Azure Database for PostgreSQL - Single Server での高可用性
適用対象:  Azure Database for PostgreSQL - 単一サーバー
Azure Database for PostgreSQL - 単一サーバー
重要
Azure Database for PostgreSQL - シングル サーバーは廃止パスにあります。 Azure Database for PostgreSQL - フレキシブル サーバーにアップグレードすることを強くお勧めします。 Azure Database for PostgreSQL - フレキシブル サーバーへの移行の詳細については、Azure Database for PostgreSQL 単一サーバーの現状に関するページを参照してください。
Azure Database for PostgreSQL – Single Server サービスでは、アップタイム に対して財務的な裏付けのあるサービス レベル 契約 (SLA) で、高レベルの可用性が保証されます。 Azure Database for PostgreSQL は、ユーザーが開始したコンピューティングのスケーリング操作などの計画的なイベント中や、基になるハードウェア、ソフトウェア、ネットワークの障害などの計画外のイベントが発生したときに高可用性を提供します。 Azure Database for PostgreSQL は、ほとんどの重大な状況から迅速に復旧できるため、このサービスを使用するとアプリケーションのダウンタイムが事実上なくなります。
Azure Database for PostgreSQL は、高いアップタイムを必要とするミッションクリティカルなデータベースの実行に適しています。 このサービスは、Azure アーキテクチャに基づいて構築されているので、計画的な停止や計画外の停止によるデータベースのダウンタイムを軽減するための高可用性、冗長性、回復性の各機能が最初から備わっており、追加のコンポーネントを構成する必要がありません。
Azure Database for PostgreSQL - Single Server のコンポーネント
| コンポーネント | 説明 |
|---|---|
| PostgreSQL データベース サーバー | Azure Database for PostgreSQL は、データベース サーバーにセキュリティ、分離、リソース保護、および迅速な再起動機能を提供します。 これらの機能により、スケーリングなどの操作が容易になり、障害の発生後数秒でデータベース サーバーの復旧操作を行えます。 データベース サーバーでのデータ変更は、通常、データベース トランザクションのコンテキストで行われます。 データベースでのすべての変更は、データベース サーバーに接続している Azure Storage に、先書きログ (WAL) の形式で同期的に記録されます。 データベース チェックポイント 処理中に、データベース サーバー メモリのデータ ページもストレージにフラッシュされます。 |
| リモート ストレージ | すべての PostgreSQL 物理データファイルと WAL ファイルは、データの冗長性、可用性、信頼性を確保するためにリージョン内にデータの 3 つのコピーを格納するように設計されている Azure Storage に格納されます。 また、このストレージ レイヤーはデータベース サーバーから独立しています。 数秒以内に、障害が発生したデータベース サーバーからデタッチして、新しいデータベース サーバーに再アタッチすることができます。 また、Azure Storage は、ストレージの障害を継続的に監視します。 ブロックの破損が検出されると、新しいストレージ コピーをインスタンス化することによって自動的に修正されます。 |
| ゲートウェイ | ゲートウェイはデータベース プロキシとして機能し、すべてのクライアント接続をデータベース サーバーにルーティングします。 |
計画的なダウンタイムの軽減
Azure Database for PostgreSQL は、計画的なダウンタイム操作中に高可用性をもたらすように設計されています。
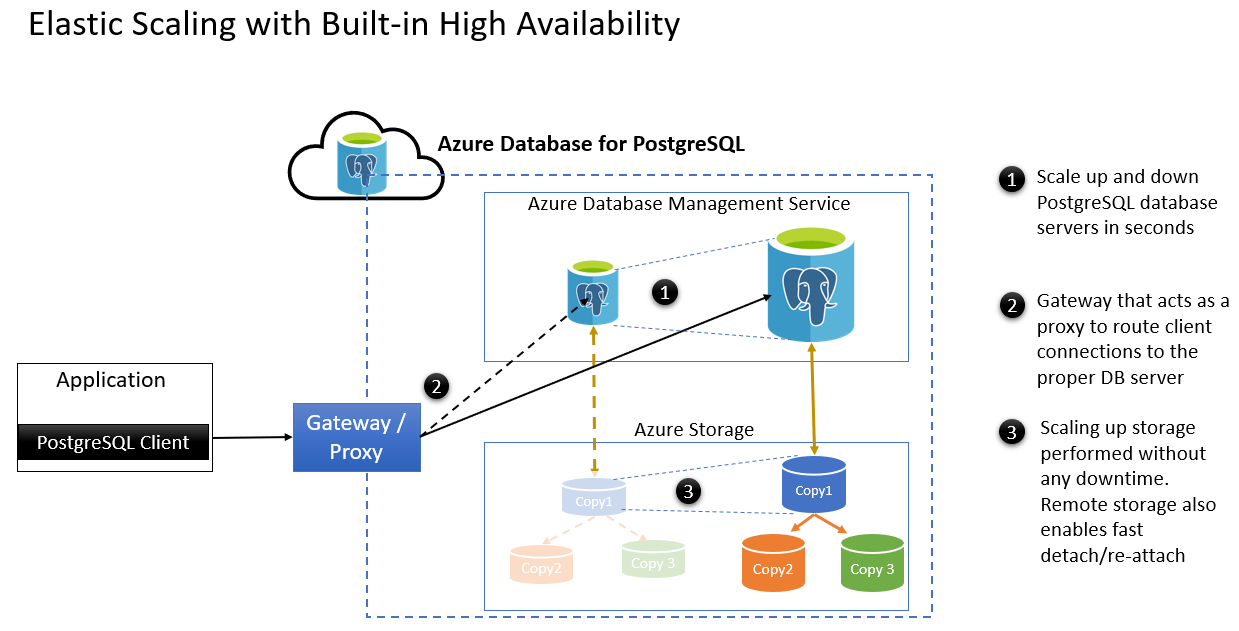
- PostgreSQL データベース サーバーを数秒でスケールアップおよびスケールダウンします。
- クライアントをルーティングするためのプロキシとして機能するゲートウェイが、適切なデータベース サーバーに接続します。
- ストレージのスケールアップは、ダウンタイムなしで実行できます。 リモート ストレージを使用すると、フェールオーバー後に高速デタッチと再アタッチが可能になります。 次に、計画的なメンテナンス シナリオをいくつか示します。
| シナリオ | 説明 |
|---|---|
| スケールアップ/スケールダウンの計算 | ユーザーがコンピューティングのスケールアップ/ダウン操作を実行すると、スケーリングされたコンピューティング構成を使用して新しいデータベース サーバーがプロビジョニングされます。 古いデータベース サーバーでは、アクティブなチェックポイントを完了でき、クライアント接続がドレインされ、コミットされていないトランザクションが取り消され、サーバー自体がシャットダウンされます。 続いてストレージが古いデータベース サーバーからデタッチされ、新しいデータベース サーバーに接続されます。 クライアント アプリケーションが接続を再試行するか、または新しい接続を確立しようとすると、ゲートウェイはその接続要求を新しいデータベース サーバーに転送します。 |
| ストレージのスケール アップ | ストレージのスケール アップはオンライン操作であるため、データベース サーバーは中断されません。 |
| 新しいソフトウェアのデプロイ (Azure) | 新機能のロールアウトやバグ修正プログラムは、サービスの計画的なメンテナンスの一環として自動的に行われます。 詳細については、ドキュメントを参照し、自身のポータルを確認してください。 |
| マイナー バージョンのアップグレード | Azure Database for PostgreSQL では、Azure によって決定されたマイナー バージョンへの修正プログラムが自動的にデータベース サーバーに適用されます。 これは、サービスの計画的なメンテナンスの一環として行われます。 これにより、秒単位の短いダウンタイムが発生し、データベース サーバーは新しいマイナー バージョンで自動的に再起動されます。 詳細については、ドキュメントを参照し、自身のポータルを確認してください。 |
計画外のダウンタイムの軽減
計画外のダウンタイムは、基になるハードウェアの障害、ネットワークの問題、ソフトウェアのバグなど、予期しない障害の結果として発生する可能性があります。 データベース サーバーが予期せず停止した場合は、新しいデータベース サーバーが数秒で自動的にプロビジョニングされます。 リモート ストレージは、新しいデータベース サーバーに自動的に接続されます。 PostgreSQL エンジンは、WAL およびデータベース ファイルを使用して復旧操作を実行し、データベース サーバーを開いてクライアントが接続できるようにします。 コミットされていないトランザクションは失われ、アプリケーションが再試行する必要があります。 計画外のダウンタイムは回避できませんが、Azure Database for PostgreSQL では、データベース サーバーとストレージ レイヤーの両方で、ユーザーの介入を必要とすることなく自動的に復旧操作を実行することでダウンタイムを軽減します。
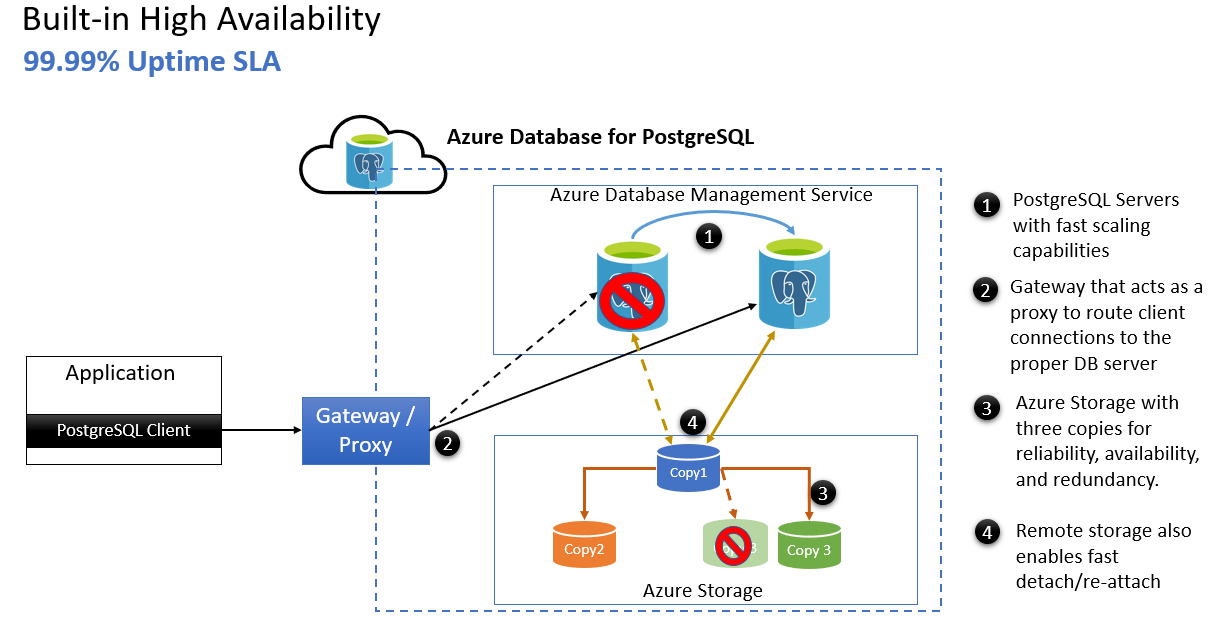
- 高速スケーリング機能を備えた Azure PostgreSQL サーバー。
- プロキシとして機能し、クライアント接続を適切なデータベース サーバーにルーティングするゲートウェイ。
- 信頼性、可用性、冗長性のための 3 つのコピーが含まれる Azure Storage。
- また、リモート ストレージを使用すると、サーバーのフェールオーバー後に高速デタッチと再アタッチが可能になります。
計画外のダウンタイム: 障害シナリオとサービス復旧
いくつかの障害シナリオと、Azure Database for PostgreSQL で自動的に復旧する方法を次に示します。
| シナリオ | 自動復旧 |
|---|---|
| データベース サーバーの障害 | 基になるハードウェアの障害が原因でデータベース サーバーが停止した場合、アクティブな接続は切断され、処理中のすべてのトランザクションは中止されます。 新しいデータベース サーバーが自動的にデプロイされ、リモート データ ストレージが新しいデータベース サーバーに接続されます。 データベースの復旧が完了すると、クライアントはゲートウェイ経由で新しいデータベース サーバーに接続できるようになります。 復旧時間 (RTO) は、大規模なトランザクションや、データベース サーバーの起動プロセス中に実行される復旧の量など、障害発生時のアクティビティを含め、さまざまな要因によって異なります。 PostgreSQL データベースを使用するアプリケーションは、切断された接続や失敗したトランザクションを検出し、再試行するように構築されている必要があります。 アプリケーションが再試行すると、ゲートウェイは、新しく作成されたデータベース サーバーへの接続を透過的にリダイレクトします。 |
| ストレージの障害 | アプリケーションは、ディスク障害や物理ブロックの破損など、ストレージ関連の問題の影響を一切認識しません。 データが 3 つのコピーに格納されるので、データのコピーは存続しているストレージから提供されます。 ブロックの破損は自動的に修正されます。 データのコピーが失われると、データの新しいコピーが自動的に作成されます。 |
| コンピューティング エラー | コンピューティング エラーはまれにしか発生しないイベントです。 コンピューティング エラーが発生した場合、新しいコンピューティング コンテナーがプロビジョニングされ、データ ファイルが格納されたストレージがそこにマップされると、PostgreSQL データベース エンジンは新しいコンテナー上でオンラインになり、ゲートウェイ サービスにより、アプリケーションを変更することなく、透過的なフェールオーバーを実現できます。 また、コンピューティング レイヤーには可用性ゾーンの回復性が組み込まれており、AZ コンピューティングエラーが発生した場合は、新しいコンピューティングが異なる可用性ゾーンでスピンアップされることにも注意してください。 |
次に、復旧にユーザーの操作が必要な障害シナリオをいくつか示します。
| シナリオ | 復旧計画 |
|---|---|
| リージョンの障害 | リージョンの障害は、まれにしか発生しないイベントです。 ただし、リージョンの障害から保護する必要がある場合は、ディザスター リカバリー (DR) 用に他のリージョンで 1 つ以上の読み取りレプリカを構成できます。 (詳細については、読み取りレプリカの作成と管理に関するこの記事をご覧ください)。 リージョン レベルの障害が発生した場合は、運用データベースサーバーとして他のリージョンで構成されている読み取りレプリカを手動で昇格できます。 |
| 可用性ゾーンの障害 | 可用性ゾーンの障害も、まれにしか発生しないイベントです。 ただし、可用性ゾーンの障害からの保護が必要な場合は、1 つ以上の読み取りレプリカを構成するか、ゾーン冗長化の高可用性を提供するフレキシブル サーバー オファリングの使用を検討することができます。 |
| 論理/ユーザー エラー | 誤って破棄されたテーブルや間違って更新されたデータなどのユーザーエラーからの復旧には、エラーが発生する直前の時間までデータを復元および復旧することによる、特定の時点への復旧 (PITR) の実行が含まれます。 データベース サーバー内のすべてのデータベースではなく、データベースまたは特定のテーブルのサブセットのみを復元する場合は、新しいインスタンスでデータベース サーバーを復元し、pg_dump を使用してテーブルをエクスポートし、pg_restore を使用してそれらのテーブルをデータベースに復元することができます。 |
まとめ
Azure Database for PostgreSQL には、データベース サーバー高速再起動機能、冗長ストレージ、ゲートウェイからの効率的なルーティングが用意されています。 データの保護を強化するために、geo レプリケートするようにバックアップを構成したり、他のリージョンに 1 つ以上の読み取りレプリカをデプロイしたりすることもできます。 Azure Database for PostgreSQL には、高可用性機能が内在されているため、最も一般的な障害からデータベースが保護され、財務に裏付けられた業界最高レベルの 99.99 % のアップタイム SLA が保証されます。 このような可用性と信頼性の機能すべてによって、Azure はミッションクリティカルなアプリケーションを実行するための理想的なプラットフォームになることができています。
次のステップ
- Azure リージョンについて学習する
- 一時的な接続エラーへの対処について学習する
- 読み取りレプリカを使用してデータをレプリケートする方法を学習する