コンポーネントとパイプラインの入力と出力を管理する
この記事では、次のことについて説明します。
- コンポーネントとパイプラインでの入力と出力の概要
- コンポーネントの入力と出力をパイプラインの入力と出力にレベル上げする方法
- 省略可能な入力を定義する方法
- 出力パスをカスタマイズする方法
- 出力をダウンロードする方法
- 出力を名前付き資産として登録する方法
入力と出力の概要
Azure Machine Learning のパイプラインでは、コンポーネントとパイプライン両方のレベルで入力と出力がサポートされます。
コンポーネント レベルでは、入力と出力によってコンポーネントのインターフェイスが定義されます。 1 つのコンポーネントからの出力を、同じ親パイプライン内の別のコンポーネントの入力として使用でき、コンポーネント間でデータやモデルを受け渡すことができます。 この相互接続性により、パイプライン内のデータ フローを示すグラフが形成されます。
パイプライン レベルの入力と出力は、トレーニング ロジックを制御するさまざまなデータ入力またはパラメーターを含むパイプライン ジョブを送信する場合に役立ちます (例: learning_rate)。 これらは、REST エンドポイントを介してパイプラインを呼び出すときに特に便利です。 これらの入力と出力を使うと、パイプラインの入力に異なる値を割り当てたり、REST エンドポイントを介してパイプライン ジョブの出力にアクセスしたりできます。 詳しくは、「バッチ エンドポイントのジョブと入力データを作成する」をご覧ください。
入力と出力の種類
コンポーネントまたはパイプラインの出力として、次の種類がサポートされています。
データ型 データ型の詳細については、Azure Machine Learning のデータ型を確認してください。
uri_fileuri_foldermltable
モデルの種類。
mlflow_modelcustom_model
データまたはモデル出力を使用して、基本的に出力をシリアル化し、保存場所にファイルとして保存します。 以降の手順では、このストレージの場所をマウント、ダウンロード、またはコンピューティング先のファイル システムにアップロードして、次の手順でジョブの実行中にファイルにアクセスできるようにします。
このプロセスでは、コンポーネントのソース コードで、目的の出力オブジェクト (通常はメモリに格納される) をファイルにシリアル化する必要があります。 たとえば、pandas データフレームを CSV ファイルとしてシリアル化できます。 Azure Machine Learning では、オブジェクトのシリアル化のための標準化されたメソッドは定義されていないことに注意してください。 ユーザーは、オブジェクトをファイルにシリアル化する方法を柔軟に選択できます。 その後、ダウンストリーム コンポーネントでは、これらのファイルを個別に逆シリアル化して読み取ることができます。 参照用のいくつかの例を次に示します。
- nyc_taxi_data_regression の例では、準備コンポーネント には
uri_folder型の出力があります。 コンポーネントのソース コードでは、入力フォルダーから csv ファイルを読み取り、ファイルを処理し、処理された CSV ファイルを出力フォルダーに書き込みます。 - nyc_taxi_data_regression の例では、トレーニング コンポーネントには
mlflow_model型の出力があります。 コンポーネントのソース コードでは、mlflow.sklearn.save_modelメソッドを使用してトレーニング済みのモデルを保存します。
上記のデータ型またはモデル型に加えて、パイプラインまたはコンポーネント入力は、次のプリミティブ型にすることもできます。
stringnumberintegerboolean
nyc_taxi_data_regression の例では、トレーニング コンポーネントには、test_split_ratio という名前の number 入力があります。
Note
プリミティブ型の出力はサポートされていません。
データの入力と出力のパスとモード
データ資産の入力と出力の場合、データの場所を指す path パラメーターを指定する必要があります。 次の表は、Azure Machine Learning のパイプラインでサポートされるさまざまなデータの場所を示したもので、path パラメーターの例も示してあります。
| Location | 例 | 入力 | 出力 |
|---|---|---|---|
| ローカル コンピューター上のパス | ./home/username/data/my_data |
✓ | |
| パブリック HTTP(S) サーバー上のパス | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
✓ | |
| Azure Storage 上のパス | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
データを読み取るために余分な ID の構成が必要になる場合があるため、推奨されません。 | |
| Azure Machine Learning データストアのパス | azureml://datastores/<data_store_name>/paths/<path> |
✓ | ✓ |
| データ資産へのパス | azureml:<my_data>:<version> |
✓ | ✓ |
Note
ストレージでの入出力については、Azure Storage の直接パスではなく、Azure Machine Learning のデータストア パスを使うことを強くお勧めします。 データストア パスは、パイプラインのさまざまなジョブの種類でサポートされています。
データの入出力では、さまざまなモード (ダウンロード、マウント、またはアップロード) から選んで、コンピューティング先でデータにアクセスする方法を定義できます。 次の表は、さまざまな種類、モード、入力、出力の組み合わせに対して使用できるモードを示したものです。
| 種類 | [入力または出力] | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
入力 | ✓ | ✓ | ✓ | ||||
uri_file |
入力 | ✓ | ✓ | ✓ | ||||
mltable |
入力 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
出力 | ✓ | ✓ | |||||
uri_file |
出力 | ✓ | ✓ | |||||
mltable |
出力 | ✓ | ✓ | ✓ |
Note
ほとんどの場合、ro_mount モードまたは rw_mount モードを使用することをおすすめします。 モードの詳細については、「データ資産のモード」をご覧ください。
Azure Machine Learning スタジオでのビジュアル表現
次のスクリーンショットは、Azure Machine Learning スタジオのパイプライン ジョブでの入力と出力の表示方法の例を示したものです。 nyc-taxi-data-regression という名前のこの特定のジョブは、azureml-example で確認できます。
スタジオのパイプライン ジョブ ページでは、コンポーネントのデータ/モデルの種類の入出力は、対応するコンポーネントの小さな円 (入出力ポートと呼ばれます) として示されます。 これらのポートは、パイプラインでのデータ フローを表します。
パイプライン レベルの出力は、簡単に識別できるように紫色のボックスとして表示されます。

入出力ポートをマウスでポイントすると、種類が表示されます。

プリミティブ型の入力はグラフに表示されません。 これは、パイプライン ジョブの概要パネル (パイプライン レベルの入力の場合) またはコンポーネント パネル (コンポーネント レベルの入力の場合) の [設定] タブにあります。 次のスクリーンショットは、パイプライン ジョブの [設定] タブを示したものです。これは、[ジョブの概要] リンクを選んで開くことができます。
コンポーネントの入力を調べたい場合は、コンポーネントをダブルクリックしてコンポーネント パネルを開きます。

同様に、デザイナーでパイプラインを編集中に、[パイプライン インターフェイス] パネルでパイプラインの入力と出力を、またコンポーネントのパネル (コンポーネントをダブルクリックするとトリガーされます) でコンポーネントの入力と出力を見つけることができます。

コンポーネントの入力と出力をパイプライン レベルに上げる方法
コンポーネントの入出力をパイプライン レベルに上げると、パイプライン ジョブを送信するときに、コンポーネントの入出力を上書きできます。 また、REST エンドポイントを使ってパイプラインをトリガーする場合にも便利です。
コンポーネントの入出力をパイプライン レベルの入出力に上げる例を次に示します。
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
完全な例は、train-score-eval パイプラインと登録済みコンポーネントに関するページで確認できます。 このパイプラインでは、3 つの入力と 3 つの出力がパイプライン レベルに上げられます。 例として pipeline_job_training_max_epocs を見てみましょう。 それは、ルート レベルの inputs セクションで宣言されています。これは、それがパイプライン レベルの入力であることを意味します。 jobs -> train_job セクションでは、max_epocs という名前の入力が ${{parent.inputs.pipeline_job_training_max_epocs}} として参照されています。これは、train_job の入力 max_epocs がパイプライン レベルの入力 pipeline_job_training_max_epocs を参照していることを示します。 同様に、同じスキーマを使ってパイプラインの出力のレベルを上げることができます。
[ スタジオ](#tab/azure-studio)
デザイナーの作成ページで、コンポーネントの入力をパイプライン レベルの入力に上げることができます。 コンポーネントをダブルクリックしてコンポーネントの設定パネルに移動し -> レベルを上げる入力を見つけてから -> 右側 の 3 つのドットを選んで ->[パイプラインの入力に追加] を選びます。

省略可能な入力
既定では、すべての入力は必須であり、パイプライン ジョブを送信するたびに値 (または既定値) を割り当てる必要があります。 ただし、省略可能な入力が必要になる場合があります。 このような場合、パイプライン ジョブの送信時に入力に値を割り当てなくてもかまわない柔軟性があります。
省略可能な入力は、次の 2 つのシナリオで役立ちます:
オプションのデータ/モデル型入力があり、パイプライン ジョブの送信時に値を割り当てない場合は、パイプライン内に先行するデータ依存関係がないコンポーネントが存在します。 言い換えると、入力ポートは、どのコンポーネントノードやデータ/モデルノードにもリンクされません。 これにより、パイプライン サービスは、前の依存関係の準備が整うのを待つのではなく、このコンポーネントを直接呼び出します。
次のスクリーンショットは、2 番目のシナリオの明確な例を示しています。 パイプラインに
continue_on_step_failure = Trueを設定し、最初のノード (node1) からの出力を省略可能な入力として使用する 2 番目のノード (node2) がある場合、node1 が失敗しても node2 は引き続き実行されます。 ただし、node2 が node1 からの必要な入力を使用している場合、node1 が失敗すると実行されません。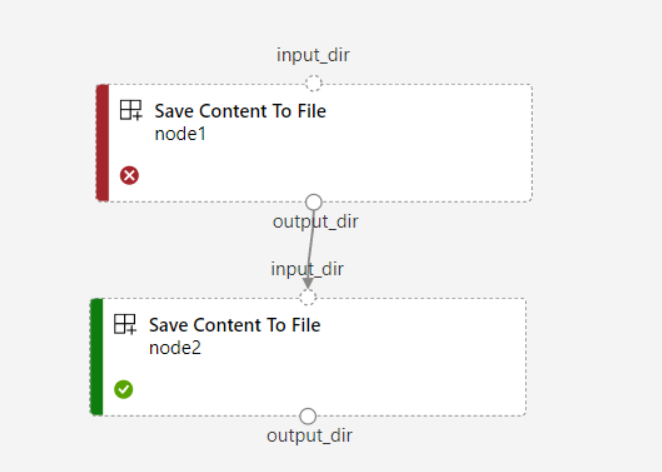

省略可能な入力を定義する方法の例を次に示します。
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}
入力が optional = true として設定されている場合、入力を含むコマンド ラインを $[[]] を使用して囲む必要があります。 上の例で強調されている行を参照してください。
Note
省略可能な出力はサポートされていません。
パイプライン グラフでは、データとモデルの種類の省略可能な入力は点線の円で表されます。 プリミティブ型の省略可能な入力は、[設定] タブで見つかります。必須の入力とは異なり、省略可能な入力の横にはアスタリスクが付いておらず、必須ではないことを示します。

出力パスをカスタマイズする方法
既定では、コンポーネントの出力は azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}} に格納されます。 {default_datastore} は、ユーザーがパイプラインに対して設定した既定のデータストアです。 設定されていない場合は、ワークスペース BLOB ストレージになります。 {name} はジョブの名前で、ジョブの実行時に解決されます。 {output_name} は、ユーザーがコンポーネントの YAML で定義した出力の名前です。
ただし、出力のパスを定義することで、出力を格納する場所をカスタマイズすることもできます。 次に例を示します。
pipeline.yaml では、3 つのパイプライン レベルの出力を持つパイプラインが定義されています。 完全な YAML は、train-score-eval パイプラインと登録済みコンポーネントの例に関するページで確認できます。
次のコマンドを使って、pipeline_job_trained_model の出力のカスタム出力パスを設定できます。
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path
出力をダウンロードする方法
次の例のようにして、コンポーネントの出力またはパイプライン出力をダウンロードできます。
パイプライン レベルの出力をダウンロードする
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
子ジョブの出力をダウンロードする
子ジョブの出力 (パイプライン レベルに上がらないコンポーネント出力) をダウンロードする必要がある場合は、最初にパイプライン ジョブのすべての子ジョブ エンティティの一覧を取得してから、同様のコードを使って出力をダウンロードする必要があります。
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select needed child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
出力を名前付き資産として登録する方法
name と version を出力に割り当てることで、コンポーネントまたはパイプラインの出力を名前付き資産として登録できます。 登録された資産は、スタジオの UI、CLI、SDK を使ってワークスペースで一覧表示でき、将来のジョブで参照することもできます。
パイプラインの出力を登録する
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
子ジョブの出力を登録する
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster