スクリプト アクションを使用して Azure HDInsight で Python 環境を安全に管理する
HDInsight では、Spark クラスターに 2 つの Python のインストール (Anaconda Python 2.7 と Python 3.5) が組み込まれています。 外部 Python パッケージのインストールなど、Python 環境のカスタマイズは、お客様が実行する必要があります。 ここでは、HDInsight 上の Apache Spark クラスターで Python 環境を安全に管理するためのベスト プラクティスについて説明します。
前提条件
HDInsight での Apache Spark クラスター。 手順については、「 Create Apache Spark clusters in Azure HDInsight (Azure HDInsight での Apache Spark クラスターの作成)」を参照してください。 HDInsight に Spark クラスターがない場合は、クラスターの作成時にスクリプト アクションを実行できます。 カスタム スクリプト アクションの使用方法に関するドキュメントを参照してください。
HDInsight クラスターで使用するオープン ソース ソフトウェアのサポート
Microsoft Azure HDInsight サービスは、Apache Hadoop を中心に形成されたオープン ソース テクノロジの環境を利用します。 Microsoft Azure は、オープン ソース テクノロジの一般的なレベルのサポートを提供します。 詳細については、Azure サポート FAQ Web サイトを参照してください。 HDInsight サービスでは、組み込みのコンポーネントに対してさらに高いレベルのサポートを提供しています。
HDInsight サービスで利用できるオープン ソース コンポーネントには、2 つの種類があります。
| コンポーネント | 説明 |
|---|---|
| 組み込み | これらのコンポーネントは、HDInsight クラスターにプレインストールされており、クラスターの主要な機能を提供します。 たとえば、Apache Hadoop YARN リソース マネージャー、Apache Hive クエリ言語 (HiveQL)、Mahout ライブラリがこのカテゴリに属します。 クラスター コンポーネントの完全な一覧は、「HDInsight で提供されるApache Hadoop クラスター バージョンの新機能」から入手できます。 |
| Custom | クラスターのユーザーは、コミュニティで入手できるコンポーネントや自作のコンポーネントを、インストールするか、ワークロード内で使用することができます。 |
重要
HDInsight クラスターに用意されているコンポーネントは全面的にサポートされており、 これらのコンポーネントに関連する問題の分離と解決については、Microsoft サポートが支援します。
カスタム コンポーネントについては、問題のトラブルシューティングを進めるための支援として、商業的に妥当な範囲のサポートを受けることができます。 Microsoft サポートによって問題が解決する場合もあれば、オープン ソース テクノロジに関する深い専門知識を入手できる場所への参加をお願いする場合もあります。 たとえば、HDInsight についての Microsoft Q&A の質問ページ (https://stackoverflow.com) などの数多くのコミュニティ サイトを利用できます。 また、Apache プロジェクトには https://apache.org にプロジェクト サイトもあります。
Python の既定のインストールを理解する
HDInsight Spark クラスターには Anaconda がインストールされています。 クラスターには 2 つの Python インストールが存在します (Anaconda Python 2.7 と Python 3.5)。 次の表に、Spark、Livy、および Jupyter 向けの既定の Python 設定を示します。
| 設定 | Python 2.7 | Python 3.5 |
|---|---|---|
| Path | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Spark のバージョン | 既定で 2.7 に設定 | 構成を 3.5 に変更可能 |
| Livy バージョン | 既定で 2.7 に設定 | 構成を 3.5 に変更可能 |
| Jupyter | PySpark カーネル | PySpark3 カーネル |
Spark 3.1.2 バージョンでは、Apache PySpark カーネルが削除され、/usr/bin/miniforge/envs/py38/bin PySpark3 カーネルによって使用される新しい Python 3.8 環境がインストールされます。 PYSPARK_PYTHONおよび PYSPARK3_PYTHON 環境変数は、次のように更新されます。
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
外部 Python パッケージを安全にインストールする
HDInsight クラスターは、組み込みの Python 環境 (Python 2.7 と Python 3.5 の両方) に依存しています。 これらの既定の組み込み環境にカスタム パッケージを直接インストールすると、予期しないライブラリ バージョンの変更が生じ、 クラスターがさらに壊れる可能性があります。 Spark アプリケーションのカスタム外部 Python パッケージを安全にインストールするには、手順に従います。
conda を使用して Python 仮想環境を作成します。 仮想環境によって、他を壊すことなく、プロジェクト用の分離された空間が用意されます。 Python 仮想環境を作成するときに使用する Python のバージョンを指定できます。 Python 2.7 および 3.5 を使用する場合でも、仮想環境を作成する必要があります。 この要件は、クラスターの既定の環境を壊さないようにするためです。 次のスクリプトを使用して、Python 仮想環境を作成するクラスターのすべてのノードで、スクリプト アクションを実行します。
--prefixには、conda 仮想環境を作成するパスを指定します。 ここで指定したパスに基づいて、さらに変更する必要がある構成がいくつかあります。 この例では、クラスターに py35 という名前の既存の仮想環境が既に存在するため、py35new が使用されています。python=には、仮想環境用の Python のバージョンを指定します。 この例では、バージョン3.5 が使用されています。これは、クラスターに組み込まれているものと同じバージョンです。 Python の他のバージョンを使用して仮想環境を作成することもできます。anacondaは、package_spec を anaconda として指定して、仮想環境に Anaconda パッケージをインストールします。
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yes必要に応じて、作成した仮想環境に外部の Python パッケージをインストールします。 次のスクリプトを使用して、クラスターのすべてのノードでスクリプト アクションを実行して、外部の Python パッケージをインストールします。 仮想環境フォルダーにファイルを書き込むために、ここでは sudo 特権が必要です。
パッケージ インデックスで、利用できるすべてのパッケージを検索します。 公開されているパッケージの一覧を他のソースから入手してもかまいません。 たとえば、conda-forge で使用できるパッケージをインストールできます。
最新バージョンのライブラリをインストールする場合は、次のコマンドを使用します。
Conda チャネルを使用します
seabornは、インストールするパッケージの名前です。-n py35newには、先ほど作成した仮想環境の名前を指定します。 仮想環境の作成に応じて、名前を適宜変更してください。
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yesまたは、PyPi リポジトリを使用し、
seabornとpy35newを適切に変更します。sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
特定のバージョンのライブラリをインストールする場合は、次のコマンドを使用します。
Conda チャネルを使用します
numpy=1.16.1は、インストールするパッケージの名前とバージョンです。-n py35newには、先ほど作成した仮想環境の名前を指定します。 仮想環境の作成に応じて、名前を適宜変更してください。
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yesまたは、PyPi リポジトリを使用し、
numpy==1.16.1とpy35newを適切に変更します。sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
仮想環境名がわからない場合は、クラスターのヘッド ノードに SSH 接続し、
/usr/bin/anaconda/bin/conda info -eを実行して、すべての仮想環境を表示できます。Spark と Livy の構成を変更して、作成した仮想環境をポイントします。
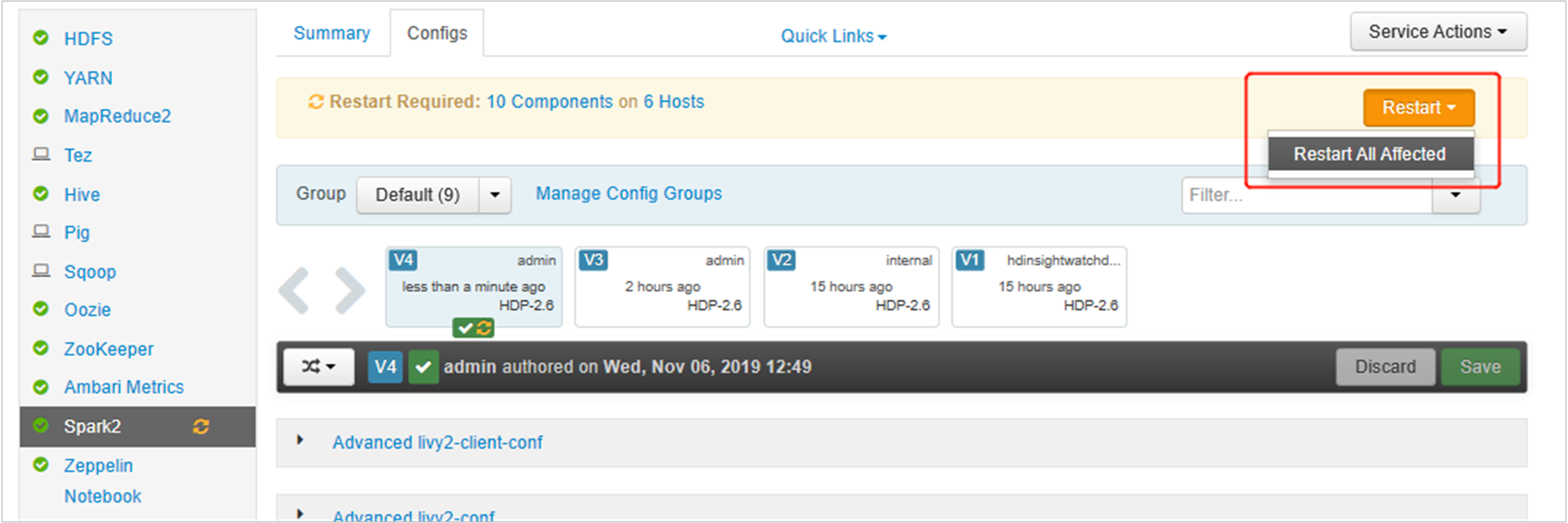
Ambari UI を開き、[Spark 2] ページの [構成] タブに移動します。
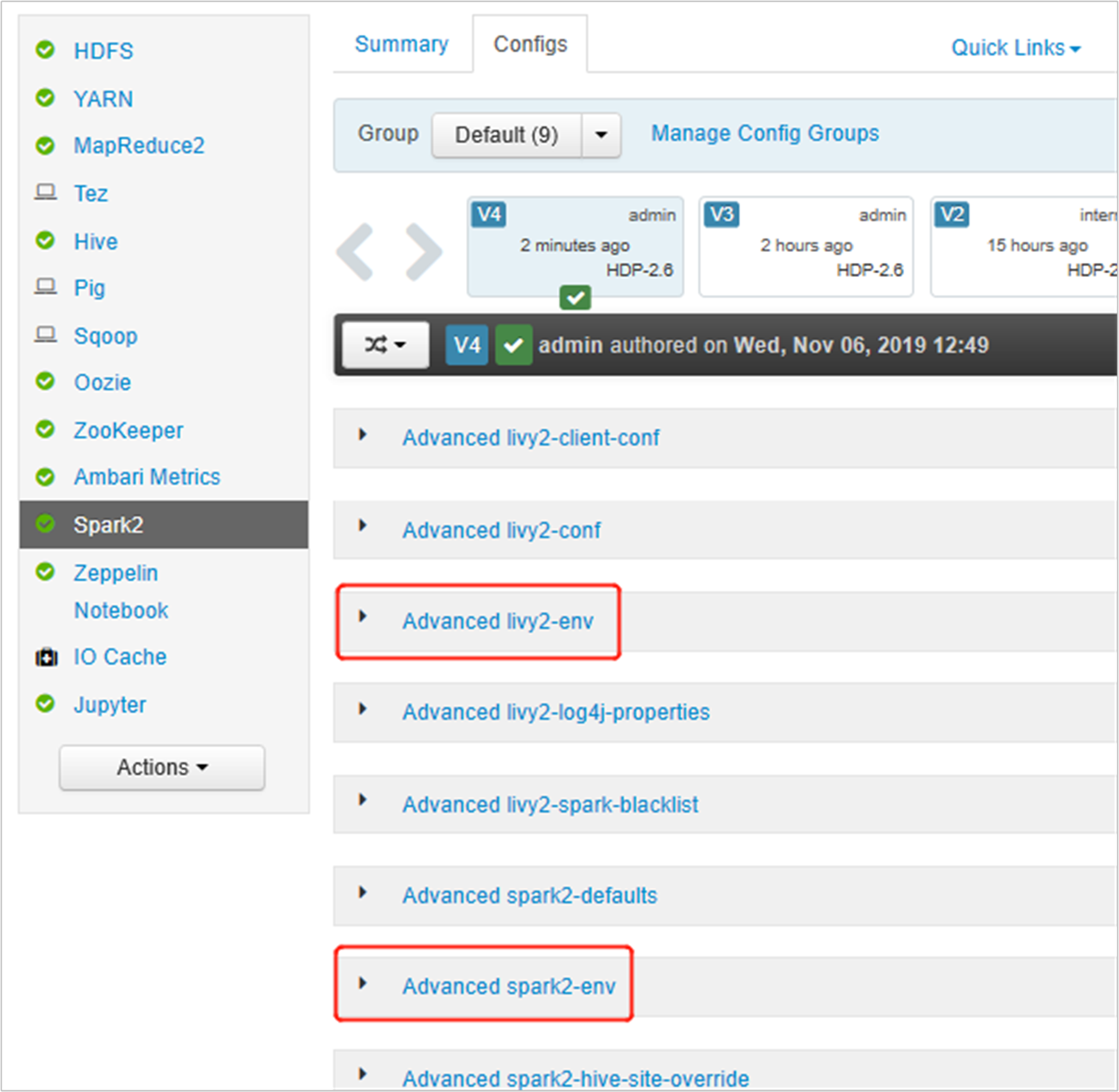
[Advanced livy2-env] を展開し、下のステートメントを末尾に追加します。 仮想環境を別のプレフィックスを使用してインストールした場合は、パスを適宜変更します。
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python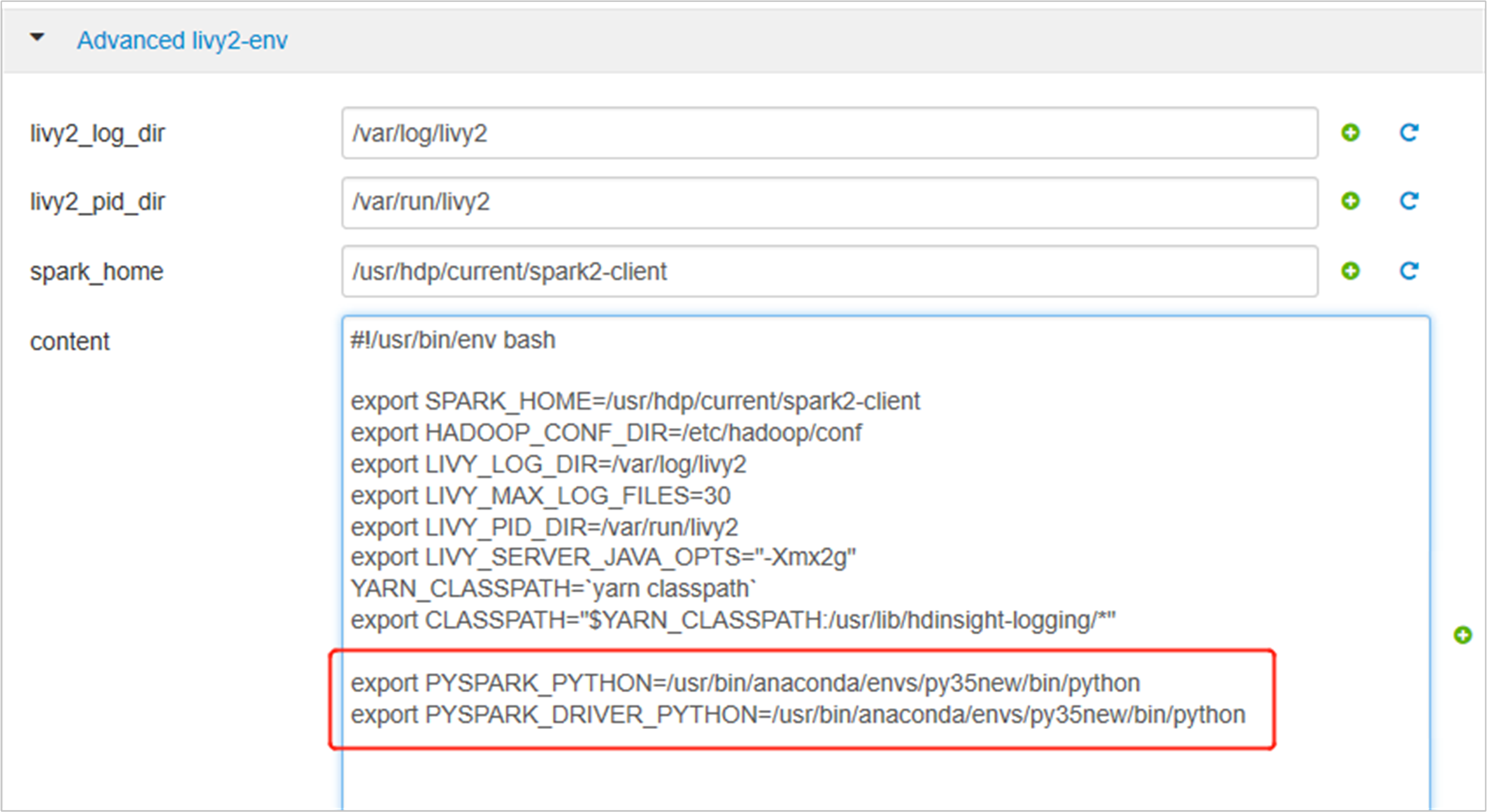
[Advanced spark2-env] を展開し、末尾にある既存の export PYSPARK_PYTHON ステートメントを置き換えます。 仮想環境を別のプレフィックスを使用してインストールした場合は、パスを適宜変更します。
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}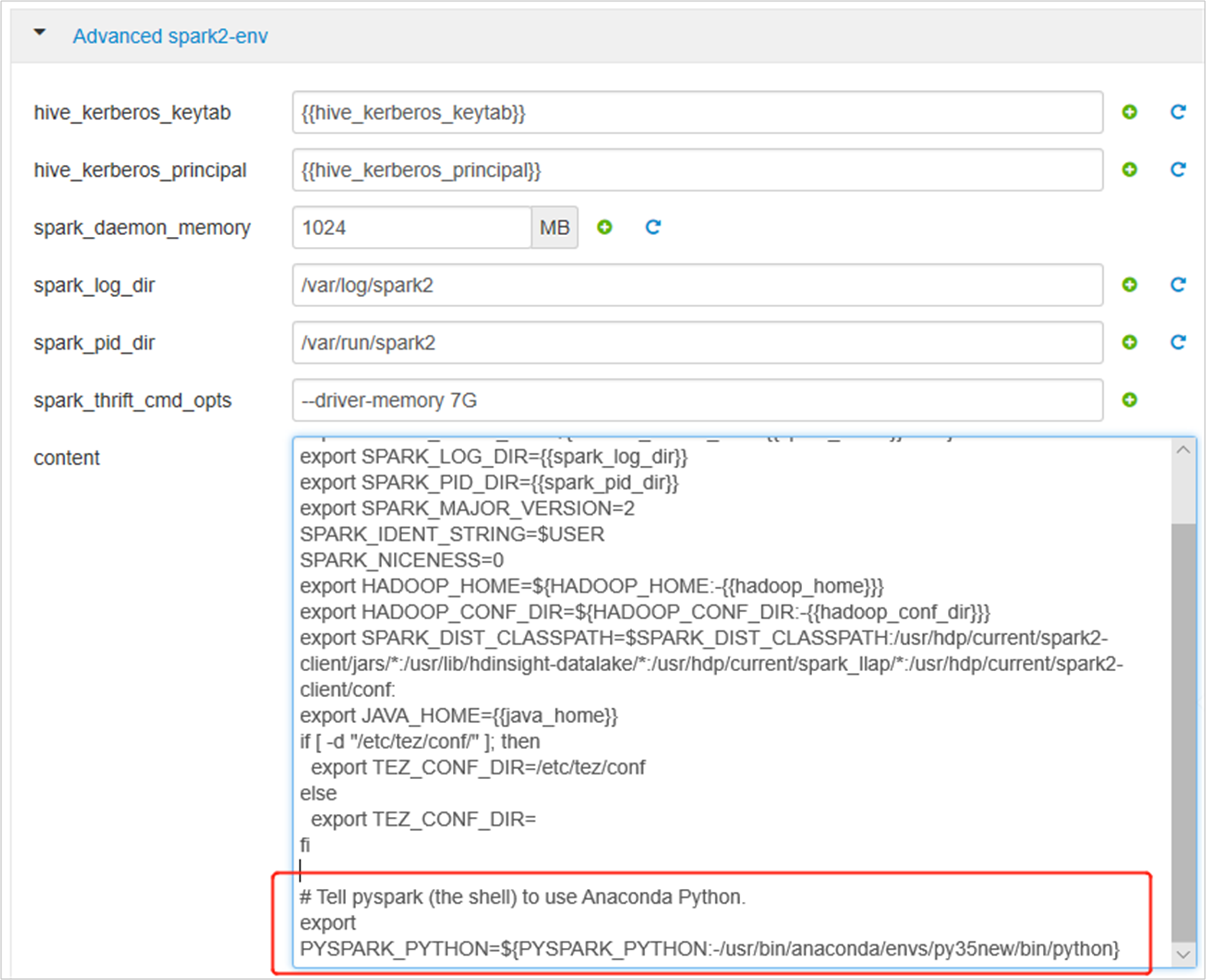
変更を保存し、影響を受けるサービスを再起動します。 これらの変更では、Spark 2 サービスを再起動する必要があります。 Ambari UI によって、再起動が必要であることを示すリマインダーが表示されます。[再起動] をクリックして、影響を受けるすべてのサービスを再起動します。
Spark セッションに 2 つのプロパティを設定して、ジョブが更新された spark 構成 (
spark.yarn.appMasterEnv.PYSPARK_PYTHONとspark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON) を指すようにします。ターミナルまたはノートブックを使用して、
spark.conf.set関数を使用します。spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")livyを使用している場合は、次のプロパティを要求本文に追加します。"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
新しく作成された仮想環境を Jupyter で使用する場合は、 Jupyter の構成を変更し、Jupyter を再起動します。 次のステートメントを使用して、すべてのヘッダー ノードでスクリプト アクションを実行して、新たに作成された仮想環境に対して Jupyter をポイントします。 パスを仮想環境用に指定したプレフィックスに必ず変更してください。 このスクリプト アクションを実行した後、Ambari UI から Jupyter サービスを再起動して、この変更を使用できるようにします。
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.jsonコードを実行して、Jupyter Notebook の Python 環境を再確認できます。