カスタム コンテナーを使用してモデルをオンライン エンドポイントにデプロイする
適用対象: Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ml extension v2 (現行)Python SDK azure-ai-ml v2 (現行)
カスタム コンテナーを使用して、Azure Machine Learning のオンライン エンドポイントにモデルをデプロイする方法について学びます。
カスタム コンテナーのデプロイでは、Azure Machine Learning によって使用される既定の Python Flask サーバー以外の Web サーバーを使用できます。 これらのデプロイのユーザーは、Azure Machine Learning の組み込みの監視、スケーリング、アラート、認証を引き続き利用できます。
次のテーブルに、TensorFlow Serving、TorchServe、Triton Inference Server、Plumber R パッケージ、Microsoft Azure Machine Learning Inference Minimal イメージなどのカスタム コンテナーを使用するさまざまなデプロイ例を示します。
| 例 | スクリプト (CLI) | 説明 |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Azure Machine Learning Inference Minimal のイメージを拡張して、複数のモデルを単一のデプロイに配置します。 |
| minimal/single-model | deploy-custom-container-minimal-single-model | Azure Machine Learning Inference Minimal のイメージを拡張して、単一のモデルをデプロイします。 |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Azure Machine Learnin Inference Minimal のイメージを使用して、異なる Python 要件を持つ 2 つの MLFlow モデルを、単一のエンドポイントの背後にある 2 つの個別のデプロイに配置します。 |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Plumber R パッケージを使用して 3 つの回帰モデルを 1 つのエンドポイントに配置する |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | 標準モデル登録プロセスを使用して TensorFlow Serving カスタム コンテナーを使用して、Half Plus Two モデルを配置します。 |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | モデルをイメージに統合した TensorFlow Serving カスタム コンテナーを使用して、シンプルな Half Plus Two モデルを配置します。 |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | TorchServe カスタム コンテナーを使用して単一のモデルを配置します。 |
| triton/single-model | deploy-custom-container-triton-single-model | カスタム コンテナーを使用して、Triton モデルをデプロイする |
この記事では、TensorFlow Serving を使用した TensorFlow (TF) モデルの提供に焦点を当てています。
警告
Microsoft では、カスタム イメージが原因で発生した問題のトラブルシューティングを行うことができない場合があります。 問題が発生した場合は、問題がイメージに固有のものであるかどうかを確認するために、既定のイメージ、または Microsoft が提供するイメージのいずれかを使用するように求められることがあります。
前提条件
この記事の手順に従う前に、次の前提条件が満たされていることをご確認ください。
Azure Machine Learning ワークスペース。 所有していない場合は、クイック スタート: ワークスペース リソースの作成に関する記事の手順に従って作成してください。
Azure CLI と
ml拡張機能または Azure Machine Learning Python SDK v2:Azure CLI と拡張機能をインストールするには、「CLI (v2) のインストール、セットアップ、および使用」を参照してください。
重要
この記事の CLI の例では、Bash (または互換性のある) シェルを使用していることを前提としています。 たとえば、Linux システムや Linux 用 Windows サブシステムなどです。
Python SDK v2 をインストールするには、次のコマンドを使用します。
pip install azure-ai-ml azure-identitySDK の既存のインストールを最新バージョンに更新するには、次のコマンドを使用します。
pip install --upgrade azure-ai-ml azure-identity詳しくは、Azure Machine Learning 用の Python SDK v2 のインストールに関する記事をご覧ください。
ユーザーまたは使用するサービス プリンシパルには、ワークスペースを含む Azure リソース グループへの 共同作成者アクセス権が必要です。 クイックスタートの記事に従ってワークスペースを構成していれば、そのようなリソース グループが得られます。
ローカルに展開するには、Docker エンジンをローカルで実行する必要があります。 この手順は強くお勧めします。 これは、問題のデバッグに役立ちます。
ソース コードのダウンロード
このチュートリアルに従うには、GitHub からソース コードを複製してください。
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
環境変数を初期化する
環境変数を定義します。
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
TensorFlow モデルをダウンロードする
入力を 2 で除算して結果に 2 を加算するモデルをダウンロードして解凍します。
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
TF Serving イメージをローカル環境で実行して動作することをテストする
docker を使用して、テストのためにローカル環境でイメージを実行します。
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
イメージに liveness とスコアリングの要求を送信できることを調べる
最初に、コンテナーが "アライブ" であること、つまりコンテナー内部のプロセスがまだ実行されていることを確認します。 200 (OK) 応答を受け取る必要があります。
curl -v http://localhost:8501/v1/models/$MODEL_NAME
次に、ラベル付けされていないデータに関する予測を取得できることを確認します。
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
イメージを停止する
ローカル環境でのテストが済んだので、イメージを停止します。
docker stop tfserving-test
オンライン エンドポイントを Azure にデプロイする
次に、オンライン エンドポイントを Azure にデプロイする
エンドポイントおよびデプロイ用の YAML ファイルを作成する
YAML を使用してクラウド デプロイを構成できます。 この例で使用する YAML の例をご覧ください。
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
この YAML または Python パラメーターには、注意すべき重要な概念がいくつかあります。
ベース イメージ
基本イメージは、環境内のパラメーターとして指定され、この例では docker.io/tensorflow/serving:latest が使用されています。 コンテナーを調べると、このサーバーが ENTRYPOINT を使用してエントリ ポイント スクリプトを開始していることがわかります。これにより、MODEL_BASE_PATH や MODEL_NAME のような環境変数を受け取り、8501 のようなポートを公開します。 これらの詳細はすべて、この選択したサーバーの特定の情報です。 サーバーに関するこの理解に基づいて、デプロイを定義する方法を決定できます。 たとえば、デプロイ定義で MODEL_BASE_PATH と MODEL_NAME の環境変数を設定した場合、サーバー (この場合は TF Serving) はサーバーを開始するための値を受け取ります。 同様に、デプロイ定義でルートのポートを 8501 に設定すると、該当するルートへのユーザー要求が TF Serving サーバーに正しくルーティングされます。
この具体的な例は TF Serving のケースに基づいていますが、稼働状態を維持し、liveness、readiness、スコアリング ルートに関する要求に応答する任意のコンテナーを使用できることに注意してください。 他の例を参照して、コンテナーを作成するために dockerfile がどのように構成されているか (たとえば、ENTRYPOINT の代わりに CMD を使用しているなど) を確認できます。
推論の構成
推論構成は環境内のパラメーターであり、3 種類のルート (liveness、readiness、スコアリング ルート) のポートとパスを指定します。 マネージド オンライン エンドポイントを使用して独自のコンテナーを実行する場合は、推論構成が必要です。
readiness ルートと liveness ルート
選択した API サーバーによって、サーバーの状態を確認する方法が提供される場合があります。 指定できるルートには、liveness と readiness の 2 種類があります。 liveness ルートは、サーバーが実行されているかどうかを調べるために使用されます。 readiness ルートは、サーバーが作業を行う準備ができているかどうかを調べるために使用されます。 機械学習推論のコンテキストでは、サーバーはモデルを読み込む前に liveness 要求に対して 200 OK を応答でき、また、サーバーはモデルがメモリに読み込まれた後でのみ、readiness 要求に対して 200 OK を応答できます。
一般的な liveness および readiness probe の詳細については、Kubernetes のドキュメントを参照してください。
liveness および readiness ルートは、前の手順でコンテナーをローカルでテストするときに特定したように、選択した API サーバーによって決定されます。 この記事のデプロイ例では、TF Serving で liveness ルートだけが定義されているため、liveness と readiness の両方に同じパスを使用することに注意してください。 ルートを定義するさまざまなパターンについては、他の例を参照してください。
スコアリング ルート
選択した API サーバーによって、作業するペイロードを受け取る方法が提供されます。 機械学習推論のコンテキストでは、サーバーは特定のルートを介して入力データを受信します。 API サーバーのこのルートは、前の手順でコンテナーをローカルでテストするときに特定し、作成するデプロイを定義するときに指定します。
デプロイが正常に作成されると、エンドポイントのscoring_uri パラメーターも更新されることに注意してください。これは az ml online-endpoint show -n <name> --query scoring_uri を使用して確認できます。
マウントされたモデルの配置
モデルをオンライン エンドポイントとしてデプロイすると、Azure Machine Learning によってモデルがエンドポイントに "マウント" されます。 モデルがマウントされると、新しい Docker イメージを作成することなく、モデルの新しいバージョンをデプロイできます。 既定では、名前 foo およびバージョン 1 で登録されたモデルは、デプロイされたコンテナーの内部の次のパスに配置されます: /var/azureml-app/azureml-models/foo/1
たとえば、ローカル コンピューター上にディレクトリ構造 /azureml-examples/cli/endpoints/online/custom-container があり、モデルの名前 がhalf_plus_two 場合は、次のようになります。
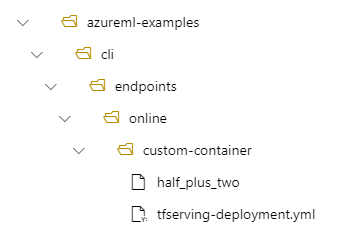
tfserving-deployment.yml には次のものが含まれます。
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
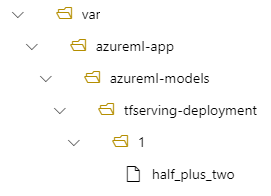
その後、デプロイの /var/azureml-app/azureml-models/tfserving-deployment/1 の下にモデルが配置されます。
必要に応じて、model_mount_path を構成することもできます。 これにより、モデルがマウントされているパスを変更できます。
重要
model_mount_path には、Linux (コンテナー イメージの OS) で有効な絶対パスを指定してください。
たとえば、以下のように tfserving-deployment.yml に model_mount_path パラメーターを含めることができます。
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
.....
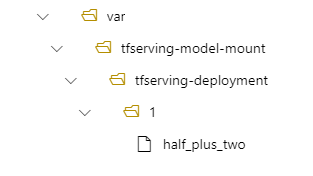
その後、デプロイの /var/tfserving-model-mount/tfserving-deployment/1 にモデルが配置されます。 azureml-app/azureml-models ではなく、ご自分で指定したマウント パスの下に配置されます。
エンドポイントとデプロイを作成する
YAML の構築方法がわかったので、ご自分でエンドポイントを作成してください。
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
デプロイの作成には数分かかる場合があります。
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
エンドポイントを呼び出す
デプロイが完了したら、デプロイされたエンドポイントにスコアリング要求を行うことができるかどうかを確認します。
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
エンティティを削除する
エンドポイントで正常にスコアリングできたので、それを削除できます。
az ml online-endpoint delete --name tfserving-endpoint