Azure Machine Learning のデザイナー (v1) とは
Azure Machine Learning デザイナーは、Azure Machine Learning スタジオでモデルのトレーニングとデプロイを行うために使用されるドラッグ アンド ドロップ式インターフェイスです。 この記事では、デザイナー内で実行できるタスクについて説明します。
重要
Azure Machine Learning のデザイナーでは、従来型の事前構築済み (v1) コンポーネントを使用するパイプライン、カスタム (v2) コンポーネントを使用するパイプラインの 2 種類がサポートされています。 これら 2 種類のコンポーネントを同じパイプライン内で併用することはできず、デザイナー v1 は CLI v2 および SDK v2 と互換性がありません。 この記事の内容は、従来型の事前構築済み (v1) コンポーネントを使用するパイプラインに関するものです。
従来型の事前構築済みコンポーネント (v1) には、一般的なデータ処理と機械学習タスク (回帰、分類など) が含まれます。 既にある従来型の事前構築済みコンポーネントは引き続き Azure Machine Learning でサポートされますが、事前構築済みコンポーネントが新たに追加されることはありません。 また、従来の事前構築済み (v1) コンポーネントのデプロイでは、マネージド オンライン エンドポイント (v2) はサポートされません。
カスタム コンポーネント (v2) を使用すると、独自のコードをコンポーネントとしてラップできるため、ワークスペース間で共有することや、Azure Machine Learning スタジオ、CLI v2、SDK v2 インターフェイスを横断的に使用したシームレスな作成が可能になります。 新しいプロジェクトにはカスタム コンポーネントを使用することをお勧めします。この種類は Azure Machine Learning v2 と互換性があり、今後も新しい更新が提供されるからです。 カスタム コンポーネントとデザイナー (v2) の詳細については、Azure Machine Learning デザイナー (v2) の記事を参照してください。
以下のアニメーション GIF は、デザイナー内でドラッグ アンド ドロップ操作により資産の配置と接続を行い、パイプラインの構築作業をビジュアルに実行する様子を示しています。

デザイナー内で使用できるコンポーネントについては、アルゴリズムとコンポーネントのリファレンスをご覧ください。 デザイナーで作業を開始するには、コードなし回帰モデルをトレーニングするためのチュートリアルをご覧ください。
モデルのトレーニングとデプロイ
デザイナーでは、Azure Machine Learning のワークスペースを使用して、次のような共有リソースが整理されます。
以下の図は、デザイナーを使用してエンド ツー エンドの機械学習ワークフローを構築する方法を示しています。 モデルのトレーニング、テスト、デプロイは、すべてデザイナーのインターフェイスから実行できます。
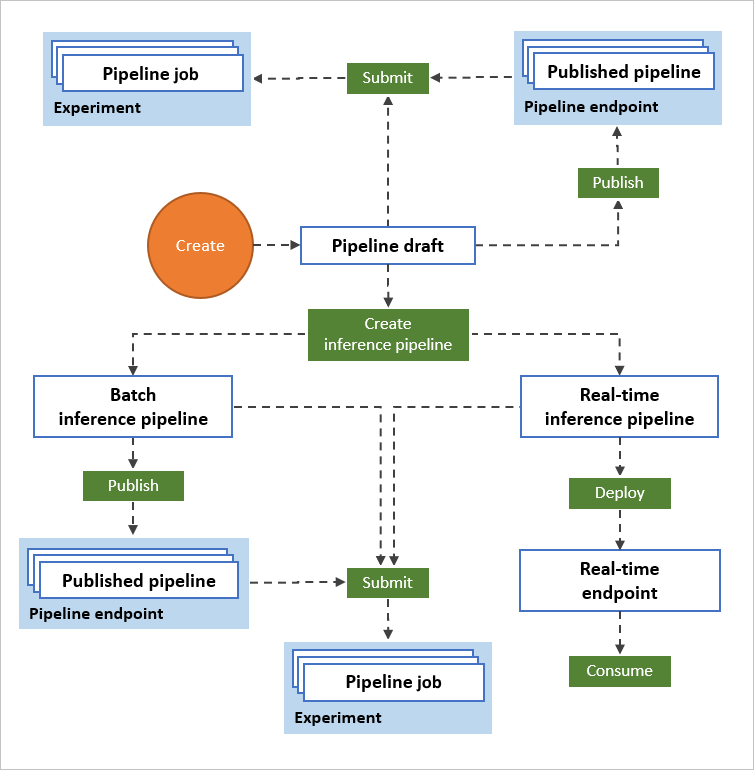
- データ資産とコンポーネントを、デザイナーのビジュアル キャンバスにドラッグ アンド ドロップで配置し、コンポーネント間を接続してパイプライン ドラフトを作成します。
- Azure Machine Learning ワークスペース内のコンピューティング リソースを使用するパイプライン ジョブを送信します。
- トレーニング パイプラインを推論パイプラインに変換します。
- パイプラインを REST パイプライン エンドポイントに発行することで、さまざまなパラメーターとデータ資産を使用して実行される新しいパイプラインを送信します。
- トレーニング パイプラインを発行し、1 つのパイプラインを再利用して、パラメーターとデータ資産を変更しながら、複数のモデルをトレーニングします。
- バッチ推論パイプラインを発行し、以前にトレーニングしたモデルを使用して、新しいデータで予測を行います。
- リアルタイム推論パイプラインをオンライン エンドポイントにデプロイして、新しいデータでの予測をリアルタイムで行います。
データ
機械学習データ資産によって、データへのアクセスと操作がより容易になります。 デザイナーには、実験用のサンプル データ資産が数個用意されています。 必要に応じて、データ資産をさらに登録することができます。
コンポーネント
コンポーネントとは、データに対して実行可能な個々のアルゴリズムです。 デザイナーには、データのイングレス機能や、プロセスのトレーニング、スコアリング、検証などのいくつかのコンポーネントが用意されています。
コンポーネントはパラメーターを取る場合があり、パラメーターを使用してコンポーネントの内部アルゴリズムを構成できます。 キャンバス内でコンポーネントを選択すると、そのコンポーネントのパラメータや他の設定が、キャンバスの右側にあるプロパティ ペインに表示されます。 このペインでは、パラメーターを変更することや、個別コンポーネントのコンピューティング リソースを設定することができます。
使用可能な機械学習アルゴリズム群から成るライブラリの詳細については、アルゴリズムとコンポーネントのリファレンスを参照してください。 アルゴリズムの選択の詳細については、Azure Machine Learning アルゴリズムのチート シートをご覧ください。
Pipelines
パイプラインは、データ資産と、作業者が接続する分析コンポーネントから構成されます。 パイプラインは作業の再利用やプロジェクトの整理に役立ちます。
パイプラインには多くの用途があります。 パイプラインを作成する目的は以下のような事柄です。
- 単一のモデルをトレーニングする。
- 複数のモデルをトレーニングする。
- リアルタイムまたはバッチで予測を行う。
- データのみをクリーンアップする。
パイプライン ドラフト
デザイナーでパイプラインを編集している間、進捗はパイプラインのドラフトとして保存されます。 パイプライン ドラフトはいつでも編集でき、コンポーネントの追加や削除、コンピューティング先の構成、パラメーターの設定を行うことができます。
パイプラインは、以下の性質を満たす場合に有効とされます。
- データ資産は、コンポーネントにのみ接続できます。
- コンポーネントは、データ資産または他のコンポーネントにのみ接続できます。
- コンポーネントのすべての入力ポートに、データ フローへの何らかの接続がある必要がある。
- 各コンポーネントの必須パラメーターがすべて設定されている必要がある。
パイプライン ドラフトを実行する準備ができたら、パイプラインを保存し、パイプライン ジョブを送信します。
パイプラインのジョブ
パイプラインを実行するたびに、パイプラインの構成とその結果が、パイプライン ジョブとしてワークスペースに格納されます。 ジョブの履歴を整理するために、パイプライン ジョブは実験にグループ化されます。
任意のパイプライン ジョブに戻り、トラブルシューティングや監査のために検査することができます。 パイプライン ジョブを複製すると、新しいパイプライン ドラフトを作成して編集できます。
コンピューティング リソース
コンピューティング先は、Azure Machine Learning スタジオ内の Azure Machine Learning ワークスペースにアタッチされます。 ワークスペース内のコンピューティング リソースを使用してパイプラインを実行し、オンライン エンドポイントまたはバッチ推論用のパイプライン エンドポイントとしてデプロイしたモデルをホストします。 以下のコンピューティング先がサポートされています。
| コンピューティング ターゲット | トレーニング | デプロイ |
|---|---|---|
| Azure Machine Learning コンピューティング | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
展開
リアルタイム推論を行うには、パイプラインをオンライン エンドポイントとしてデプロイする必要があります。 オンライン エンドポイントでは、外部アプリケーションと自分のスコアリング モデルの間にインターフェイスが作成されます。 エンドポイントは、Web プログラミング プロジェクトで広く使われているアーキテクチャの REST に基づいています。 オンライン エンドポイントを呼び出すと、予測結果がリアルタイムでアプリケーションに返されます。
オンライン エンドポイントを呼び出すには、エンドポイントのデプロイ時に作成された API キーを渡します。 オンライン エンドポイントは、AKS クラスターにデプロイする必要があります。 モデルのデプロイ方法の詳細については、「チュートリアル: デザイナーで機械学習モデルをデプロイする」を参照してください。
発行
パイプライン エンドポイントにパイプラインを発行することもできます。 パイプライン エンドポイントでも、オンライン エンドポイントと同様に、外部アプリケーションから REST 呼び出しで新しいパイプライン ジョブを送信できます。 ただし、パイプライン エンドポイントの場合、リアルタイムでデータを送受信することはできません。
発行されたパイプライン エンドポイントは柔軟性に優れ、モデルのトレーニングや再トレーニング、バッチ推論の実行、または新しいデータの処理に使用できます。 複数のパイプラインを 1 つのパイプライン エンドポイントに発行し、実行するパイプラインのバージョンを指定できます。
発行されたパイプラインは、各コンポーネントのパイプライン ドラフトで定義されているコンピューティング リソース上で実行されます。 デザイナーでは、SDK と同じ PublishedPipeline オブジェクトが作成されます。
関連するコンテンツ
- 予測分析と機械学習の基礎的な事項を学ぶには: チュートリアル: デザイナーで自動車価格を予測する
- 既存のデザイナーのサンプルを変更して、ニーズに合わせて調整する方法について説明します。