クイックスタート: Azure Machine Learning での Apache Spark を使用した対話型データ ラングリング
Azure Machine Learning と Azure Synapse Analytics を統合すると、Azure Machine Learning ノートブックの対話型データ ラングリングを処理するために、Apache Spark フレームワークに簡単にアクセスできます。 このアクセスにより、Azure Machine Learning ノートブックの対話型データ ラングリングが可能になります。
このクイックスタート ガイドでは、Azure Machine Learning サーバーレス Spark コンピューティング、Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウント、ユーザー ID パススルーを使って、対話型データ ラングリングを実行する方法について説明します。
前提条件
- Azure サブスクリプション。Azure サブスクリプションを持っていない場合は、始める前に無料アカウントを作成してください。
- Azure Machine Learning ワークスペース。 ワークスペース リソースの作成に関する記事をご覧ください。
- Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウント。 Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントの作成に関するページを参照してください。
Azure ストレージ アカウントの資格情報をシークレットとして Azure Key Vault に格納する
Azure portal ユーザー インターフェイスを使って、Azure ストレージ アカウントの資格情報をシークレットとして Azure Key Vault に格納するには、次のようにします。
Azure portal でお使いの Azure キー コンテナーに移動します
左側のパネルから [シークレット] を選びます
[+生成/インポート] を選択します
![[Azure Key Vault シークレットの生成またはインポート] タブを示すスクリーンショット。](media/apache-spark-environment-configuration/azure-key-vault-secrets-generate-import.png?view=azureml-api-2)
[シークレットの作成] 画面で、作成するシークレットの [名前] を入力します
次の図に示すように、Azure portal で [Azure Blob Storage アカウント] に移動します。
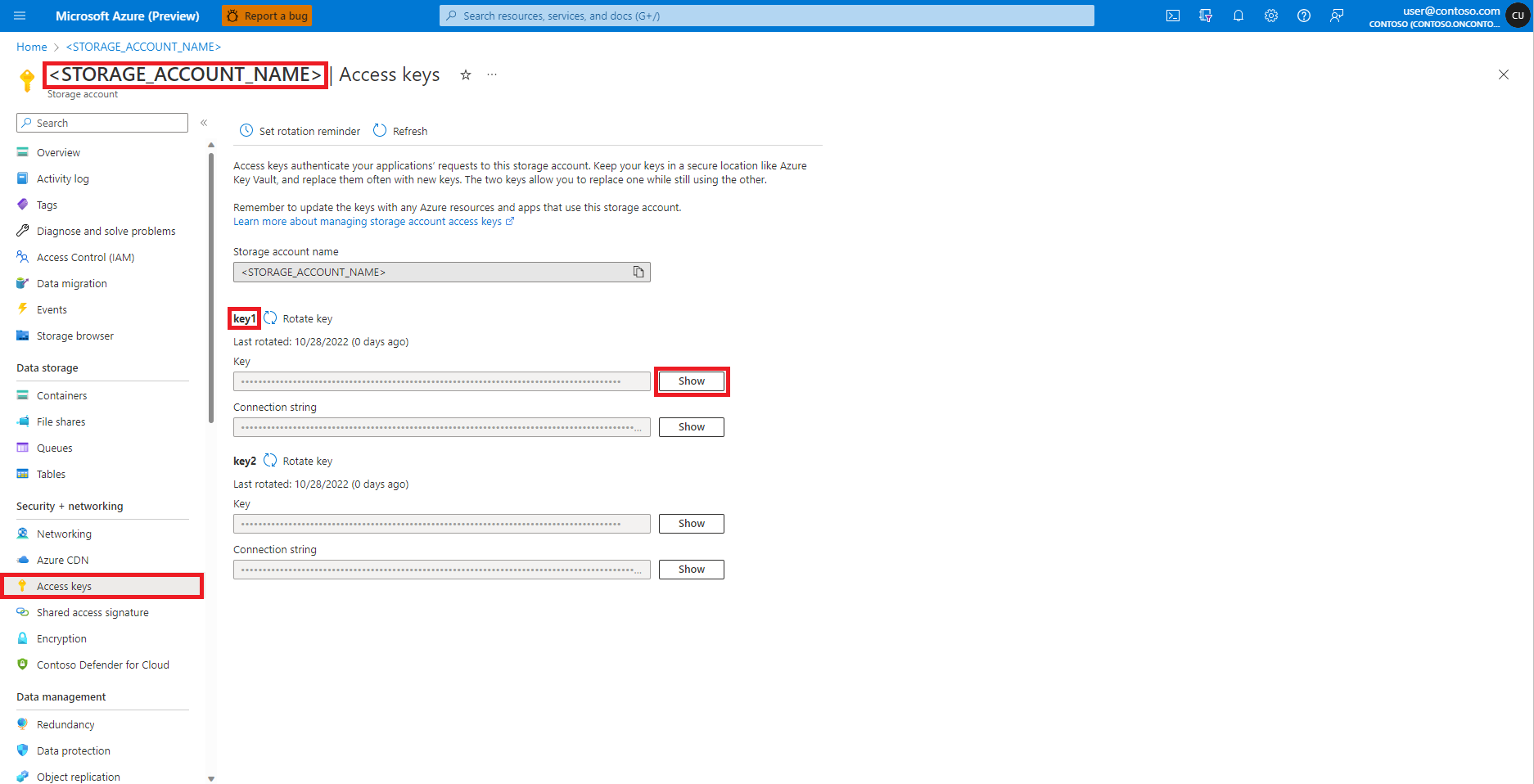
左側のパネルの [Azure Blob Storage アカウント] ページから [アクセス キー] を選びます
[キー 1] の横にある [表示] を選び、[クリップボードにコピー] を選んで、ストレージ アカウントのアクセス キーを取得します
Note
コピーする適切なオプションを選びます
- Azure BLOB Storage コンテナーの Shared Access Signature (SAS) トークン
- Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウント サービス プリンシパルの資格情報
- テナント ID
- クライアント ID と
- シークレット
それらの Azure Key Vault シークレットを作成する際に、それぞれのユーザー インターフェイス上で行います
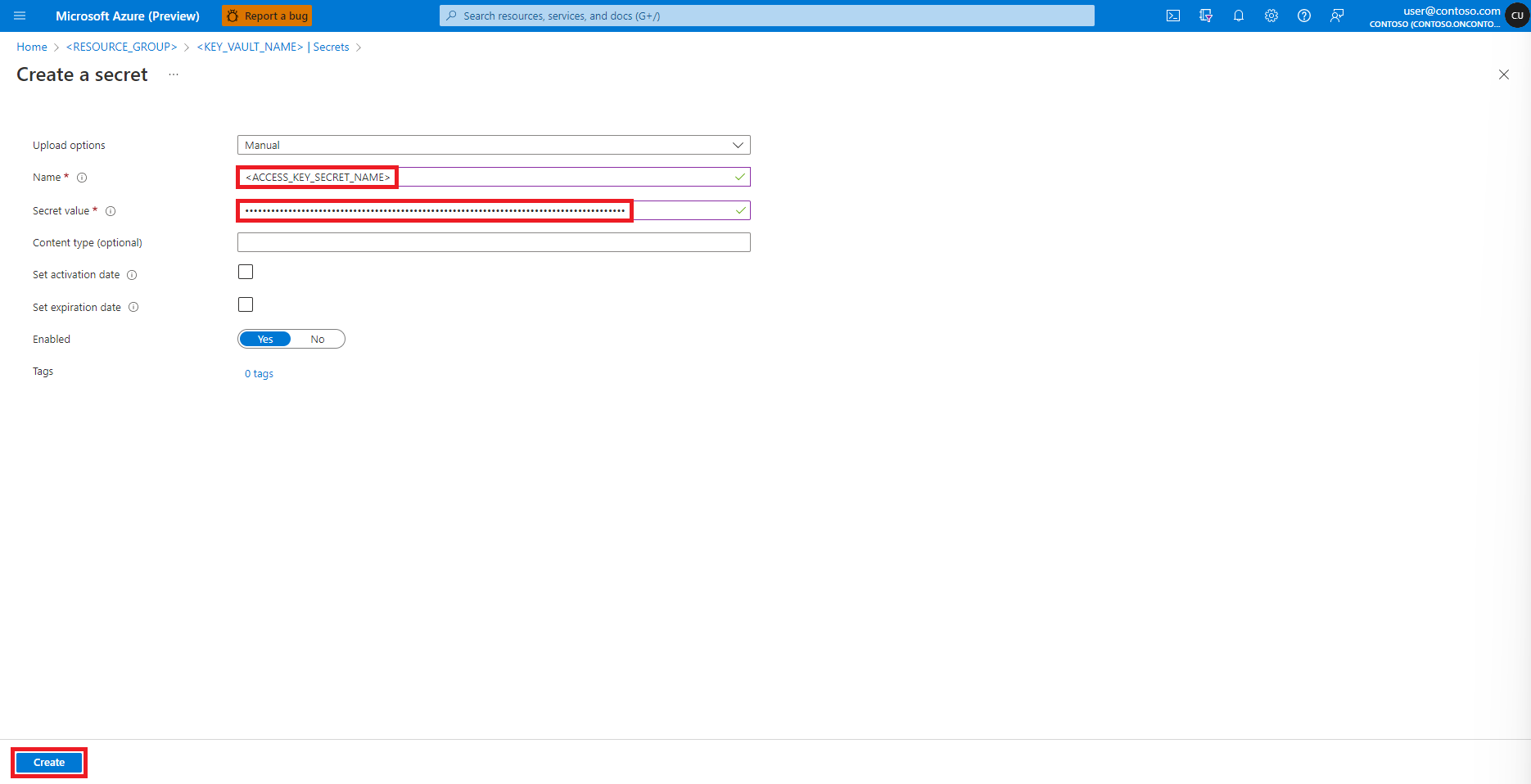
[シークレットの作成] 画面に戻ります
[シークレット値] ボックスに、前の手順でクリップボードにコピーされた Azure ストレージ アカウントのアクセス キー資格情報を入力します
[作成] を選択します
ヒント
Azure CLI と Python 用 Azure Key Vault シークレット クライアント ライブラリ では、Azure Key Vault シークレットを作成することもできます。
Azure ストレージ アカウントにロールの割り当てを追加する
対話型データ ラングリングを開始する前に、入力と出力のデータ パスにアクセスできることを確認する必要があります。 最初に
Notebooks セッションのログインしているユーザーのユーザー ID
または
サービス プリンシパル
ログイン ユーザーのユーザー ID に閲覧者およびストレージ BLOB データ閲覧者のロールを割り当てます。 ただし、特定のシナリオでは、ラングリングされたデータを Azure ストレージ アカウントに書き戻す必要がある場合があります。 閲覧者 ロールとストレージ BLOB データ閲覧者 ロールは、ユーザー ID またはサービス プリンシパルへの読み取り専用アクセスを提供します。 読み取りと書き込みアクセスを有効にするには、ユーザー ID またはサービス プリンシパルに 共同作成者 ロールと ストレージ BLOB データ共同作成者 ロールを割り当てます。 ユーザー ID に適切なロールを割り当てるには:
Microsoft Azure portal を開きます
ストレージ アカウント サービスを検索して選びます

[ストレージ アカウント] ページで、一覧から Azure Data Lake Storage (ADLS) Gen 2 ストレージ アカウントを選択します。 ストレージ アカウントの [概要] を示すページが開きます
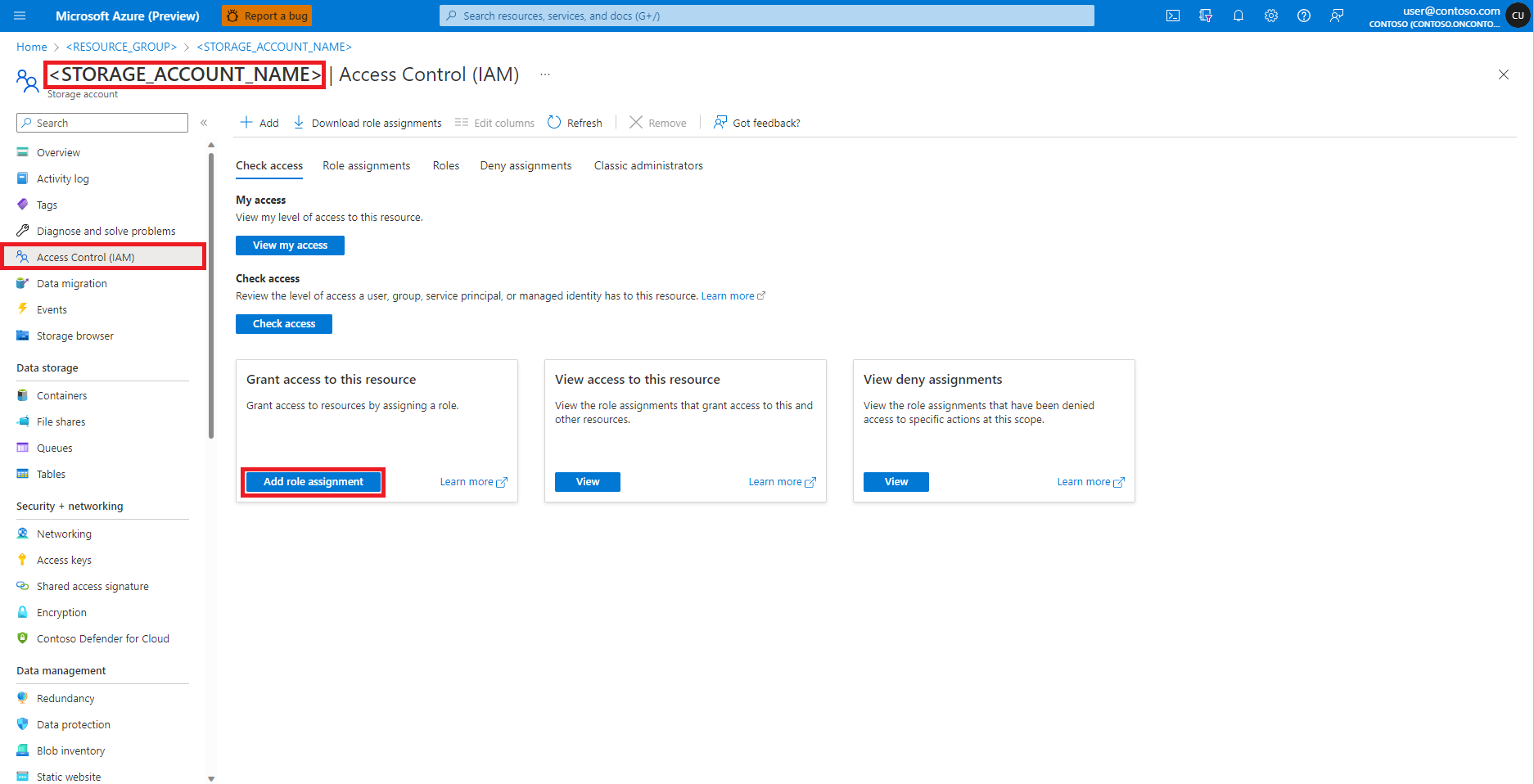
左ペインから [Access Control (IAM)](アクセス制御 (IAM)) を選択します
[ロールの割り当ての追加] を選択します
[Storage Blob Data Contributor](ストレージ BLOB データ共同作成者) ロールを見つけて選択します
[次へ] を選択します
![Azure の [ロールの割り当ての追加] 画面を示すスクリーンショット。](media/apache-spark-environment-configuration/add-role-assignment-choose-role.png?view=azureml-api-2)
[ユーザー、グループ、またはサービス プリンシパル] を選びます
[+ メンバーの選択] を選びます
[選択] の下でユーザー ID を検索します
[選択したメンバー] の下に表示されるように、リストからユーザー ID を選びます
適切なユーザー ID を選びます
[次へ] を選択します
![Azure の [ロールの割り当ての追加] 画面の [メンバー] タブを示すスクリーンショット。](media/apache-spark-environment-configuration/add-role-assignment-choose-members.png?view=azureml-api-2)
[レビューと割り当て] を選択します
![Azure の [ロールの割り当ての追加] 画面で [確認と割り当て] タブを示すスクリーンショット。](media/apache-spark-environment-configuration/add-role-assignment-review-and-assign.png?view=azureml-api-2)
共同作成者ロールの割り当てについて手順 2 から 13 を繰り返します



![Azure の [ロールの割り当ての追加] 画面を示すスクリーンショット。](media/apache-spark-environment-configuration/add-role-assignment-choose-role.png?view=azureml-api-2#lightbox)
![Azure の [ロールの割り当ての追加] 画面の [メンバー] タブを示すスクリーンショット。](media/apache-spark-environment-configuration/add-role-assignment-choose-members.png?view=azureml-api-2#lightbox)
![Azure の [ロールの割り当ての追加] 画面で [確認と割り当て] タブを示すスクリーンショット。](media/apache-spark-environment-configuration/add-role-assignment-review-and-assign.png?view=azureml-api-2#lightbox)
ユーザー ID に適切なロールが割り当てられると、Azure ストレージ アカウント内のデータにアクセスできるようになります。
Note
アタッチされた Synapse Spark プールが、マネージド仮想ネットワークが関連付けられている Azure Synapse ワークスペース内の Synapse Spark プールを指している場合は、データ アクセスを確保するために、ストレージ アカウントへのマネージド プライベート エンドポイントを構成する必要があります。
Spark ジョブのリソース アクセスを確認する
Spark ジョブでは、マネージド ID またはユーザー ID パススルーを使って、データや他のリソースにアクセスできます。 次の表は、Azure Machine Learning サーバーレス Spark コンピューティングとアタッチされた Synapse Spark プール使用中のリソース アクセスに関するさまざまなメカニズムをまとめたものです。
| Spark プール | サポートされている ID | 既定の ID |
|---|---|---|
| サーバーレス Spark コンピューティング | ユーザー ID、ワークスペースにアタッチされたユーザー割り当てマネージド ID | ユーザー ID |
| アタッチされた Synapse Spark プール | ユーザー ID、アタッチされた Synapse Spark プールにアタッチされたユーザー割り当てマネージド ID、アタッチされた Synapse Spark プールのシステム割り当てマネージド ID | アタッチされた Synapse Spark プールのシステム割り当てマネージド ID |
CLI または SDK コードでマネージド ID を使うオプションを定義する場合、Azure Machine Learning サーバーレス Spark コンピューティングは、ワークスペースにアタッチされたユーザー割り当てマネージド ID に依存します。 Azure Machine Learning CLI v2 または ARMClient を使って、既存の Azure Machine Learning ワークスペースにユーザー割り当てマネージド ID をアタッチできます。
次のステップ
- Azure Machine Learning での Apache Spark
- Azure Machine Learning で Synapse Spark プールをアタッチして管理する
- Azure Machine Learning での Apache Spark を使用した対話型データ ラングリング
- Azure Machine Learning で Spark ジョブを送信する
- Azure Machine Learning CLI を使用する Spark ジョブのコード サンプル
- Azure Machine Learning Python SDK を使用する Spark ジョブのコード サンプル