スタジオの UI で責任ある AI 分析情報を生成する
この記事では、Azure Machine Learning スタジオの UI のコードなしのエクスペリエンスで、責任ある AI ダッシュボードとスコアカード (プレビュー) を作成します。
重要
現在、この機能はパブリック プレビュー段階にあります。 このプレビュー バージョンはサービス レベル アグリーメントなしで提供されており、運用環境のワークロードに使用することは推奨されません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。
詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
ダッシュボード生成ウィザードにアクセスし、責任ある AI ダッシュボードを生成するには、次の操作を行います。
コードなしのエクスペリエンスにアクセスできるように、Azure Machine Learning にモデルを登録します。
Azure Machine Learning スタジオの左側のペインで、[モデル] タブを選択します。
責任ある AI 分析情報を作成する登録済みモデルを選択し、[詳細] タブを選択します。
[責任ある AI ダッシュボードの作成 (プレビュー)] を選択します。
![ウィザードの詳細ペインのスクリーンショット。[責任ある AI ダッシュボードの作成 (プレビュー)] タブが強調表示されています。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard.png?view=azureml-api-2)
![ウィザードの詳細ペインのスクリーンショット。[責任ある AI ダッシュボードの作成 (プレビュー)] タブが強調表示されています。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard.png?view=azureml-api-2#lightbox)
責任ある AI ダッシュボードでサポートされているモデルの種類と制限事項の詳細については、サポートされているシナリオと制限事項に関するページを参照してください。
ウィザードに用意されたインターフェイスを使用すると、コードに触れることなく、責任ある AI ダッシュボードを作成するために必要なすべてのパラメーターを入力できます。 このエクスペリエンスは、Azure Machine Learning スタジオの UI ですべてが行われます。 スタジオには、どの責任ある AI コンポーネントでダッシュボードを設定するべきかに関するさまざまな選択肢のコンテキストを確認するのに役立つ、ガイド付きフローと指示テキストが表示されます。
このウィザードは、5 つのセクションに分かれています。
- トレーニング データセット
- テスト データセット
- モデリング タスク
- [ダッシュボード] のコンポーネント
- コンポーネントのパラメーター
- 実験構成
データセットを選択する
最初の 2 つのセクションでは、モデルのトレーニング時に使用したトレーニングとテストのデータセットを選択して、モデル デバッグの分析情報を生成します。 モデルを必要としない原因分析などのコンポーネントの場合は、トレーニング データセットを使用して原因モデルをトレーニングして、原因分析情報を生成します。
注意
ML テーブルでは、表形式のデータセットのみがサポートされています。
[トレーニング用のデータセットの選択]: Azure Machine Learning ワークスペースの登録済みデータセットのリストで、モデルの説明やエラー分析などのコンポーネントに対する責任ある AI の分析情報を生成するために使用するデータセットを選択します。
![[トレーニング データセット] タブのスクリーンショット。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-train-dataset.png?view=azureml-api-2)
[テスト用のデータセットの選択]: 登録されたデータセットのリストで、責任ある AI ダッシュボードの視覚化を事前設定するために使用するデータセットを選択します。
![[テスト データセット] タブのスクリーンショット。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-test-dataset.png?view=azureml-api-2)
使用するトレーニング データセットまたはテスト データセットが一覧にない場合は、[作成] を選択してアップロードします。
![[トレーニング データセット] タブのスクリーンショット。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-train-dataset.png?view=azureml-api-2#lightbox)
![[テスト データセット] タブのスクリーンショット。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-test-dataset.png?view=azureml-api-2#lightbox)
モデリング タスクを選択する
データセットを選択したら、次の図に示すようにモデリング タスクの種類を選択します。
![[モデリング タスク] タブのスクリーンショット。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-modeling-task.png?view=azureml-api-2#lightbox)
ダッシュボードのコンポーネントを選択する
責任ある AI ダッシュボードには、生成できるツールの推奨されるセット用に 2 つのプロファイルが用意されています。
[モデルのデバッグ]: エラー分析、反事実条件 what-if の例、モデル説明を使用して、機械学習モデルの誤りのあるデータ コーホートを理解してデバッグします。
[実際のインターベンション]: 原因分析を使用して、機械学習モデルの誤りのあるデータ コーホートを理解してデバッグします。
注意
複数クラス分類では、実際のインターベンション分析プロファイルはサポートされていません。
![[ダッシュボード コンポーネント] タブのスクリーンショット。[モデルのデバッグ] と [実際のインターベンション] プロファイルが表示されています。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-dashboard-components.png?view=azureml-api-2#lightbox)
- 使用するプロファイルを選択します。
- [次へ] を選択します。
ダッシュボードのコンポーネント用のパラメーターを構成する
プロファイルを選択すると、対応するコンポーネントの [モデル デバッグのためのコンポーネント パラメーター] 構成ペインが表示されます。
![[コンポーネント パラメーター] タブのスクリーンショット。[モデル デバッグのコンポーネント パラメーター] 構成ペインが表示されています。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-component-parameter-debugging.png?view=azureml-api-2#lightbox)
モデル デバッグ用のコンポーネント パラメーター:
[対象の特徴量] (必須): モデルが予測するようにトレーニングされた特徴を指定します。
[Categorical features](カテゴリの特徴): ダッシュボード UI でカテゴリ値として適切にレンダリングするためのカテゴリである特徴を示します。 このフィールドは、データセットのメタデータに基づいて事前に読み込まれます。
[エラー ツリーとヒート マップを生成する]: 責任ある AI ダッシュボードでのエラー分析コンポーネントの生成のオンとオフを切り替えます。
[エラー ヒート マップの特徴]: エラー ヒート マップを事前に生成する最大 2 つの特徴を選択します。
[詳細な構成]: [エラー ツリーの最大深度]、[エラー ツリー内のリーフ数]、[各リーフ ノードの最小サンプル数] など、追加のパラメーターを指定します。
[反事実条件 what-if の例を生成する]: 責任ある AI ダッシュボードでの反事実条件 what-if コンポーネントの生成のオンとオフを切り替えます。
[反事実条件の数] (必須): データ ポイントごとに生成する反事実条件の例の数を指定します。 目的の予測を達成するために平均に対して最も摂動された特徴の横棒グラフ ビューを有効にするには、10 個以上生成する必要があります。
[値の予測の範囲] (必須): 回帰シナリオの場合に、反事実条件の例で予測値が含まれる範囲を指定します。 二項分類のシナリオでは、データ ポイントごとに逆のクラスの反事実条件が生成されるように、範囲が自動的に設定されます。 複数分類のシナリオの場合は、ドロップダウン リストを使用して、各データ ポイントをどのクラスとして予測するかを指定します。
[摂動する特徴の指定]: 既定では、すべての特徴が摂動されます。 ただし、特定の特徴のみを摂動させる場合は、[反事実条件の説明を生成するために摂動させる特徴の指定] を選択して、選択する特徴の一覧を含むペインを表示します。
[摂動する特徴の指定] を選択した場合は、摂動可能な範囲を指定できます。 たとえば、特徴 YOE (経験年数) の場合、反事実条件の特徴値を、既定値の 5 から 21 ではなく、10 から 21 の範囲のみにする必要があることを指定します。

[Generate explanations](説明を生成する): 責任ある AI ダッシュボードでのモデル説明コンポーネントの生成のオンとオフを切り替えます。 既定の不透明な箱の模倣の説明を使用して特徴量の重要度が生成されるため、構成は必要ありません。

代わりに [実際の介入] プロファイルを選択した場合は、次の画面に原因分析が生成されます。 これは、最適化したい特定の結果に対する "処理" したい特徴量の因果効果を理解するのに役立ちます。
![ウィザードのスクリーンショット。[実際のインターベンションのコンポーネント パラメーター] ペインが表示されています。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-component-parameter-real-life-intervention.png?view=azureml-api-2#lightbox)
実際のインターベンションのためのコンポーネント パラメーターでは、原因分析を使用します。 次の操作を行います。
- [対象の特徴量] (必須): 因果効果を計算する対象の結果を選びます。
- 処理特徴量 (必須): ターゲットの結果を最適化するために、変更 ("処理") してみたい特徴量を 1 つ以上選択します。
- [Categorical features](カテゴリの特徴): ダッシュボード UI でカテゴリ値として適切にレンダリングするためのカテゴリである特徴を示します。 このフィールドは、データセットのメタデータに基づいて事前に読み込まれます。
- [詳細設定]: 異種特徴量 (つまり、処理特徴量に加えて、解析における因果関係のセグメント化を理解するための追加特徴量) や使用する原因モデルなど、原因分析の追加パラメーターを指定します。
実験を構成する
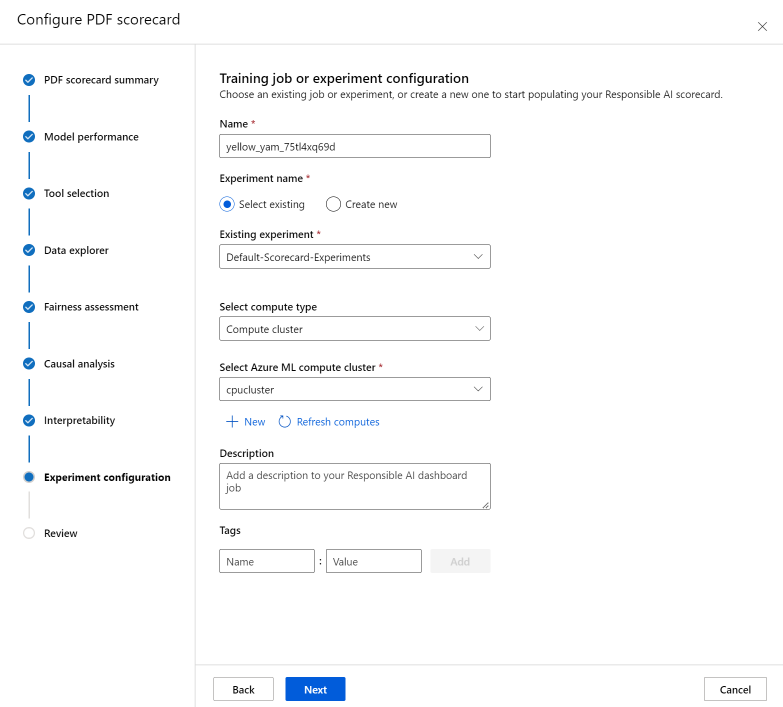
最後に、責任ある AI ダッシュボードを生成するジョブを開始するように実験を構成します。
![[実験の構成] タブのスクリーンショット。[トレーニング ジョブまたは実験の構成] ペインが表示されています。](media/how-to-responsible-ai-insights-ui/create-responsible-ai-dashboard-ui-experiment-config.png?view=azureml-api-2#lightbox)
[トレーニング ジョブまたは実験の構成] ペインで、次の操作を行います。
- 名前: 特定のモデルのダッシュボードの一覧を確認するときに区別できるように、ダッシュボードに一意の名前を付けます。
- [実験名]: ジョブを実行する既存の実験を選ぶか、新しい実験を作ります。
- [既存の実験]: ドロップダウン リストで、既存の実験を選択します。
- [コンピューティングの種類の選択]: ジョブの実行に使用するコンピューティングの種類を指定します。
- [コンピューティングの選択]: ドロップダウン リストで、使用するコンピューティングを選択します。 既存のコンピューティング リソースがない場合は、プラス記号 ([+]) を選択して新しいコンピューティング リソースを作成し、一覧を更新します。
- [説明]: 責任ある AI ダッシュボードの詳細な説明を追加します。
- [タグ]: この責任ある AI ダッシュボードにタグを追加します。
実験の構成が完了したら、[作成] を選択して、責任ある AI ダッシュボードの生成を開始します。 実験ページにリダイレクトされ、ジョブの完了時にジョブ ページの結果の責任ある AI ダッシュボードへのリンクが表示され、ジョブの進行状況が追跡できます。
責任ある AI ダッシュボードを表示して使用する方法については、「Azure Machine Learning スタジオで責任ある AI ダッシュボードを使用する」を参照してください。
責任ある AI のスコアカードを生成する方法 (プレビュー)
ダッシュボードを作成したら、Azure Machine Learning スタジオのコード不要 UI を使用して、責任ある AI スコアカードをカスタマイズして生成できます。 これにより、公平性や特徴量の重要度など、モデルの責任あるデプロイに関する重要な分析情報を、技術関係者や技術以外の関係者と共有できます。 ダッシュボードの作成と同様に、次の手順を使用してスコアカード生成ウィザードにアクセスできます。
- Azure Machine Learning スタジオの左側のナビゲーション バーから [モデル] タブに移動します。
- スコアカードを作成したい登録済みモデルを選択し、[責任ある AI] タブを選択します。
- 上部のパネルで、[責任ある AI 分析情報の作成 (プレビュー)] を選択し、[新しい PDF スコアカードを生成する] を選択します。
ウィザードを使用すると、コードに触れることなく PDF スコアカードをカスタマイズできます。 このエクスペリエンスは完全に Azure Machine Learning スタジオ内で実行され、スコアカードを設定するべきコンポーネントの選択を支援するガイド付きフローと指示テキストで、さまざまな UI の選択肢のコンテキストを確認することを支援します。 ウィザードは 7 つのステップに分かれています。8 番目のステップ (公平性評価) は、カテゴリの特徴を持つモデルにのみ表示されます。
- PDF スコアカードの概要
- モデル パフォーマンス
- ツールの選択
- データ分析 (以前のデータ エクスプローラー)
- 原因分析
- 解釈可能性
- 実験構成
- 公平性評価 (カテゴリの特徴が存在する場合のみ)
スコアカードの構成
まず、スコアカードのわかりやすいタイトルを入力します。 また、モデルの機能、トレーニングおよび評価の元となるデータ、アーキテクチャの種類などについて、省略可能な説明を入力することもできます。
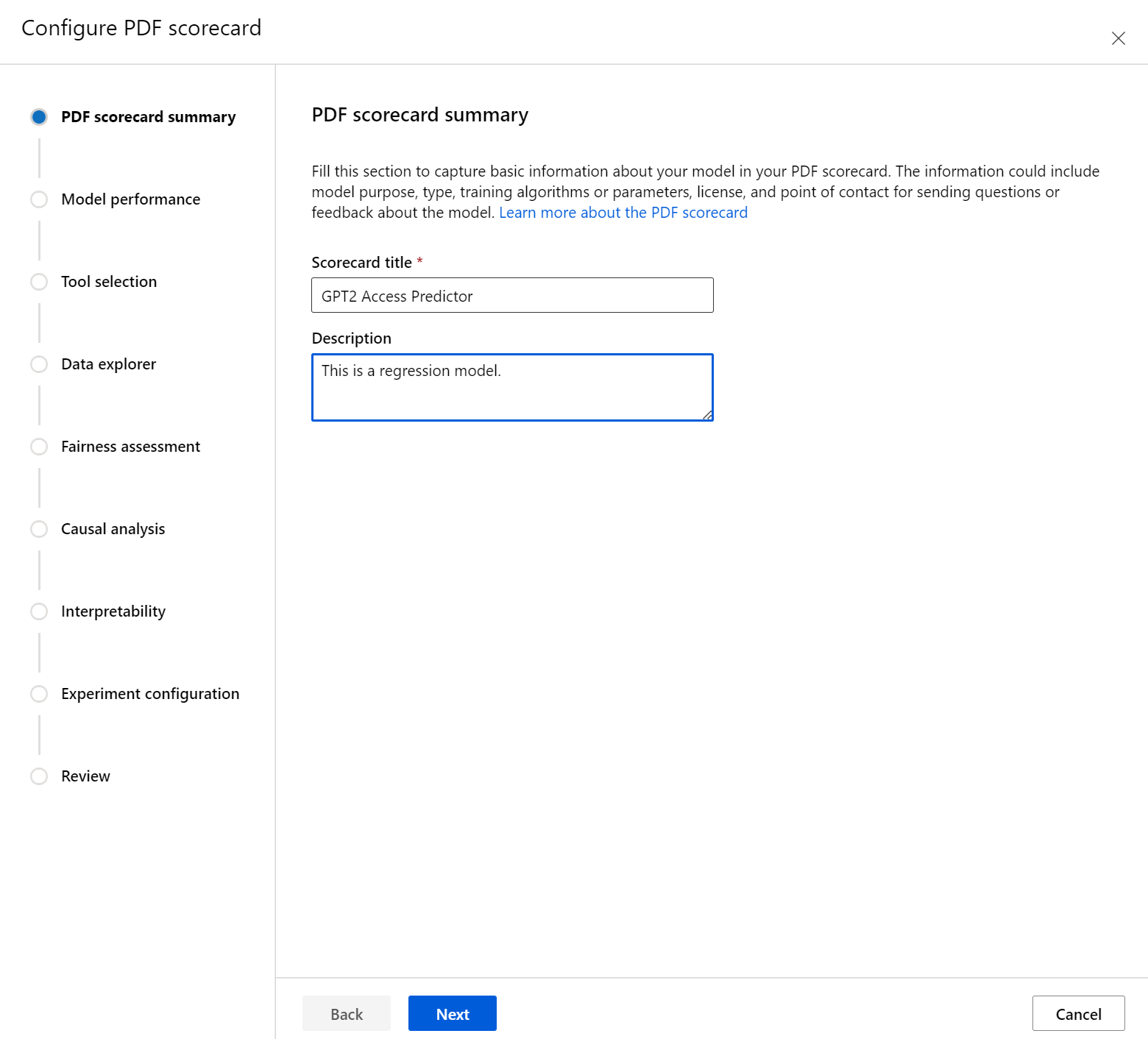
"モデルのパフォーマンス" セクションでは、スコアカードに業界標準モデル評価メトリックに組み込みながら、選択したメトリックに必要なターゲット値を設定できます。 ドロップダウンを使用して、目的のパフォーマンス メトリック (最大 3 つ) とターゲット値を選択します。
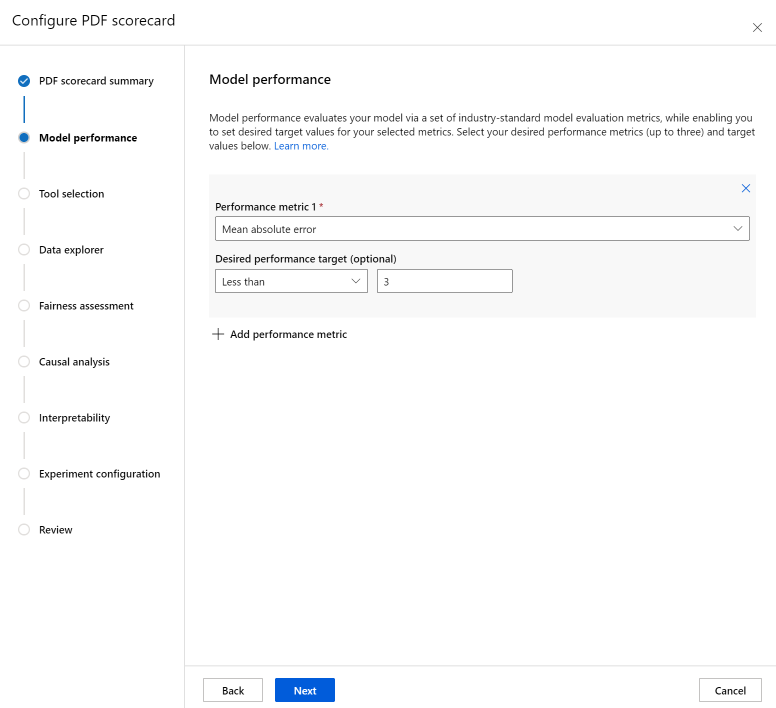
"ツールの選択" ステップでは、スコアカードに含める後続のコンポーネントを選択できます。 [スコアカードに含める] をオンにしてすべてのコンポーネントを含めるか、各コンポーネントを個別にオンまたはオフにします。 コンポーネントの横にある情報アイコン (円の中の "i") を選択して、コンポーネントの詳細を確認します。

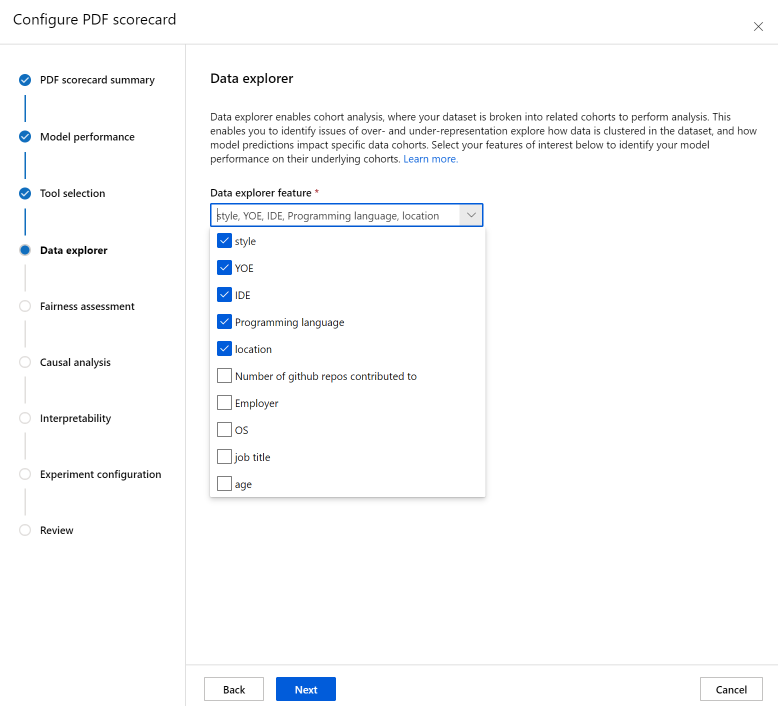
"データ分析" セクション (以前のデータ エクスプローラー) を使用すると、コーホート分析が可能になります。 ここでは、過大評価と過小評価の問題の特定や、データセット内のデータがどのようにクラスター化されているか、モデル予測が特定のデータ コーホートにどのように影響するかを調べることができます。 ドロップダウンのチェックボックスを使用して以下の必要な機能を選択し、基になるコーホートでのモデルのパフォーマンスを特定します。
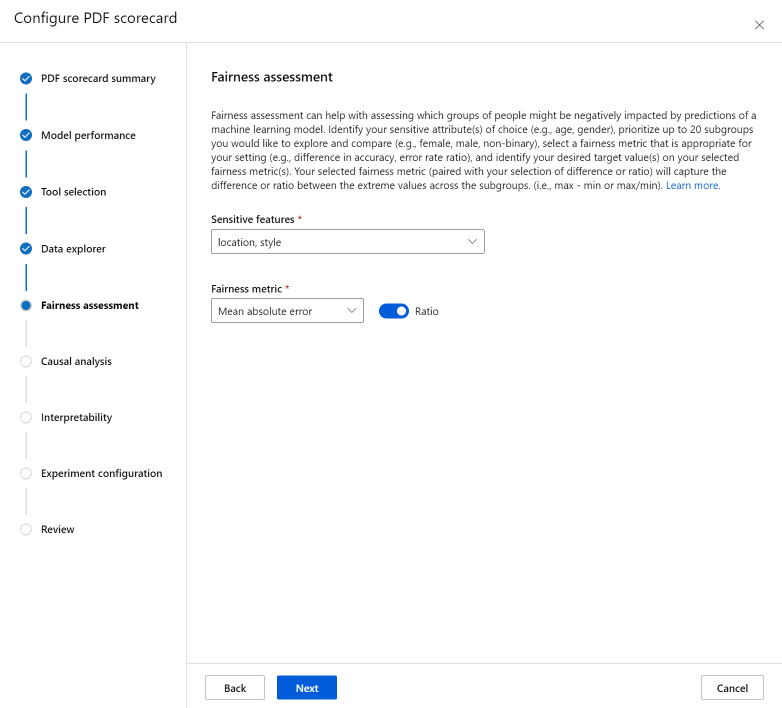
"公平性評価" セクションは、機械学習モデルの予測によって悪影響を受ける可能性のあるユーザーのグループを評価するのに役立ちます。 このセクションには 2 つのフィールドがあります。
センシティブ特徴: 調査して比較する最大 20 のサブグループに優先順位を付けることで、選択した機密性の高い属性 (年齢、性別など) を特定します。
公平性メトリック: 設定に適した公平性メトリック (精度の差、エラー率比など) を選択し、選択した公平性メトリックで目的のターゲット値を特定します。 選択した公平性メトリック (トグルを使用した差または比率の選択と組み合わせて) は、サブグループ全体の極値間の差または比率をキャプチャします。 (max - min または max/min)。
注意
公平性評価は現在、性別などのカテゴリに依存する属性でのみ使用できます。
"原因分析" セクションは、処理の変更が実際の結果にどのように影響するかについての実際的な "もしも...だったら" の質問に答えを与えます。 スコアカードを生成する、責任ある AI ダッシュボードで原因コンポーネントがアクティブ化されている場合は、これ以上の構成は必要ありません。

"解釈可能性" セクションでは、機械学習モデルによって行われた予測について、人間が理解できる説明を生成します。 モデルの説明を使用すると、モデルによって行われた決定の背後にある推論を理解できます。 以下の数値 (K) を選択して、モデル全体の予測に影響を与える K の重要な特徴を確認します。 K の既定値は 10 です。
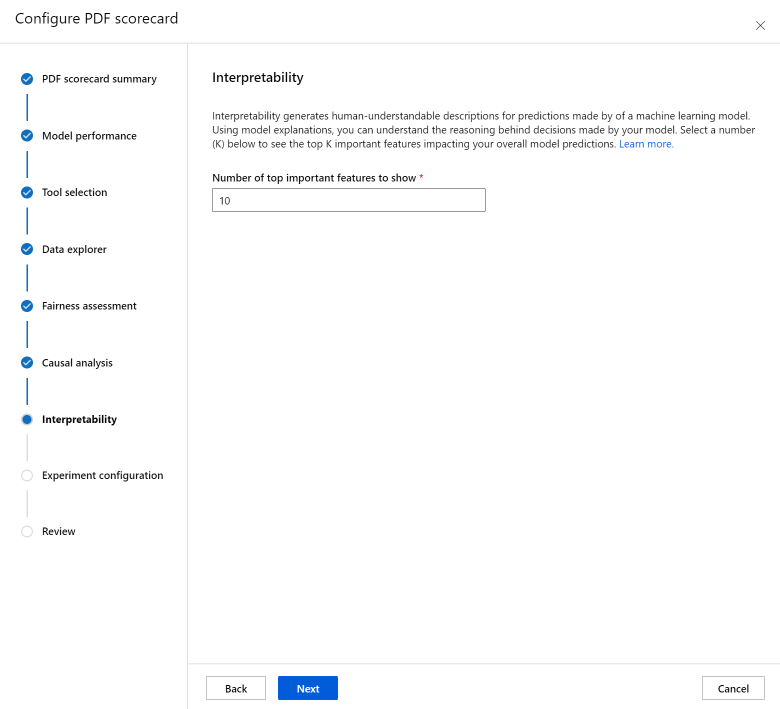
最後に、スコアカードを生成するジョブを開始するように実験を構成します。 これらの構成は、責任ある AI ダッシュボードの構成と同じです。
最後に、構成を確認し、[作成] を選択してジョブを開始します。

開始すると、ジョブの進行状況を追跡するため、実験ページにリダイレクトされます。 責任ある AI スコアカードを表示して使用する方法については、責任ある AI スコアカードの使用 (プレビュー) に関するページを参照してください。









次の手順
- 責任ある AI ダッシュボードを生成したら、Azure Machine Learning スタジオでそれにアクセスして使用する方法を確認します。
- 責任ある AI ダッシュボードの背後にある概念と手法の詳細について確認します。
- 責任を持ってデータを収集する方法の詳細を確認します。
- 責任ある AI ダッシュボードとスコアカードを使用してデータとモデルをデバッグし、この技術コミュニティのブログ投稿で、より良い意思決定を通知する方法について学習します。
- 実際の顧客事例で、責任ある AI ダッシュボードとスコアカードが英国の国民保健サービス (NHS) によってどのように使用されたかについて学習します。
- この対話型 AI ラボ Web デモを使用して、責任ある AI ダッシュボードの機能を確認します。