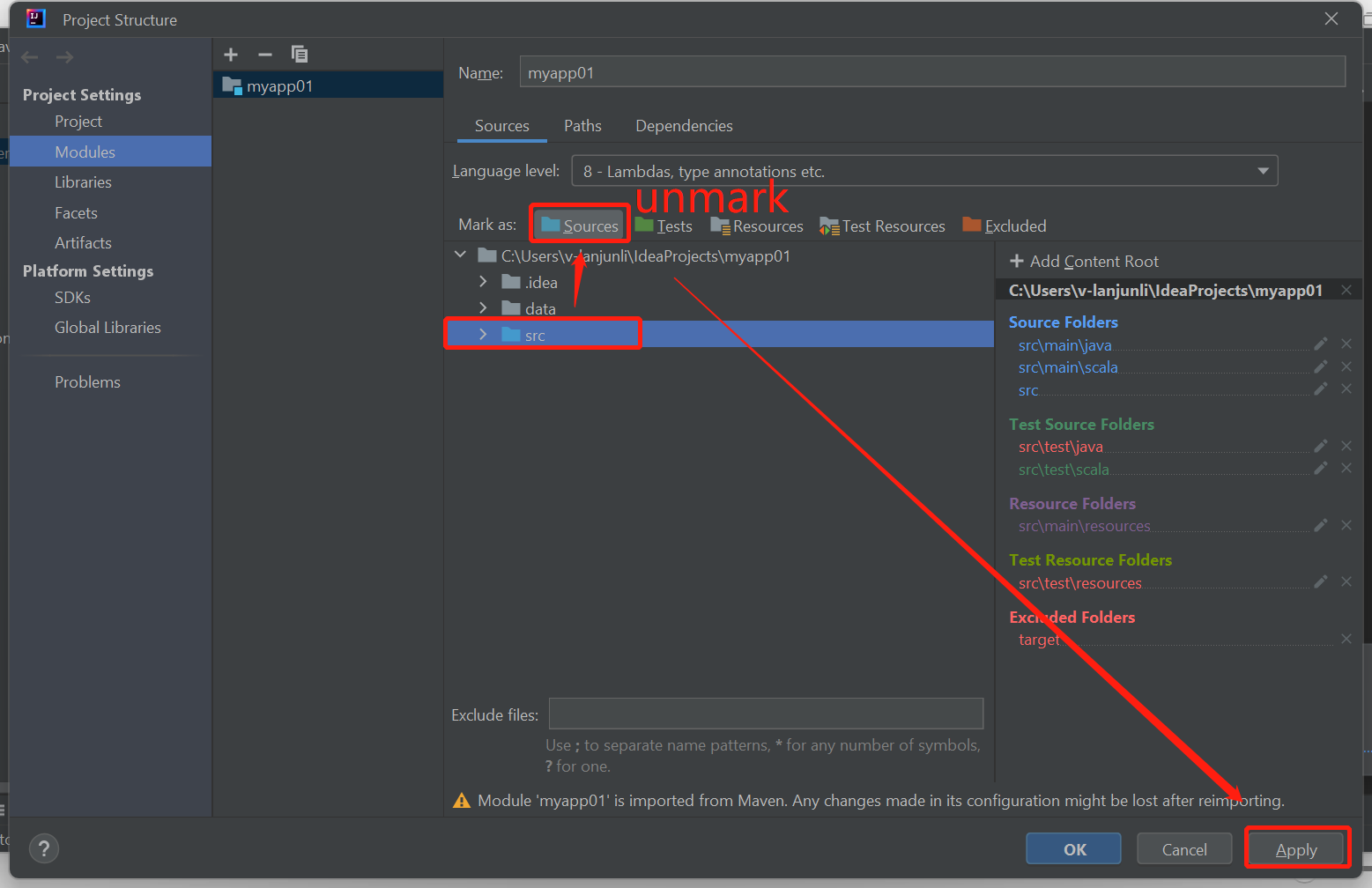
次のようにビルドに失敗したエラーが発生した場合は、src フォルダーのマークをソースとしてマーク解除します。

この問題を解決する ソース として次の src フォルダーのマークを解除します。
[ファイル] に移動し、[プロジェクト構造] を選択します。
[プロジェクトの設定] の下にある [モジュール] を選択します。
src ファイルを選択し、ソースとしてマークを解除します。
[適用] ボタン、[OK] ボタンの順にクリックしてダイアログを閉じます。
次のステップ
この記事では、Azure Toolkit for IntelliJ プラグインを使用して、Scala で記述された Apache Spark アプリケーションを開発する方法について学習しました。 その後、IntelliJ 統合開発環境 (IDE) から直接 HDInsight Spark クラスターに送信しました。 次の記事に進んで、Apache Spark に登録したデータを Power BI などの BI 分析ツールに取り込む方法を確認してください。