MLflow と Azure Machine Learning を使用して ML モデルを追跡する
適用対象:  Python SDK azureml v1
Python SDK azureml v1
このアーティクルでは、MLflow Tracking を有効にして、MLflow 実験のバックエンドとして Azure Machine Learning に接続する方法について説明します。
MLflow は、機械学習の実験のライフサイクルを管理するためのオープンソース ライブラリです。 MLFlow Tracking は MLflow のコンポーネントです。これは、実験の環境がローカル コンピューター、リモートのコンピューティング先、仮想マシン、Azure Databricks クラスターのいずれであるかにかかわらず、トレーニング実行のメトリックとモデル成果物をログに記録し、追跡します。
MLflow プロジェクトのサポート (プレビュー) やモデル デプロイなど、サポートされているすべての MLflow および Azure Machine Learning 機能については、「MLflow と Azure Machine Learning」を参照してください。
ヒント
Azure Databricks または Azure Synapse Analytics で実行されている実験を追跡する場合は、専用のアーティクルMLflow と Azure Machine Learning を使用した Azure Databricks ML 実験の追跡またはMLflow と Azure Machine Learning を使用した Azure Synapse Analytics ML 実験の追跡を参照してください。
注意
このドキュメントの情報は主に、モデルのトレーニング プロセスを監視したいデータ サイエンティストや開発者を対象としています。 Azure Machine Learning からリソース使用状況やイベント (クォータ、トレーニング ジョブの完了、モデル デプロイの完了など) を監視することに関心がある管理者の方は、Azure Machine Learning の監視を参照してください。
前提条件
mlflowパッケージをインストールします。- SQL ストレージ、サーバー、UI、またはデータ サイエンスの依存関係のない軽量 MLflow パッケージである MLflow Skinny を使用できます。 主に追跡機能とログ機能を必要とし、デプロイを含む MLflow の全機能はインポートしないユーザーには、これが推奨されます。
azureml-mlflowパッケージをインストールします。Azure Machine Learning CLI (v1) をインストールして設定します。必ず、ml 拡張機能をインストールします。
重要
この記事の Azure CLI コマンドの一部では、Azure Machine Learning 用に
azure-cli-ml、つまり v1 の拡張機能を使用しています。 v1 拡張機能のサポートは、2025 年 9 月 30 日に終了します。 その日付まで、v1 拡張機能をインストールして使用できます。2025 年 9 月 30 日より前に、
ml(v2) 拡張機能に移行することをお勧めします。 v2 拡張機能の詳細については、Azure ML CLI 拡張機能と Python SDK v2 に関するページを参照してください。Azure Machine Learning SDK for Python をインストールして設定します。
ローカル コンピューターまたはリモート コンピューティングからの実行を追跡する
Azure Machine Learning で MLflow を使用して追跡すると、ローカル コンピューターで実行された、ログに記録されたメトリックと成果物の実行を Azure Machine Learning ワークスペースに保存できます。
追跡環境を設定する
Azure Machine Learning コンピューティングで実行されていない実行 (以降、ローカル コンピューティング と呼ぶ) を追跡するには、ローカル コンピューティングを Azure Machine Learning MLflow 追跡 URI にポイントする必要があります。
Note
Azure Compute (Azure Notebooks、Azure Compute Instances または Compute Clusters でホストされている Jupyter Notebook) で実行する場合、追跡 URI を構成する必要はありません。 これは、自動的に構成されます。
適用対象: Python SDK azureml v1
Azure Machine Learning MLflow 追跡 URI は、Azure Machine Learning SDK v1 for Python を使って取得できます。 使用しているクラスターにライブラリ azureml-sdk がインストールされていることを確認します。 次の例では、ワークスペースに関連付けられている一意の MLFLow 追跡 URI を取得します。 次に、メソッド set_tracking_uri() では、MLflow 追跡 URI をその URI にポイントします。
ワークスペース構成ファイルを使用する
from azureml.core import Workspace import mlflow ws = Workspace.from_config() mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())ヒント
ワークスペース構成ファイルは、次の方法でダウンロードできます。
- Azure Machine Learning スタジオに移動します
- ページの右上 -> [構成ファイルのダウンロード] の順にクリックします。
- 作業しているのと同じディレクトリにファイル
config.jsonを保存します。
サブスクリプション ID、リソース グループ名、ワークスペース名を使用する
from azureml.core import Workspace import mlflow #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace_name = '<AZUREML_WORKSPACE_NAME>' ws = Workspace.get(name=workspace_name, subscription_id=subscription_id, resource_group=resource_group) mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
実験名を設定する
すべての MLflow 実行は、アクティブな実験にログが記録されます。 既定では、実行のログは、自動的に作成される Default という名前の実験に記録されます。 作業する実験を構成するには、MLflow コマンド mlflow.set_experiment() を使用します。
experiment_name = 'experiment_with_mlflow'
mlflow.set_experiment(experiment_name)
ヒント
Azure Machine Learning SDK を使用してジョブを送信する場合は、送信時にプロパティ experiment_name を使用して実験名を設定できます。 トレーニング スクリプトでそれを構成する必要はありません。
トレーニング実行を開始する
MLflow の実験名を設定したら、start_run() でトレーニング実行を開始できます。 次に、log_metric() を使用して MLflow ログ API をアクティブにし、トレーニング実行のメトリックのログ記録を開始します。
import os
from random import random
with mlflow.start_run() as mlflow_run:
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
MLflow を使用して実行でメトリック、パラメーター、成果物をログに記録する方法の詳細については、メトリックをログに記録して表示する方法に関する記事を参照してください。
Azure Machine Learning で実行されている実行を追跡する
適用対象: Python SDK azureml v1
リモート実行 (ジョブ) を使用すると、より堅牢で反復的な方法でモデルをトレーニングできます。 また、Machine Learning コンピューティング クラスターなど、より強力なコンピューティングを活用することもできます。 さまざまなコンピューティング オプションについては、「モデル トレーニング用のコンピューティング ターゲットを使用する」をご覧ください。
実行を送信すると、実行が実行されているワークスペースで動作するように MLflow が Azure Machine Learning によって自動的に構成されます。 つまり、MLflow 追跡 URI を構成する必要はありません。 その上、実験の送信の詳細に基づいて自動的に実験に名前が付けられます。
重要
トレーニング ジョブを Azure Machine Learning に送信する際に、トレーニング ロジックで MLflow 追跡 URI を構成する必要はありません (自動で既に構成されているため)。 また、トレーニング ルーチンで実験名を構成する必要もありません。
トレーニング ルーチンを作成する
まず、src サブディレクトリを作成し、src サブディレクトリ内の train.py ファイルにトレーニング コードを含むファイルを作成する必要があります。 すべてのトレーニング コードは、src サブディレクトリ (train.py を含む) に入ります。
トレーニング コードは、Azure Machine Learning サンプル リポジトリにあるこの MLfLow の例から取得されます。
そのファイルにこのコードをコピーします。
# imports
import os
import mlflow
from random import random
# define functions
def main():
mlflow.log_param("hello_param", "world")
mlflow.log_metric("hello_metric", random())
os.system(f"echo 'hello world' > helloworld.txt")
mlflow.log_artifact("helloworld.txt")
# run functions
if __name__ == "__main__":
# run main function
main()
実験を構成する
Python を使用して実験を Azure Machine Learning に送信する必要があります。 ノートブックまたは Python ファイルで、Environment クラスを使用してコンピューティングとトレーニングの実行環境を構成します。
from azureml.core import Environment
from azureml.core.conda_dependencies import CondaDependencies
env = Environment(name="mlflow-env")
# Specify conda dependencies with scikit-learn and temporary pointers to mlflow extensions
cd = CondaDependencies.create(
conda_packages=["scikit-learn", "matplotlib"],
pip_packages=["azureml-mlflow", "pandas", "numpy"]
)
env.python.conda_dependencies = cd
次に、コンピューティング先としてリモート コンピューティングを使用して ScriptRunConfig を構築します。
from azureml.core import ScriptRunConfig
src = ScriptRunConfig(source_directory="src",
script=training_script,
compute_target="<COMPUTE_NAME>",
environment=env)
このコンピューティングおよびトレーニングの実行構成では、Experiment.submit() メソッドを使用して実行を送信します。 この方法により、MLflow の追跡 URI が自動的に設定され、MLflow からワークスペースにログが送信されます。
from azureml.core import Experiment
from azureml.core import Workspace
ws = Workspace.from_config()
experiment_name = "experiment_with_mlflow"
exp = Experiment(workspace=ws, name=experiment_name)
run = exp.submit(src)
ワークスペースでのメトリックと成果物の表示
MLflow ログ記録のメトリックと成果物は、お使いのワークスペースで追跡されます。 それらを随時表示するには、Azure Machine Learning Studio でワークスペースに移動し、ワークスペースで名前によって実験を見つけます。 または、次のコードを実行します。
MLflow get_run() を使用して実行メトリックを取得します。
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
run_id = mlflow_run.info.run_id
finished_mlflow_run = MlflowClient().get_run(run_id)
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
print(metrics,tags,params)
実行の成果物を表示するには、MlFlowClient.list_artifacts() を使用できます
client.list_artifacts(run_id)
現在のディレクトリに成果物をダウンロードするには、MLFlowClient.download_artifacts() を使用できます
client.download_artifacts(run_id, "helloworld.txt", ".")
MLflow を使用して Azure Machine Learning の実験と実行から情報を取得する方法の詳細については、「MLflow を使用して実験と実行を管理する」を参照してください。
比較とクエリ
次のコードを使用して、Azure Machine Learning ワークスペースですべての MLflow 実行を比較してクエリを実行します。 MLflow で実行のクエリを実行する方法の詳細を確認してください。
from mlflow.entities import ViewType
all_experiments = [exp.experiment_id for exp in MlflowClient().list_experiments()]
query = "metrics.hello_metric > 0"
runs = mlflow.search_runs(experiment_ids=all_experiments, filter_string=query, run_view_type=ViewType.ALL)
runs.head(10)
自動ログ記録
Azure Machine Learning および MLFlow を使用すると、モデルのトレーニング時に、メトリック、モデル パラメーター、モデル成果物を自動的にログに記録できます。 さまざまな人気の高い機械学習ライブラリがサポートされています。
自動ログ記録を有効にするには、トレーニング コードの前に次のコードを挿入します。
mlflow.autolog()
MLflow による自動ログ記録の詳細情報を参照してください。
モデルを管理する
MLflow モデル レジストリをサポートする Azure Machine Learning モデル レジストリにモデルを登録して追跡します。 Azure Machine Learning モデルは、MLflow モデル スキーマに対応しているため、これらのモデルをさまざまなワークフロー間で容易にエクスポートおよびインポートすることができます。 実行 ID などの MLflow 関連のメタデータは、追跡可能性のために登録されたモデルとともに追跡されます。 ユーザーは、トレーニングの実行を送信し、MLflow の実行から生成されたモデルを登録およびデプロイすることができます。
運用準備が整ったモデルを 1 つの手順でデプロイおよび登録したい場合は、「MLflow モデルのデプロイと登録」を参照してください。
実行からのモデルを登録して表示するには、次の手順に従います。
実行が完了したら、
register_model()メソッドを呼び出します。# the model folder produced from a run is registered. This includes the MLmodel file, model.pkl and the conda.yaml. model_path = "model" model_uri = 'runs:/{}/{}'.format(run_id, model_path) mlflow.register_model(model_uri,"registered_model_name")Azure Machine Learning Studio を使用してワークスペースに登録されたモデルを表示します。
次の例では、登録されたモデル
my-modelの MLflow 追跡メタデータがタグ付けされています。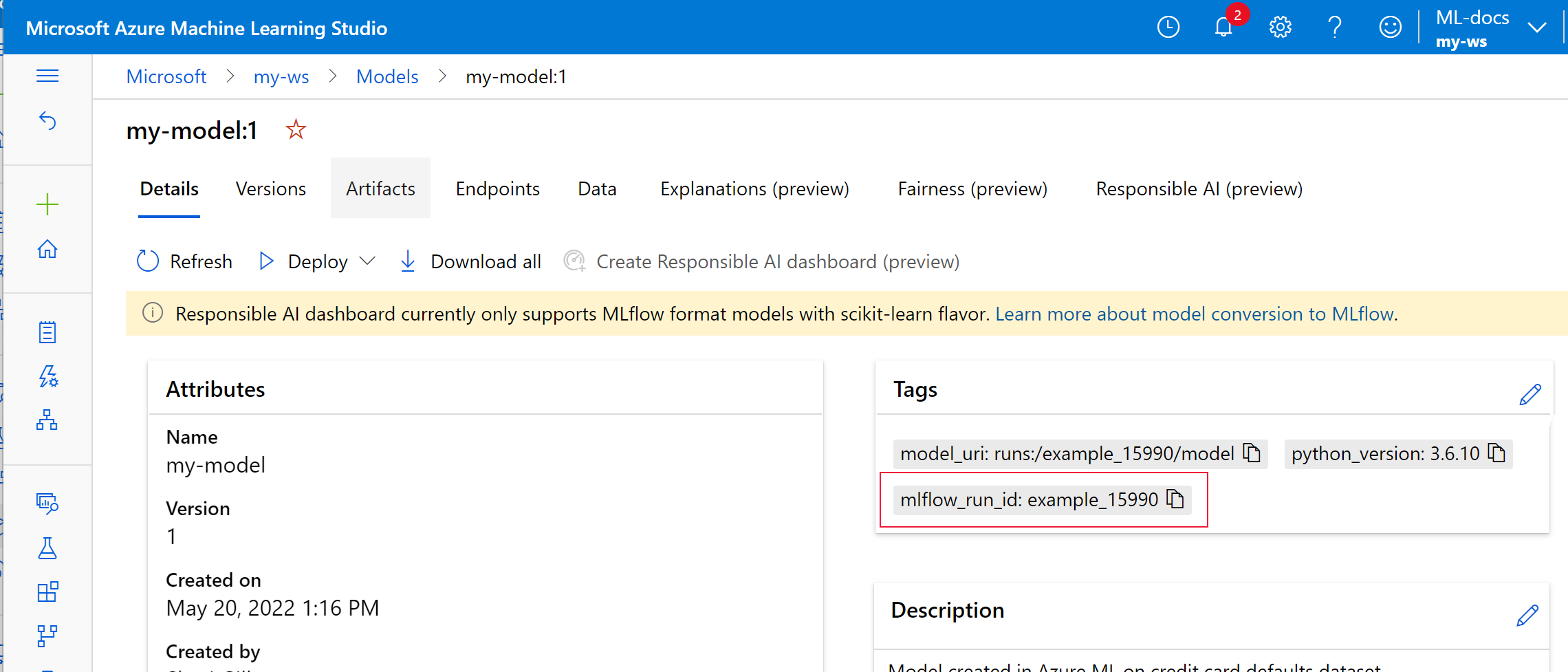
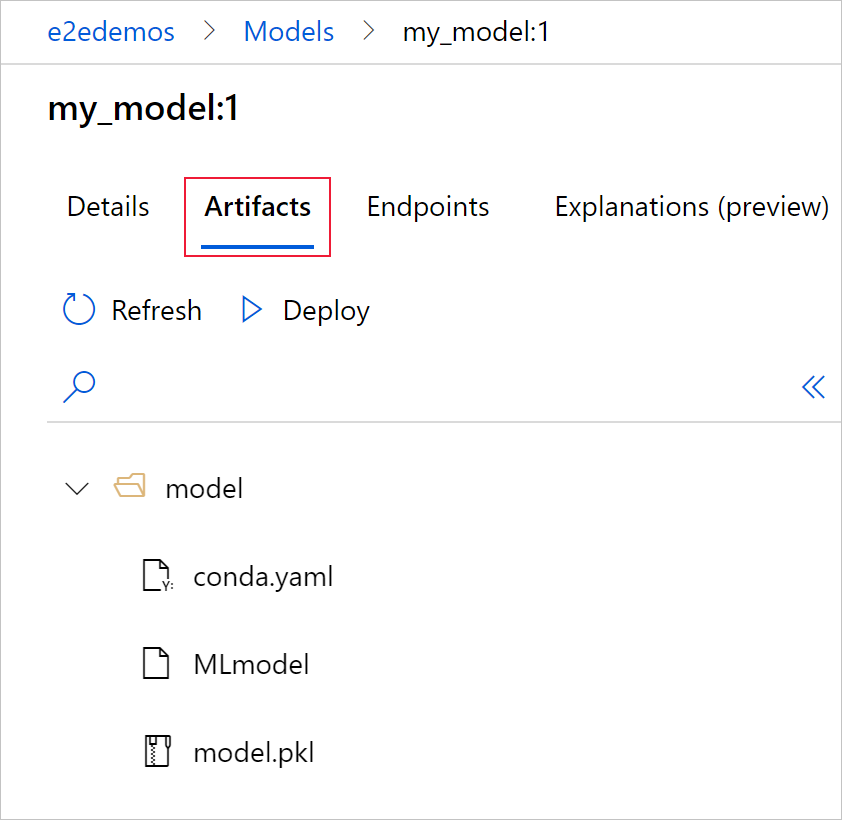
[成果物] タブを選択すると、MLflow モデル スキーマ (conda.yaml、MLmodel、model.pkl) に対応するすべてのモデル ファイルが表示されます。
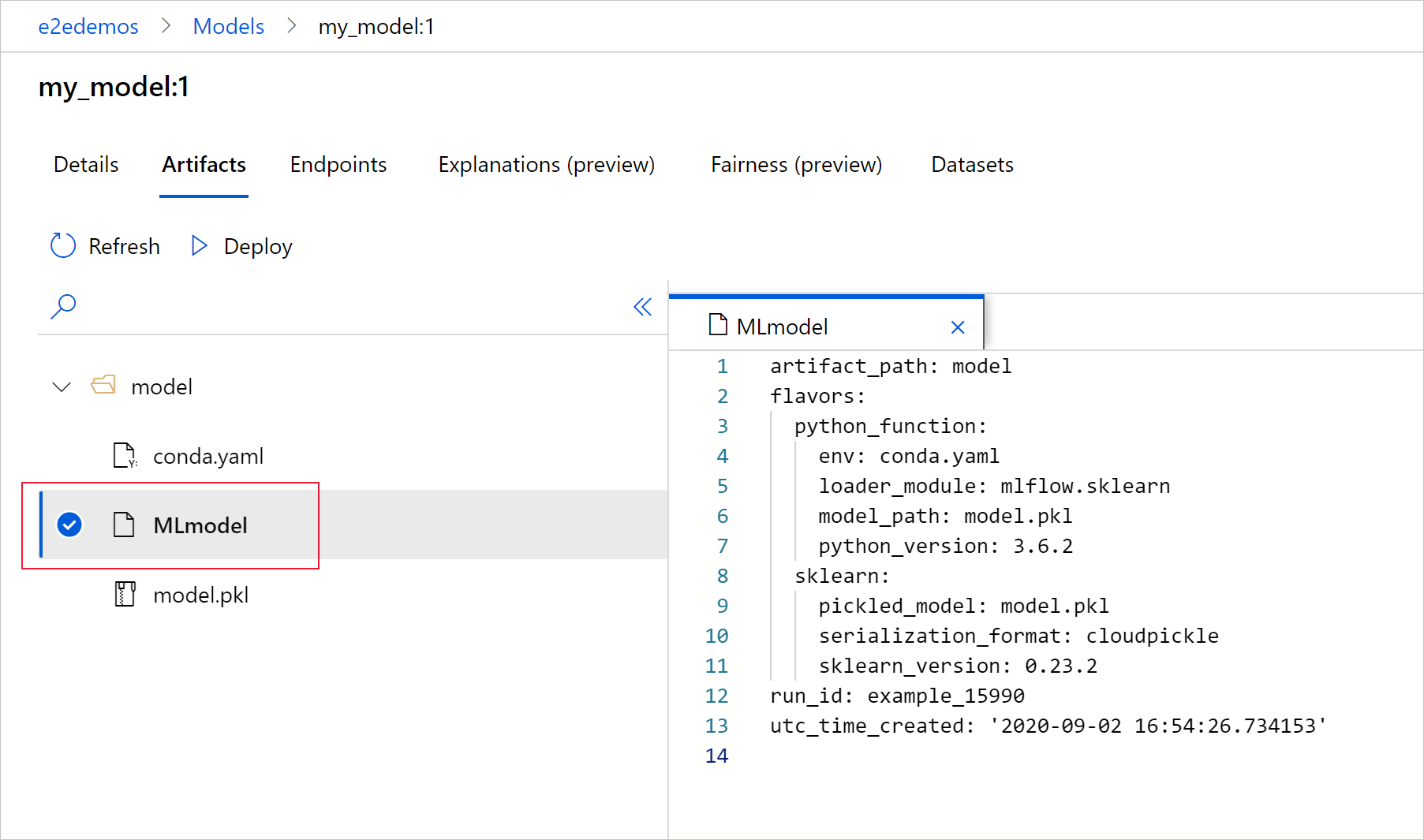
[MLmodel] を選択すると、実行によって生成された MLmodel ファイルが表示されます。
リソースをクリーンアップする
ログに記録されたメトリックと成果物をワークスペースで使用する予定がない場合、現時点では、それらを個別に削除する機能は提供されていません。 代わりに、ストレージ アカウントとワークスペースを含むリソース グループを削除すれば、課金は発生しません。
Azure Portal で、左端にある [リソース グループ] を選択します。
作成したリソース グループを一覧から選択します。
[リソース グループの削除] を選択します。
リソース グループ名を入力します。 次に、 [削除] を選択します。
サンプルの Notebook
Azure Machine Learning ノートブックでの MLflow は、この記事で提示した概念を示し、さらに詳しく説明します。 コミュニティ主導のリポジトリである AzureML-Examples も参照してください。
次のステップ
- MLflow を使用してモデルをデプロイします。
- データの誤差について実稼働モデルを監視します。
- MLflow を使用して Azure Databricks 実行を追跡する。
- モデルを管理します。