バッチ デプロイ用のスコアリング スクリプトを作成する
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
バッチ エンドポイントを使用すると、長時間の推論を大規模に実行するモデルをデプロイできます。 モデルをデプロイするときは、スコアリング スクリプト (バッチ ドライバー スクリプトとも呼ばれます) を作成して指定し、予測を作成するために入力データに対してモデルをどのように使用するかを示す必要があります。 この記事では、さまざまなシナリオのモデル デプロイでスコアリング スクリプトを使用する方法を学習します。 また、バッチ エンドポイントのベスト プラクティスについても学習します。
ヒント
MLflow モデルにはスコアリング スクリプトは必要ありません。 それは自動生成されます。 バッチ エンドポイントが MLflow モデルでどのように動作するかの詳細については、専用のチュートリアルである「バッチ デプロイでの MLflow モデルの使用」を参照してください。
警告
バッチ エンドポイントの下に自動 ML モデルをデプロイする際には、自動 ML が提供しているのは、オンライン エンドポイントでしか機能しないスコアリング スクリプトであることに注意してください。 このスコアリング スクリプトは、バッチ実行用のものではありません。 自分のモデルが行うこと向けにカスタマイズされたスコアリング スクリプトを作成する方法の詳細を知るには、以下のガイドラインに従ってください。
スコアリング スクリプトについて
スコアリング スクリプトは、モデルの実行方法を指定し、バッチ デプロイ エグゼキューターが送信する入力データを読み取る Python ファイル (.py) です。 各モデル デプロイでは、作成時に (他のすべての必要な依存関係と共に) スコアリング スクリプトを指定します。 通常、スコアリング スクリプトは次のようになります。
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
スコアリング スクリプトには、次の 2 つのメソッドを含める必要があります。
init メソッド
init() メソッドは、コストのかかる準備、または一般的な準備を行うときに使用します。 たとえば、これを使って、モデルをメモリに読み込みます。 バッチ ジョブ全体の開始時に、この関数が 1 回呼び出されます。 モデルのファイルは、環境変数 AZUREML_MODEL_DIR によって決められたパス内に存在します。 モデルの登録方法によっては、それらのファイルはフォルダー内に含まれている場合があります。 次の例では、モデルは model という名前のフォルダー内にいくつかのファイルを持っています。 詳細については、「モデルが使用するフォルダーを決定する方法」を参照してください。
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
この例では、モデルをグローバル変数 model 内に配置します。 スコアリング関数で推論を実行するために必要な資産を使用できるようにするには、グローバル変数を使用します。
run メソッド
run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] メソッドを使用して、バッチ デプロイによって生成される各ミニバッチのスコアリングを処理します。 このメソッドは、入力データに対して生成された mini_batch ごとに 1 回呼び出されます。 バッチ デプロイでは、デプロイの構成に基づいて、データがバッチで読み取られます。
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
メソッドは、ファイル パスのリストをパラメーター (mini_batch) として受け取ります。 このリストを使用すると、各ファイルを反復して個別に処理したり、バッチ全体を読み取って一度に処理したりできます。 最適なオプションは、お使いのコンピューティング メモリと達成すべきスループットによって異なります。 一度にデータのバッチ全体を読み取る方法を示す例については、「高スループット デプロイ」を参照してください。
Note
作業の分散方法について
バッチ デプロイでは、作業はファイル レベルで分散されます。つまり、100 個のファイルを含むフォルダーに、10 個のファイルのミニバッチが設定されると、それぞれが 10 個のファイルのバッチが 10 個生成されます。 関連するファイルのサイズには意味がないことに注意してください。 ファイルが大きすぎて大きなミニバッチで処理できない場合は、ファイルをより小さなファイルに分割して高いレベルの並列性を実現するか、ミニバッチあたりのファイル数を減らすことをお勧めします。 現時点では、バッチ デプロイでファイルのサイズ配分の偏りを解消することはできません。
run() メソッドは、Pandas の DataFrame または配列やリストを返します。 返された出力要素はそれぞれ、入力 mini_batch 内で成功した入力要素の 1 回の実行を示します。 ファイルまたはフォルダーのデータ資産の場合、返されたそれぞれの行/要素が処理された 1 つのファイルを表します。 表形式データ資産の場合、返されたそれぞれの行/要素が処理されたファイル内の 1 つの行を表します。
重要
予測を記述する方法
run() 関数が返すすべてのものは、バッチ ジョブが生成する出力予測ファイルに追加されます。 この関数から正しいデータ型を返すことが重要です。 1 つの予測を出力する必要があるときは、配列を返します。 複数の情報を返す必要があるときは、pandas DataFrames を返します。 たとえば、表形式データの場合、元レコードに予測を追加したい場合があるかもしれません。 これを行うには、pandas DataFrame を使用します。 pandas DataFrame には列名が含まれている場合がありますが、出力ファイルにはこれらの名前は含まれていません。
別の方法で予測を書き込むには、バッチ デプロイで出力をカスタマイズできます。
警告
run 関数では、pandas.DataFrame の代わりに複雑なデータ型 (または複雑なデータ型のリスト) を出力しないでください。 そのような出力は文字列に変換されるため、読むことが困難になります。
結果の DataFrame または配列は、指定された出力ファイルに追加されます。 結果のカーディナリティに関する要件はありません。 1 つのファイルで、出力に 1 つまたは複数の行/要素を生成できます。 結果の DataFrame または配列内のすべての要素は、そのまま出力ファイルに書き込まれます (output_action が summary_only でないことを想定)。
スコアリング用の Python パッケージ
スコアリング スクリプトがバッチ デプロイが実行される環境で実行されるために必要とするライブラリを指定する必要があります。 スコアリング スクリプトに対して、環境はデプロイごとに指定されます。 通常は、次のような conda.yml 依存関係ファイルを使用して要件を指定します。
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
モデルの環境を指定する方法の詳細については、「バッチ デプロイの作成」を参照してください。
別の方法で予測を書き込む
既定では、バッチ デプロイでは、デプロイで示されているように、モデルの予測は 1 つのファイルに書き込まれます。 ただし、場合によっては、予測を複数のファイルに記述する必要があります。 たとえば、分割された入力データの場合は、同様に分割された出力を生成したい可能性が高いでしょう。 このような場合、バッチ デプロイの出力をカスタマイズして、以下を指定することができます。
- 予測を書き込むために使用されるファイル形式 (CSV、parquet、json など)
- 出力におけるデータの分割方法
これを実現する方法の詳細については、「バッチ デプロイでの出力のカスタマイズ」を参照してください。
スコアリング スクリプトのソース管理
スコアリング スクリプトはソース管理下に置くことが強く推奨されます。
スコアリング スクリプトを記述するためのベスト プラクティス
大量のデータを処理するスコアリング スクリプトを記述する場合は、以下のようないくつかの要因を考慮する必要があります
- 各ファイルのサイズ
- 各ファイルのデータ量
- 各ファイルを読み取るために必要なメモリ量
- ファイルのバッチ全体を読み取るために必要なメモリ量
- モデルのメモリ占有領域
- 入力データを処理しているときのモデルのメモリ占有領域
- コンピューティングで利用可能なメモリ
バッチ デプロイは、ファイル レベルで作業を分散します。 つまり、100 個のファイルを含むフォルダーは、10 個のファイルのミニバッチでは、それぞれが 10 個のファイルのバッチを 10 個生成します (含まれるファイルのサイズは関係ありません)。 ファイルが大きすぎて大きなミニバッチで処理できない場合は、ファイルをより小さなファイルに分割して高いレベルの並列性を実現するか、ミニバッチあたりのファイル数を減らすことをお勧めします。 現時点では、バッチ デプロイでファイルのサイズ配分の偏りを解消することはできません。
並列処理の程度とスコアリング スクリプトの関係
デプロイ構成により、各ミニバッチのサイズと各ノード上のワーカーの数が制御されます。 これは、ミニバッチ全体を読み取って推論を実行するか、ファイルごとに推論を実行するか、行ごとに推論を実行するか (表形式の場合) を決定するときに重要になります。 詳細については、「ミニバッチ、ファイル、または行レベルでの推論の実行」を参照してください。
同じインスタンス上で複数のワーカーを実行する場合、メモリがすべてのワーカーで共有される事実を考慮する必要があります。 データ サイズとコンピューティング SKU が同じままの場合、ノードあたりのワーカー数を増やすには、通常、ミニバッチのサイズを減らしたり、スコアリング戦略の変更を同時に行う必要があります。
ミニバッチ、ファイル、または行レベルでの推論の実行
バッチ エンドポイントは、ミニバッチごとに、スコアリング スクリプト内の run() 関数を 1 回呼び出します。 ただし、バッチ全体に対して推論を実行するか、一度に 1 つのファイルに対して推論を実行するか、表形式データで一度に 1 行に対して推論を実行するかは自分で決定できます。
ミニバッチ レベル
バッチ スコアリング プロセスで高いスループットを実現したい場合は、通常、バッチに対して推論をすべて一度に実行する必要があります。 これは、GPU を介して推論を実行し、推論デバイスの飽和状態を実現したい場合が該当します。 また、データがメモリに収まらない場合、バッチ自体を処理できるデータ ローダー (TensorFlow や PyTorch データ ローダーなど) を利用する場合もあります。 このような場合は、バッチ全体で推論を実行する必要があります。
警告
バッチ レベルで推論を実行するには、入力データ サイズを詳細に制御し、メモリ要件に適切に対応して、メモリ不足例外を回避する必要があります。 ミニバッチ全体をメモリに読み込めるかどうかは、ミニバッチのサイズ、クラスター内のインスタンスのサイズ、各ノード上のワーカーの数によって決まります。
これを実現する方法については、「高スループット デプロイ」を参照してください。 この例では、一度にファイルのバッチ全体を処理します。
ファイル レベル
推論を実行する最も簡単な方法の 1 つは、ミニバッチ内のすべてのファイルを反復処理した後、それに対してモデルを実行することです。 画像処理などのいくつかのケースでは、これは良いアイディアです。 表形式データの場合は、各ファイル内の行数を適切に見積もる必要があるかもしれません。 この見積もりによって、モデルがメモリ要件を満たしてデータ全体をメモリに読み込み、それに対する推論を実行できるかどうかが示されます。 一部のモデル (特に、再帰型ニューラル ネットワークに基づくモデル) は展開後に行数に非線形なメモリ占有領域を示す可能性があります。 メモリ コストが高いモデルの場合は、行レベルで推論を実行することを検討してください。
ヒント
並列性を高めるために、一度に読み取るには大きすぎるファイルは、複数のより小さなファイルに分割することを検討してください。
これを行う方法については、「バッチ デプロイを使用した画像処理」を参照してください。 この例では、一度に 1 つのファイルを処理します。
行レベル (表形式)
入力サイズに関して課題があるモデルの場合、行レベルで推論を実行する必要があります。 バッチ デプロイは、ファイルのミニバッチでもスコアリング スクリプトを提供します。 ただし、一度に読み取るのは 1 つのファイルあるいは 1 行です。 これは一見非効率的ですが、一部のディープ ラーニング モデルでは、ハードウェア リソースをスケールアップせずに推論を実行する唯一の方法となる場合があります。
これを行う方法については、「バッチ デプロイを使用したテキスト処理」を参照してください。 この例では、一度に 1 つの行を処理します。
フォルダーであるモデルの使用
AZUREML_MODEL_DIR 環境変数には、選択されたモデルの場所へのパスが含まれており、通常、init() 関数はそれを使用してモデルをメモリに読み込みます。 ただし、一部のモデルはフォルダー内に自身のファイルを持っており、そのようなモデルを読み込むときには、それに対処する必要があります。 モデルのフォルダー構造は、以下に示す方法で特定できます。
Azure Machine Learning ポータルに移動します。
[モデル] セクションに移動します。
デプロイしたいモデルを選択し、[成果物] タブを選択します。
表示されたフォルダーをメモします。 モデルの登録時にこのフォルダーが示されました。
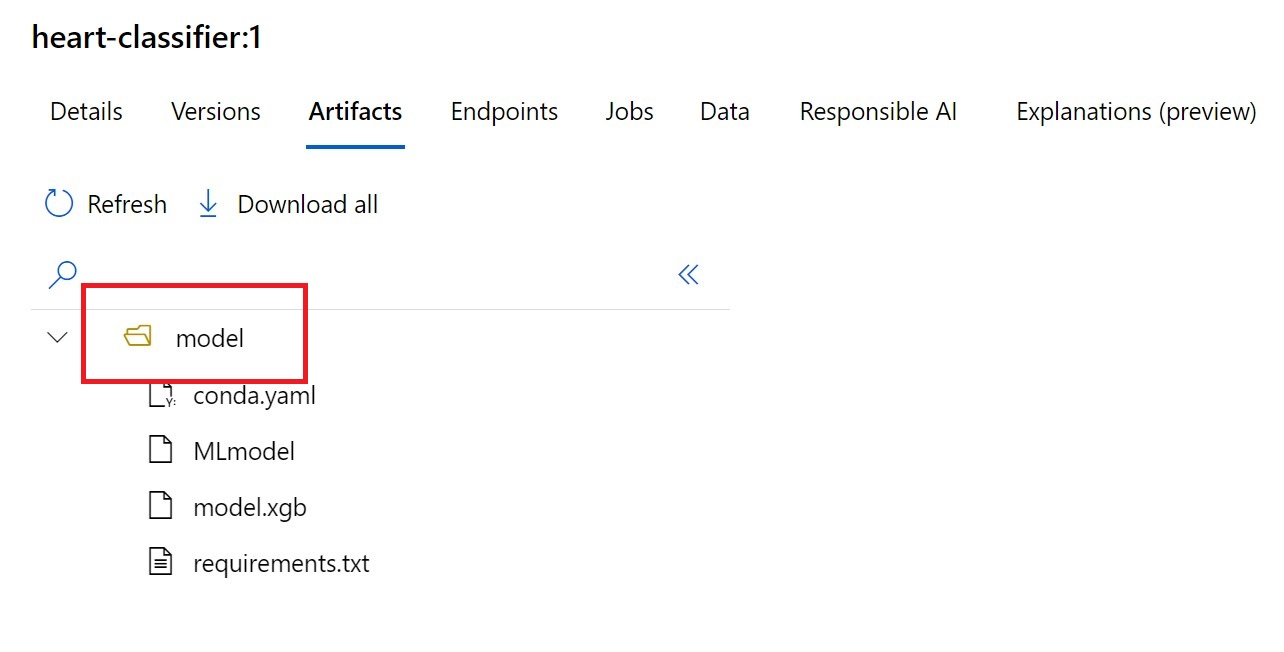

このパスを使用して以下のようにモデルを読み込みます。
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)