Enterprise セキュリティ パッケージを使用して HDInsight に Spark SQL 用の Apache Ranger ポリシーを構成する
この記事では、HDInsight の Enterprise セキュリティ パッケージを使用して Spark SQL 用の Apache Ranger ポリシーを構成する方法について説明します。
この記事では、次のことについて説明します。
- Apache Ranger ポリシーを作成する。
- 適用される Ranger ポリシーを確認する。
- Spark SQL 用 Apache Ranger の設定ガイドラインを適用する。
前提条件
- Enterprise セキュリティ パッケージを使用した HDInsight バージョン 5.1 での Apache Spark クラスター
Apache Ranger 管理 UI への接続
ブラウザーから、URL
https://ClusterName.azurehdinsight.net/Ranger/を使用して Ranger 管理ユーザー インターフェイスに接続します。ClusterNameを、使用している Spark クラスターの名前に変更します。Microsoft Entra 管理者の資格情報を使用してサインインします。 Microsoft Entra 管理者の資格情報は、HDInsight クラスターの資格情報や Linux HDInsight ノードの Secure Shell (SSH) 資格情報と同じではありません。

ドメイン ユーザーの作成
sparkuser ドメイン ユーザーを作成する方法については、「ESP を使用する HDInsight クラスターを作成する」を参照してください。 運用シナリオでは、ドメイン ユーザーは Microsoft Entra テナントに含まれます。
Ranger ポリシーの作成
このセクションでは、2 つの Ranger ポリシーを作成します。
- Spark SQL から
hivesampletableにアクセスするためのアクセス ポリシー hivesampletableの列を難読化するためのマスク ポリシー
Ranger アクセス ポリシーを作成する
Ranger 管理 UI を開きます。
HADOOP SQL の下にある hive_and_spark を選択します。
[アクセス] タブで、[新しいポリシーの追加] を選択します。
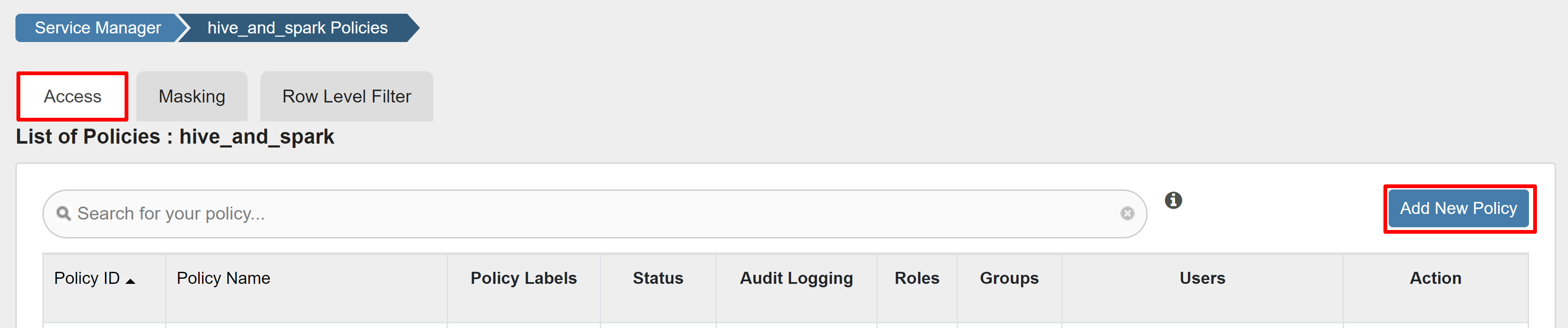
次の値を入力します。
プロパティ 値 ポリシー名 read-hivesampletable-all database default table hivesampletable column * ユーザーの選択 sparkuserアクセス許可 SELECT… 
[ユーザーの選択] にドメイン ユーザーが自動的に設定されない場合は、Ranger が Microsoft Entra ID と同期されるまでしばらく待ってください。
[Add](追加) をクリックしてポリシーを保存します。
Zeppelin ノートブックを開き、次のコマンドを実行してポリシーを確認します。
%sql select * from hivesampletable limit 10;ポリシーが適用される前の結果を次に示します。
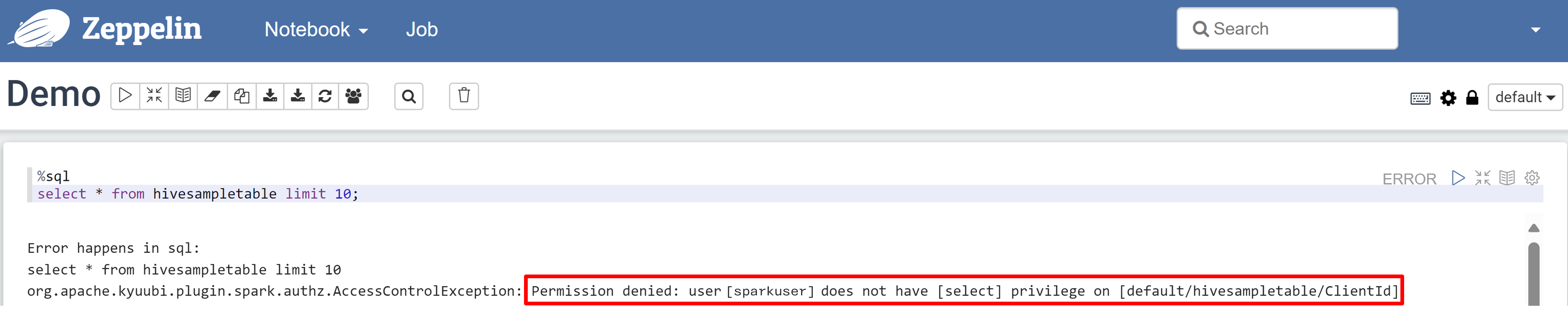
ポリシーが適用された後の結果を次に示します。





Ranger マスク ポリシーを作成する
次の例は、列をマスキングするポリシーの作成方法を示しています。
[マスク] タブで、[新しいポリシーの追加] を選択します。

次の値を入力します。
プロパティ 値 ポリシー名 mask-hivesampletable Hive Database default Hive テーブル hivesampletable Hive Column devicemake ユーザーの選択 sparkuserアクセスの種類 SELECT… マスク オプションの選択 ハッシュ 
[保存] を選択してポリシーを保存します。
Zeppelin ノートブックを開き、次のコマンドを実行してポリシーを確認します。
%sql select clientId, deviceMake from hivesampletable;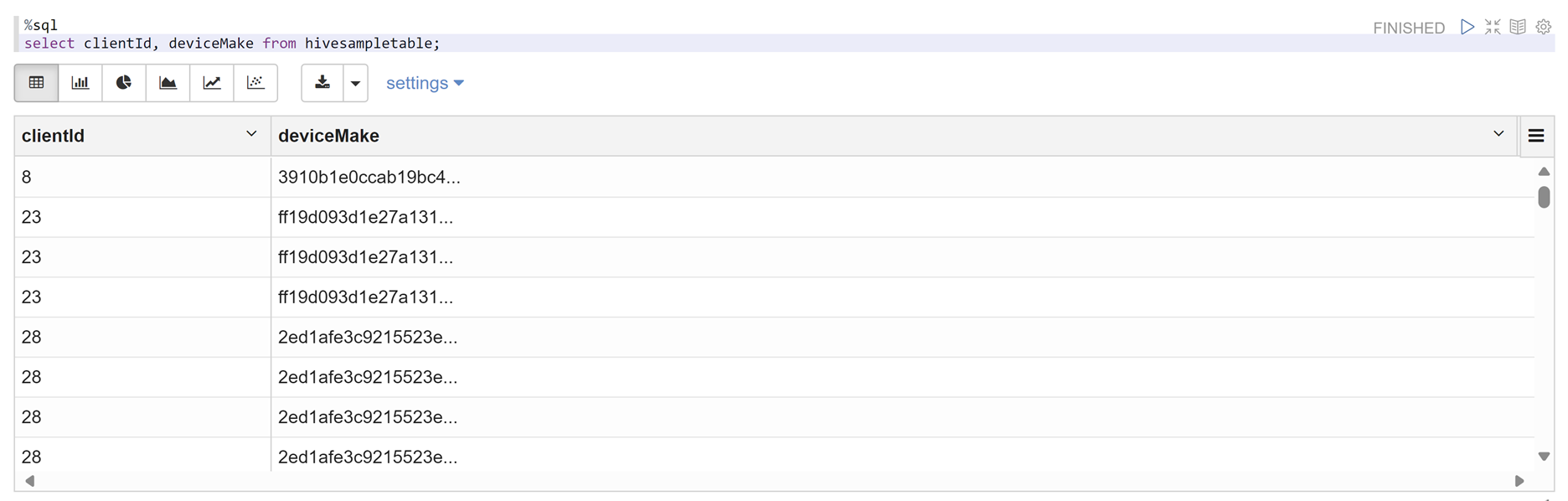



Note
既定では、Hive と Spark SQL のポリシーは Ranger で共通になります。
Spark SQL 用 Apache Ranger の設定ガイドラインを適用する
次のシナリオでは、新しい Ranger データベースを使用することによる、および既存の Ranger データベースを使用することによる HDInsight 5.1 Spark クラスター作成のガイドラインについて説明します。
シナリオ 1: HDInsight 5.1 Spark クラスターの作成中に新しい Ranger データベースを使用する
新しい Ranger データベースを使用してクラスターを作成すると、Hive と Spark の Ranger ポリシーを含む関連する Ranger リポジトリが、Ranger データベースの Hadoop SQL サービスに hive_and_spark という名前で作成されます。

ポリシーを編集すると、Hive と Spark の両方に適用されます。
次の点を考慮します。
Hive (DB1 など) と Spark (DB1 など) の両方のカタログに使用される同じ名前を持つ 2 つのメタストア データベースがある場合:
- Spark で Spark カタログ (
metastore.catalog.default=spark) を使用する場合、ポリシーは Spark カタログの DB1 データベースに適用されます。 - Spark で Hive カタログ (
metastore.catalog.default=hive) を使用する場合、ポリシーは Hive カタログの DB1 データベースに適用されます。
Ranger の視点では、Hive カタログと Spark カタログの DB1 を区別する方法はありません。
このような場合は、次のいずれかをお勧めします。
- Hive と Spark の両方に Hive カタログを使用します。
- Hive と Spark の両方のカタログで異なるデータベース名、テーブル名、列名を維持し、カタログ全体のデータベースにポリシーが適用されないようにします。
- Spark で Spark カタログ (
Hive と Spark の両方に Hive カタログを使用する場合は、次の例を検討してください。
たとえば、現在の xyz ユーザーを使用した Hive を介して table1 という名前のテーブルを作成します。 これにより、所有者が xyz ユーザーである table1.db という名前の Hadoop 分散ファイル システム (HDFS) ファイルが作成されます。
ここで、ユーザー abc を使用して Spark SQL セッションを開始するとします。 ユーザー abc のこのセッションで、table1 に何かを書き込もうとすると、テーブルの所有者が xyz であるため失敗します。
このような場合は、テーブルを更新するために Hive と Spark の SQL で同じユーザーを使用することをお勧めします。 そのユーザーには、更新操作を実行するための十分な特権が必要です。
シナリオ 2: HDInsight 5.1 Spark クラスターの作成中に既存の Ranger データベース (既存のポリシーを含む) を使用する
既存の Ranger データベースを使用して HDInsight 5.1 クラスターを作成すると、新しいクラスターの名前を hive_and_spark という形式にして、このデータベース上に新しい Ranger リポジトリが再び作成されます。

たとえば、Hadoop SQL サービス内の既存の Ranger データベース上に oldclustername_hive という名前で Ranger リポジトリに定義されたポリシーが既にあるとします。 新しい HDInsight 5.1 Spark クラスターで同じポリシーを共有する必要があります。 この目標を達成するために、次の手順を使用します。
Note
Ambari 管理者特権を持つユーザーは、構成の更新を実行できます。
新しい HDInsight 5.1 クラスターから Ambari UI を開きます。
Spark3 サービスに移動し、[Configs] (構成) に移動します。
[Advanced ranger-spark-security] (ranger-spark-security 詳細設定) 構成を開きます。
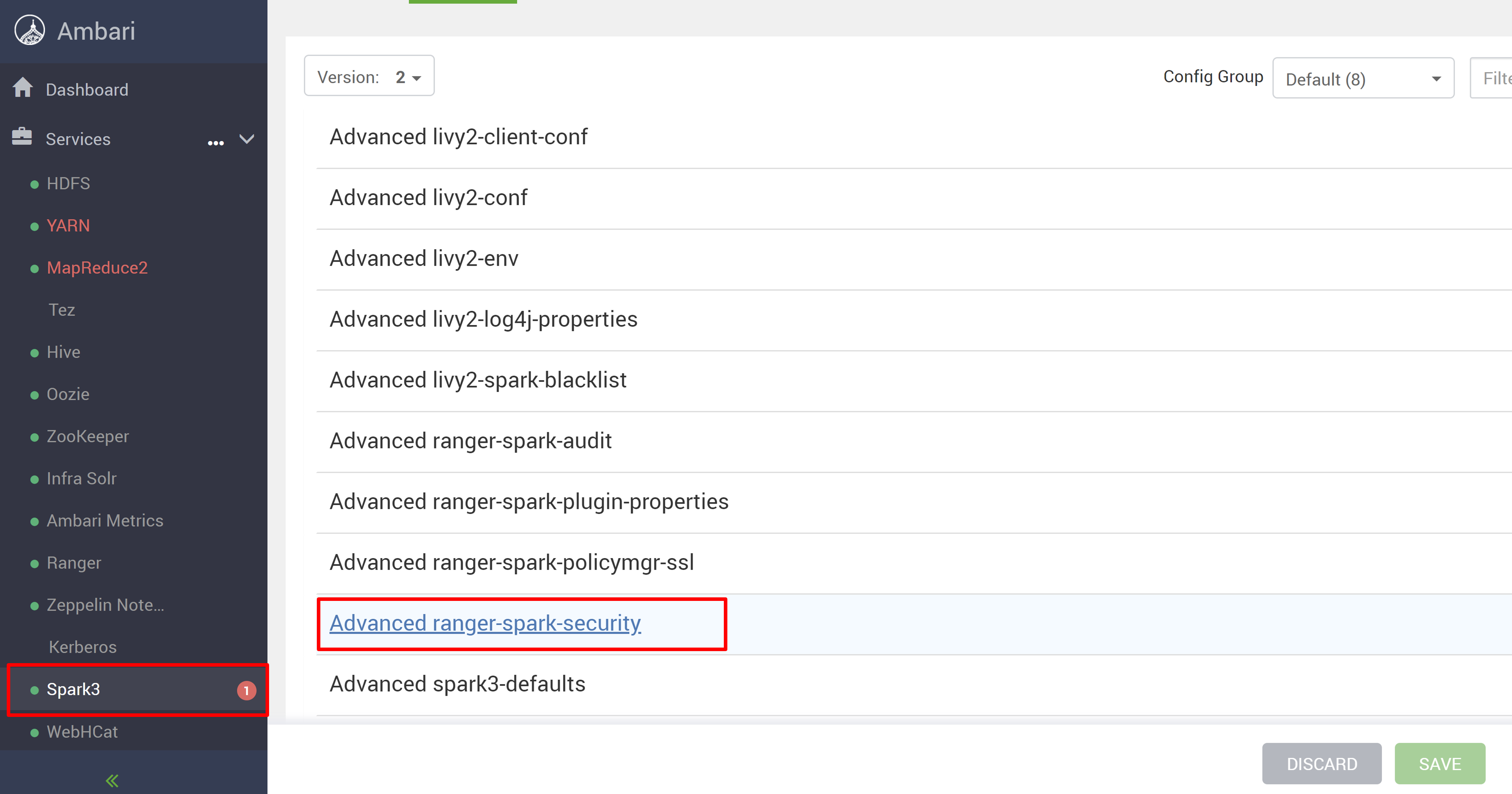
または SSH を使用して、/etc/spark3/conf 内でこの構成を開くこともできます。
2 つの構成 (ranger.plugin.spark.service.name と ranger.plugin.spark.policy.cache.dir) を編集して、古いポリシーのリポジトリである oldclustername_hive をポイントするようにし、構成を保存します。
Ambari:

XML ファイル:

Ambari から Ranger と Spark のサービスを再起動します。
Ranger 管理者 UI を開き、[HADOOP SQL] サービスの下にある編集ボタンをクリックします。

oldclustername_hive サービスの場合は、[policy.download.auth.users] と [tag.download.auth.users] 一覧の中に rangersparklookup ユーザーを追加して、[保存] をクリックします。






ポリシーは、Spark カタログ内のデータベースに適用されます。 Hive カタログ内のデータベースにアクセスする場合は、次のようにします。
Ambari で、[Spark3]> [Configs] (構成) に移動します。
metastore.catalog.default を spark から hive に変更します。


既知の問題
- Ranger admin がダウンしている場合、Apache Ranger と Spark SQL の統合は機能しません。
- Ranger 監査ログ内で、[リソース] 列にカーソルを合わせても、実行したクエリ全体を表示することはできません。