Azure の Red Hat Enterprise Linux に Pacemaker を設定する
この記事では、Red Hat Enterprise Server (RHEL) で基本的な Pacemaker クラスターを構成する方法について説明します。 この手順では、RHEL 7、RHEL 8、RHEL 9 について説明します。
前提条件
はじめに、次の SAP ノートおよび記事を確認してください。
RHEL High Availability (HA) のドキュメント
- 高可用性クラスターの設定および管理。
- RHEL High Availability クラスターのサポート ポリシー - sbd および fence_sbd。
- RHEL High Availability クラスターのサポート ポリシー - fence_azure_arm。
- ソフトウェアでエミュレーションされたウォッチドッグの既知の制限。
- RHEL High Availability のコンポーネントの探索 - sbd および fence_sbd。
- RHEL High Availability クラスターの設計ガイダンス - sbd の考慮事項。
- RHEL 8 の導入に関する考慮事項 - 高可用性およびクラスター
Azure 固有の RHEL ドキュメント
SAP オファリングの RHEL ドキュメント
概要
重要
複数の仮想ネットワーク (VNet)/サブネットにまたがる Pacemaker クラスターは、Standard サポート ポリシーの対象ではありません。
Azure で RHEL 用の Pacemaker クラスターでフェンスを構成するために使用できるオプションは 2 つあります。Azure API を介して障害が発生したノードを再起動する Azure フェンス エージェントか、SBD デバイスを使用することです。
重要
Azure の、ストレージ ベースのフェンス (fence_sbd) を使用する RHEL 高可用性クラスターでは、ソフトウェアでエミュレーションされたウォッチドッグが使用されます。 フェンス メカニズムとして SBD を選択する場合は、「ソフトウェアでエミュレーションされたウォッチドッグの既知の制限」と「RHEL High Availability クラスターのサポート ポリシー - sbd および fence_sbd」を確認することが重要です。
SBD デバイスを使用する
Note
SBD を使用したフェンス メカニズムは、RHEL 8.8 以降と RHEL 9.0 以降でサポートされています。
SBD デバイスを構成するには、次の 2 つのオプションのいずれかを使用します。
SBD と iSCSI ターゲット サーバー
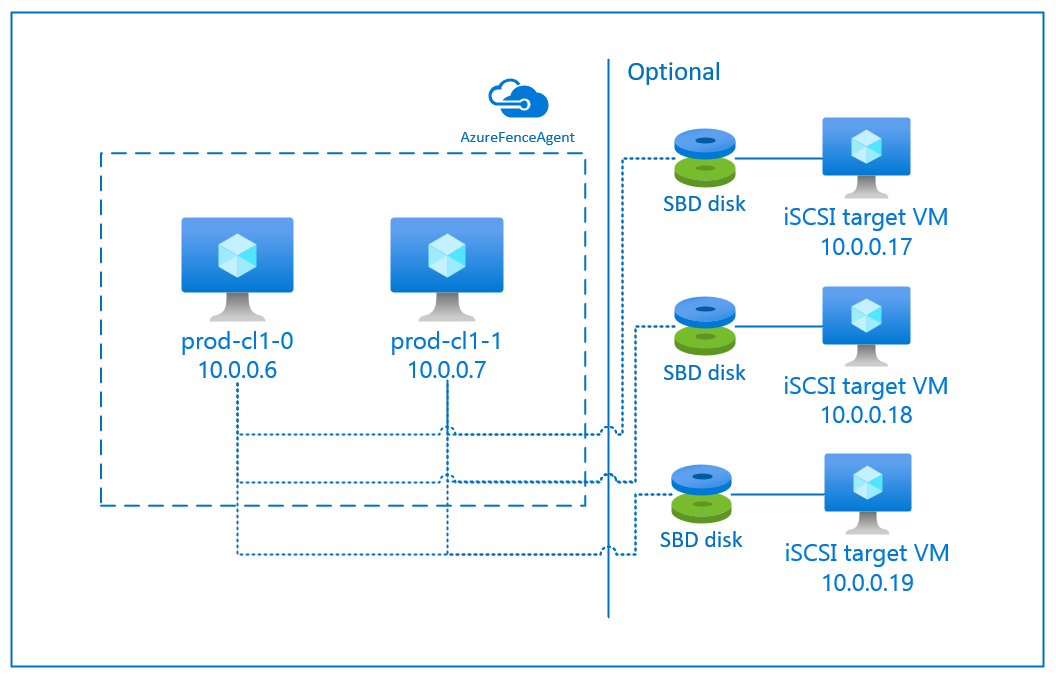
SBD デバイスを使う場合、Internet Small Computer System Interface (iSCSI) ターゲット サーバーとして機能しつつ SBD デバイスを提供する仮想マシン (VM) が、少なくとも 1 つ、追加で必要となります。 ただし、これらの iSCSI ターゲット サーバーは他の Pacemaker クラスターと共有することができます。 SBD デバイスを使う利点は、SBD デバイスを既にオンプレミスで使用している場合、Pacemaker クラスターの運用方法に変更を加える必要は一切ないことです。
特定の SBD デバイスが利用できなくなる状況 (たとえば、iSCSI ターゲット サーバーの OS ファイルの部分置換時など) に備えるにあたっては、1 つの Pacemaker クラスターに対し、最大 3 つの SBD デバイスを使用できます。 Pacemaker あたり 2 つ以上の SBD デバイスを使用する場合は、複数の iSCSI ターゲット サーバーをデプロイし、各 iSCSI ターゲット サーバーから 1 つの SBD を接続するようにしてください。 SBD デバイスは、1 つまたは 3 つ使用することをお勧めします。 SBD デバイスが 2 つしか構成されておらず、そのうちの 1 つが使用できない場合、Pacemaker はクラスター ノードを自動的にフェンスできません。 1 つの iSCSI ターゲット サーバーがダウンした場合にフェンシングを行えるようにするには、3 つの SBD デバイスと、3 つの iSCSI ターゲット サーバーを使用する必要があります。 これは、SBD を使用しているときの回復力が最も高い構成です。
重要
Linux Pacemaker クラスター ノードと SBD デバイスを計画してデプロイする場合、仮想マシンと、ネットワーク仮想アプライアンス (NVA) など、他のデバイスを通過するための SBD デバイスをホストする VM 間をルーティングしないようにする必要があります。
メンテナンス イベントと NVA の問題がクラスター構成全体の安定性と信頼性に負の影響を与える可能性があります。 詳細については、ユーザー定義のルーティング規則に関する記事を参照してください。
SBD と Azure 共有ディスク
SBD デバイスを構成するには、Pacemaker クラスターに属しているすべての仮想マシンに、Azure 共有ディスクを少なくとも 1 つアタッチする必要があります。 Azure 共有ディスクを使用する SBD デバイスの利点は、仮想マシンを別途デプロイして構成する必要がないことです。
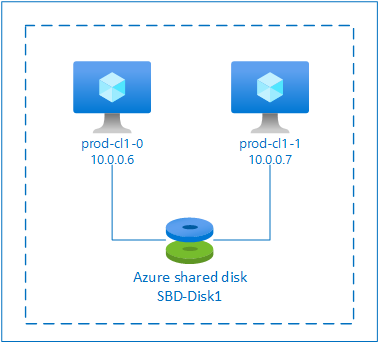
Azure 共有ディスクを使用している場合の SBD デバイスの構成に関する重要な考慮事項を次に示します。
- Premium SSD を使用した Azure 共有ディスクが SBD デバイスとしてサポートされます。
- Azure 共有ディスクを使用する SBD デバイスは、RHEL 8.8 以降でサポートされています。
- Azure Premium 共有ディスクを使用する SBD デバイスは、ローカル冗長ストレージ (LRS) およびゾーン冗長ストレージ (ZRS) でサポートされます。
- デプロイの種類に応じて、Azure 共有ディスクの適切な冗長ストレージを SBD デバイスとして選択します。
- Azure Premium 共有ディスクに LRS を使用する SBD デバイス (skuName - Premium_LRS) は、可用性セットのようなリージョン単位のデプロイでのみサポートされます。
- 可用性ゾーンや FD=1 のスケール セットのようなゾーン単位のデプロイには、Azure Premium 共有ディスクに ZRS を使用する SBD デバイス (skuName - Premium_ZRS) が推奨されます。
- マネージド ディスクの ZRS は、現在、「リージョン別の提供状況」のドキュメントに記載されているリージョンで使用できます。
- SBD デバイスに使用する Azure 共有ディスクは、大きなサイズである必要はありません。 共有ディスクを使用できるクラスター ノードの数は、maxShares 値によって決まります。 たとえば、SAP ASCS/ERS、SAP HANA スケールアップなどの 2 ノード クラスターでは、SBD デバイスに P1 または P2 のディスク サイズを使用できます。
- HANA システム レプリケーション (HSR) と Pacemaker を使用した HANA スケールアウトの場合、SBD デバイスに Azure 共有ディスクを使用できるのは、現在の maxShares の制限により、レプリケーション サイトあたり最大 5 ノードのクラスターとなります。
- Azure 共有ディスクの SBD デバイスを Pacemaker クラスター全体にアタッチすることはお勧めしません。
- Azure 共有ディスクの SBD デバイスを複数使用する場合は、VM にアタッチできる最大データ ディスク数の上限を確認してください。
- Azure 共有ディスクの制限事項の詳細については、Azure 共有ディスクのドキュメントの「制限事項」セクションを参照してください。
Azure フェンス エージェントを使用する
フェンスは、Azure フェンス エージェントを使用して設定できます。 Azure フェンス エージェントでは、クラスター VM のマネージド ID か、障害が発生したノードの再起動を Azure API 経由で管理するサービス プリンシパルまたはマネージド システム ID (MSI) が必要です。 Azure フェンス エージェントでは、追加の仮想マシンをデプロイする必要はありません。
SBD と iSCSI ターゲット サーバー
フェンスに iSCSI ターゲット サーバーを使用する SBD デバイスを使用するには、次のセクションの手順に従います。
iSCSI ターゲット サーバーをセットアップする
まず、iSCSI ターゲット仮想マシンを作成する必要があります。 iSCSI ターゲット サーバーは、複数の Pacemaker クラスターと共有することができます。
サポートされている RHEL OS バージョンで実行される仮想マシンをデプロイし、SSH 経由で接続します。 VM は大きなサイズである必要はありません。 Standard_E2s_v3 または Standard_D2s_v3 などのサイズの VM で十分です。 OS ディスクには Premium ストレージを使用してください。
HA および Update Services で RHEL for SAP を使用したり、iSCSI ターゲット サーバーで RHEL for SAP Apps OS イメージを使用したりする必要はありません。 代わりに、標準の RHEL OS イメージを使用できます。 ただし、サポート ライフ サイクルは OS 製品のリリースによって異なります。
すべての iSCSI ターゲット仮想マシンに対し、次のコマンドを実行します。
RHEL を更新します。
sudo yum -y updateNote
OS のアップグレード後または更新後に、ノードの再起動が必要になる場合があります。
iSCSI ターゲット パッケージをインストールします。
sudo yum install targetcli起動時に開始するようにターゲットを開始して構成します。
sudo systemctl start target sudo systemctl enable targetファイアウォールでポート
3260を開きますsudo firewall-cmd --add-port=3260/tcp --permanent sudo firewall-cmd --add-port=3260/tcp
iSCSI ターゲット サーバーに iSCSI デバイスを作成する
SAP システム クラスター用の iSCSI ディスクを作成するには、すべての iSCSI ターゲット仮想マシンに対して次のコマンドを実行します。 この例は、複数のクラスターに対する SBD デバイスの作成を示したもので、複数のクラスターに 1 つの iSCSI ターゲット サーバーが使用されています。 SBD デバイスは OS ディスクに構成されているため、十分な領域があることを確認します。
- ascsnw1: NW1 の ASCS/ERS クラスターを表します。
- dbhn1: HN1 のデータベース クラスターを表します。
- sap-cl1 と sap-cl2: NW1 ASCS/ERS クラスター ノードのホスト名。
- hn1-db-0 と hn1-db-1: データベース クラスター ノードのホスト名。
次の手順では、必要に応じて、特定のホスト名と SID を使用してコマンドを変更します。
すべての SBD デバイスのルート フォルダーを作成します。
sudo mkdir /sbdシステム NW1 の ASCS/ERS サーバー用の SBD デバイスを作成します。
sudo targetcli backstores/fileio create sbdascsnw1 /sbd/sbdascsnw1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.ascsnw1.local:ascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/luns/ create /backstores/fileio/sbdascsnw1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl1.local:sap-cl1 sudo targetcli iscsi/iqn.2006-04.ascsnw1.local:ascsnw1/tpg1/acls/ create iqn.2006-04.sap-cl2.local:sap-cl2システム HN1 のデータベース クラスター用の SBD デバイスを作成します。
sudo targetcli backstores/fileio create sbddbhn1 /sbd/sbddbhn1 50M write_back=false sudo targetcli iscsi/ create iqn.2006-04.dbhn1.local:dbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/luns/ create /backstores/fileio/sbddbhn1 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-0.local:hn1-db-0 sudo targetcli iscsi/iqn.2006-04.dbhn1.local:dbhn1/tpg1/acls/ create iqn.2006-04.hn1-db-1.local:hn1-db-1targetcli の構成を保存します。
sudo targetcli saveconfigすべてが正しく設定されていることを確認します
sudo targetcli ls o- / ......................................................................................................................... [...] o- backstores .............................................................................................................. [...] | o- block .................................................................................................. [Storage Objects: 0] | o- fileio ................................................................................................. [Storage Objects: 2] | | o- sbdascsnw1 ............................................................... [/sbd/sbdascsnw1 (50.0MiB) write-thru activated] | | | o- alua ................................................................................................... [ALUA Groups: 1] | | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | | o- sbddbhn1 ................................................................... [/sbd/sbddbhn1 (50.0MiB) write-thru activated] | | o- alua ................................................................................................... [ALUA Groups: 1] | | o- default_tg_pt_gp ....................................................................... [ALUA state: Active/optimized] | o- pscsi .................................................................................................. [Storage Objects: 0] | o- ramdisk ................................................................................................ [Storage Objects: 0] o- iscsi ............................................................................................................ [Targets: 2] | o- iqn.2006-04.dbhn1.local:dbhn1 ..................................................................................... [TPGs: 1] | | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | | o- acls .......................................................................................................... [ACLs: 2] | | | o- iqn.2006-04.hn1-db-0.local:hn1-db-0 .................................................................. [Mapped LUNs: 1] | | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | | o- iqn.2006-04.hn1-db-1.local:hn1-db-1 .................................................................. [Mapped LUNs: 1] | | | o- mapped_lun0 ............................................................................... [lun0 fileio/sbdhdb (rw)] | | o- luns .......................................................................................................... [LUNs: 1] | | | o- lun0 ............................................................. [fileio/sbddbhn1 (/sbd/sbddbhn1) (default_tg_pt_gp)] | | o- portals .................................................................................................... [Portals: 1] | | o- 0.0.0.0:3260 ..................................................................................................... [OK] | o- iqn.2006-04.ascsnw1.local:ascsnw1 ................................................................................. [TPGs: 1] | o- tpg1 ............................................................................................... [no-gen-acls, no-auth] | o- acls .......................................................................................................... [ACLs: 2] | | o- iqn.2006-04.sap-cl1.local:sap-cl1 .................................................................... [Mapped LUNs: 1] | | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | | o- iqn.2006-04.sap-cl2.local:sap-cl2 .................................................................... [Mapped LUNs: 1] | | o- mapped_lun0 ........................................................................... [lun0 fileio/sbdascsers (rw)] | o- luns .......................................................................................................... [LUNs: 1] | | o- lun0 ......................................................... [fileio/sbdascsnw1 (/sbd/sbdascsnw1) (default_tg_pt_gp)] | o- portals .................................................................................................... [Portals: 1] | o- 0.0.0.0:3260 ..................................................................................................... [OK] o- loopback ......................................................................................................... [Targets: 0]
iSCSI ターゲット サーバーの SBD デバイスをセットアップする
[A]: すべてのノードに適用されます。 [1]: ノード 1 にのみ適用されます。 [2]: ノード 2 にのみ適用されます。
クラスター ノードで、前のセクションで作成した iSCSI デバイスを接続して検出します。 以下のコマンドは、作成する新しいクラスターの各ノード上で実行します。
[A] すべてのクラスター ノードの iSCSI イニシエーター ユーティリティをインストールまたは更新します。
sudo yum install -y iscsi-initiator-utils[A] クラスターと SBD パッケージをすべてのクラスター ノードにインストールします。
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] iSCSI サービスを有効にします。
sudo systemctl enable iscsid iscsi[1] クラスターの 1 つ目のノードのイニシエーター名を変更します。
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl1.local:sap-cl1[2] クラスターの 2 つ目のノードのイニシエーター名を変更します。
sudo vi /etc/iscsi/initiatorname.iscsi # Change the content of the file to match the access control ists (ACLs) you used when you created the iSCSI device on the iSCSI target server (for example, for the ASCS/ERS servers) InitiatorName=iqn.2006-04.sap-cl2.local:sap-cl2[A] iSCSI サービスを再起動して、変更を適用します。
sudo systemctl restart iscsid sudo systemctl restart iscsi[A] iSCSI デバイスを接続します。 下の例の 10.0.0.17 は iSCSI ターゲット サーバーの IP アドレス、3260 は既定のポートです。 最初のコマンド
iscsiadm -m discoveryを実行すると、ターゲット名iqn.2006-04.ascsnw1.local:ascsnw1が一覧に表示されます。sudo iscsiadm -m discovery --type=st --portal=10.0.0.17:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.17:3260 sudo iscsiadm -m node -p 10.0.0.17:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 複数の SBD デバイスを使用している場合は、2 つ目の iSCSI ターゲット サーバーにも接続します。
sudo iscsiadm -m discovery --type=st --portal=10.0.0.18:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.18:3260 sudo iscsiadm -m node -p 10.0.0.18:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] 複数の SBD デバイスを使用している場合は、3 つ目の iSCSI ターゲット サーバーにも接続します。
sudo iscsiadm -m discovery --type=st --portal=10.0.0.19:3260 sudo iscsiadm -m node -T iqn.2006-04.ascsnw1.local:ascsnw1 --login --portal=10.0.0.19:3260 sudo iscsiadm -m node -p 10.0.0.19:3260 -T iqn.2006-04.ascsnw1.local:ascsnw1 --op=update --name=node.startup --value=automatic[A] iSCSI デバイスが利用可能な状態であることを確認し、デバイス名を書き留めておいてください。 次の例では、ノードを 3 つの iSCSI ターゲット サーバーに接続することで、3 つの iSCSI デバイスが検出されます。
lsscsi [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sde [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdb [1:0:0:2] disk Msft Virtual Disk 1.0 /dev/sdc [1:0:0:3] disk Msft Virtual Disk 1.0 /dev/sdd [2:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdf [3:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdh [4:0:0:0] disk LIO-ORG sbdascsnw1 4.0 /dev/sdg[A] ここで、iSCSI デバイスの ID を取得します。
ls -l /dev/disk/by-id/scsi-* | grep -i sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -> ../../sdf # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_85d254ed-78e2-4ec4-8b0d-ecac2843e086 -> ../../sdf ls -l /dev/disk/by-id/scsi-* | grep -i sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -> ../../sdh # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_87122bfc-8a0b-4006-b538-d0a6d6821f04 -> ../../sdh ls -l /dev/disk/by-id/scsi-* | grep -i sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-1LIO-ORG_sbdhdb:d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -> ../../sdg # lrwxrwxrwx 1 root root 9 Jul 15 20:21 /dev/disk/by-id/scsi-SLIO-ORG_sbdhdb_d2ddc548-060c-49e7-bb79-2bb653f0f34a -> ../../sdgこのコマンドを実行すると、SBD デバイスごとに 3 つのデバイス ID が一覧表示されます。 scsi-3 で始まる ID を使用することをお勧めします。 前の例では、ID は次のようになります。
- /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2
- /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d
- /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65
[1] SBD デバイスを作成します。
iSCSI デバイスのデバイス ID を使用して、1 つ目のクラスター ノードに新しい SBD デバイスを作成します。
sudo sbd -d /dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2 -1 60 -4 120 create複数の SBD デバイスを使用する場合は、2 つ目と 3 つ目の SBD デバイスも作成します。
sudo sbd -d /dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d -1 60 -4 120 create sudo sbd -d /dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 -1 60 -4 120 create
[A] SBD の構成を調整します
SBD の構成ファイルを開きます。
sudo vi /etc/sysconfig/sbdSBD デバイスのプロパティを変更し、Pacemaker の統合を有効にして、SBD の起動モードを変更します。
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2;/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d;/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] 次のコマンドを実行して
softdogモジュールを読み込みます。modprobe softdog[A] 次のコマンドを実行して、ノードの再起動後に
softdogが自動的に読み込まれるようにします。echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] SBD サービスのタイムアウト値は既定では 90 秒に設定されます。 ただし、
SBD_DELAY_START値がyesに設定されている場合、SBD サービスは、msgwaitタイムアウトが終わるまで開始を遅延します。 そのため、SBD_DELAY_STARTが有効な場合は、SBD サービスのタイムアウト値がmsgwaitタイムアウトを超える必要があります。sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
SBD と Azure 共有ディスク
このセクションは、Azure 共有ディスクで SBD デバイスを使用する場合にのみ適用されます。
PowerShell を使用して共有ディスクを構成する
PowerShell を使用して Azure 共有ディスクを作成してアタッチするには、次の手順を実行します。 Azure CLI または Azure portal を使用してリソースをデプロイしたい場合は、「ZRS ディスクのデプロイ」も参照してください。
$ResourceGroup = "MyResourceGroup"
$Location = "MyAzureRegion"
$DiskSizeInGB = 4
$DiskName = "SBD-disk1"
$ShareNodes = 2
$LRSSkuName = "Premium_LRS"
$ZRSSkuName = "Premium_ZRS"
$vmNames = @("prod-cl1-0", "prod-cl1-1") # VMs to attach the disk
# ZRS Azure shared disk: Configure an Azure shared disk with ZRS for a premium shared disk
$zrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $ZRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$zrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $zrsDiskConfig
# Attach ZRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $zrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
# LRS Azure shared disk: Configure an Azure shared disk with LRS for a premium shared disk
$lrsDiskConfig = New-AzDiskConfig -Location $Location -SkuName $LRSSkuName -CreateOption Empty -DiskSizeGB $DiskSizeInGB -MaxSharesCount $ShareNodes
$lrsDataDisk = New-AzDisk -ResourceGroupName $ResourceGroup -DiskName $DiskName -Disk $lrsDiskConfig
# Attach LRS disk to cluster VMs
foreach ($vmName in $vmNames) {
$vm = Get-AzVM -ResourceGroupName $resourceGroup -Name $vmName
Add-AzVMDataDisk -VM $vm -Name $diskName -CreateOption Attach -ManagedDiskId $lrsDataDisk.Id -Lun 0
Update-AzVM -VM $vm -ResourceGroupName $resourceGroup -Verbose
}
Azure 共有ディスクの SBD デバイスをセットアップする
[A] クラスターと SBD パッケージをすべてのクラスター ノードにインストールします。
sudo yum install -y pcs pacemaker sbd fence-agents-sbd[A] アタッチされているディスクが利用可能であることを確認します。
lsblk # NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT # sda 8:0 0 4G 0 disk # sdb 8:16 0 64G 0 disk # ├─sdb1 8:17 0 500M 0 part /boot # ├─sdb2 8:18 0 63G 0 part # │ ├─rootvg-tmplv 253:0 0 2G 0 lvm /tmp # │ ├─rootvg-usrlv 253:1 0 10G 0 lvm /usr # │ ├─rootvg-homelv 253:2 0 1G 0 lvm /home # │ ├─rootvg-varlv 253:3 0 8G 0 lvm /var # │ └─rootvg-rootlv 253:4 0 2G 0 lvm / # ├─sdb14 8:30 0 4M 0 part # └─sdb15 8:31 0 495M 0 part /boot/efi # sr0 11:0 1 1024M 0 rom lsscsi # [0:0:0:0] disk Msft Virtual Disk 1.0 /dev/sdb # [0:0:0:2] cd/dvd Msft Virtual DVD-ROM 1.0 /dev/sr0 # [1:0:0:0] disk Msft Virtual Disk 1.0 /dev/sda # [1:0:0:1] disk Msft Virtual Disk 1.0 /dev/sdc[A] アタッチされている共有ディスクのデバイス ID を取得します。
ls -l /dev/disk/by-id/scsi-* | grep -i sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-14d534654202020200792c2f5cc7ef14b8a7355cb3cef0107 -> ../../sda # lrwxrwxrwx 1 root root 9 Jul 15 22:24 /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -> ../../sdaこのコマンドにより、アタッチされている共有ディスクのデバイス ID が一覧表示されます。 scsi-3 で始まる ID を使用することをお勧めします。 この例では、ID は /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 です。
[1] SBD デバイスを作成します
# Use the device ID from step 3 to create the new SBD device on the first cluster node sudo sbd -d /dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107 -1 60 -4 120 create[A] SBD の構成を調整します
SBD の構成ファイルを開きます。
sudo vi /etc/sysconfig/sbdSBD デバイスのプロパティを変更し、Pacemaker の統合を有効にして、SBD の起動モードを変更します
[...] SBD_DEVICE="/dev/disk/by-id/scsi-3600224800792c2f5cc7e55cb3cef0107" [...] SBD_PACEMAKER=yes [...] SBD_STARTMODE=always [...] SBD_DELAY_START=yes [...]
[A] 次のコマンドを実行して
softdogモジュールを読み込みます。modprobe softdog[A] 次のコマンドを実行して、ノードの再起動後に
softdogが自動的に読み込まれるようにします。echo softdog > /etc/modules-load.d/watchdog.conf systemctl restart systemd-modules-load[A] SBD サービスのタイムアウト値は既定では 90 秒に設定されます。 ただし、
SBD_DELAY_START値がyesに設定されている場合、SBD サービスは、msgwaitタイムアウトが終わるまで開始を遅延します。 そのため、SBD_DELAY_STARTが有効な場合は、SBD サービスのタイムアウト値がmsgwaitタイムアウトを超える必要があります。sudo mkdir /etc/systemd/system/sbd.service.d echo -e "[Service]\nTimeoutSec=144" | sudo tee /etc/systemd/system/sbd.service.d/sbd_delay_start.conf sudo systemctl daemon-reload systemctl show sbd | grep -i timeout # TimeoutStartUSec=2min 24s # TimeoutStopUSec=2min 24s
Azure フェンス エージェントの構成
フェンス デバイスは、Azure リソースのマネージド IDまたはサービス プリンシパルのいずれかを使用して、Azure に対する認可を行います。 ID 管理の方法に応じて、適切な手順に従います。
ID 管理を構成します
マネージド ID またはサービス プリンシパルを使用します。
マネージド ID (MSI) を作成するには、クラスター内の VM ごとにシステム割り当てマネージド ID を作成します。 システム割り当てマネージド ID が既に存在する場合は、それが使用されます。 現時点では、Pacemaker でユーザー割り当てマネージド ID を使用しないでください。 マネージド ID に基づくフェンス デバイスは、RHEL 7.9 および RHEL 8.x/RHEL 9.x でサポートされています。
フェンス エージェントのカスタム ロールを作成する
既定では、マネージド ID とサービス プリンシパルのどちらにも、Azure リソースにアクセスするためのアクセス許可はありません。 クラスターのすべての VM を開始および停止 (電源オフ) するアクセス許可をマネージド ID またはサービス プリンシパルに付与する必要があります。 まだカスタム ロールを作成していない場合は、PowerShell または Azure CLI を使って作成できます。
入力ファイルには次の内容を使用します。 コンテンツをサブスクリプションに合わせる必要があります。つまり、
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxとyyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyyをサブスクリプションの ID に置き換えます。 ご利用のサブスクリプションが 1 つしかない場合は、AssignableScopesの 2 つ目のエントリは削除してください。{ "Name": "Linux Fence Agent Role", "description": "Allows to power-off and start virtual machines", "assignableScopes": [ "/subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "/subscriptions/yyyyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy" ], "actions": [ "Microsoft.Compute/*/read", "Microsoft.Compute/virtualMachines/powerOff/action", "Microsoft.Compute/virtualMachines/start/action" ], "notActions": [], "dataActions": [], "notDataActions": [] }カスタム ロールを割り当てる
マネージド ID またはサービス プリンシパルを使用します。
最後のセクションで作成したカスタム ロール
Linux Fence Agent Roleをクラスター VM の各マネージド ID に割り当てます。 各 VM のシステム割り当てマネージド ID には、クラスター VM のリソースごとにロールを割り当てる必要があります。 詳細については、[Azure portal を使用してリソースにマネージド ID アクセスを割り当てる] を参照してください。 各 VM のマネージド ID ロールの割り当てにすべてのクラスター VM が含まれていることを確認します。重要
マネージド ID による認可の割り当てと削除は、有効になるまで遅延する場合があることに注意してください。
クラスターのインストール
コマンドまたは RHEL 7 と RHEL 8/RHEL 9 の構成の違いは、ドキュメントでマークされています。
[A] RHEL HA アドオンをインストールします。
sudo yum install -y pcs pacemaker nmap-ncat[A] RHEL 9.x で、クラウド デプロイ用のリソース エージェントをインストールします。
sudo yum install -y resource-agents-cloud[A] フェンス デバイスを使用している場合は、Azure フェンス エージェントに基づいて、fence-agents パッケージをインストールします。
sudo yum install -y fence-agents-azure-arm重要
フェンス エージェントのサービス プリンシパル名ではなく、Azure リソースのマネージド ID を使用することを希望するお客様には、次のバージョンの Azure Fence Agent (またはそれ以降) をおすすめします。
- RHEL 8.4: fence-agents-4.2.1-54.el8.
- RHEL 8.2: fence-agents-4.2.1-41.el8_2.4
- RHEL 8.1: fence-agents-4.2.1-30.el8_1.4
- RHEL 7.9: fence-agents-4.2.1-41.el7_9.4.
重要
RHEL 9 では、Azure Fence Agent の問題を回避するために、次のパッケージ バージョン (またはそれ以降) をおすすめします。
- fence-agents-4.10.0-20.el9_0.7
- fence-agents-common-4.10.0-20.el9_0.6
- ha-cloud-support-4.10.0-20.el9_0.6.x86_64.rpm
Azure Fence Agent のバージョンを確認します。 必要に応じて、最低限必要なバージョン以降に更新します。
# Check the version of the Azure Fence Agent sudo yum info fence-agents-azure-arm重要
Azure Fence Agent を更新する必要があり、カスタム ロールを使用している場合は、カスタム ロールを更新してアクション powerOff を含めるようにします。 詳細については、「フェンス エージェントのカスタム ロールを作成する」を参照してください。
[A] ホスト名解決を設定します。
DNS サーバーを使用するか、すべてのノードの
/etc/hostsファイルを変更することができます。 この例では、/etc/hostsファイルを使用する方法を示します。 次のコマンドの IP アドレスとホスト名を置き換えます。重要
クラスター構成でホスト名を使用している場合は、信頼性の高いホスト名解決が不可欠です。 名前が使用できず、クラスターのフェールオーバーの遅延につながる可能性がある場合、クラスター通信は失敗します。
/etc/hostsを使用する利点は、単一障害点になる可能性もある DNS からクラスターを独立させられることです。sudo vi /etc/hosts/etc/hostsに次の行を挿入します。 お使いの環境に合わせて IP アドレスとホスト名を変更します。# IP address of the first cluster node 10.0.0.6 prod-cl1-0 # IP address of the second cluster node 10.0.0.7 prod-cl1-1[A]
haclusterのパスワードを同じパスワードに変更します。sudo passwd hacluster[A] Pacemaker のファイアウォール規則を追加します。
クラスター ノード間のすべてのクラスターの通信用に、次のファイアウォール規則を追加します。
sudo firewall-cmd --add-service=high-availability --permanent sudo firewall-cmd --add-service=high-availability[A] 基本的なクラスター サービスを有効にします。
次のコマンドを実行し、Pacemaker サービスを有効にして、それを開始します。
sudo systemctl start pcsd.service sudo systemctl enable pcsd.service[1] Pacemaker クラスターを作成します。
次のコマンドを実行し、ノードを認証してクラスターを作成します。 トークンを 30000 に設定してメモリ保持メンテナンスを可能にします。 詳細については、Linux のこの記事を参照してください。
RHEL 7.x でクラスターをビルドしている場合は、次のコマンドを使用します。
sudo pcs cluster auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup --name nw1-azr prod-cl1-0 prod-cl1-1 --token 30000 sudo pcs cluster start --allRHEL 8.x/RHEL 9.x でクラスターをビルドしている場合は、次のコマンドを使用します。
sudo pcs host auth prod-cl1-0 prod-cl1-1 -u hacluster sudo pcs cluster setup nw1-azr prod-cl1-0 prod-cl1-1 totem token=30000 sudo pcs cluster start --all次のコマンドを実行して、クラスターの状態を確認します。
# Run the following command until the status of both nodes is online sudo pcs status # Cluster name: nw1-azr # WARNING: no stonith devices and stonith-enabled is not false # Stack: corosync # Current DC: prod-cl1-1 (version 1.1.18-11.el7_5.3-2b07d5c5a9) - partition with quorum # Last updated: Fri Aug 17 09:18:24 2018 # Last change: Fri Aug 17 09:17:46 2018 by hacluster via crmd on prod-cl1-1 # # 2 nodes configured # 0 resources configured # # Online: [ prod-cl1-0 prod-cl1-1 ] # # No resources # # Daemon Status: # corosync: active/disabled # pacemaker: active/disabled # pcsd: active/enabled[A] 予想される票を設定します。
# Check the quorum votes pcs quorum status # If the quorum votes are not set to 2, execute the next command sudo pcs quorum expected-votes 2ヒント
マルチノード クラスター (2 つ以上のノードを持つクラスター) をビルドしている場合は、投票を 2 に設定しないでください。
[1] 同時フェンス アクションを許可します。
sudo pcs property set concurrent-fencing=true
Pacemaker クラスターにフェンス デバイスを作成する
ヒント
- 2 ノードの Pacemaker クラスター内でのフェンス レースを回避するには、
priority-fencing-delayクラスター プロパティを構成します。 このプロパティを使用すると、スプリット ブレイン シナリオが発生したときに、リソースの優先度の合計が高いノードをフェンスする際に、さらに遅延が発生するようになります。 詳細については、実行中のリソースが最も少ないクラスター ノードの Pacemaker によるフェンスに関するページを参照してください。 priority-fencing-delayプロパティは、Pacemaker バージョン 2.0.4-6.el8 以降および 2 ノード クラスターに適用されます。priority-fencing-delayクラスター プロパティを構成する場合は、pcmk_delay_maxプロパティを設定する必要はありません。 ただし、Pacemaker のバージョンが 2.0.4-6.el8 未満の場合は、pcmk_delay_maxプロパティを設定する必要があります。priority-fencing-delayクラスター プロパティを設定する方法については、SAP ASCS/ERS および SAP HANA スケールアップ HA のそれぞれのドキュメントを参照してください。
選択したフェンス メカニズムに基づいて、関連する手順のセクション (「フェンス デバイスとしての SBD」または「フェンス デバイスとしての Azure フェンス エージェント」のどちらか) に従います。
フェンス デバイスとしての SBD
[A] SBD サービスを有効にします
sudo systemctl enable sbd[1] iSCSI ターゲット サーバーまたは Azure 共有ディスクを使用して構成された SBD デバイスの場合は、次のコマンドを実行します。
sudo pcs property set stonith-timeout=144 sudo pcs property set stonith-enabled=true # Replace the device IDs with your device ID. pcs stonith create sbd fence_sbd \ devices=/dev/disk/by-id/scsi-3600140585d254ed78e24ec48b0decac2,/dev/disk/by-id/scsi-3600140587122bfc8a0b4006b538d0a6d,/dev/disk/by-id/scsi-36001405d2ddc548060c49e7bb792bb65 \ op monitor interval=600 timeout=15[1] クラスターを再起動します
sudo pcs cluster stop --all # It would take time to start the cluster as "SBD_DELAY_START" is set to "yes" sudo pcs cluster start --allNote
Pacemaker クラスターの起動時に次のエラーが発生した場合は、メッセージを無視できます。 または、
pcs cluster start --all --request-timeout 140コマンドを使用してクラスターを起動することもできます。エラー: node1/node2 のすべてのノードを起動できません: node1/node2 に接続できません。pcsd がそこで実行されているかどうかを確認するか、
--request-timeoutオプションを使用してより高いタイムアウトを設定してみてください (操作は 0 バイトを受信した状態で 60000 ミリ秒後にタイムアウトしました)
フェンス デバイスとしての Azure フェンス エージェント
[1] 両方のクラスター ノードにロールを割り当てたら、クラスターのフェンス デバイスを構成できます。
sudo pcs property set stonith-timeout=900 sudo pcs property set stonith-enabled=true[1] Azure フェンス エージェントにマネージド ID とサービス プリンシパルのどちらを使用しているかに応じて、適切なコマンドを実行します。
Note
Azure Government クラウドを使用する場合は、フェンス エージェントを構成するときに
cloud=オプションを指定する必要があります。 たとえば、米国政府の Azure クラウドの場合はcloud=usgovになります。 Azure Government クラウドでの RedHat サポートの詳細については、「RHEL 高可用性クラスターに関するポリシーのサポート - クラスター メンバーとしての Microsoft Azure Virtual Machines」を参照してください。ヒント
pcmk_host_mapのオプションは、RHEL ホスト名と Azure VM 名が同一でない場合のみ、このコマンドで必要です。 hostname:vm-name の形式でマッピングを指定します。 詳細については、pcmk_host_map でフェンス デバイスへのノード マッピングを指定する場合に使用する形式に関するページを参照してください。RHEL 7.x の場合は、次のコマンドを使用してフェンス デバイスを構成します。
sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600RHEL 8.x/9.x の場合は、次のコマンドを使用してフェンス デバイスを構成します。
# Run following command if you are setting up fence agent on (two-node cluster and pacemaker version greater than 2.0.4-6.el8) OR (HANA scale out) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 \ op monitor interval=3600 # Run following command if you are setting up fence agent on (two-node cluster and pacemaker version less than 2.0.4-6.el8) sudo pcs stonith create rsc_st_azure fence_azure_arm msi=true resourceGroup="resource group" \ subscriptionId="subscription id" pcmk_host_map="prod-cl1-0:prod-cl1-0-vm-name;prod-cl1-1:prod-cl1-1-vm-name" \ power_timeout=240 pcmk_reboot_timeout=900 pcmk_monitor_timeout=120 pcmk_monitor_retries=4 pcmk_action_limit=3 pcmk_delay_max=15 \ op monitor interval=3600
サービス プリンシパルの構成に基づいてフェンス デバイスを使用している場合は、「Azure フェンシングを使用した Pacemaker クラスターの SPN から MSI への変更」を参照し、マネージド ID 構成に変換する方法について学習します。
監視およびフェンス操作は逆シリアル化されます。 その結果、長時間実行されている監視操作と同時フェンス イベントがある場合、既に実行されている監視操作により、クラスターのフェールオーバーに遅延は発生しません。
ヒント
Azure フェンス エージェントには、パブリック エンドポイントへの送信接続が必要です。 考えられる解決策と詳細については、「標準 ILB を使用した VM のパブリック エンドポイント接続」を参照してください。
Azure のスケジュール化されたイベント用に Pacemaker を構成する
Azure では、スケジュール化されたイベントが提供されています。 スケジュール化されたイベントは、メタデータ サービスを介して送信され、このようなイベントに対して準備する時間をアプリケーションに与えます。
Pacemaker リソース エージェント azure-events-az では、スケジュール化された Azure イベントが監視されます。 イベントが検出され、リソース エージェントが別のクラスター ノードが使用可能であると判断した場合は、クラスター正常性属性が設定されます。
ノードにクラスター正常性属性が設定されると、場所制約がトリガーされ、health- で始まらない名前を持つすべてのリソースが、スケジュール化されたイベントを含むノードから移行されます。 影響を受けるクラスター ノードが実行中のクラスター リソースを解放すると、スケジュール化されたイベントが確認され、再起動などのアクションを実行できます。
[A]
azure-events-azエージェントのパッケージが既にインストールされ、最新であることを確認します。RHEL 8.x: sudo dnf info resource-agents RHEL 9.x: sudo dnf info resource-agents-cloud最小バージョンの要件:
- RHEL 8.4:
resource-agents-4.1.1-90.13 - RHEL 8.6:
resource-agents-4.9.0-16.9 - RHEL 8.8:
resource-agents-4.9.0-40.1 - RHEL 9.0:
resource-agents-cloud-4.10.0-9.6 - RHEL 9.2 以降:
resource-agents-cloud-4.10.0-34.1
- RHEL 8.4:
[1] Pacemaker 内でリソースを構成します。
#Place the cluster in maintenance mode sudo pcs property set maintenance-mode=true[1] Pacemaker クラスター正常性ノードの戦略と制約を設定します。
sudo pcs property set node-health-strategy=custom sudo pcs constraint location 'regexp%!health-.*' \ rule score-attribute='#health-azure' \ defined '#uname'重要
次の手順で説明するリソース以外に、
health-で始まるクラスター内の他のリソースは定義しないでください。[1] クラスター属性の初期値を設定します。 各クラスター ノードおよびマジョリティ メーカー VM を含むスケールアウト環境に対して実行します。
sudo crm_attribute --node prod-cl1-0 --name '#health-azure' --update 0 sudo crm_attribute --node prod-cl1-1 --name '#health-azure' --update 0[1] Pacemaker 内でリソースを構成します。 リソースが
health-azureで始まることを確認します。sudo pcs resource create health-azure-events \ ocf:heartbeat:azure-events-az \ op monitor interval=10s timeout=240s \ op start timeout=10s start-delay=90s sudo pcs resource clone health-azure-events allow-unhealthy-nodes=true failure-timeout=120sPacemaker クラスターのメンテナンス モードを解除します。
sudo pcs property set maintenance-mode=false有効化中にエラーをクリアし、
health-azure-eventsリソースがすべてのクラスター ノードで正常に開始されたことを確認します。sudo pcs resource cleanupスケジュール化されたイベントに対する初回クエリの実行には、最大 2 分かかることがあります。 スケジュール化されたイベントを使用した Pacemaker テストでは、クラスター VM の再起動または再デプロイ アクションを使用できます。 詳細については、「スケジュールされたイベント」を参照してください。
オプションのフェンス構成
ヒント
このセクションは、特殊なフェンス デバイス fence_kdump を構成する必要がある場合にのみ適用されます。
VM 内で診断情報を収集する必要がある場合は、フェンス エージェント fence_kdump に基づいて別のフェンス デバイスを構成すると有用な場合があります。 fence_kdump エージェントでは、他のフェンス メソッドが呼び出される前に、kdump クラッシュ復旧に入ったノードを検出してクラッシュ復旧サービスを完了できるようにすることができます。 fence_kdump は、SBD や Azure VM 使用時の Azure フェンス エージェントのような、従来のフェンス メカニズムに代わるものではないことに注意してください。
重要
fence_kdump が第 1 レベルのフェンス デバイスとして構成されている場合、それによってフェンス操作で遅延が発生し、アプリケーション リソースのフェールオーバーでそれぞれ遅延が発生することに注意してください。
クラッシュ ダンプが正常に検出された場合、フェンスはクラッシュ復旧サービスが完了するまで遅延されます。 失敗したノードが到達不能な場合や応答しない場合は、構成されている繰り返しの回数と、fence_kdump のタイムアウトによって決まる時間だけフェンスが遅延されます。 詳細については、「Red Hat Pacemaker クラスターで fence_kdump を構成する方法」を参照してください。
提案されている fence_kdump のタイムアウトは、実際の環境に合わせて調整する必要がある場合があります。
fence_kdump フェンスを構成するのは、VM 内で診断情報を収集する必要がある場合のみとし、必ず SBD や Azure フェンス エージェントのような従来のフェンス方式と組み合わせることをお勧めします。
以下の Red Hat KB には、fence_kdump フェンスの構成に関する重要な情報が含まれています。
- 「Red Hat Pacemaker クラスターで fence_kdump を構成する方法」を参照してください。
- 「Pacemaker を使用する RHEL クラスターでフェンス レベルを構成および管理する方法」を参照してください。
- 「2.0.14 よりも古い kexec-tools を使用すると "X 秒後にタイムアウトします" と表示されて RHEL 6 または 7 HA クラスターで fence_kdump が失敗する」を参照してください。
- 既定のタイムアウトを変更する方法については、「RHEL 6、7、8 HA アドオンで使用するために kdump を構成する方法」を参照してください。
fence_kdumpの使用時にフェールオーバーの遅延を減らす方法については、「fence_kdump 構成の追加時に予想されるフェールオーバーの遅延を減らすことができるか」を参照してください。
Azure Fence Agent の構成に加えて以下のオプションの手順を実行し、第 1 レベルのフェンス構成として fence_kdump を追加します。
[A]
kdumpがアクティブになっていて、構成されていることを確認します。systemctl is-active kdump # Expected result # active[A]
fence_kdumpフェンス エージェントをインストールします。yum install fence-agents-kdump[1] クラスター内に
fence_kdumpフェンス デバイスを作成します。pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" timeout=30[1] フェンス レベルを構成して、
fence_kdumpフェンス メカニズムが最初に動作するようにします。pcs stonith create rsc_st_kdump fence_kdump pcmk_reboot_action="off" pcmk_host_list="prod-cl1-0 prod-cl1-1" pcs stonith level add 1 prod-cl1-0 rsc_st_kdump pcs stonith level add 1 prod-cl1-1 rsc_st_kdump # Replace <stonith-resource-name> to the resource name of the STONITH resource configured in your pacemaker cluster (example based on above configuration - sbd or rsc_st_azure) pcs stonith level add 2 prod-cl1-0 <stonith-resource-name> pcs stonith level add 2 prod-cl1-1 <stonith-resource-name> # Check the fencing level configuration pcs stonith level # Example output # Target: prod-cl1-0 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name> # Target: prod-cl1-1 # Level 1 - rsc_st_kdump # Level 2 - <stonith-resource-name>[A] ファイアウォールを通過する
fence_kdumpのために必要なポートを許可します。firewall-cmd --add-port=7410/udp firewall-cmd --add-port=7410/udp --permanent[A]
kexec-toolsの一部のバージョンでタイムアウトによるfence_kdumpの失敗が発生しないように、/etc/kdump.confでfence_kdump_nodesの構成を実行します。 詳細については、「kexec-tools バージョン 2.0.15 以降の使用時に fence_kdump_nodes が指定されていないと fence_kdump がタイムアウトする」と、「2.0.14 より前のバージョンの kexec-tools の使用時に RHEL 6 または 7 の高可用性クラスターで "X 秒後にタイムアウトします" と表示されて fence_kdump が失敗する」を参照してください。 ここでは、2 ノード クラスターの構成例を示します。/etc/kdump.confで変更を加えた後に、kdump イメージを再生成する必要があります。 再生成するには、kdumpサービスを再起動します。vi /etc/kdump.conf # On node prod-cl1-0 make sure the following line is added fence_kdump_nodes prod-cl1-1 # On node prod-cl1-1 make sure the following line is added fence_kdump_nodes prod-cl1-0 # Restart the service on each node systemctl restart kdump[A]
initramfsイメージ ファイルにfence_kdumpとhostsのファイルが含まれることを確認します。 詳細については、「Red Hat Pacemaker クラスターで fence_kdump を構成する方法」を参照してください。lsinitrd /boot/initramfs-$(uname -r)kdump.img | egrep "fence|hosts" # Example output # -rw-r--r-- 1 root root 208 Jun 7 21:42 etc/hosts # -rwxr-xr-x 1 root root 15560 Jun 17 14:59 usr/libexec/fence_kdump_sendノードをクラッシュさせて構成をテストします。 詳細については、「Red Hat Pacemaker クラスターで fence_kdump を構成する方法」を参照してください。
重要
クラスターが既に運用環境で使用中の場合は、ノードをクラッシュさせるとアプリケーションに影響があるため、それに応じてテストを計画します。
echo c > /proc/sysrq-trigger
次のステップ
- 「SAP のための Azure Virtual Machines の計画と実装」を参照してください。
- 「SAP のための Azure Virtual Machines のデプロイ」を参照してください。
- 「SAP のための Azure Virtual Machines DBMS のデプロイ」を参照してください。
- Azure VM 上の SAP HANA の HA を確保し、ディザスター リカバリーを計画する方法を確認するには、「Azure Virtual Machines 上の SAP HANA の高可用性」を参照してください。