Azure Data Factory からバッチ エンドポイントを実行する
適用対象: Azure CLI ML 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
Azure CLI ML 拡張機能 v2 (現行)Python SDK azure-ai-ml v2 (現行)
ビッグ データには、これらの膨大な量の生データをアクションにつながるビジネス分析へと精製するプロセスを統合および運用化できるサービスが必要です。 マネージド クラウド サービスである Azure Data Factory が、これらの複雑でハイブリッドな抽出-変換-読み込み (ETL)、抽出-読み込み-変換 (ELT) およびデータ統合プロジェクトを処理します。
Azure Data Factory を使うと、複数のデータ変換を調整し、1 つのユニットとして管理できるパイプラインを作成できます。 バッチ エンドポイントは、そのような処理ワークフローのステップになる優れた候補です。
この記事では、Web 呼び出しアクティビティと REST API を利用して、Azure Data Factory アクティビティでバッチ エンドポイントを使う方法について説明します。
ヒント
Fabric でデータ パイプラインを使用する場合は、Azure Machine Learning アクティビティを使用してバッチ エンドポイントを直接呼び出すことができます。 最新の機能を活用するために、可能な限り Fabric をデータのオーケストレーションに使用することをお勧めします。 Azure Data Factory の Azure Machine Learning アクティビティは、Azure Machine Learning V1 の資産でのみ動作します。 詳細については、「バッチ エンドポイント (プレビュー) を使用して、Fabric から Azure Machine Learning モデルを実行する」を参照してください。
前提条件
バッチ エンドポイントにデプロイされたモデル。 「バッチ デプロイでの MLflow モデルの使用」 で作成したハート条件分類子を使用します。
Azure Data Factory リソース。 データ ファクトリを作成するには、「クイックスタート: Azure portal を使用してデータ ファクトリを作成する」の手順を実行します。
データ ファクトリを作成したら、Azure portal でデータ ファクトリを参照し、[スタジオの起動] を選択します。
![Azure Data Factory のホーム ページのスクリーンショット。[Azure Data Factory を開く] と [スタジオの起動] ラベルが強調表示されています。](media/how-to-use-batch-adf/data-factory-home-page.png?view=azureml-api-2)
![Azure Data Factory のホーム ページのスクリーンショット。[Azure Data Factory を開く] と [スタジオの起動] ラベルが強調表示されています。](media/how-to-use-batch-adf/data-factory-home-page.png?view=azureml-api-2#lightbox)
バッチ エンドポイントに対して認証する
Azure Data Factory は、Web 呼び出しアクティビティを使うことで、バッチ エンドポイントの REST API を呼び出すことができます。 バッチ エンドポイントは、認可に Microsoft Entra ID をサポートしており、API に対する要求には適切な認証処理が必要です。 詳細については、「Azure Data Factory と Azure Synapse Analytics の Web アクティビティ」を参照してください。
サービス プリンシパルまたはマネージド ID を使って、バッチ エンドポイントに対する認証を行うことができます。 シークレットを簡単に使用できるので、マネージド ID を使うことをお勧めします。
Azure Data Factory のマネージド ID を使って、バッチ エンドポイントと通信できます。 この場合に必要なのは、Azure Data Factory リソースがマネージド ID を使ってデプロイされたことを確認することだけです。
Azure Data Factory リソースがない場合、またはマネージド ID なしで既にデプロイを行った場合は、システム割り当てマネージド IDの手順を実行し、作成します。
注意事項
デプロイ後に Azure Data Factory のリソース ID を変更することはできません。 作成後にリソースの ID を変更する必要がある場合は、リソースを再作成する必要があります。
デプロイ後、Azure Machine Learning ワークスペースに作成したリソースのマネージド ID へのアクセス権を付与します。 「アクセス権を付与する方法」を参照してください。 この例では、サービス プリンシパルに次のものが必要です。
- バッチ デプロイを読み取り、それらに対してアクションを実行するためのワークスペース内のアクセス許可。
- データ ストアの読み取りと書き込みを行うアクセス許可。
- データ入力として示されている任意のクラウドの場所 (ストレージ アカウント) で読み取りを行うアクセス許可。
パイプラインについて
この例では、何らかのデータについて特定のバッチ エンドポイントを呼び出すことができるパイプラインを Azure Data Factory で作成します。 そのパイプラインは、REST を使って Azure Machine Learning バッチ エンドポイントと通信します。 バッチ エンドポイントの REST API を使用する方法の詳細については、「バッチ エンドポイント用のジョブと入力データの作成」を参照してください。
パイプラインは次のようになります。

パイプラインには、次のアクティビティが含まれています。
バッチ エンドポイントの実行: バッチ エンドポイントの URI を使ってそれを呼び出す Web アクティビティ。 データが配置されている入力データ URI と、必要な出力ファイルを渡します。
ジョブの待機: 作成されたジョブの状態をチェックし、Completed または Failed として完了するのを待機するループ アクティビティです。 このアクティビティからは、次のアクティビティが使われます。
- 状態のチェック: バッチ エンドポイントの実行アクティビティの応答として返されたジョブ リソースの状態を照会する Web アクティビティ。
- 待機: ジョブの状態のポーリング頻度を制御する待機アクティビティ。 既定値の 120 (2 分) を設定します。
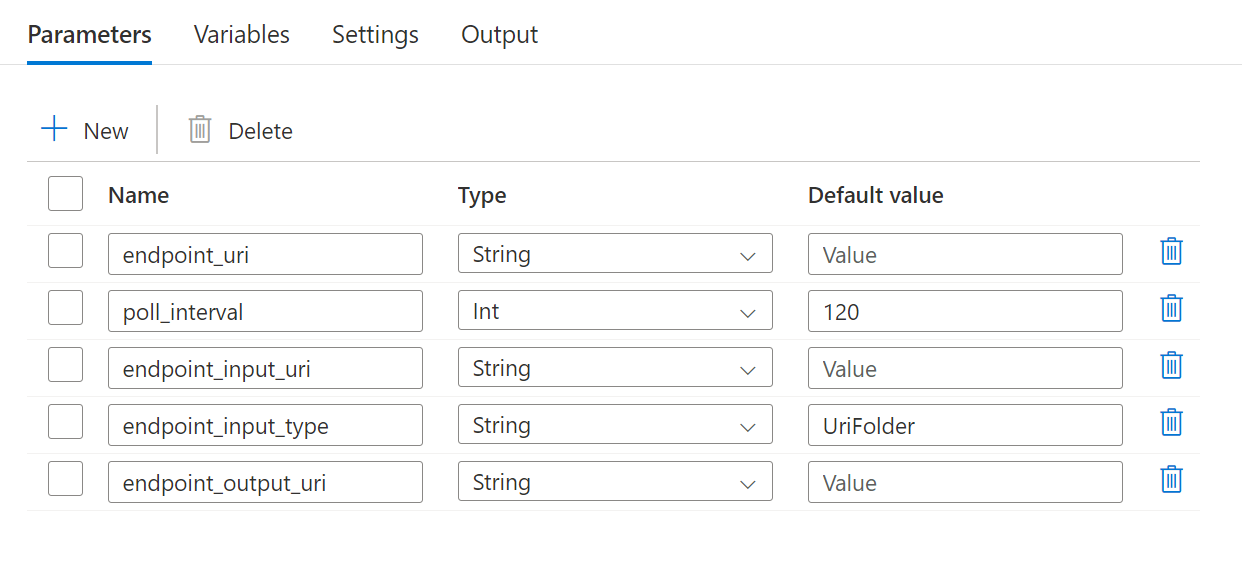
パイプラインでは、次のパラメーターを構成する必要があります。
| パラメーター | 説明 | 値の例 |
|---|---|---|
endpoint_uri |
エンドポイント スコアリング URI | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
ジョブの完了状態をチェックするまで待機する秒数。 既定値は 120 です。 |
120 |
endpoint_input_uri |
エンドポイントの入力データ。 複数の種類のデータ入力がサポートされています。 ジョブの実行に使用するマネージド ID が、基になる場所にアクセスできることを確認します。 または、データ ストアを使用する場合は、資格情報がそこで示されていることを確認します。 | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
指定する入力データの種類。 現在、バッチ エンドポイントではフォルダー (UriFolder) とファイル (UriFile) がサポートされています。 既定値は UriFolder です。 |
UriFolder |
endpoint_output_uri |
エンドポイントの出力データ ファイル。 Machine Learning ワークスペースにアタッチされているデータ ストア内の出力ファイルへのパスである必要があります。 他の種類の URI はサポートされていません。 workspaceblobstore という名前の既定の Azure Machine Learning データ ストアを使用できます。 |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

警告
endpoint_output_uri は、まだ存在しないファイルへのパスである必要があります。 その場合、パスが既に存在する旨のエラーが発生し、ジョブは失敗します。
パイプラインを作成する
既存の Azure Data Factory でこのパイプラインを作成してバッチ エンドポイントを呼び出すには、次の手順を行います。
バッチ エンドポイントが実行されているコンピューティングに、Azure Data Factory が入力として指定するデータをマウントするためのアクセス許可があることを確認します。 エンドポイントを呼び出すエンティティが、引き続きアクセスを許可します。
この場合は、Azure Data Factory が該当します。 ただし、バッチ エンドポイントが実行されるコンピューティングには、Azure Data Factory が指定するストレージ アカウントをマウントするためのアクセス許可が必要です。 詳しくは、「ストレージ サービスへのアクセス」をご覧ください。
Azure Data Factory Studio を開きます。 鉛筆アイコンを選択して [作成者] ウィンドウを開き、[ファクトリ リソース] でプラス記号を選択します。
[パイプライン]>[パイプライン テンプレートからインポートする] を選びます。
..zip ファイルを選択します。
パイプラインのプレビューがポータルに表示されます。 このテンプレートを使用する を選択します。
Run-BatchEndpoint という名前で、パイプラインが自動的に作成されます。
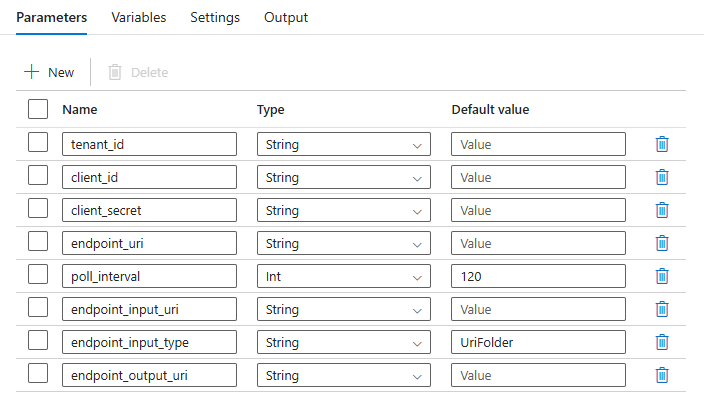
バッチ デプロイのパラメーターを構成します。
警告
ジョブを送信する前に、バッチ エンドポイントに既定のデプロイが構成されていることを確認します。 作成されたパイプラインによってエンドポイントが呼び出されます。 既定のデプロイを作成して構成する必要があります。
ヒント
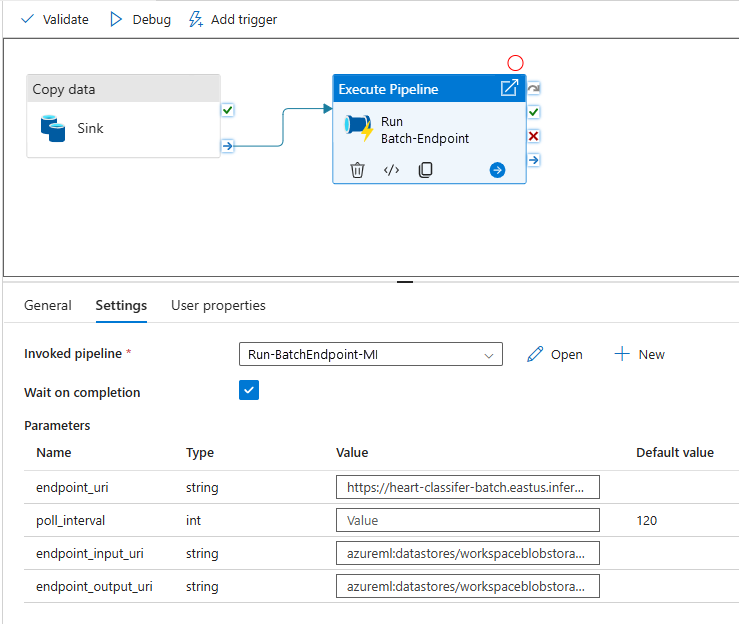
再利用性を最大限に高めるには、作成したパイプラインをテンプレートとして使い、パイプラインの実行アクティビティを使って他の Azure Data Factory パイプライン内から呼び出します。 その場合は、次の図に示すように、内部パイプラインでパラメーターを構成するのではなく、外側パイプラインからパラメーターとして渡します。
パイプラインを使用する準備ができました。
制限事項
Azure Machine Learning のバッチ デプロイを使用するときは、次の制限を考慮してください。
データ入力
- 入力としてサポートされるのは、Azure Machine Learning データ ストアまたは Azure ストレージ アカウント (Azure Blob Storage、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2) のみです。 入力データが別のソースにある場合は、バッチ ジョブの実行前に Azure Data Factory の Copy アクティビティを使って、互換性のあるストアにデータをシンクします。
- バッチ エンドポイント ジョブでは、入れ子になったフォルダーを探索しません。 入れ子になったフォルダー構造では機能しません。 データが複数のフォルダーに分散されている場合は、構造をフラット化する必要があります。
- デプロイで指定したスコアリング スクリプトが、ジョブにフィードされると予想されるデータを処理できることを確認します。 モデルが MLflow の場合、サポートされるファイルの種類に関する制限事項については、「バッチ デプロイでの MLflow モデルのデプロイ」を参照してください。
データ出力
- サポートされているのは、登録された Azure Machine Learning データ ストアのみです。 Azure Data Factory が Azure Machine Learning のデータ ストアとして使用しているストレージ アカウントを登録することをお勧めします。 そうすることで、読み取っているのと同じストレージ アカウントに書き戻すことができます。
- 出力では、Azure Blob Storage アカウントのみがサポートされます。 たとえば、Azure Data Lake Storage Gen2 はバッチ デプロイ ジョブの出力としてサポートされていません。 使用するデータを別の場所またはシンクに出力する必要がある場合は、バッチ ジョブを実行した後で、Azure Data Factory の Copy アクティビティを使います。