デザイナーの例外とエラー コード
この記事では、Machine Learning パイプラインのトラブルシューティングに役立つ Azure Machine Learning デザイナーのエラー メッセージと例外コードについて説明します。
デザイナーでエラー メッセージを確認するには、次の手順に従います。
失敗したコンポーネントを選択し、 [Outputs+logs](出力とログ) タブにアクセスすると、azureml-logs カテゴリの下の 70_driver_log.txt ファイルに詳細なログがあります。
詳細なコンポーネント エラーについては、module_statistics カテゴリの下にある error_info.json で確認できます。
デザイナーにおけるコンポーネントのエラー コードを次に示します。
エラー 0001
データ セットで指定した列のうち 1 つまたは複数が見つからない場合、例外が発生します。
コンポーネントに対して列を選択したが、選択した列が入力データ セットに存在しない場合、このエラーが発生します。 このエラーは、列名を手動で入力した場合、またはパイプラインの実行時にデータセットに存在しなかった列候補が列セレクターによって提供された場合に発生する可能性があります。
解決策: この例外がスローされているコンポーネントを見直し、列の名前 (1 つまたは複数) が正しいこと、および参照されているすべての列が存在することを確認します。
| 例外メッセージ |
|---|
| One or more specified columns were not found. (指定された列のうち 1 つ以上が見つかりませんでした。) |
| Column with name or index "{column_id}" not found. (名前またはインデックス "{column_id}" の列が見つかりません。) |
| Column with name or index "{column_id}" does not exist in "{arg_name_missing_column}". (名前またはインデックス "{column_id}" の列が "{arg_name_missing_column}" に存在しません。) |
| Column with name or index "{column_id}" does not exist in "{arg_name_missing_column}", but exists in "{arg_name_has_column}". (名前またはインデックス "{column_id}" の列は "{arg_name_missing_column}" には存在せず、"{arg_name_has_column}" に存在します。) |
| Columns with name or index "{column_names}" not found. (名前またはインデックス "{column_names}" の列が見つかりません。) |
| Columns with name or index "{column_names}" does not exist in "{arg_name_missing_column}". (名前またはインデックス "{column_names}" の列が "{arg_name_missing_column}" に存在しません。) |
| Columns with name or index "{column_names}" does not exist in "{arg_name_missing_column}", but exists in "{arg_name_has_column}". (名前またはインデックス "{column_names}" の列は "{arg_name_missing_column}" には存在せず、"{arg_name_has_column}" に存在します。) |
エラー 0002
1 つ以上のパラメーターを解析できなかったか、指定した型からターゲット メソッドの型で必須に変換できなかった場合、例外が発生します。
このエラーは、パラメーターを入力として指定し、値の型が想定される型と異なり、暗黙的な変換を実行できない場合に、Azure Machine Learning で発生します。
解決策: コンポーネントの要件を確認し、必要な値の型を特定します (文字列、整数、倍精度浮動小数点数型など)
| 例外メッセージ |
|---|
| Failed to parse parameter. (パラメーターを解析できませんでした。) |
| Failed to parse "{arg_name_or_column}" parameter. ("{arg_name_or_column}" パラメーターを解析できませんでした。) |
| Failed to convert "{arg_name_or_column}" parameter to "{to_type}". ("{arg_name_or_column}" パラメーターを "{to_type}" に変換できませんでした。) |
| Failed to convert "{arg_name_or_column}" parameter from "{from_type}" to "{to_type}". ("{arg_name_or_column}" パラメーターを "{from_type}" から "{to_type}" に変換できませんでした。) |
| Failed to convert "{arg_name_or_column}" parameter value "{arg_value}" from "{from_type}" to "{to_type}". ("{arg_name_or_column}" パラメーター値 "{arg_value}" を "{from_type}" から "{to_type}" に変換できませんでした。) |
| Failed to convert value "{arg_value}" in column "{arg_name_or_column}" from "{from_type}" to "{to_type}" with usage of the format "{fmt}" provided. (指定された形式 "{fmt}" を使用して、列 "{arg_name_or_column}" の値 "{arg_value}" を "{from_type}" から "{to_type}" に変換できませんでした。) |
エラー 0003
1 つまたは複数の入力が null または空の場合、例外が発生します。
コンポーネントへの入力またはパラメーターが null または空の場合、Azure Machine Learning でこのエラーが発生します。 このエラーは、たとえば、パラメーターの値を入力しなかった場合に発生する可能性があります。 欠損値のあるデータセットまたは空のデータセットを選択した場合にも、発生する可能性があります。
解決策:
- 例外が発生したコンポーネントを開き、すべての入力が指定されていることを確認します。 すべての必須入力が指定されていることを確認します。
- Azure Storage から読み込まれたデータにアクセスできることを確認し、アカウント名またはキーが変更されていないことを確認します。
- 入力データで欠損値または null 値を確認します。
- データ ソースに対するクエリを使用している場合は、必要な形式でデータが返されることを確認します。
- 入力ミスや、データの指定でのその他の変更を確認します。
| 例外メッセージ |
|---|
| One or more of inputs are null or empty. (1 つまたは複数の入力が null または空です。) |
| Input "{name}" is null or empty. (入力 "{name}" が null または空です。) |
エラー 0004
パラメーターが特定の値以下の場合、例外が発生します。
メッセージ内のパラメーターが、コンポーネントがデータを処理するために必要な境界値を下回っている場合は、Azure Machine Learning でこのエラーが発生します。
解決策: 例外がスローされているコンポーネントを見直し、指定された値より大きくなるようにパラメーターを修正します。
| 例外メッセージ |
|---|
| Parameter should be greater than boundary value. (パラメーターは、境界値より大きい値にする必要があります。) |
| Parameter "{arg_name}" value should be greater than {lower_boundary}. (パラメーター "{arg_name}" の値は {lower_boundary} より大きくする必要があります。) |
| Parameter "{arg_name}" has value "{actual_value}" which should be greater than {lower_boundary}. (パラメーター "{arg_name}" には値 "{actual_value}" が含まれていますが、これは {lower_boundary} より大きくする必要があります。) |
エラー 0005
パラメーターが特定の値より小さい場合、例外が発生します。
メッセージ内のパラメーターが、コンポーネントがデータを処理するために必要な境界値以下の場合、Azure Machine Learning でこのエラーが発生します。
解決策: 例外がスローされているコンポーネントを見直し、指定された値以上になるようにパラメーターを修正します。
| 例外メッセージ |
|---|
| Parameter should be greater than or equal to boundary value. (パラメーターは、境界値以上にする必要があります。) |
| Parameter "{arg_name}" value should be greater than or equal to {lower_boundary}. (パラメーター "{arg_name}" の値は {lower_boundary} 以上とする必要があります。) |
| Parameter "{arg_name}" has value "{value}" which should be greater than or equal to {lower_boundary}. (パラメーター "{arg_name}" には値 "{value}" が含まれていますが、これは {lower_boundary} 以上とする必要があります。) |
エラー 0006
パラメーターが指定された値以上の場合、例外が発生します。
メッセージ内のパラメーターが、コンポーネントがデータを処理するために必要な境界値以上の場合、Azure Machine Learning でこのエラーが発生します。
解決策: 例外がスローされているコンポーネントを見直し、指定された値より小さくなるようにパラメーターを修正します。
| 例外メッセージ |
|---|
| Parameters mismatch. (パラメーターが一致しません。) One of the parameters should be less than another. (パラメーターの 1 つは他より小さくする必要があります。) |
| Parameter "{arg_name}" value should be less than parameter "{upper_boundary_parameter_name}" value. (パラメーター "{arg_name}" の値は、パラメーター "{upper_boundary_parameter_name}" の値より小さくする必要があります。) |
| Parameter "{arg_name}" has value "{value}" which should be less than {upper_boundary_parameter_name}. (パラメーター "{arg_name}" には値 "{value}" が含まれていますが、これは {upper_boundary_parameter_name} より小さくする必要があります。) |
エラー 0007
パラメーターが特定の値より大きい場合、例外が発生します。
このエラーは、コンポーネントのプロパティで、許可されている値より大きい値を指定した場合に、Azure Machine Learning で発生します。 たとえば、サポートされる日付の範囲外にあるデータを指定した場合や、3 列のみ使用可能なときに 5 列を使用することを示した場合です。
また、何らかの方法で一致する必要がある 2 つのデータ セットを指定している場合も、このエラーが表示されることがあります。 たとえば、列の名前を変更し、インデックスで列を指定する場合、指定する名前の数は列インデックスの数と一致する必要があります。 もう 1 つの例として、2 つの列を使用する算術演算では、列に同じ数の行が含まれる必要があります。
解決策:
- 問題のコンポーネントを開き、数値プロパティの設定を確認します。
- すべてのパラメーター値が、そのプロパティに対してサポートされている値の範囲内にあることを確認します。
- コンポーネントが複数の入力を受け取る場合は、入力が同じサイズであることを確認します。
- データセットまたはデータ ソースが変更されたかどうかを確認します。 以前のバージョンのデータで動作していた値が、列の数、列のデータ型、またはデータのサイズを変更すると失敗することがあります。
| 例外メッセージ |
|---|
| Parameters mismatch. (パラメーターが一致しません。) One of the parameters should be less than another. (パラメーターの 1 つが他より小さい必要があります。) |
| Parameter "{arg_name}" value should be less than or equal to parameter "{upper_boundary_parameter_name}" value. (パラメーター "{arg_name}" の値は、パラメーター "{upper_boundary_parameter_name}" の値以下とする必要があります。) |
| Parameter "{arg_name}" has value "{actual_value}" which should be less than or equal to {upper_boundary}. (パラメーター "{arg_name}" には値 "{actual_value}" が含まれていますが、これは {upper_boundary} 以下とする必要があります。) |
| Parameter "{arg_name}" value {actual_value} should be less than or equal to parameter "{upper_boundary_parameter_name}" value {upper_boundary}. (パラメーター "{arg_name}" の値 {actual_value} は、パラメーター "{upper_boundary_parameter_name}" の値 {upper_boundary} 以下とする必要があります。) |
| Parameter "{arg_name}" value {actual_value} should be less than or equal to {upper_boundary_meaning} value {upper_boundary}. (パラメーター "{arg_name}" の値 {actual_value} は、"{upper_boundary_meaning}" の値 {upper_boundary} 以下とする必要があります。) |
エラー 0008
パラメーターが範囲内にない場合、例外が発生します。
メッセージ内のパラメーターが、コンポーネントがデータを処理するために必要な範囲外にある場合は、Azure Machine Learning でこのエラーが発生します。
たとえば、行の追加を使って列の数が異なる 2 つのデータセットを結合しようとすると、このエラーが表示されます。
解決策: 例外がスローされているコンポーネントを見直し、指定された範囲内になるようにパラメーターを修正します。
| 例外メッセージ |
|---|
| Parameter value is not in the specified range. (パラメーターの値が、指定された範囲内ではありません。) |
| Parameter "{arg_name}" value is not in range. (パラメーター "{arg_name}" の値が範囲内ではありません。) |
| Parameter "{arg_name}" value should be in the range of [{lower_boundary}, {upper_boundary}]. (パラメーター "{arg_name}" の値は、[{lower_boundary}, {upper_boundary}] の範囲内に収める必要があります。) |
| Parameter "{arg_name}" value is not in range. (パラメーター "{arg_name}" の値が範囲内ではありません。) {reason} |
エラー 0009
Azure ストレージ アカウント名またはコンテナー名が正しく指定されていない場合、例外が発生します。
このエラーは、Azure ストレージ アカウントのパラメーターを指定したが、名前またはパスワードを解決できない場合に、Azure Machine Learning デザイナーで発生します。 パスワードまたはアカウント名に関するエラーは、多くの理由で発生する可能性があります。
- アカウントの種類が正しくありません。 一部の新しいアカウントの種類は、Machine Learning デザイナーで使用できません。 詳しくは、「Import Data (データのインポート)」をご覧ください。
- 正しくないアカウント名を入力しました
- アカウントはもう存在しません
- ストレージ アカウントのパスワードが間違っているか、変更されています
- コンテナー名を指定しなかったか、コンテナーが存在しない
- ファイルのパス (BLOB へのパス) を完全に指定していません
解決策:
このような問題は、アカウント名、パスワード、またはコンテナーのパスを手入力しようとすると発生することがよくあります。 データのインポート コンポーネントの新しいウィザードを使うことをお勧めします。名前の検索と確認に役立ちます。
また、アカウント、コンテナー、または BLOB が削除されているかどうかも確認します。 アカウント名とパスワードが正しく入力されたこと、およびコンテナーが存在することを確認するには、別の Azure ストレージ ユーティリティを使います。
一部の新しいアカウントの種類は、Azure Machine Learning ではサポートされていません。 たとえば、新しい "ホット" または "コールド" のストレージの種類を機械学習に使用することはできません。 従来のストレージ アカウントおよび "汎用" として作成されたストレージ アカウントはどちらも、正常に動作します。
BLOB への完全なパスを指定した場合は、パスが "コンテナー/BLOB 名" として指定されていること、およびコンテナーと BLOB の両方がアカウントに存在することを確認します。
パスに先頭のスラッシュを含めることはできません。 たとえば、 /container/blob は正しくなく、container/blob と入力する必要があります。
| 例外メッセージ |
|---|
| The Azure storage account name or container name is incorrect. (Azure ストレージ アカウント名またはコンテナー名が正しくありません。) |
| The Azure storage account name "{account_name}" or container name "{container_name}" is incorrect; a container name of the format container/blob was expected. (Azure ストレージ アカウント名 "{account_name}" またはコンテナー名 "{container_name}" が正しくありません。コンテナー名は "コンテナー/BLOB" の形式であることが予想されていました。) |
エラー 0010
入力データセットで一致している必要のある列名があっても、そうなっていない場合、例外が発生します。
メッセージ内の列インデックスの列名が 2 つの入力データセットで異なる場合、Azure Machine Learning でこのエラーが発生します。
解決策:メタデータの編集を使うか、または元のデータセットを変更して指定された列インデックスの列名を同じにします。
| 例外メッセージ |
|---|
| Columns with corresponding index in input datasets have different names. (入力データセット内の対応するインデックスに伴う列の名前が異なります。) |
| Column names are not the same for column {col_index} (zero-based) of input datasets ({dataset1} and {dataset2} respectively). (入力データセット ({dataset1} と {dataset2}) それぞれの列 {col_index} (ゼロ ベース) に対する列の名前が同じではありません。) |
エラー 0011
渡された列セット引数がデータセット列のいずれにも適用されない場合、例外が発生します。
指定した列の選択が、指定されたデータセット内の列のいずれにも一致しない場合、Azure Machine Learning でこのエラーが発生します。
コンポーネントが動作するために少なくとも 1 つの列が必要なときに列が選択されていない場合も、このエラーが発生することがあります。
解決策: データセット内の列に適用されるように、コンポーネント内の列の選択を変更します。
特定の列 (ラベル列など) を選択する必要があるコンポーネントの場合、正しい列が選択されていることを確認します。
不適切な列が選択されている場合は、それらを削除し、パイプラインを再実行します。
| 例外メッセージ |
|---|
| Specified column set does not apply to any of dataset columns. (指定された列セットは、データセットのどの列にも適用されません。) |
| Specified column set "{column_set}" does not apply to any of dataset columns. (指定された列セット "{column_set}" が、データセットのどの列にも適用されません。) |
エラー 0012
渡された一連の引数でクラスのインスタンスを作成できなかった場合、例外が発生します。
解決策: このエラーはユーザーが操作できないため、今後のリリースで非推奨となる予定です。
| 例外メッセージ |
|---|
| Untrained model, please train model first. (未トレーニングのモデルです。先に、モデルをトレーニングしてください。) |
| Untrained model ({arg_name}), use trained model. (未トレーニングのモデル ({arg_name}) です。トレーニング済みのモデルを使用してください。) |
エラー 0013
コンポーネントに渡された学習器が無効な種類の場合、例外が発生します。
このエラーは、トレーニング済みモデルと接続されたスコアリング コンポーネントとの間に互換性がないときに、常に発生します。
解決策:
トレーニング コンポーネントによって生成される学習器の種類を特定し、学習器に対する適切なスコアリング コンポーネントを決定します。
モデルが特別なトレーニング コンポーネントを使ってトレーニングされた場合、対応する特別なスコアリング コンポーネントにのみ、トレーニング済みモデルを接続します。
| モデルの種類 | トレーニング コンポーネント | スコアリング コンポーネント |
|---|---|---|
| 任意の分類子 | モデルのトレーニング | モデルのスコア付け |
| 任意の回帰モデル | モデルのトレーニング | モデルのスコア付け |
| 例外メッセージ |
|---|
| Learner of invalid type is passed. (無効な種類の学習器が渡されました。) |
| Learner "{arg_name}" has invalid type. (学習器 "{arg_name}" の種類が無効です。) |
| Learner "{arg_name}" has invalid type "{learner_type}". (学習器 "{arg_name}" の種類 "{learner_type}" は無効です。) |
| Learner of invalid type is passed. (無効な種類の学習器が渡されました。) Exception message: {exception_message} (例外メッセージ: {exception_message}) |
エラー 0014
列の一意の値の数が許容されているより多い場合、例外が発生します。
このエラーは、ID 列やテキスト列など、列に含まれる一意の値の数が多すぎる場合に発生します。 列がカテゴリ データとして処理するように指定されていても、列の一意の値が多すぎて処理を完了できない場合、このエラーが発生する可能性があります。 また、2 つの入力で一意の値の数が一致しない場合にも、このエラーが表示されることがあります。
次の条件の両方を満たした場合に、一意の値が許可される数を上回るエラーが発生します。
- 1 つの列の 97% を超えるインスタンスが一意の値であるため、ほぼすべてのカテゴリが互いに異なっています。
- 1 つの列に 1,000 を超える一意の値があります。
解決策:
エラーが発生したコンポーネントを開き、入力として使用されている列を特定します。 一部のコンポーネントでは、データセット入力を右クリックして [視覚化] を選択し、一意の値の数とその分布が含まれる個々の列の統計情報を取得できます。
グループ化または分類に使用する列の場合は、列の一意の値の数を減らすための手順を実行します。 列のデータ型に応じて、さまざまな方法で減らすことができます。
モデルのトレーニング中に意味のある機能ではない ID 列の場合は、 Edit Metadata を使用してその列を Clear 機能としてマークできます モデルのトレーニング中には使用されません。
テキスト列の場合、特徴ハッシュやテキストからの N gram 特徴抽出コンポーネントを利用し、テキスト列を事前処理できます。
ヒント
シナリオに合った解決策が見つかりませんか。 このトピックのフィードバックとして、エラーが発生したコンポーネントの名前と、列のデータ型およびカーディナリティを提供してください。 その情報を使用して、一般的なシナリオに対してさらに対象を絞り込んだトラブルシューティング手順を提供します。
| 例外メッセージ |
|---|
| Amount of column unique values is greater than allowed. (列の一意の値の量が許容値を超えています。) |
| Number of unique values in column: "{column_name}" is greater than allowed. (列 "{column_name}" の一意の値の数が許容される数を超えています。) |
| Number of unique values in column: "{column_name}" exceeds tuple count of {limitation}. (列 "{column_name}" の一意の値の数がタプル数 {limitation} を超えています。) |
エラー 0015
データベース接続が失敗した場合、例外が発生します。
正しくない SQL アカウント名、パスワード、データベース サーバー、またはデータベース名を入力した場合、またはデータベースまたはサーバーの問題が原因でデータベースとの接続を確立できない場合、このエラーが発生します。
解決策: アカウント名、パスワード、データベース サーバー、およびデータベースを正しく入力したこと、および指定したアカウントに適切なレベルのアクセス許可があることを確認します。 データベースが現在アクセス可能であることを確認します。
| 例外メッセージ |
|---|
| Error making database connection. (データベースとの接続でエラーが発生しました。) |
| Error making database connection: {connection_str}. (データベースとの接続中にエラーが発生しました: {connection_str}。) |
エラー 0016
コンポーネントに渡される入力データセットに互換性のある列型が必要だが、互換性がない場合、例外が発生します。
2 つ以上のデータセットで渡された列の型が互いに互換性がない場合は、Azure Machine Learning でこのエラーが発生します。
解決策:メタデータの編集を使うか、または元の入力データセットを修正して、列の型が互換性を備えるようにします。
| 例外メッセージ |
|---|
| Columns with corresponding index in input datasets do have incompatible types. (入力データセット内の対応するインデックスを伴う列に互換性のない型が含まれています。) |
| Columns '{first_col_names}' are incompatible between train and test data. (トレーニングとテストのデータの間で、列 '{first_col_names}' に互換性がありません。) |
| Columns '{first_col_names}' and '{second_col_names}' are incompatible. (列 '{first_col_names}' と '{second_col_names}' には互換性がありません。) |
| 列要素の型は、入力データセット ({first_dataset_names} と {second_dataset_names} の列 '{first_col_names}' (0 から始まる) に対応していません。 |
エラー 0017
選択した列で、現在のコンポーネントでサポートされていないデータ型が使用されている場合、例外が発生します。
たとえば、数値演算の文字列列やカテゴリ特徴列が必要なスコア列など、コンポーネントで処理できないデータ型の列が列の選択に含まれている場合、Azure Machine Learning でこのエラーが発生することがあります。
解決策:
- 問題となっている列を特定します。
- コンポーネントの要件を確認します。
- 要件に準拠するように列を修正します。 列と変換の試行に応じて、次のいくつかのコンポーネントを使用して変更が必要になる場合があります。
- Edit Metadataを使用して、列のデータ型を変更したり、列の使用法を特徴から数値、カテゴリから非カテゴリに変更したりできます。
- 最後の手段として、元の入力データセットの修正が必要になる可能性があります。
ヒント
シナリオに合った解決策が見つかりませんか。 このトピックのフィードバックとして、エラーが発生したコンポーネントの名前と、列のデータ型およびカーディナリティを提供してください。 その情報を使用して、一般的なシナリオに対してさらに対象を絞り込んだトラブルシューティング手順を提供します。
| 例外メッセージ |
|---|
| Cannot process column of current type. (現在の型の列を処理することができません。) The type is not supported by the component. (型がコンポーネントでサポートされていません。) |
| Cannot process column of type {col_type}. (型 {col_type} の列を処理できません。) The type is not supported by the component. (型がコンポーネントでサポートされていません。) |
| Cannot process column "{col_name}" of type {col_type}. (型 {col_type} の列 "{col_name}" を処理できません。) The type is not supported by the component. (型がコンポーネントでサポートされていません。) |
| Cannot process column "{col_name}" of type {col_type}. (型 {col_type} の列 "{col_name}" を処理できません。) The type is not supported by the component. (型がコンポーネントでサポートされていません。) Parameter name: {arg_name}. (パラメーター名: {arg_name}。) |
エラー 0018
入力データセットが有効でない場合、例外が発生します。
解決策: Azure Machine Learning のこのエラーは多くのコンテキストで発生する可能性があるため、1 つの解決策はありません。 一般に、このエラーは、コンポーネントへの入力として指定されたデータの列数が間違っているか、データ型がコンポーネントの要件と一致しないことを示します。 次に例を示します。
コンポーネントにはラベル列が必要ですが、列がラベルとしてマークされていないか、ラベル列をまだ選択していません。
コンポーネントではデータはカテゴリである必要がありますが、データが数値です。
データの形式が正しくありません。
インポートされたデータに、無効な文字、無効な値、または範囲外の値が含まれています。
列が空か、または欠損値が多く含みすぎています。
要件とデータの方法を決定するには、データセットを入力として使用するコンポーネントのヘルプ記事を確認してください。
.| 例外メッセージ |
|---|
| Dataset is not valid. (データセットが無効です。) |
| {dataset1} contains invalid data. ({dataset1} に無効なデータが含まれています。) |
| {dataset1} and {dataset2} should be consistent columnwise. ({dataset1} と {dataset2} には、列方向で一貫性がある必要があります。) |
| {dataset1} contains invalid data, {reason}. ({dataset1} に無効なデータが含まれています {reason}。) |
| {dataset1} contains {invalid_data_category}. ({dataset1} に {invalid_data_category} が含まれています。) {troubleshoot_hint} |
| {dataset1} is not valid, {reason}. ({dataset1} は無効です。{reason}。) {troubleshoot_hint} |
エラー 0019
列に並べ替えられた値が含まれていると予想されるが、含まれていない場合は例外が発生します。
指定した列の値が順序に合わない場合は、Azure Machine Learning でこのエラーが発生します。
解決策: 入力データセットを手動で変更して列の値を並べ替えた後、コンポーネントを再実行します。
| 例外メッセージ |
|---|
| Values in column are not sorted. (列の値が並べ替えられていません。) |
| Values in column "{col_index}" are not sorted. (列 "{col_index}" の値が並べ替えられていません。) |
| Values in column "{col_index}" of dataset "{dataset}" are not sorted. (データセット "{dataset}" の列 "{col_index}" の値が並べ替えられていません。) |
| Values in argument "{arg_name}" are not sorted in "{sorting_order}" order. (引数 "{arg_name}" の値が "{sorting_order}" の順序で並べ替えられていません。) |
エラー 0020
コンポーネントに渡された一部のデータセットの列の数が少なすぎる場合、例外が発生します。
コンポーネントに対して十分な列が選択されていない場合は、Azure Machine Learning でこのエラーが発生します。
解決策: コンポーネントを見直し、列セレクターで正しい数の列が選択されていることを確認します。
| 例外メッセージ |
|---|
| Number of columns in input dataset is less than allowed minimum. (入力データセット内の列数が、許容される最少数未満です。) |
| Number of columns in input dataset "{arg_name}" is less than allowed minimum. (入力データセット "{arg_name}" 内の列数が、許容される最小値を下回っています。) |
| Number of columns in input dataset is less than allowed minimum of {required_columns_count} column(s). (入力データセットの列数が、許容される最小数の {required_columns_count} 列未満です。) |
| Number of columns in input dataset "{arg_name}" is less than allowed minimum of {required_columns_count} column(s). (入力データセット "{arg_name}" の列数が、許容される最小数の {required_columns_count} 列未満です。) |
エラー 0021
コンポーネントに渡された一部のデータセットの行の数が少なすぎる場合、例外が発生します。
このエラーは、指定された操作を実行するのに十分な行がデータセットにない場合に、Azure Machine Learning に表示されます。 たとえば、入力データセットが空の場合や、いくつかの最小行数を有効にする必要がある操作を実行しようとしている場合に、このエラーが表示されることがあります。 このような操作には、統計方法、特定の種類のビン分割、カウントを使用した学習に基づくグループ化または分類が含まれます (ただし、これらに限定されません)。
解決策:
- エラーを返したコンポーネントを開き、入力データセットとコンポーネントのプロパティを確認します。
- 入力データセットが空でないことを確認し、コンポーネント ヘルプで説明されている要件を満たすのに十分なデータ行があることを確認します。
- データが外部ソースから読み込まれる場合は、データ ソースが使用可能であり、インポート プロセスの行数が少なくなる原因となるデータ定義にエラーや変更がないことを確認します。
- コンポーネントの上流にあるデータに対して、データの種類や値の数 (クリーニング、分割、結合操作など) に影響する可能性がある操作を実行している場合は、それらの操作の出力を確認して、返される行数を確認します。
| 例外メッセージ |
|---|
| Number of rows in input dataset is less than allowed minimum. (入力データセット内の行数が、許容される最小数未満です。) |
| Number of rows in input dataset is less than allowed minimum of {required_rows_count} row(s). (入力データセット内の行数が、許容される最小数の {required_rows_count} 行未満です。) |
| Number of rows in input dataset is less than allowed minimum of {required_rows_count} row(s). (入力データセット内の行数が、許容される最小数の {required_rows_count} 行未満です。) {reason} |
| Number of rows in input dataset "{arg_name}" is less than allowed minimum of {required_rows_count} row(s). (入力データセット "{arg_name}" 内の行数が、許容される最小数の {required_rows_count} 行未満です。) |
| Number of rows in input dataset "{arg_name}" is {actual_rows_count}, less than allowed minimum of {required_rows_count} row(s). (入力データセット "{arg_name}" 内の行数は {actual_rows_count} で、許容される最小数の {required_rows_count} 行未満です。) |
| Number of "{row_type}" rows in input dataset "{arg_name}" is {actual_rows_count}, less than allowed minimum of {required_rows_count} row(s). (入力データセット "{arg_name}" 内の "{row_type}" 行の数は {actual_rows_count} で、許容される最小数の {required_rows_count} 行未満です。) |
エラー 0022
入力データセット内の選択された列の数が予想される数と等しくない場合、例外が発生します。
Azure Machine Learning では、ダウンストリームのコンポーネントまたは操作で特定の数の列または入力が必要なときに、提供する列または入力が多すぎるか少なすぎる場合、このエラーが発生します。 次に例を示します。
1 つのラベル列またはキー列を指定するときに、誤って複数の列を選択している。
列の名前を変更するが、列よりも多くの名前または少ない名前を指定している。
ソースまたはターゲットの列の数が変更された、またはコンポーネントによって使用される列の数と一致しない。
入力の値のコンマ区切りのリストを指定しましたが、値の数が一致しないか、複数の入力がサポートされていません。
解決策: コンポーネントを見直し、列の選択を調べて、正しい数の列が選択されていることを確認します。 アップストリームのコンポーネントの出力と、ダウンストリームの操作の要件を確認します。
複数の列を選択できる列選択オプションのいずれかを使った場合 (列のインデックス、すべての特徴、すべての数字など)、選択によって返される列の正確な数を確認します。
アップストリーム列の数または種類が変更されていないかどうかを確認します。
レコメンデーション データセットを使用してモデルをトレーニングする場合、レコメンダーは、ユーザーと項目のペアまたはユーザー項目のランク付けに対応する限られた数の列を想定していることを覚えておいてください。 モデルをトレーニングする前、または推奨データセットを分割する前に、追加の列を削除します。 詳しくは、「Split Data (データの分割)」をご覧ください。
| 例外メッセージ |
|---|
| Number of selected columns in input dataset does not equal to the expected number. (入力データセットで選択された列の数が、予想される数と等しくありません。) |
| Number of selected columns in input dataset does not equal to {expected_col_count}. (入力データセットで選択された列の数が、{expected_col_count} と等しくありません。) |
| Column selection pattern "{selection_pattern_friendly_name}" provides number of selected columns in input dataset not equal to {expected_col_count}. (列選択パターン "{selection_pattern_friendly_name}" で提供される入力データセット内で選択された列の数が、{expected_col_count} と等しくありません。) |
| Column selection pattern "{selection_pattern_friendly_name}" is expected to provide {expected_col_count} column(s) selected in input dataset, but {selected_col_count} column(s) is/are actually provided. (列選択パターン "{selection_pattern_friendly_name}" では入力データセット内で選択された {expected_col_count} 列が指定される必要がありますが、実際には {selected_col_count} 列が指定されています。) |
エラー 0023
入力データセットのターゲット列が現在のトレーナー コンポーネントに対して有効でない場合、例外が発生します。
Azure Machine Learning のこのエラーは、(コンポーネント パラメーターで選択されている) ターゲット列が有効なデータ型ではない場合、欠損値がすべて含まれている場合、または想定どおりにカテゴリ化されていない場合に発生します。
解決策: コンポーネントの入力を見直し、ラベル/ターゲット列の内容を調べます。 すべての欠損値が含まれていないことを確認します。 コンポーネントでターゲット列がカテゴリである必要がある場合、ターゲット列に複数の個別値があることを確認します。
| 例外メッセージ |
|---|
| Input dataset has unsupported target column. (入力データセットにサポートされていないターゲット列があります。) |
| Input dataset has unsupported target column "{column_index}". (入力データセットにサポートされていないターゲット列 "{column_index}" があります。) |
| Input dataset has unsupported target column "{column_index}" for learner of type {learner_type}. (入力データセットに {learner_type} 型の学習器に対してサポートされていないターゲット列 "{column_index}" があります。) |
エラー 0024
データセットにラベル列が含まれていない場合、例外が発生します。
Azure Machine Learning のこのエラーは、コンポーネントにラベル列が必要で、データセットにラベル列がない場合に発生します。 たとえば、スコアリングされたデータセットの評価では、通常、正確さのメトリックを計算するためにラベル列が存在する必要があります。
また、ラベル列がデータセットに存在していても、Azure Machine Learning によって正しく検出されない場合にも、発生することがあります。
解決策:
- エラーを生成したコンポーネントを開き、ラベル列が存在するかどうかを確認します。 予測しようとしている 1 つの結果 (または従属変数) が列に含まれている限り、列の名前またはデータ型は重要ではありません。 ラベルを持つ列がわからない場合は、 Class または Target などの汎用名を探します。
- データセットにラベル列が含まれていない場合は、ラベル列が明示的に削除されたか、アップストリームで誤って削除された可能性があります。 また、データセットがアップストリーム スコアリング コンポーネントの出力ではない可能性もあります。
- ラベル列として列を明示的にマークするには、メタデータの編集コンポーネントを追加して、データセットを接続します。 ラベル列だけを選択し、 [フィールド] ドロップダウン リストから [ラベル] を選択します。
- 間違った列をラベルとして選択した場合は、 [フィールド] から [ラベルのクリア] を選択して、列のメタデータを修正できます。
| 例外メッセージ |
|---|
| There is no label column in dataset. (データセットにラベル列がありません。) |
| There is no label column in "{dataset_name}". ("{dataset_name}" にはラベル列がありません。) |
エラー 0025
データセットにスコア列が含まれていない場合、例外が発生します。
評価されたモデルへの入力に有効なスコア列が含まれていない場合、Azure Machine Learning でこのエラーが発生します。 たとえば、適切なトレーニング済みモデルでデータセットがスコアリングされる前にユーザーがデータセットを評価しようとしているか、またはアップストリームでスコア列が明示的に削除されています。 2 つのデータセットのスコア列に互換性がない場合も、この例外が発生します。 たとえば、線形リグレッサーの精度をバイナリ分類器と比較しようとしている可能性があります。
解決策: 評価されたモデルへの入力を見直し、1 つ以上のスコア列が含まれているかどうかを調べます。 そうでない場合は、データセットがスコア付けされなかったか、スコア列がアップストリーム コンポーネントで削除されました。
| 例外メッセージ |
|---|
| There is no score column in dataset. (データセットにスコア列がありません。) |
| There is no score column in "{dataset_name}". ("{dataset_name}" にスコア列がありません。) |
| There is no score column in "{dataset_name}" that is produced by a "{learner_type}". ("{learner_type}" によって生成されたスコア列が "{dataset_name}" にありません。) Score the dataset using the correct type of learner. (適切な種類の学習器を使用してデータセットをスコアリングしてください。) |
エラー 0026
同じ名前の列が許可されていない場合、例外が発生します。
Azure Machine Learning では、複数の列の名前が同じ場合、このエラーが発生します。 このエラーを受け取る方法の 1 つは、データセットにヘッダー行がない場合と列名が自動的に割り当てられている場合です(Col0、Col1 など)。
解決策: 複数の列に同じ名前が付けられている場合は、入力データセットとコンポーネントの間にメタデータの編集コンポーネントを挿入します。 メタデータの編集で列セレクターを使って名前を変更する列を選択し、 [新しい列名] テキスト ボックスに新しい名前を入力します。
| 例外メッセージ |
|---|
| Equal column names are specified in arguments. (同じ列名が引数で指定されています。) Equal column names are not allowed by component. (コンポーネントでは同じ列名は許可されません。) |
| Equal column names in arguments "{arg_name_1}" and "{arg_name_2}" are not allowed. (引数 "{arg_name_1}" と "{arg_name_2}" での同じ列名は許可されません。) Please specify different names. (別の名前を指定してください。) |
エラー 0027
例外は、2 つのオブジェクトが同じサイズである必要があるが、同じでない場合に発生します。
これは Azure Machine Learning の一般的なエラーであり、多くの状況で発生することがあります。
解決策: 特定の解決策はありません。 ただし、次のような状況を確認することはできます。
列の名前を変更する場合は、各リスト (入力列と新しい名前のリスト) に同じ数の項目があることを確認します。
2 つのデータセットを結合または連結する場合は、それらが同じスキーマを持っていることを確認します。
複数の列を持つ 2 つのデータセットを結合する場合は、キー列のデータ型が同じであることを確認し、 重複を解除し、選択した列の順序を保持するオプションを選択します。
| 例外メッセージ |
|---|
| The size of passed objects is inconsistent. (渡されたオブジェクトのサイズが一致していません。) |
| The size of "{friendly_name1}" is inconsistent with size of "{friendly_name2}". ("{friendly_name1}" のサイズが "{friendly_name2}" のサイズと一致していません。) |
エラー 0028
例外は、列セットに重複する列名が含まれており、許可されていない場合に発生します。
Azure Machine Learning では、列名が重複している場合、つまり一意ではない場合、このエラーが発生します。
解決策: 同じ名前の列がある場合は、入力データセットと、エラーが発生したコンポーネントの間に、メタデータの編集のインスタンスを追加します。 メタデータの編集で列セレクターを使って名前を変更する列を選択し、 [新しい列名] テキスト ボックスに新しい列名を入力します。 複数の列の名前を変更する場合は、 New 列名 に入力する値が一意であることを確認します。
| 例外メッセージ |
|---|
| Column set contains duplicated column name(s). (列セットに重複する列名が含まれます。) |
| The name "{duplicated_name}" is duplicated. (名前 "{duplicated_name}" が重複しています。) |
| The name "{duplicated_name}" is duplicated in "{arg_name}". (名前 "{duplicated_name}" が "{arg_name}" で重複しています。) |
| The name "{duplicated_name}" is duplicated. (名前 "{duplicated_name}" が重複しています。) Details: {details} (詳細: {details}) |
エラー 0029
無効な URI が渡された場合、例外が発生します。
Azure Machine Learning では、無効な URI が渡された場合、このエラーが発生します。 次のいずれかの条件に該当する場合は、このエラーが発生します。
読み取りまたは書き込みのために Azure Blob Storage に対して提供されたパブリック URI または SAS URI に、エラーが含まれます。
SAS の時間枠の期限が切れています。
HTTP ソースによる Web URL が、ファイルまたはループバック URI を表しています。
HTTP による Web URL に、正しくない形式の URL が含まれています。
URL はリモート ソースで解決できません。
解決策: コンポーネントを見直し、URI の形式を検証します。 データ ソースが HTTP 経由の Web URL である場合は、目的のソースがファイルまたはループバック URI (localhost) ではないことを確認します。
| 例外メッセージ |
|---|
| Invalid Uri is passed. (無効な URI が渡されました。) |
| The Uri "{invalid_url}" is invalid. (URI "{invalid_url}" が無効です。) |
エラー 0030
例外は、ファイルをダウンロードできない場合に発生します。
Azure Machine Learning でのこの例外は、ファイルをダウンロードできない場合に発生します。 この例外は、3 回の再試行の後に HTTP ソースからの読み取りが失敗した場合に受け取ります。
解決策: HTTP ソースに対する URI が正しいこと、および現在インターネット経由でサイトにアクセスできることを確認します。
| 例外メッセージ |
|---|
| Unable to download a file. (ファイルをダウンロードできません。) |
| Error while downloading the file: {file_url} (ファイルのダウンロード中にエラーが発生しました: {file_url}。) |
エラー 0031
列セット内の列の数が必要とされるより少ない場合、例外が発生します。
Azure Machine Learning では、選択された列の数が必要とされるより少ない場合、このエラーが発生します。 必要最小限の列数が選択されていない場合、このエラーが表示されます。
解決策:列セレクターを使って、列の選択に列を追加します。
| 例外メッセージ |
|---|
| Number of columns in column set is less than required. (列セット内の列の数が必要な数に達していません。) |
| At least {required_columns_count} column(s) should be specified for input argument "{arg_name}". (入力引数 "{arg_name}" には、少なくとも {required_columns_count} 個の列を指定する必要があります。) |
| At least {required_columns_count} column(s) should be specified for input argument "{arg_name}". (入力引数 "{arg_name}" には、少なくとも {required_columns_count} 個の列を指定する必要があります。) The actual number of specified columns is {input_columns_count}. (実際に指定された列の数は {input_columns_count} です。) |
エラー 0032
引数が数値でない場合、例外が発生します。
引数が double または NaN の場合、Azure Machine Learning でこのエラーが発生します。
解決策: 有効な値を使うように、指定された引数を修正します。
| 例外メッセージ |
|---|
| Argument is not a number. (引数が数値ではありません。) |
| "{arg_name}" is not a number. ("{arg_name}" が数値ではありません。) |
エラー 0033
引数が無限である場合、例外が発生します。
Azure Machine Learning では、引数が無限である場合、このエラーが発生します。 引数が double.NegativeInfinity または double.PositiveInfinityの場合、このエラーが発生します。
解決策: 有効な値になるように、指定された引数を修正します。
| 例外メッセージ |
|---|
| Argument must be finite. (引数は有限である必要があります。) |
| "{arg_name}" is not finite. ("{arg_name}" が有限ではありません。) |
| Column "{column_name}" contains infinite values. (列 "{column_name}" に無限の値が含まれています。) |
エラー 0034
特定のユーザーと項目のペアに対して複数の評価が存在する場合、例外が発生します。
Azure Machine Learning では、ユーザーと項目のペアに複数の評価値がある場合、推奨でこのエラーが発生します。
解決策: ユーザーと項目のペアで評価値が 1 つのみ所有されていることを確認します。
| 例外メッセージ |
|---|
| More than one rating exists for the value(s) in dataset. (データセット内の値に対して複数の評価が存在します。) |
| More than one rating for user {user} and item {item} in rating prediction data table. (評価予測データ テーブルに、ユーザー {user} と項目 {item} に対する複数の評価があります。) |
| More than one rating for user {user} and item {item} in {dataset}. ({dataset} に、ユーザー {user} と項目 {item} に対する複数の評価があります。) |
エラー 0035
特定のユーザーまたは項目に対して特徴が提供されなかった場合、例外が発生します。
Azure Machine Learning でこのエラーが発生すると、スコア付けに推奨モデルを使用しようとしていますが、特徴ベクトルが見つかりません。
解決策:
マッチボックス レコメンダーには、項目の特徴またはユーザーの特徴のいずれかを使うときに満たす必要がある特定の要件があります。 このエラーは、入力として指定したユーザーまたは項目に特徴ベクターがないことを示します。 各ユーザーまたは項目のデータで特徴ベクターが使用できることを確認します。
たとえば、ユーザーの年齢、場所、収入などの機能を使用してレコメンデーション モデルをトレーニングしたが、トレーニング中に表示されなかった新しいユーザーのスコアを作成する場合は、新しいユーザーに対して適切な予測を行うために、新しいユーザーに同等の機能セット (年齢、場所、収入の値) を提供する必要があります。
これらのユーザーの機能がない場合は、特徴エンジニアリングを検討して適切な特徴を生成します。 たとえば、個々のユーザーの年齢や収入の値がない場合は、ユーザーのグループに使用する概算値を生成できます。
ヒント
解決策が自分のケースに該当しませんか。 この記事のフィードバックを送信し、コンポーネントや列の行数など、シナリオについての情報を提供してください。 この情報を使用して、今後さらに詳細なトラブルシューティング手順を提供します。
| 例外メッセージ |
|---|
| No features were provided for a required user or item. (必要なユーザーまたは項目に特徴が提供されませんでした。) |
| Features for {required_feature_name} required but not provided. ({Required_feature_name} に特徴が必須ですが、指定されていません。) |
エラー 0036
特定のユーザーまたは項目に対して複数の特徴ベクターが提供された場合、例外が発生します。
Azure Machine Learning では、特徴ベクターが複数回定義された場合、このエラーが発生します。
解決策: 特徴ベクトルが複数回定義されていないことを確認します。
| 例外メッセージ |
|---|
| Duplicate feature definition for a user or item. (ユーザーまたは項目に対する特徴の定義が重複しています。) |
エラー 0037
複数のラベル列が指定されているときに、ラベル列が 1 つのみ許可される場合、例外が発生します。
Azure Machine Learning では、新しいラベル列として複数の列が選択された場合、このエラーが発生します。 ほとんどの教師あり学習アルゴリズムでは、1 つの列がターゲットまたはラベルとしてマークされている必要があります。
解決策: 新しいラベル列として 1 つの列を選択します。
| 例外メッセージ |
|---|
| Multiple label columns are specified. (複数のラベル列が指定されています。) |
| Multiple label columns are specified in "{dataset_name}". ("{dataset_name}" に複数のラベル列が指定されています。) |
エラー 0039
操作が失敗した場合、例外が発生します。
Azure Machine Learning でのこのエラーは、内部操作を完了できない場合に発生します。
解決策: このエラーは多くの条件によって発生し、特定の解決策はありません。
次の表はこのエラーに対する一般的なメッセージであり、後で状況について具体的に説明します。
使用可能な詳細情報がない場合は、Microsoft Q&A 質問ページでフィードバックを送信して、エラーが発生したコンポーネントおよび関連する状況に関する情報を提供してください。
| 例外メッセージ |
|---|
| 操作に失敗しました。 |
| Error while completing operation: "{failed_operation}". (操作 "{failed_operation}" の完了中にエラーが発生しました。) |
| Error while completing operation: "{failed_operation}". (操作 "{failed_operation}" の完了中にエラーが発生しました。) Reason: "{reason}". (理由: "{reason}"。) |
エラー 0042
例外は、列を別の型に変換できない場合に発生します。
Azure Machine Learning のこのエラーは、列を指定した型に変換できない場合に発生します。 コンポーネントが特定のデータ型 (datetime、text、浮動小数点数、整数など) を必要とするが、既存の列を必要な型に変換できない場合、このエラーが発生します。
たとえば、列を選択し、算術演算で使用するために数値データ型に変換しようとした場合、列に無効なデータが含まれていると、このエラーが発生する可能性があります。
このエラーが発生する可能性のあるもう 1 つの理由としては、浮動小数点数または多くの一意の値が含まれる列をカテゴリ列として使おうとする場合です。
解決策:
- エラーが生成されたコンポーネントのヘルプ ページを開き、データ型の要件を確認します。
- 入力データセットで列のデータ型を確認します。
- いわゆるスキーマレス データ ソースで発生するデータを調べます。
- 目的のデータ型への変換を妨げる可能性がある欠損値または特殊文字がないか、データセットを確認します。
- 数値データ型は一貫している必要があります。たとえば、整数の列で浮動小数点数を確認します。
- 数値列でテキスト文字列または NA 値を探します。
- ブール値は、必要なデータ型に応じて、適切な表現に変換できます。
- テキスト列で一等コードでない文字、タブ文字、または制御文字を調べる
- モデリング エラーを回避するには日時データが一貫している必要がありますが、形式が多いためクリーンアップが複雑になることがあります。 クリーンアップ実行のため、Python スクリプトの実行コンポーネントの使用を検討します。
- 必要な場合は、列を正常に変換できるように、入力データセット内の値を修正します。 修正には、ビン分割、切り捨てまたは丸め処理、外れ値の削除、または欠損値の補完などがあります。 機械学習での一般的なデータ変換シナリオについては、次の記事をご覧ください。
ヒント
解決策がわからない、または自分のケースに該当しませんか。 この記事のフィードバックを送信し、コンポーネントや列のデータ型など、シナリオについての情報を提供してください。 この情報を使用して、今後さらに詳細なトラブルシューティング手順を提供します。
| 例外メッセージ |
|---|
| Not allowed conversion. (変換は許可されていません。) |
| Could not convert column of type {type1} to column of type {type2}. (型 {type1} の列を型 {type2} の列に変換できませんでした。) |
| Could not convert column "{col_name1}" of type {type1} to column of type {type2}. (型 {type1} の列 "{col_name1}" を型 {type2} の列に変換できませんでした。) |
| Could not convert column "{col_name1}" of type {type1} to column "{col_name2}" of type {type2}. (型 {type1} の列 "{col_name1}" を型 {type2} の列 "{col_name2}" に変換できませんでした。) |
エラー 0044
既存の値から列の要素型を派生できない場合、例外が発生します。
Azure Machine Learning のこのエラーは、データセット内の列または列の型を推測できない場合に発生します。 これは通常、要素型が異なる複数のデータセットを連結するときに発生します。 Azure Machine Learning で、情報を失うことなく列または列内のすべての値を表すことができる共通の型を特定できない場合、このエラーが生成されます。
解決策: 結合される両方のデータセットの特定の列のすべての値が、同じ型であるか (数値、ブール値、カテゴリ、文字列、日付など)、または同じ型に変換できることを確認します。
| 例外メッセージ |
|---|
| Cannot derive element type of the column. (列の要素型を派生できません。) |
| Cannot derive element type for column "{column_name}" -- all the elements are null references. (列 "{column_name}" の要素型を派生できません -- すべての要素が null 参照です。) |
| Cannot derive element type for column "{column_name}" of dataset "{dataset_name}" -- all the elements are null references. (データセット "{dataset_name}" の列 "{column_name}" の要素型を派生できません -- すべての要素が null 参照です。) |
エラー 0045
ソース内の要素型が混在しているために列を作成できない場合、例外が発生します。
Azure Machine Learning では、結合される 2 つのデータセットの要素型が異なる場合、このエラーが生成されます。
解決策: 結合される両方のデータセットの特定の列のすべての値が、同じ型 (数値、ブール値、カテゴリ、文字列、日付など) であることを確認します。
| 例外メッセージ |
|---|
| Cannot create column with mixed element types. (混合要素型の列は作成できません。) |
| Cannot create column with id "{column_id}" of mixed element types: (混合要素型の ID "{column_id}" の列を作成できません:) Type of data[{row_1}, {column_id}] is "{type_1}". (data[{row_1}、{column_id}] の型は "{type_1}" です。) Type of data[{row_2}, {column_id}] is "{type_2}". (data[{row_2}、{column_id}] の型は "{type_2}" です。) |
| Cannot create column with id "{column_id}" of mixed element types: (混合要素型の ID "{column_id}" の列を作成できません:) Type in chunk {chunk_id_1} is "{type_1}". (チャンク {chunk_id_1} の型は "{type_1}" です。) Type in chunk {chunk_id_2} is "{type_2}" with chunk size: {chunk_size}. (chunk {chunk_id_2} の型は chunk size: {chunk_size} の "{type_2}" です。) |
エラー 0046
指定したパスにディレクトリを作成できない場合、例外が発生します。
Azure Machine Learning でこのエラーが発生するのは、指定したパスにディレクトリを作成できない場合です。 Hive クエリの出力ディレクトリへのパスの一部が正しくないか、アクセスできない場合、このエラーが発生します。
解決策: コンポーネントを見直し、ディレクトリ パスが正しく書式設定されていること、および現在の資格情報でアクセス可能であることを確認します。
| 例外メッセージ |
|---|
| Please specify a valid output directory. (有効な出力ディレクトリを指定してください。) |
| Directory: {path} cannot be created. (ディレクトリ: {path} を作成できません。) Please specify valid path. (有効なパスを指定してください。) |
エラー 0047
コンポーネントに渡された一部のデータセットの特徴列の数が少なすぎる場合、例外が発生します。
Azure Machine Learning でこのエラーが発生するのは、トレーニング用の入力データセットに、アルゴリズムに必要な列の最小数が含まれていない場合です。 通常、データセットが空か、トレーニング列のみが含まれています。
解決策: 入力データセットを見直し、ラベル列とは別に 1 つ以上の列があることを確認します。
| 例外メッセージ |
|---|
| Number of feature columns in input dataset is less than allowed minimum. (入力データセット内の特徴列の数が許容される最少数未満です。) |
| Number of feature columns in input dataset is less than allowed minimum of {required_columns_count} column(s). (入力データセット内の特徴列の数が、許容される最小数の {required_columns_count} 列未満です。) |
| Number of feature columns in input dataset "{arg_name}" is less than allowed minimum of {required_columns_count} column(s). (入力データセット "{arg_name}" 内の特徴列の数が、許容される最小数の {required_columns_count} 列未満です。) |
エラー 0048
例外は、ファイルを開くことができない場合に発生します。
Azure Machine Learning のこのエラーは、読み取りまたは書き込みのためにファイルを開くことができない場合に発生します。 このエラーは、次の理由で発生する可能性があります。
コンテナーまたはファイル (BLOB) が存在しない
ファイルまたはコンテナーのアクセス レベルでは、ファイルにアクセスできません
ファイルが大きすぎて読み取ることができないか、または形式が正しくない
解決策: 読み取ろうとしているコンポーネントとファイルを見直します。
コンテナーとファイルの名前が正しいことを確認します。
クラシック Azure portal または Azure ストレージ ツールを使って、ファイルにアクセスするためのアクセス許可があることを確認します。
| 例外メッセージ |
|---|
| Unable to open a file. (ファイルを開くことができません。) |
| Error while opening the file: {file_name}. (ファイルを開くときにエラーが発生しました: {file_name}。) |
| Error while opening the file: {file_name}. (ファイルを開くときにエラーが発生しました: {file_name}。) Storage exception message: {exception}. (ストレージの例外メッセージ: {exception}。) |
エラー 0049
例外は、ファイルを解析できない場合に発生します。
Azure Machine Learning でのこのエラーは、ファイルを解析できない場合に発生します。 このエラーは、 Import Data コンポーネントで選択したファイル形式がファイルの実際の形式と一致しない場合、またはファイルに認識できない文字が含まれている場合に発生します。
解決策: コンポーネントを見直し、ファイルの形式と一致しない場合は、ファイル形式の選択を修正します。 可能であれば、ファイルを調べて、無効な文字が含まれていないことを確認します。
| 例外メッセージ |
|---|
| Unable to parse a file. (ファイルを解析できません。) |
| Error while parsing the {file_format} file. ({file_format} ファイルの解析中にエラーが発生しました。) |
| Error while parsing the {file_format} file: {file_name}. ({file_format} ファイルの解析中にエラーが発生しました: {file_name}。) |
| Error while parsing the {file_format} file. ({file_format} ファイルの解析中にエラーが発生しました。) Reason: {failure_reason}. (理由: {failure_reason}。) |
| Error while parsing the {file_format} file: {file_name}. ({file_format} ファイルの解析中にエラーが発生しました: {file_name}。) Reason: {failure_reason}. (理由: {failure_reason}。) |
エラー 0052
正しくない Azure ストレージ アカウント キーが指定された場合、例外が発生します。
Azure Machine Learning では、Azure ストレージ アカウントへのアクセスに使用するキーが正しくない場合、このエラーが発生します。 たとえば、コピーして貼り付けるときに Azure ストレージ キーが切り捨てられた場合、または間違ったキーを使用した場合、このエラーが表示される可能性があります。
Azure ストレージ アカウントのキーの取得方法について詳しくは、ストレージ アクセス キーの表示、コピー、再生成に関する記事をご覧ください。
解決策: コンポーネントを見直し、Azure ストレージ キーがアカウントに対して正しいことを確認します。必要な場合は、クラシック Azure portal からキーをもう一度コピーします。
| 例外メッセージ |
|---|
| The Azure storage account key is incorrect. (Azure ストレージ アカウント キーが正しくありません。) |
エラー 0053
マッチボックスの推奨に対するユーザーの特徴や項目がない場合、例外が発生します。
Azure Machine Learning でのこのエラーは、特徴ベクトルが見つからない場合に生成されます。
解決策: 入力データセットに特徴ベクターが存在することを確認します。
| 例外メッセージ |
|---|
| User features or/and items are required but not provided. (ユーザーの特徴や項目が必要ですが提供されていません。) |
エラー 0056
操作に対して選択した列が要件に違反している場合、例外が発生します。
Azure Machine Learning でこのエラーは、列が特定のデータ型である必要がある操作の列を選択するときに発生します。
このエラーは、列が正しいデータ型である場合にも発生する可能性がありますが、使用しているコンポーネントでは、列も特徴、ラベル、またはカテゴリ列としてマークされている必要があります。
解決策:
現在選択されている列のデータ型を見直します。
選択した列がカテゴリ列、ラベル列、または特徴列かどうかを確認します。
列を選択したコンポーネントのヘルプ トピックを調べて、データ型または列の使用方法について特定の要件があるかどうかを確認します。
メタデータの編集を使って、この操作を行っている間、列の型を変更します。 ダウンストリームの操作で列が必要な場合は、メタデータの編集の別のインスタンスを使って、忘れずに列の型を元の値に戻します。
| 例外メッセージ |
|---|
| One or more selected columns were not in an allowed category. (選択した列の 1 つ以上が、許可されたカテゴリに含まれませんでした。) |
| Column with name "{col_name}" is not in an allowed category. ("{col_name}" という名前の列は、許可されたカテゴリに含まれていません。) |
エラー 0057
既に存在しているファイルまたは BLOB を作成しようとすると、例外が発生します。
この例外は、 Export Data コンポーネントまたはその他のコンポーネントを使用して Azure Machine Learning のパイプラインの結果を Azure BLOB ストレージに保存しているが、既に存在するファイルまたは BLOB を作成しようとすると発生します。
解決策:
このエラーは、以前にプロパティ Azure BLOB ストレージ書き込みモード を Error に設定した場合にのみ発生します。 仕様により、このコンポーネントでは既に存在する BLOB にデータセットを書き込もうとするとエラーが発生します。
- コンポーネントのプロパティを開き、 [Azure blob storage write mode](Azure Blob Storage 書き込みモード) プロパティを [上書き] に変更します。
- または、別の宛先 BLOB またはファイルの名前を入力し、まだ存在しない BLOB を必ず指定することもできます。
| 例外メッセージ |
|---|
| File or Blob already exists. (ファイルまたは BLOB は既に存在しています。) |
| File or Blob "{file_path}" already exists. (ファイルまたは BLOB "{file_path}" は既に存在しています。) |
エラー 0058
Azure Machine Learning のこのエラーは、データセットに予期されるラベル列が含まれていない場合に発生します。
この例外は、指定されたラベル列が学習者が期待するデータまたはデータ型と一致しない場合や、値が間違っている場合にも発生する可能性があります。 たとえば、バイナリ分類器をトレーニングするときに、実数値のラベル列を使うと、この例外が生成されます。
解決策: 解決策は、使用している学習者またはトレーナーと、データセット内の列のデータ型によって異なります。 最初に、機械学習アルゴリズムまたはトレーニング コンポーネントの要件を確認します。
入力データセットを見直します。 ラベルとして扱われる列に、作成するモデルに適したデータ型があることを確認します。
欠損値がないか入力を確認し、必要に応じてそれらを除去または置換します。
必要な場合は、メタデータの編集コンポーネントを追加し、ラベル列をラベルとして確実にマークします。
| 例外メッセージ |
|---|
| The label column values and scored label column values are not comparable. (ラベル列の値とスコアリングされたラベル列の値は比較できません。) |
| The label column is not as expected in "{dataset_name}". (ラベル列が "{dataset_name}" で予期されているものではありません。) |
| The label column is not as expected in "{dataset_name}", {reason}. (ラベル列が "{dataset_name}" で予期されているものではありません。{reason}。) |
| The label column "{column_name}" is not expected in "{dataset_name}". (ラベル列 "{column_name}" は "{dataset_name}" で予期されていません。) |
| The label column "{column_name}" is not expected in "{dataset_name}", {reason}. (ラベル列 "{column_name}" は "{dataset_name}" で予期されていません。{reason}。) |
エラー 0059
列ピッカーで指定された列インデックスを解析できない場合、例外が発生します。
Azure Machine Learning でこのエラーが発生するのは、列セレクターを使用するときに指定された列インデックスを解析できない場合です。 このエラーは、列インデックスが解析できない無効な形式である場合に発生します。
解決策: 有効なインデックス値を使うように、列インデックスを修正します。
| 例外メッセージ |
|---|
| One or more specified column indexes or index ranges could not be parsed. (指定された 1 つまたは複数の列インデックスまたはインデックス範囲を解析できませんでした。) |
| Column index or range "{column_index_or_range}" could not be parsed. (列のインデックスまたは範囲 "{column_index_or_range}" を解析できませんでした。) |
エラー 0060
列ピッカーで範囲外の列範囲を指定すると、例外が発生します。
Azure Machine Learning では、列セレクターで範囲外の列範囲を指定する場合、このエラーが発生します。 列ピッカーの列範囲がデータセット内の列に対応していない場合、このエラーが発生します。
解決策: データセット内の列に対応するように、列ピッカーで列範囲を修正します。
| 例外メッセージ |
|---|
| Invalid or out of range column index range specified. (無効または範囲外の列インデックス範囲が指定されました。) |
| Column range "{column_range}" is invalid or out of range. (列範囲 "{column_range}" が無効または範囲外です。) |
エラー 0061
列の数がテーブルとは異なる DataTable に行を追加しようとすると、例外が発生します。
Azure Machine Learning では、あるデータセットとは列の数が異なるデータセットに行を追加しようとする場合、このエラーが発生します。 このエラーは、データセットに追加される行の列数が入力データセットとは異なる場合に発生します。 列数が異なる場合、データセットに行を追加することはできません。
解決策: 追加される行と同じ列数になるように入力データセットを修正するか、またはデータセットと同じ列数になるように追加される行を修正します。
| 例外メッセージ |
|---|
| All tables must have the same number of columns. (すべてのテーブルは同じ列数である必要があります。) |
| Columns in chunk "{chunk_id_1}" is different with chunk "{chunk_id_2}" with chunk size: {chunk_size}. (チャンク "{chunk_id_1}" の列は、チャンク サイズ {chunk_size} のチャンク "{chunk_id_2}" と異なります。) |
| Column count in file "{filename_1}" (count={column_count_1}) is different with file "{filename_2}" (count={column_count_2}). (ファイル "{filename_1}" (count={column_count_1}) の列数が、ファイル "{filename_2}" (count={column_count_2}) と異なります。) |
エラー 0062
学習器の種類が異なる 2 つのモデルを比較しようとすると、例外が発生します。
Azure Machine Learning でのこのエラーは、2 つの異なるスコア付けされたデータセットの評価メトリックを比較できない場合に生成されます。 この場合、スコア付けされた 2 つのデータセットの生成に使用されるモデルの有効性を比較することはできません。
解決策: スコアリングの結果が、同じ種類の機械学習モデル (バイナリ分類、回帰、多クラス分類、推奨、クラスタリング、異常検出など) によって生成されていることを確認します。比較するモデルはすべて、学習器の種類が同じである必要があります。
| 例外メッセージ |
|---|
| All models must have the same learner type. (すべてのモデルは学習器の種類が同じでなければなりません。) |
| Got incompatible learner type: "{actual_learner_type}". (互換性のない学習器の種類 "{actual_learner_type}" を取得しました。) Expected learner types are: "{expected_learner_type_list}". (予期されている学習器の種類は "{expected_learner_type_list}" です。) |
エラー 0064
正しくない Azure ストレージ アカウント名またはストレージ キーが指定された場合、例外が発生します。
Azure Machine Learning では、Azure ストレージ アカウントの名前またはストレージ キーが誤って指定された場合、このエラーが発生します。 ストレージ アカウントのアカウント名またはパスワードが正しくない場合、このエラーが表示されます。 これは、アカウント名またはパスワードを手入力したときに発生する可能性があります。 アカウントが削除された場合にも発生する可能性があります。
解決策: アカウント名とパスワードを正しく入力したこと、およびアカウントが存在することを確認します。
| 例外メッセージ |
|---|
| The Azure storage account name or storage key is incorrect. (Azure ストレージ アカウント名またはストレージ キーが正しくありません。) |
| The Azure storage account name "{account_name}" or storage key for the account name is incorrect. (Azure ストレージ アカウント名 "{account_name}" またはアカウント名のストレージ キーが正しくありません。) |
エラー 0065
正しくない Azure BLOB 名が指定された場合、例外が発生します。
Azure Machine Learning では、Azure BLOB 名が誤って指定された場合、このエラーが発生します。 次の場合にエラーが表示されます。
- 指定したコンテナーに BLOB が見つかりません。
形式がエンコードされた Excel または CSV の場合、 Import Data 要求のソースとしてコンテナーのみが指定されました。コンテナー内のすべての BLOB の内容を連結することは、これらの形式では許可されません。
SAS URI には、有効な BLOB の名前が含まれません。
解決策: 例外をスローするコンポーネントを見直します。 指定された BLOB がストレージ アカウントのコンテナーに存在していること、および BLOB を表示できるアクセス許可があることを確認します。 エンコード形式の Excel または CSV を使用している場合、入力が "コンテナー名/ファイル名" の形式であることを確認します。 SAS URI に有効な BLOB の名前が含まれていることを確認します。
| 例外メッセージ |
|---|
| The Azure storage blob name is incorrect. (Azure Storage の BLOB 名が正しくありません。) |
| The Azure storage blob name "{blob_name}" is incorrect. (Azure Storage の BLOB 名 "{blob_name}" が正しくありません。) |
| The Azure storage blob name with prefix "{blob_name_prefix}" does not exist. (プレフィックス "{blob_name_prefix}" を持つ、Azure Storage の BLOB 名は存在しません。) |
| Failed to find any Azure storage blobs under container "{container_name}". (コンテナー "{container_name}" で、Azure Storage の BLOB を検出できませんでした。) |
| Failed to find any Azure storage blobs with wildcard path "{blob_wildcard_path}". (ワイルドカードパス "{blob_wildcard_path}" を持つ、Azure Storage の BLOB を検出できませんでした。) |
エラー 0066
リソースを Azure BLOB にアップロードできなかった場合、例外が発生します。
Azure Machine Learning でのこのエラーは、リソースを Azure BLOB にアップロードできなかった場合に発生します。 どちらも、入力ファイルを含むアカウントと同じ Azure ストレージ アカウントに保存されます。
解決策: コンポーネントを見直します。 Azure アカウント名、ストレージ キー、コンテナーが正しいこと、およびアカウントにコンテナーへの書き込みアクセス許可があることを確認します。
| 例外メッセージ |
|---|
| The resource could not be uploaded to Azure storage. (リソースを Azure Storage にアップロードできませんでした。) |
| The file "{source_path}" could not be uploaded to Azure storage as "{dest_path}". (ファイル "{source_path}" を Azure Storage に "{dest_path}" としてアップロードできませんでした。) |
エラー 0067
データセットの列数が予想とは異なる場合、例外が発生します。
Azure Machine Learning では、データセットの列数が予想とは異なる場合、このエラーが発生します。 このエラーは、データセット内の列の数が、実行中にコンポーネントが予期する列の数と異なる場合に発生します。
解決策: 入力データセットまたはパラメーターを修正します。
| 例外メッセージ |
|---|
| Unexpected number of columns in the datatable. (データ テーブル内の列数が予想と異なります。) |
| Unexpected number of columns in the dataset "{dataset_name}". (データセット "{dataset_name}" に予期しない数の列があります。) |
| Expected "{expected_column_count}" column(s) but found "{actual_column_count}" column(s) instead. ("{expected_column_count}" 列が予期されていますが、代わりに "{actual_column_count}" 列が見つかりました。) |
| In input dataset "{dataset_name}", expected "{expected_column_count}" column(s) but found "{actual_column_count}" column(s) instead. (入力データセット "{dataset_name}" では、"{expected_column_count}" 列が予期されていますが、代わりに "{actual_column_count}" 列が見つかりました。) |
エラー 0068
指定した Hive スクリプトが正しくない場合、例外が発生します。
Azure Machine Learning では、Hive QL スクリプトに構文エラーがある場合、またはクエリやスクリプトの実行中に Hive インタープリターでエラーが発生した場合、このエラーが発生します。
解決策:
通常 Hive からのエラー メッセージがエラー ログで報告されるので、特定のエラーに基づいてアクションを実行できます。
- コンポーネントを開き、クエリで誤りを調べます。
- Hadoop クラスターの Hive コンソールにログインしてクエリを実行することにより、Azure Machine Learning の外部でクエリが正しく動作することを確認します。
- Hive スクリプトで実行可能なステートメントとコメントを単一の行に混在させるのではなく、コメントを別の行に配置することを試みます。
リソース
機械学習での Hive クエリの使用については、次の記事をご覧ください。
- Hive テーブルを作成して Azure Blob Storage からデータを読み込む
- Hive クエリを使用してテーブルのデータを探索する
- Hive クエリを使用して Hadoop クラスターのデータの特徴を作成する
- SQL ユーザー向け Hive のチート シート (PDF)
| 例外メッセージ |
|---|
| Hive script is incorrect. (Hive スクリプトが正しくありません。) |
エラー 0069
指定した SQL スクリプトが正しくない場合、例外が発生します。
Azure Machine Learning のこのエラーは、指定された SQL スクリプトに構文の問題がある場合、またはスクリプトで指定された列またはテーブルが無効な場合に発生します。
このエラーは、クエリまたはスクリプトの実行中に SQL エンジンでエラーが発生した場合に発生します。 通常 SQL のエラー メッセージがエラー ログで報告されるので、特定のエラーに基づいてアクションを実行できます。
解決策: コンポーネントを見直し、SQL クエリで誤りを調べます。
データベース サーバーに直接ログインしてクエリを実行することにより、Azure Machine Learning の外部でクエリが正しく動作することを確認します。
コンポーネント例外によって報告された SQL 生成メッセージがある場合は、報告されたエラーに基づいてアクションを実行します。 たとえば、エラー メッセージには、発生する可能性の高いエラーに関する具体的なガイダンスが含まれる場合があります。
- "No such column or missing database" (そのような列はないか、またはデータベースが存在しません) は、列名を誤って入力した可能性があることを示します。 列名が正しい場合は、角かっこまたは引用符を使用して列識別子を囲んでみます。
- "SQL logic error near <SQL keyword> " ("
の近くに SQL ロジック エラーがあります") は、指定されたキーワードの前に構文エラーが存在する可能性があることを示します
| 例外メッセージ |
|---|
| SQL script is incorrect. (SQL スクリプトが正しくありません。) |
| SQL query "{sql_query}" is not correct. (SQL クエリ "{sql_query}" が正しくありません。) |
| SQL query "{sql_query}" is not correct. (SQL クエリ "{sql_query}" が正しくありません。) Exception message: {exception}. (例外メッセージ: {exception}。) |
エラー 0070
存在しない Azure テーブルにアクセスしようとすると、例外が発生します。
Azure Machine Learning でこのエラーは、存在しない Azure テーブルにアクセスしようとすると発生します。 Azure Storage でテーブルを指定すると、このエラーが発生します。このテーブルは、Azure Table Storage の読み取りまたは書き込み時には存在しません。 これは、目的のテーブルの名前を誤って入力した場合、またはターゲットの名前とストレージの種類の間に不一致がある場合に発生する可能性があります。 たとえば、テーブルから読み取ろうとして、代わりに BLOB の名前を入力したような場合です。
解決策: コンポーネントを見直して、テーブルの名前が正しいことを確認します。
| 例外メッセージ |
|---|
| Azure table does not exist. (Azure のテーブルが存在しません。) |
| Azure table "{table_name}" does not exist. (Azure のテーブル "{table_name}" が存在しません。) |
エラー 0072
接続がタイムアウトした場合、例外が発生します。
Azure Machine Learning でのこのエラーは、接続がタイムアウトしたときに発生します。このエラーは、低速なインターネット接続など、データ ソースまたは宛先に現在接続の問題がある場合、またはデータセットが大きい場合や、データを読み取る SQL クエリが複雑な処理を実行している場合に発生します。
解決策: 現在、Azure ストレージまたはインターネットへの接続が遅くなる問題が発生しているかどうかを特定します。
| 例外メッセージ |
|---|
| Connection timeout occurred. (接続のタイムアウトが発生しました。) |
エラー 0073
列を別の型に変換しているときにエラーが発生した場合、例外が発生します。
Azure Machine Learning のこのエラーは、列を別の型に変換できない場合に発生します。 コンポーネントが特定の型を必要とし、列を新しい型に変換できない場合、このエラーが発生します。
解決策: 入力データセットを修正し、内部例外に基づいて列を変換できるようにします。
| 例外メッセージ |
|---|
| Failed to convert column. (列を変換できませんでした。) |
| Failed to convert column to {target_type}. (列を {target_type} に変換できませんでした。) |
エラー 0075
データセットを量子化するときに無効なビン分割機能を使用すると、例外が発生します。
Azure Machine Learning でこのエラーが発生するのは、サポートされていない方法を使用してデータをビン分割しようとしている場合、またはパラメーターの組み合わせが無効な場合です。
解決策:
このイベントでのエラー処理は、ビン分割方法のカスタマイズがより広い範囲で可能だった以前のバージョンの Azure Machine Learning で導入されました。 現在は、ビン分割方法はすべてドロップダウン リストでの選択に基づくため、技術的には、このエラーが発生する可能性はありません。
| 例外メッセージ |
|---|
| Invalid binning function used. (無効なビン分割機能が使われました。) |
エラー 0077
不明な BLOB ファイル書き込みモードが渡されると、例外が発生します。
Azure Machine Learning では、BLOB ファイルのターゲットまたはソースを指定するときに無効な引数が渡される場合、このエラーが発生します。
解決策: Azure BLOB ストレージとの間でデータをインポートまたはエクスポートするほぼすべてのコンポーネントでは、書き込みモードを制御するパラメーター値がドロップダウン リストを使用して割り当てられます。そのため、無効な値を渡すことはできません。このエラーは表示されません。 このエラーは、今後のリリースでは非推奨とされます。
| 例外メッセージ |
|---|
| Unsupported blob write mode. (サポートされていない BLOB 書き込みモードです。) |
| Unsupported blob write mode: {blob_write_mode}. (サポートされていない BLOB 書き込みモードです: {blob_write_mode}。) |
エラー 0078
データのインポートに対する HTTP オプションでリダイレクトを示す 3xx 状態コードを受け取ると、例外が発生します。
Azure Machine Learning では、データのインポートに対する HTTP オプションでリダイレクトを示す 3xx (301、302、304 など) 状態コードを受け取る場合、このエラーが発生します。 ブラウザーを別のページにリダイレクトする HTTP ソースに接続しようとすると、このエラーが表示されます。 セキュリティ上の理由から、Web サイトのリダイレクトは Azure Machine Learning のデータ ソースとして許可されません。
解決策: Web サイトが信頼できる Web サイトの場合は、リダイレクト先の URL を直接入力します。
| 例外メッセージ |
|---|
| Http redirection not allowed. (HTTP のリダイレクトは許可されません。) |
エラー 0079
正しくない Azure ストレージ コンテナー名が指定されると、例外が発生します。
Azure Machine Learning では、Azure ストレージ コンテナー名が誤って指定される場合、このエラーが発生します。 このエラーは、Azure Blob Storage に書き込むときに コンテナーで始まる BLOB へのパス オプションを使用して、コンテナーと BLOB (ファイル) 名の両方を指定していない場合に発生します。
解決策:データのエクスポートコンポーネントを見直し、BLOB へのパスの指定に、コンテナーとファイル名の両方がコンテナー/ファイル名の形式で含まれていることを確認します。
| 例外メッセージ |
|---|
| The Azure storage container name is incorrect. (Azure ストレージ コンテナーの名前が正しくありません。) |
| The Azure storage container name "{container_name}" is incorrect; a container name of the format container/blob was expected. (Azure ストレージ コンテナー名 "{container_name}" が正しくありません。コンテナー名は、コンテナー/BLOB 形式であると予想されていました。) |
エラー 0080
すべての値が欠落している列がコンポーネントで許可されていない場合、例外が発生します。
Azure Machine Learning では、コンポーネントによって使用される 1 つまたは複数の列に欠損値しか含まれていないと、このエラーが生成されます。 たとえば、コンポーネントが各列の集計統計を計算している場合、データを含まない列では操作できません。 そのような場合、コンポーネントの実行はこの例外で停止します。
解決策: 入力データセットを見直し、欠損値しか含まれていない列を削除します。
| 例外メッセージ |
|---|
| Columns with all values missing are not allowed. (すべて欠損値の列は許可されません。) |
| Column {col_index_or_name} has all values missing. (列 {col_index_or_name} では、すべての値が欠落しています。) |
エラー 0081
削減後のディメンションの数が、少なくとも 1 つのスパース特徴列を含む入力データセットの特徴列の数と等しい場合、PCA コンポーネントで例外が発生します。
Azure Machine Learning では、次の条件が満たされる場合、このエラーが生成されます。(a) 入力データセットに少なくとも 1 つのスパース列があり、かつ、(b) 要求されたディメンションの最終的な数が入力ディメンションの数と同じである。
解決策: 出力のディメンションの数を、入力のディメンションの数より少なくなるように減らすことを検討します。 これは、PCA のアプリケーションで一般的です。
| 例外メッセージ |
|---|
| For dataset containing sparse feature columns number of dimensions to reduce to should be less than number of feature columns. (スパース特徴列を含むデータセットでは、削減後のディメンションの数を特徴列の数より少なくする必要があります。) |
エラー 0082
例外は、モデルを正常に逆シリアル化できない場合に発生します。
Azure Machine Learning でのこのエラーは、破壊的変更の結果として、保存された機械学習モデルまたは変換を新しいバージョンの Azure Machine Learning ランタイムで読み込めなかった場合に発生します。
解決策: モデルまたは変換を生成したトレーニング パイプラインを再度実行して、モデルまたは変換を保存し直す必要があります。
| 例外メッセージ |
|---|
| Model could not be deserialized because it is likely serialized with an older serialization format. (古いシリアル化形式でシリアル化された可能性があるため、モデルを逆シリアル化できませんでした。) Retrain and resave the model. (モデルを再トレーニングして再度保存してください。) |
エラー 0083
トレーニングに使用されるデータセットを具象学習器に使用できない場合、例外が発生します。
Azure Machine Learning では、データセットとトレーニング中の学習器の間に互換性がないと、このエラーが生成されます。 たとえば、データセットの各行に少なくとも 1 つの欠損値が含まれ、結果として、トレーニング中にデータセット全体がスキップされる可能性があります。 また、異常検出などの一部の機械学習アルゴリズムでは、ラベルが存在することを想定せず、データセットにラベルが存在する場合は、この例外をスローする可能性があります。
解決策: 入力データセットの要件を確認するために使用されている学習器のドキュメントを参照します。 列を調べて、必要な列がすべて存在することを確認します。
| 例外メッセージ |
|---|
| Dataset used for training is invalid. (トレーニングに使用されているデータセットが無効です。) |
| {data_name} contains invalid data for training. ({data_name} には、トレーニング用の無効なデータが含まれます。) |
| {data_name} contains invalid data for training. ({data_name} には、トレーニング用の無効なデータが含まれます。) Learner type: {learner_type}. (学習器の種類: {learner_type}。) |
| {data_name} contains invalid data for training. ({data_name} には、トレーニング用の無効なデータが含まれます。) Learner type: {learner_type}. (学習器の種類: {learner_type}。) Reason: {reason}. (理由: {reason}。) |
| Failed to apply "{action_name}" action on training data {data_name}. ("{action_name}" アクションをトレーニング データ {data_name} に適用できませんでした。) Reason: {reason}. (理由: {reason}。) |
エラー 0084
R スクリプトから生成されたスコアが評価されると、例外が発生します。 現在、これはサポートされていません。
Azure Machine Learning では、スコアが含まれる R スクリプトからの出力でモデルを評価するためにコンポーネントのいずれかを使用しようとする場合、このエラーが発生します。
解決策:
| 例外メッセージ |
|---|
| Evaluating scores produced by Custom Model is currently unsupported. (カスタム モデルによって生成されたスコアの評価は、現在サポートされていません。) |
エラー 0085
スクリプトの評価がエラーを伴い失敗すると、例外が発生します。
Azure Machine Learning でこのエラーが発生するのは、構文エラーを含むカスタム スクリプトを実行している場合です。
解決策: 外部エディターでコードを確認し、エラーを調べます。
| 例外メッセージ |
|---|
| Error during evaluation of script. (スクリプトの評価中にエラーが発生しました。) |
| The following error occurred during script evaluation, please view the output log for more information: (スクリプトの評価中に次のエラーが発生しました。詳細については、出力ログを参照してください:) ---------- Start of error message from {script_language} interpreter ---------- (---------- {Script_language} インタープリターからのエラー メッセージの開始 ----------) {message} ---------- End of error message from {script_language} interpreter ---------- (---------- {script_language} インタープリターからのエラー メッセージの終わり ----------) |
エラー 0090
Hive テーブルの作成が失敗すると、例外が発生します。
Azure Machine Learning でこのエラーが発生するのは、 Export Data または HDInsight クラスターにデータを保存する別のオプションを使用していて、指定した Hive テーブルを作成できない場合です。
解決策: クラスターに関連付けられている Azure ストレージ アカウント名を確認し、コンポーネントのプロパティで同じアカウントを使用していることを確認します。
| 例外メッセージ |
|---|
| The Hive table could not be created. (Hive テーブルを作成できませんでした。) For a HDInsight cluster, please ensure the Azure storage account name associated with cluster is the same as what is passed in through the component parameter. (HDInsight クラスターでは、クラスターに関連付けられた Azure ストレージ アカウント名が、コンポーネントのパラメーターで渡されたものと同じであることを確認してください。) |
| The Hive table "{table_name}" could not be created. (Hive テーブル "{table_name}" を作成できませんでした。) For a HDInsight cluster, please ensure the Azure storage account name associated with cluster is the same as what is passed in through the component parameter. (HDInsight クラスターでは、クラスターに関連付けられた Azure ストレージ アカウント名が、コンポーネントのパラメーターで渡されたものと同じであることを確認してください。) |
| The Hive table "{table_name}" could not be created. (Hive テーブル "{table_name}" を作成できませんでした。) For a HDInsight cluster, ensure the Azure storage account name associated with cluster is "{cluster_name}". (HDInsight クラスターでは、クラスターに関連付けられた Azure ストレージ アカウント名が "{cluster_name}" であることを確認してください。) |
エラー 0102
ZIP ファイルを抽出できない場合にスローされます。
Azure Machine Learning でこのエラーが発生するのは、.zip拡張子を持つ zip 形式のパッケージをインポートしているが、パッケージが zip ファイルではないか、サポートされている zip 形式を使用していないファイルである場合です。
解決策: 選択したファイルが有効な .zip ファイルであること、およびサポートされている圧縮アルゴリズムのいずれかを使って圧縮されていることを確認します。
圧縮形式のデータセットをインポートするときにこのエラーが発生する場合は、含まれるすべてのファイルが、サポートされているファイル形式のいずれかが使われているものであり、かつ Unicode 形式であることを確認します。
目的のファイルを圧縮された新しい zip フォルダーに読み取り、もう一度カスタム コンポーネントを追加してみてください。
| 例外メッセージ |
|---|
| Given ZIP file is not in the correct format. (指定された ZIP ファイルは正しい形式ではありません。) |
エラー 0105
このエラーは、コンポーネント定義ファイルにサポートされていないパラメーター型が含まれている場合に表示されます。
Azure Machine Learning のこのエラーは、カスタム コンポーネントの xml 定義を作成するときに生成され、定義内のパラメーターまたは引数の型がサポートされている型と一致しません。
解決策: カスタム コンポーネントの xml 定義ファイル内の Arg 要素の型プロパティが、サポートされている型であることを確認します。
| 例外メッセージ |
|---|
| Unsupported parameter type. (パラメーターの型がサポートされていません。) |
| Unsupported parameter type '{0}' specified. (サポートされていないパラメーターの型 '\{0\}' が指定されています。) |
エラー 0107
コンポーネント定義ファイルでサポートされていない出力の種類が定義されている場合にスローされます。
Azure Machine Learning のこのエラーは、カスタム コンポーネント XML 定義の出力ポートの型がサポートされている型と一致しない場合に生成されます。
解決策: カスタム コンポーネントの xml 定義ファイル内の Output 要素の型プロパティが、サポートされている型であることを確認します。
| 例外メッセージ |
|---|
| Unsupported output type. (出力の型がサポートされていません。) |
| Unsupported output type '{output_type}' specified. (サポートされていない出力の型 '{output_type}' が指定されています。) |
エラー 0125
複数のデータセットのスキーマが一致しない場合にスローされます。
解決策:
| 例外メッセージ |
|---|
| Dataset schema does not match. (データセットのスキーマが一致しません。) |
エラー 0127
Image pixel size exceeds allowed limit. (画像のピクセル サイズが許容される上限を超えています。)
このエラーは、分類のために画像データセットから画像を読み取っていて、画像がモデルで処理できるよりも大きい場合に発生します。
| 例外メッセージ |
|---|
| Image pixel size exceeds allowed limit. (画像のピクセル サイズが許容される上限を超えています。) |
| Image pixel size in the file '{file_path}' exceeds allowed limit: '{size_limit}'. (ファイル '{file_path}' 内の画像のピクセル サイズが、許容される上限を超えています: '{size_limit}'。) |
エラー 0128
カテゴリ列の条件付き確率の値が制限を超えています。
解決策:
| 例外メッセージ |
|---|
| カテゴリ列の条件付き確率の値が制限を超えています。 |
| カテゴリ列の条件付き確率の値が制限を超えています。 Columns '{column_name_or_index_1}' and '{column_name_or_index_2}' are the problematic pair. (列 '{column_name_or_index_1}' および '{column_name_or_index_2}' が問題のあるペアです。) |
エラー 0129
データセット内の列の数が、許可される上限を超えています。
解決策:
| 例外メッセージ |
|---|
| データセット内の列の数が、許可される上限を超えています。 |
| Number of columns in the dataset in '{dataset_name}' exceeds allowed. ('{dataset_name}' のデータセット内の列数が許容値を超えています。) |
| Number of columns in the dataset in '{dataset_name}' exceeds allowed limit of '{component_name}'. ('{dataset_name}' のデータセット内の列数が、'{component_name}' の許容される上限を超えています。) |
| Number of columns in the dataset in '{dataset_name}' exceeds allowed '{limit_columns_count}' limit of '{component_name}'. ('{dataset_name}' のデータセット内の列数が、'{component_name}' の許容される上限 '{limit_columns_count}' を超えています。) |
エラー 0134
Exception occurs when label column is missing or has insufficient number of labeled rows. (ラベル列が存在しない場合、またはラベルの付いた行の数が不足している場合、例外が発生します。)
このエラーは、コンポーネントがラベル列を必要とするが、列の選択にラベル列を含めなかった場合、またはラベル列に不足している値が多すぎる場合に発生します。
前の操作によってデータセットが変更され、ダウンストリーム操作で使用できる行が不足している場合にも、このエラーが発生する可能性があります。 たとえば、パーティションとサンプル コンポーネントで、式を使って値によるデータセットの分割を行っているとします。 使用した式で一致するものが見つからない場合、パーティションによって得たデータセットの 1 つが空になります。
解決策:
列の選択にラベル列を含めても認識されない場合は、メタデータの編集コンポーネントを使って、それをラベル列としてマークします。
その後、見つからないデータのクリーンアップ コンポーネントを使って、ラベル列に欠損値のある行を削除できます。
入力データセットを調べて、有効なデータが含まれること、および操作の要件を満たすために十分な行があることを確認します。 多くのアルゴリズムでは、データの最小行数が必要な場合にエラー メッセージが生成されますが、データに含まれる行は数行のみ、またはヘッダーのみが含まれます。
| 例外メッセージ |
|---|
| Exception occurs when label column is missing or has insufficient number of labeled rows. (ラベル列が存在しない場合、またはラベルの付いた行の数が不足している場合、例外が発生します。) |
| Exception occurs when label column is missing or has less than {required_rows_count} labeled rows. (ラベル列がないか、ラベルの付いた行 {required_rows_count} より少ない場合、例外が発生します。) |
| Exception occurs when label column in dataset {dataset_name} is missing or has less than {required_rows_count} labeled rows. (データセット {dataset_name} 内にラベル列がないか、ラベルの付いた行 {required_rows_count} より少ない場合、例外が発生します。) |
エラー 0138
Memory has been exhausted, unable to complete running of component. (メモリが不足しており、コンポーネントの実行を完了できません。) データセットのダウンサンプリングは、問題の軽減に役立つことがあります。
実行中のコンポーネントに、Azure コンテナーで使用できるより多くのメモリが必要な場合、このエラーが発生します。 これは、大規模なデータセットを操作していて、現在の操作がメモリに収まらない場合に発生する可能性があります。
解決策: 大規模なデータセットを読み取ろうとしていて、操作を完了できない場合は、データセットのダウンサンプリングが役立つ可能性があります。
| 例外メッセージ |
|---|
| Memory has been exhausted, unable to complete running of component. (メモリが不足しており、コンポーネントの実行を完了できません。) |
| Memory has been exhausted, unable to complete running of component. (メモリが不足しており、コンポーネントの実行を完了できません。) Details: {details} (詳細: {details}) |
エラー 0141
選択された数値列の数およびカテゴリ列と文字列列の一意の値の数が少なすぎる場合、例外が発生します。
Azure Machine Learning のこのエラーは、選択した列に操作を実行するのに十分な一意の値がない場合に発生します。
解決策: 一部の操作では、特徴列とカテゴリ列に対して統計演算が実行され、値が不足している場合、操作が失敗したり、無効な結果が返されたりする可能性があります。 データセットを調べて、特徴列とラベル列に含まれる値の数を確認し、実行しようとしている操作が統計的に有効かどうかを判断します。
ソース データセットが有効な場合は、アップストリームのデータ操作やメタデータ操作によってデータが変更されたり値が削除されたりしたかどうかもチェックします。
アップストリームの操作に分割、サンプリング、または再サンプリングが含まれる場合、予想される数の行と値が出力に含まれていることを確認します。
| 例外メッセージ |
|---|
| The number of the selected numerical columns and unique values in the categorical and string columns is too small. (選択された数値列の数およびカテゴリ列と文字列列の一意の値の数が少なすぎます。) |
| The total number of the selected numerical columns and unique values in the categorical and string columns (currently {actual_num}) should be at least {lower_boundary}. (選択された数値列およびカテゴリ列と文字列列の一意の値の総数 (現在 {actual_num}) は、{lower_boundary} 以上である必要があります。) |
エラー 0154
ユーザーが、列の型に互換性がないキー列でデータを結合しようとすると、例外が発生します。
| 例外メッセージ |
|---|
| Key column element types are not compatible. (キー列の要素型に互換性がありません。) |
| Key column element types are not compatible.(left: {keys_left}; right: {keys_right}) (キー列の要素型に互換性がありません。(左: {keys_left}、右: {keys_right})) |
エラー 0155
例外は、データセットの列名が文字列でない場合に発生します。
| 例外メッセージ |
|---|
| データフレーム列名は文字列型である必要があります。 Column names are not string. (列名が文字列ではありません。) |
| データフレーム列名は文字列型である必要があります。 Column names {column_names} are not string. (列名 {column_names} は文字列ではありません。) |
エラー 0156
Exception occurs when failed to read data from Azure SQL Database. (Azure SQL Database からデータを読み取ることができなかった場合、例外が発生します。)
| 例外メッセージ |
|---|
| Failed to read data from Azure SQL Database. (Azure SQL Database からデータを読み取れませんでした。) |
| Failed to read data from Azure SQL Database: {detailed_message} DB: {database_server_name}:{database_name} Query: {sql_statement} (Azure SQL Database からデータを読み取れませんでした: {detailed_message} DB: {database_server_name}: {database_name} クエリ: {sql_statement}) |
エラー 0157
Datastore not found. (データストアが見つかりません。)
| 例外メッセージ |
|---|
| Datastore information is invalid. (データストア情報が無効です。) |
| Datastore information is invalid. (データストア情報が無効です。) ワークスペース '{workspace_name}' 内の Azure Machine Learning データストア '{datastore_name}' を取得できませんでした。 |
エラー 0158
変換ディレクトリが無効な場合にスローされます。
| 例外メッセージ |
|---|
| Given TransformationDirectory is invalid. (指定された TransformationDirectory は無効です。) |
| TransformationDirectory "{arg_name}" is invalid. (TransformationDirectory "{arg_name}" は無効です。) Reason: {reason}. (理由: {reason}。) Rerun training experiment, which generates the Transform file. (変換ファイルを生成するトレーニング実験を再実行してください。) If training experiment was deleted, please recreate and save the Transform file. (トレーニング実験が削除された場合は、変換ファイルを再作成して保存してください。) |
| TransformationDirectory "{arg_name}" is invalid. (TransformationDirectory "{arg_name}" は無効です。) Reason: {reason}. (理由: {reason}。) {troubleshoot_hint} |
エラー 0159
コンポーネント モデル ディレクトリが無効な場合に、例外が発生します。
| 例外メッセージ |
|---|
| Given ModelDirectory is invalid. (指定された ModelDirectory が無効です。) |
| ModelDirectory "{arg_name}" is invalid. (ModelDirectory "{arg_name}" が無効です。) |
| ModelDirectory "{arg_name}" is invalid. (ModelDirectory "{arg_name}" が無効です。) Reason: {reason}. (理由: {reason}。) |
| ModelDirectory "{arg_name}" is invalid. (ModelDirectory "{arg_name}" が無効です。) Reason: {reason}. (理由: {reason}。) {troubleshoot_hint} |
エラー 1000
内部ライブラリの例外。
このエラーは、他の方法では処理されない内部エンジン エラーをキャプチャするために提供されます。 そのため、このエラーの原因は、エラーが生成されたコンポーネントによって異なる可能性があります。
詳細なヘルプを受けるには、エラーに付随する詳細なメッセージに、入力として使用したデータなどのシナリオの説明を添えて、Azure Machine Learning フォーラムに投稿することをお勧めします。 このフィードバックは、エラーに優先順位を付け、さらに作業を進めるために最も重要な問題を特定するのに役立ちます。
| 例外メッセージ |
|---|
| Library exception. (ライブラリ例外。) |
| Library exception: {exception}. (ライブラリの例外: {exception}。) |
| Unknown library exception: {exception}. (不明なライブラリの例外: {exception}。) {customer_support_guidance}。 |
トラブルシューティング ガイド
Python スクリプト コンポーネントの実行エラー
Execute Python Script コンポーネントの 70_driver_logs で azureml_main を検索すると、エラーが発生した行を見つけることができます。 たとえば、"File "/tmp/tmp01_ID/user_script.py", line 17, in azureml_main" は、Python スクリプトの 17 行目でエラーが発生したことを示します。
分散トレーニング
現在、デザイナーでは、PyTorch モデルのトレーニングコンポーネントと、それに対する分散トレーニングをサポートしています。
コンポーネント対応の分散トレーニングが 70_driver ログなしで失敗した場合、70_mpi_log でエラーの詳細を確認できます。
次の例は、実行設定のノード数が、コンピューティング クラスターの使用可能なノード数を超えていることを示しています。

次の例は、ノードあたりのプロセス数が、コンピューティングの処理単位よりも大きいことを示しています。

それ以外の場合は、70_driver_log で各プロセスを確認できます。 70_driver_log_0 は、マスター プロセス用です。

パイプラインにサンプル データをマウントできない

上記のエラーが発生した場合は、次の手順に従って問題を解決してください。
データ ノードをダブルクリックして、データストアの詳細ページに移動します。
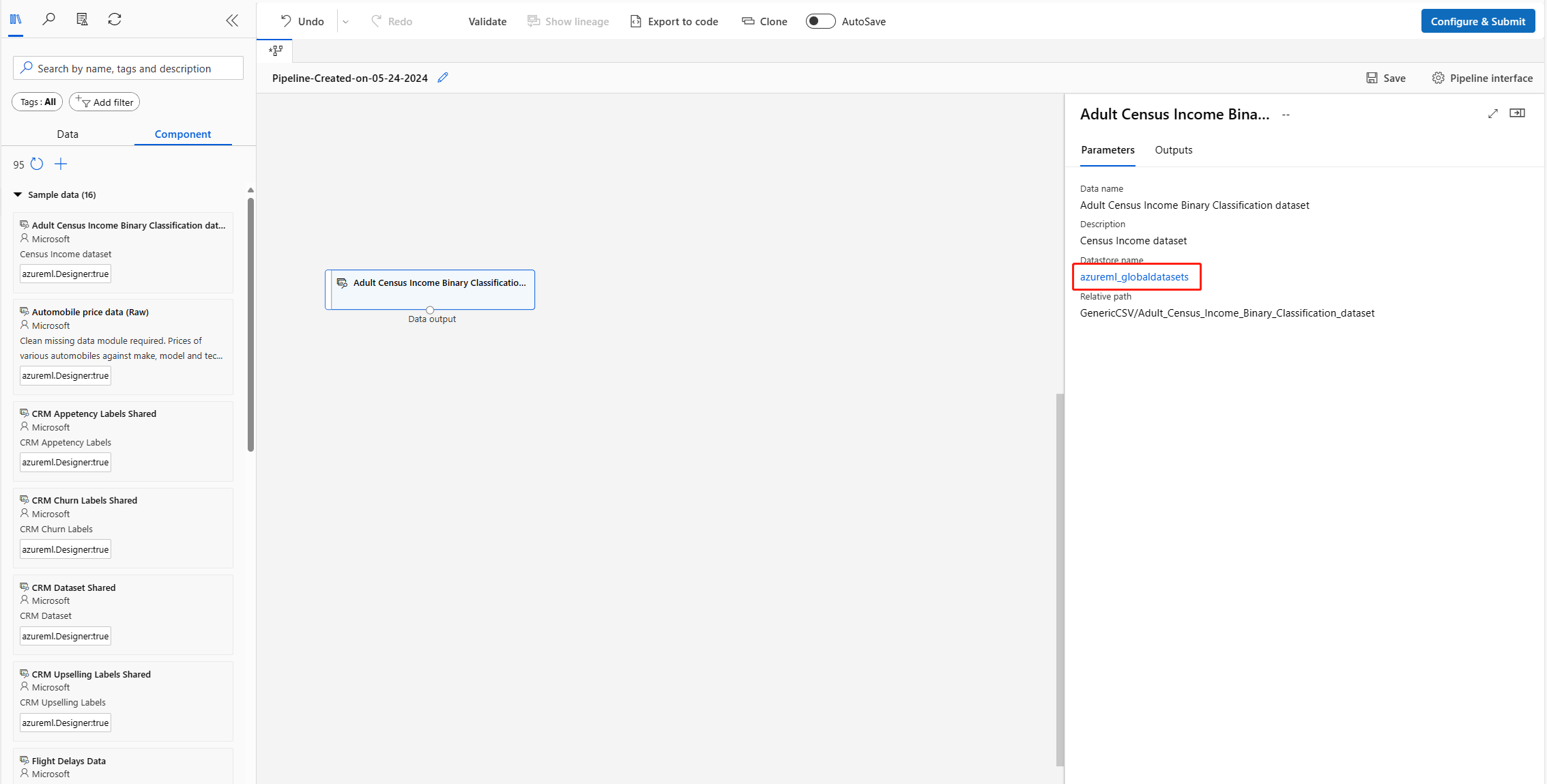
Unregisterこのazureml_globaldatasetsデータ ストア。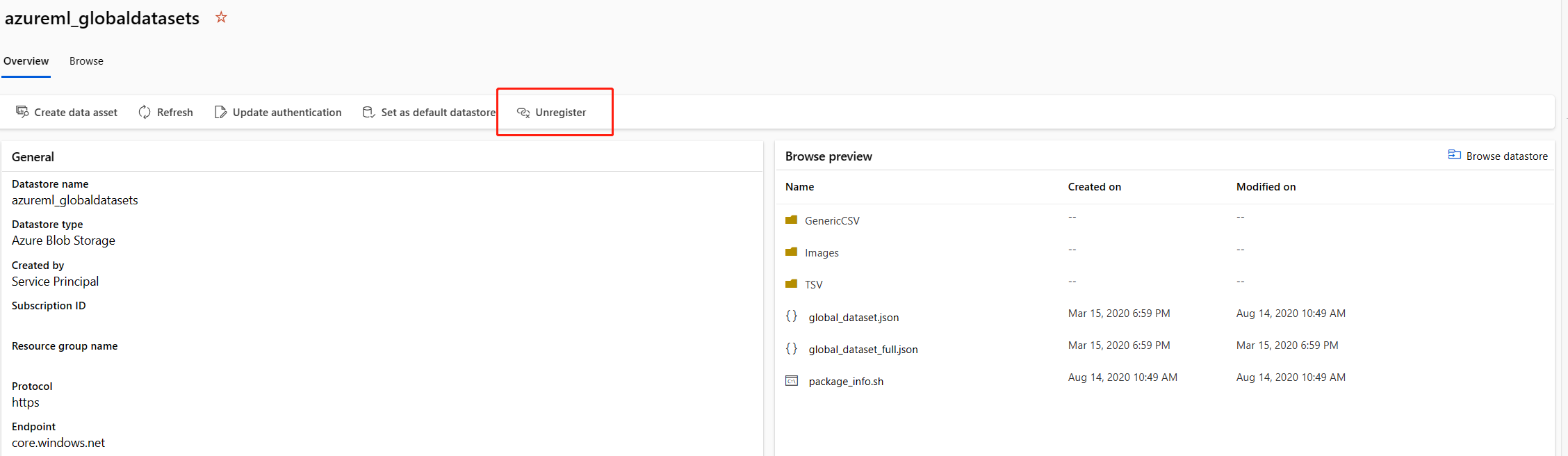
新しい
Sample Dataノードをパイプラインにドラッグ アンド ドロップして、もう一度試します。

