Azure Machine Learning スタジオでプロンプト フロー コンピューティング セッションを管理する
プロンプト フロー コンピューティング セッションでは、必要なすべての依存関係パッケージを含む Docker イメージなど、アプリケーションの実行に必要なコンピューティング リソースが提供されます。 この信頼性が高くスケーラブルな環境により、プロンプト フローはシームレスなユーザー エクスペリエンスのためのタスクと機能を効率的に実行できます。
コンピューティング セッション管理のアクセス許可とロール
ロールを割り当てるには、リソースに対する owner または Microsoft.Authorization/roleAssignments/write アクセス許可を持っている必要があります。
コンピューティング セッションのユーザーに、ワークスペースで AzureML Data Scientist ロールを割り当てます。 詳しくは、「Azure Machine Learning ワークスペースへのアクセスの管理」をご覧ください。
ロールの割り当てが有効になるまで、数分かかる場合があります。
スタジオでコンピューティング セッションを開始する
Azure Machine Learning スタジオを使用してコンピューティング セッションを開始する前に、次の点を確認してください。
- ワークスペースでの
AzureML Data Scientistロールを持っている。 - ワークスペースの既定のデータ ストア (通常は
workspaceblobstore) の種類が BLOB である。 - 作業ディレクトリ (
workspaceworkingdirectory) がワークスペースに存在する。 - プロンプト フローに仮想ネットワークを使う場合は、「プロンプト フローでのネットワークの分離」での考慮事項を理解している。
フロー ページでコンピューティング セッションを開始する
1 つのフローが 1 つのコンピューティング セッションにバインドされます。 フロー ページでコンピューティング セッションを開始できます。
開始を選択します。 フロー フォルダーの
flow.dag.yamlで定義されている環境を使用してコンピューティング セッションを始めます。これは、ワークスペースに十分なクォータがある、サーバーレス コンピューティングの仮想マシン (VM) サイズで実行されます。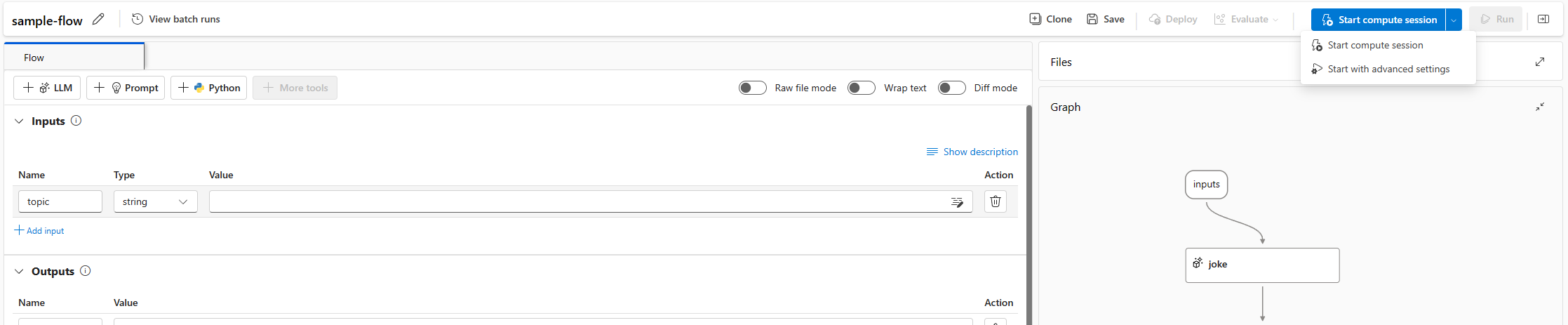
[詳細設定から始める] を選択します。 詳細設定では、次のことを実行できます。
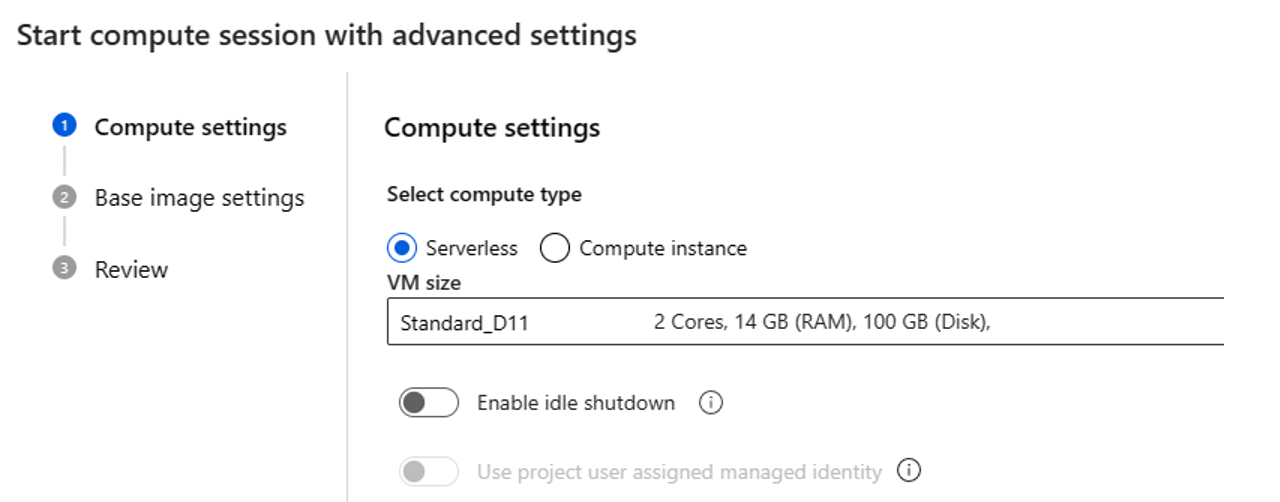
- コンピューティングの種類を選択します。 サーバーレス コンピューティングとコンピューティング インスタンスのどちらかを選択できます。
サーバーレス コンピューティングを選択する場合は、次のように設定します。
- コンピューティング セッションで使用する VM サイズをカスタマイズします。 VM シリーズ D 以降を選択します。 詳細については、サポートされている VM シリーズとサイズに関するセクションを参照してください
- アイドル時間をカスタマイズします。この時間中、コンピューティング セッションがしばらく使用されないと、セッションは自動的に削除されます。
- ユーザー割り当てマネージド ID を設定する。 コンピューティング セッションではこの ID を使用して基本イメージをプルし、接続を使って認証し、パッケージをインストールします。 ユーザー割り当てマネージド ID に十分なアクセス許可があることを確認します。 この ID を設定しない場合は、既定でユーザー ID を使用します。
- 次の CLI コマンドを使用して、ユーザー割り当てマネージド ID をワークスペースに割り当てることができます。 ワークスペースのユーザー割り当て ID を作成および更新する方法の詳細を確認してください。
az ml workspace update -f workspace_update_with_multiple_UAIs.yml --subscription <subscription ID> --resource-group <resource group name> --name <workspace name>workspace_update_with_multiple_UAIs.yml の内容は、次のようになります。
identity: type: system_assigned, user_assigned user_assigned_identities: '/subscriptions/<subscription_id>/resourcegroups/<resource_group_name>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<uai_name>': {} '<UAI resource ID 2>': {}ヒント
Azure Machine Learning ワークスペースがワークスペースに関連するリソースのデータにアクセスするには、ユーザー割り当てマネージド ID に次の Azure RBAC のロールの割り当てが必要になります。
リソース 権限 Azure Machine Learning ワークスペース Contributor Azure Storage 共同作成者 (コントロール プレーン) + ストレージ BLOB データ共同作成者 + ストレージ ファイル データ特権共同作成者 (データ プレーン、ファイル共有のフロー ドラフトと BLOB 内のデータの使用) Azure Key Vault (アクセス ポリシーのアクセス許可モデルを使用する場合) 共同作成者 + 消去操作以外のすべてのアクセス ポリシーのアクセス許可。これはリンクされた Azure Key Vault の既定モードです。 Azure Key Vault (RBAC アクセス許可モデルを使用する場合) 共同作成者 (コントロール プレーン) + Key Vault 管理者 (データ プレーン) Azure Container Registry Contributor Azure Application Insights Contributor Note
ジョブの送信者には、ユーザー割り当てマネージド ID に対する
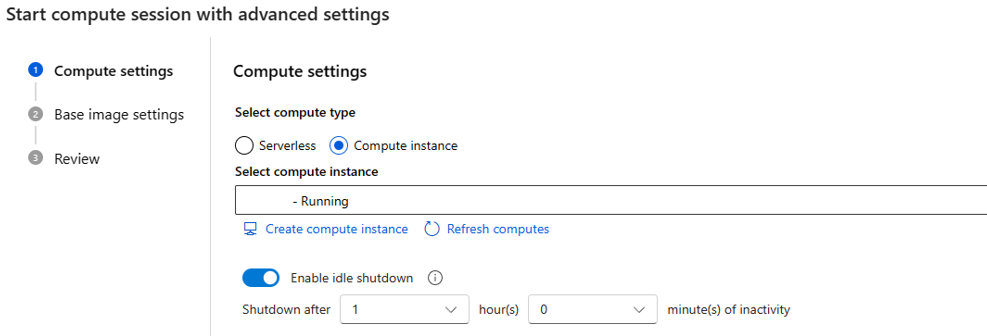
assignアクセス許可が必要です。Managed Identity Operatorロールを割り当てることができます。サーバーレス コンピューティング セッションを作成するたびに、ユーザー割り当てマネージド ID がコンピューティングに割り当てられます。コンピューティングの種類としてコンピューティング インスタンスを選択する場合は、アイドル シャットダウン時間のみを設定できます。
既存のコンピューティング インスタンス上で実行されているため、VM のサイズは固定され、セッション側で変更することはできません。
このセッションに使用される ID はコンピューティング インスタンスでも定義され、既定ではユーザー ID が使用されます。 コンピューティング インスタンスに ID を割り当てる方法の詳細
アイドル シャットダウン時間は、コンピューティング セッションのライフ サイクルを定義するために使用されます。設定した時間にセッションがアイドル状態の場合は、自動的に削除されます。 コンピューティング インスタンスでアイドル シャットダウンを有効にした場合は、コンピューティング レベルから有効になります。
- コンピューティングの種類を選択します。 サーバーレス コンピューティングとコンピューティング インスタンスのどちらかを選択できます。



コンピューティング セッションを使用して CLI/SDK でフロー実行を送信する
スタジオに加えて、フロー実行を送信するときに CLI/SDK でコンピューティング セッションを指定することもできます。
リソース部分でインスタンスの種類またはコンピューティング インスタンス名を指定することもできます。 インスタンスの種類またはコンピューティング インスタンス名を指定しない場合、クォータ、コスト、パフォーマンス、ディスク サイズなどの要因に基づいて、Azure Machine Learning によってインスタンスの種類 (VM サイズ) が選択されます。 サーバーレス コンピューティングの詳細についてはこちらをご覧ください。
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
# specify identity used by serverless compute.
# default value
# identity:
# type: user_identity
# use workspace first UAI
# identity:
# type: managed
# use specified client_id's UAI
# identity:
# type: managed
# client_id: xxx
column_mapping:
url: ${data.url}
# define cloud resource
resources:
instance_type: <instance_type> # serverless compute type
# compute: <compute_instance_name> # use compute instance as compute type
CLI を使用してこの実行を送信します。
pfazure run create --file run.yml
Note
CLI/SDK を使用してフロー実行を送信する場合、アイドル シャットダウンは 1 時間です。 コンピューティング ページに移動してコンピューティングをリリースできます。
フロー フォルダーの外部にあるファイルを参照する
場合によっては、フロー フォルダーの外部にある requirements.txt ファイルを参照できます。 たとえば、複数のフローを含む複雑なプロジェクトがある場合に、同じ requirements.txt ファイルを共有するとします。 これを行うには、このフィールド additional_includes を flow.dag.yaml に追加します。 このフィールドの値は、フロー フォルダーへの相対ファイル/フォルダー パスの一覧です。 たとえば、requirements.txt がフロー フォルダーの親フォルダーにある場合は、../requirements.txt を additional_includes フィールドに追加できます。
inputs:
question:
type: string
outputs:
output:
type: string
reference: ${answer_the_question_with_context.output}
environment:
python_requirements_txt: requirements.txt
additional_includes:
- ../requirements.txt
...
requirements.txt ファイルがフロー フォルダーにコピーされ、それを使用してコンピューティング セッションが開始されます。
スタジオ フロー ページでコンピューティング セッションを更新する
フロー ページで、次のオプションを使用してコンピューティング セッションを管理できます。
- コンピューティング セッションの設定を変更し、VM サイズやサーバーレス コンピューティングのユーザー割り当てマネージド ID などのコンピューティング設定を変更します。コンピューティング インスタンスを使用している場合は、他のインスタンスを使用するように変更できます。 次を変更することもできます。
- サーバーレス コンピューティングのユーザー割り当てマネージド ID を変更することもできます。 VM サイズを変更すると、コンピューティング セッションは新しい VM サイズでリセットされます。 Azure を
- requirements.txt からのパッケージのインストール プロンプト フロー UI で
requirements.txtを開き、その中のパッケージを追加できます。 - インストールされているパッケージの表示 コンピューティング セッションにインストールされているパッケージを表示します。 これには、基本イメージにインストールされたパッケージと、フロー フォルダー内の
requirements.txtファイルで指定されたパッケージが含まれます。 - コンピューティング セッションのリセット 現在のコンピューティング セッションが削除され、同じ環境で新しいコンピューティング セッションが作成されます。 パッケージの競合の問題が発生した場合は、このオプションを試すことができます。
- コンピューティング セッションの停止 現在のコンピューティング セッションが削除されます。 基になるコンピューティングにアクティブなコンピューティング セッションがない場合、サーバーレス コンピューティング リソースも削除されます。

また、フロー フォルダー内の requirements.txt ファイルにパッケージを追加することで、このフローの実行に使用する環境を簡単にカスタマイズできます。 このファイルにさらにパッケージを追加した後は、次のいずれかのオプションを選択できます。
- [Save and install] (保存してインストール) を使用すると、フロー フォルダー内の
pip install -r requirements.txtがトリガーされます。 インストールするパッケージによって、このプロセスは数分かかる場合があります。 - [Save only] (保存のみ) を使用すると、
requirements.txtファイルの保存だけが行われます。 後から自分でパッケージをインストールできます。

Note
requirements.txt の場所とファイル名を変更できますが、必ずフロー フォルダー内の flow.dag.yaml ファイル内でもそれらを変更してください。
requirements.txt 内では promptflow と promptflow-tools のバージョンを固定しないでください。これは既にセッションの基本イメージ内に含めてあります。
requirements.txt では、ローカル ホイール ファイルはサポートされません。 イメージ内でそれらをビルドし、カスタマイズされた基本イメージを flow.dag.yaml で更新します。 カスタム基本イメージを構築する方法の詳細を確認してください。
Azure DevOps のプライベート フィードにパッケージを追加する
Azure DevOps でプライベート フィードを使用する場合は、次の手順に従います。
マネージド ID をワークスペースまたはコンピューティング インスタンスに割り当てます。
コンピューティング セッションとしてサーバーレス コンピューティングを使用します。ユーザー割り当てマネージド ID をワークスペースに割り当てる必要があります。
ユーザー割り当てマネージド ID を作成し、この ID を Azure DevOps 組織に追加します。 詳細については、「サービス プリンシパルとマネージド ID を使用する」を参照してください。
Note
[ユーザーの追加] ボタンが表示されていない場合は、おそらくこのアクションを実行するために必要なアクセス許可がありません。
ユーザー割り当て ID をワークスペースに追加するか、更新します。
Note
ユーザー割り当てマネージド ID の、ワークスペースにリンクされた keyvault に
Microsoft.KeyVault/vaults/readがあることを確認してください。
コンピューティング インスタンスをコンピューティング セッションとして使用するには、ユーザー割り当てマネージド ID をコンピューティング インスタンスに割り当てる必要があります。
プライベート フィードの URL に
{private}を追加します。 たとえば、Azure DevOps のtest_feedからtest_packageをインストールする場合は、requirements.txtに-i https://{private}@{test_feed_url_in_azure_devops}を追加します。-i https://{private}@{test_feed_url_in_azure_devops} test_packageコンピューティング セッション構成でユーザー割り当てマネージド ID を使用して指定します。
サーバーレス コンピューティングを使用していて、コンピューティング セッションが実行されていない場合は [詳細設定から始める] でユーザー割り当てマネージド ID を指定し、コンピューティング セッションが実行されている場合は [Change compute session settings]\(コンピューティング セッションの設定の変更\) ボタンを使用します。
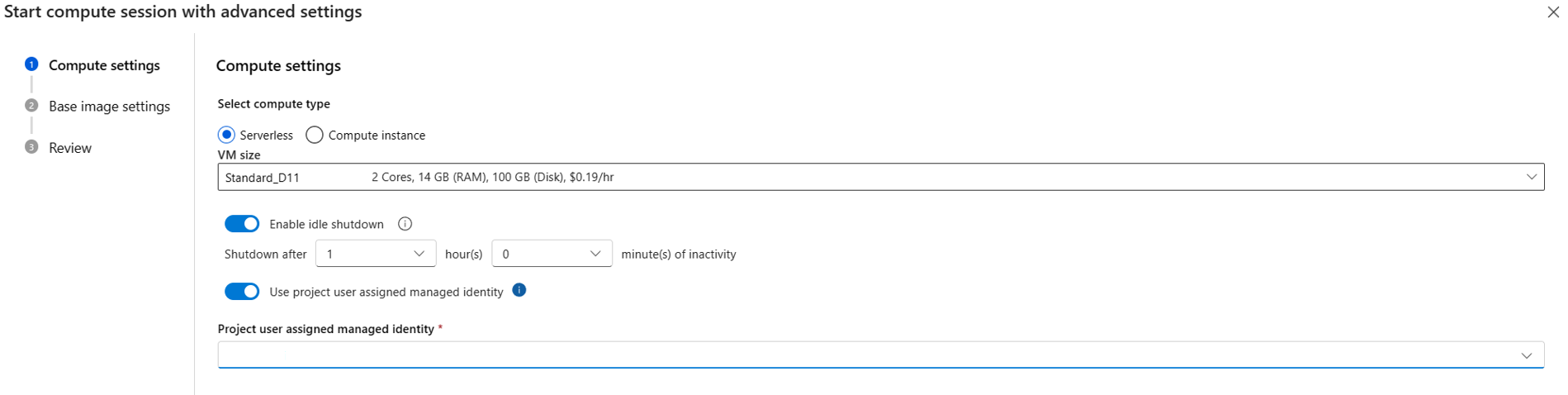
コンピューティング インスタンスを使用している場合は、コンピューティング インスタンスに割り当てたユーザー割り当てマネージド ID が使用されます。

Note
このアプローチは、主にフロー開発フェーズでのクイック テストに焦点を当てています。エンドポイントとしてこのフローをデプロイする場合は、このプライベート フィードをイメージにビルドし、flow.dag.yaml の基本イメージを更新してください。 カスタム基本イメージをビルドする方法の詳細はこちらをご覧ください。
コンピューティング セッションの基本イメージを変更する
既定では、最新のプロンプト フローの基本イメージを使用します。 別の基本イメージを使う場合は、カスタムのものを作成できます。
- スタジオでは、コンピューティング セッション設定の基本イメージ設定で基本イメージを変更できます。

フロー フォルダー内の
flow.dag.yamlファイルのenvironmentの下で新しい基本イメージを指定することもできます。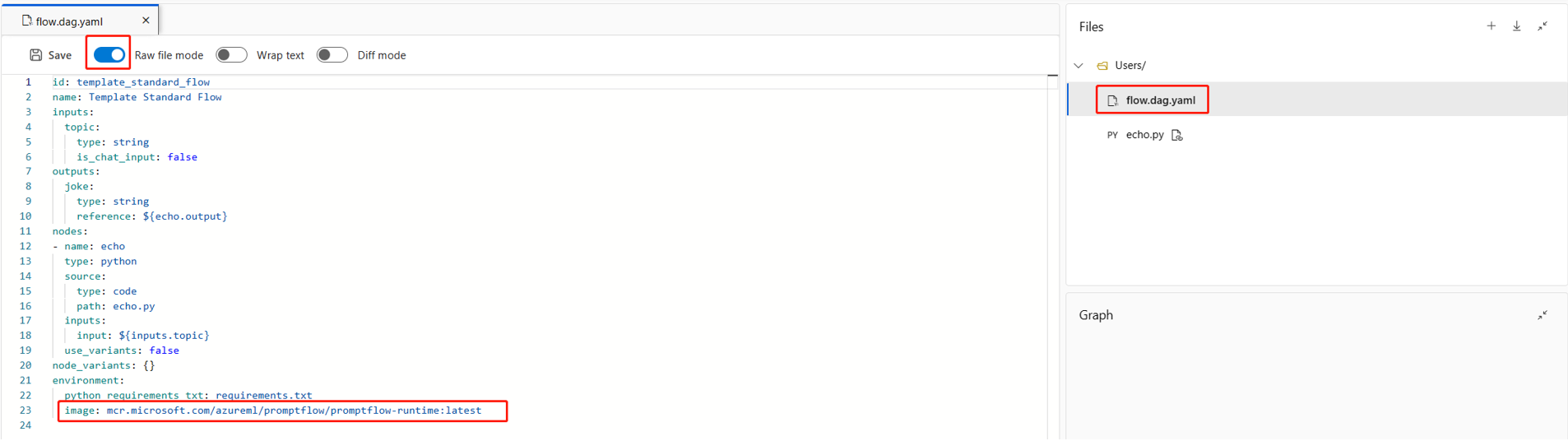
environment: image: <your-custom-image> python_requirements_txt: requirements.txt

新しい基本イメージを使用するには、コンピューティング セッションをリセットする必要があります。 このプロセスは、新しい基本イメージをプルしてパッケージを再インストールするので数分かかります。
コンピューティング セッションで使用されるサーバーレス インスタンスを管理する
サーバーレス コンピューティングをコンピューティング セッションとして使用する場合、サーバーレス インスタンスを管理できます。 コンピューティング ページにあるコンピューティング セッションを一覧するタブで、サーバーレス インスタンスを表示します。

また、[Active flows and runs]\(アクティブなフローと実行\) タブで、コンピューティングで実行されているフローと実行にアクセスすることもできます。削除すると、インスタンスはフローに影響し、その上で実行されます。

コンピューティング セッション、コンピューティング リソース、フロー、ユーザーの関係
- 1 人のユーザーが複数のコンピューティング リソース (サーバーレスまたはコンピューティング インスタンス) を持つことができます。 さまざまなニーズのために、1 人のユーザーが複数のコンピューティング リソースを持つことができます。 たとえば、1 人のユーザーが VM サイズやユーザー割り当てマネージド ID が異なる複数のコンピューティング リソースを持つことができます。
- 1 つのコンピューティング リソースは、1 人のユーザーのみが使用できます。 コンピューティング リソースは、1 人のユーザーのプライベートな開発ボックスとして使用されます。 複数のユーザーが同じコンピューティング リソースを共有することはできません。
- 1 つのコンピューティング リソースで複数のコンピューティング セッションをホストできます。 コンピューティング セッションは、基になるコンピューティング リソースで実行されているコンテナーです。 たとえば、プロンプト フローの作成には多くのコンピューティング リソースは必要にならないため、1 つのコンピューティング リソースで同じユーザーの複数のコンピューティング セッションをホストできます。
- 1 つのコンピューティング セッションは、一度に 1 つのコンピューティング リソースにのみ属します。 ただし、コンピューティング セッションを削除または停止し、別のコンピューティング リソースに再び割り当てることはできます。
- 1 つのフローで使用できるコンピューティング セッションは 1 つだけです。 各フローは自己完結型であり、コンピューティング セッションのフロー フォルダーに基本イメージと必要な Python パッケージを定義します。
ランタイムをコンピューティング セッションに切り替える
コンピューティング インスタンス ランタイムと比べて、コンピューティング セッションには以下の利点があります。
- セッションおよび基盤のコンピューティングのライフサイクルを自動的に管理します。 それらを手動で作成して管理する必要はありません。
- カスタム環境を作成するのではなく、フロー フォルダーの
requirements.txtファイルにパッケージを追加することで、パッケージを簡単にカスタマイズします。
次の手順を使用して、コンピューティング インスタンス ランタイムをコンピューティング セッションに切り替えます。
- フロー フォルダーの
requirements.txtファイルを準備します。requirements.txtでpromptflowとpromptflow-toolsのバージョンを固定しないようにします。これらは基本イメージに既に含まれています。 コンピューティング セッションでは、起動時にパッケージがrequirements.txtファイルにインストールされます。 - コンピューティング インスタンス ランタイムを作成するためにカスタム環境を作成する場合は、環境の詳細ページからイメージを取得し、フロー フォルダーの
flow.dag.yamlファイルでそれを指定できます。 詳細については、「コンピューティング セッションの基本イメージを変更する」を参照してください。 ワークスペース上で、自分または関連するユーザー割り当てマネージド ID に、イメージに対するacr pullのアクセス許可があることを確認します。

- コンピューティング リソースに関して、ライフサイクルを手動で管理する場合は、既存のコンピューティング インスタンスを引き続き使用できます。または、ライフサイクルがシステムで管理されるサーバーレス コンピューティングを試すこともできます。