2 - JavaScript を使用して検索インデックスを作成して読み込む
次の手順に従って、引き続き検索が有効な Web サイトを構築します。
- 検索リソースを作成する
- 新しいインデックスを作成する
- bulk=insert_book スクリプトと Azure SDK @azure/search-documents を使用して JavaScript でデータをインポートします。
Azure AI Search リソースを作成する
Azure CLI または Azure PowerShell を使用して、コマンド ラインから新しい検索リソースを作成します。 インデックスへの読み取りアクセスに使用するクエリ キーを取得し、オブジェクトの追加に使用される組み込みの管理キーを取得します。
デバイスに Azure CLI または Azure PowerShell がインストールされている必要があります。 デバイスのローカル管理者でない場合は、[Azure PowerShell] を選択し、Scope パラメーターを使用して現在のユーザーとして実行します。
注意
このタスクには、Azure CLI と Azure PowerShell 用の Visual Studio Code 拡張機能は必要ありません。 Visual Studio Code では、拡張機能のないコマンド ライン ツールが認識されます。
Visual Studio Code の ターミナル で、新しいターミナル を選択します。
Azure に接続します:
az login新しい検索サービスを作成する前に、サブスクリプションの既存のサービスを一覧表示します:
az resource list --resource-type Microsoft.Search/searchServices --output table使用するサービスがある場合は、名前を書き留め、次のセクションに進んでください。
新しい検索サービスを作成します。 次のコマンドレットをテンプレートとして使用し、リソース グループ、サービス名、レベル、リージョン、パーティション、レプリカを有効な値に置き換えます。 次のステートメントでは、前の手順で作成した "cognitive-search-demo-rg" リソース グループを使用し、"free" レベルを指定します。 Azure サブスクリプションに既に無料検索サービスがある場合は、代わりに "basic" などの課金対象レベルを指定します。
az search service create --name my-cog-search-demo-svc --resource-group cognitive-search-demo-rg --sku free --partition-count 1 --replica-count 1検索サービスへの読み取りアクセスを許可するクエリ キーを取得します。 検索サービスは、2 つの管理キーと 1 つのクエリ キーでプロビジョニングされます。 リソース グループと検索サービスの有効な名前を置き換えます。 後の手順でクライアント コードに貼り付けることができるように、クエリ キーをメモ帳にコピーします。
az search query-key list --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc検索サービス管理 API キーを取得します。 管理 API キーは、検索サービスへの書き込みアクセスを提供します。 管理キーのいずれかをメモ帳にコピーして、インデックスを作成して読み込む一括インポート手順で使用できるようにします。
az search admin-key show --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc
Search 用の一括インポート スクリプトを準備する
ESM スクリプトでは、Azure AI Search 用の Azure SDK を使用します。
Visual Studio Code で、サブディレクトリ
search-website-functions-v4/bulk-insert内のbulk_insert_books.jsファイルを開き、次の変数を実際の値に置き換えて、Azure Search SDK による認証を行います。- YOUR-SEARCH-RESOURCE-NAME
- YOUR-SEARCH-ADMIN-KEY
import fetch from 'node-fetch'; import Papa from 'papaparse'; import { SearchClient, SearchIndexClient, AzureKeyCredential } from '@azure/search-documents'; // Azure AI Search resource settings const SEARCH_ENDPOINT = 'https://YOUR-RESOURCE-NAME.search.windows.net'; const SEARCH_ADMIN_KEY = 'YOUR-RESOURCE-ADMIN-KEY'; // Azure AI Search index settings const SEARCH_INDEX_NAME = 'good-books'; import SEARCH_INDEX_SCHEMA from './good-books-index.json' assert { type: 'json' }; // Data settings const BOOKS_URL = 'https://raw.githubusercontent.com/Azure-Samples/azure-search-sample-data/main/good-books/books.csv'; const BATCH_SIZE = 1000; // Create Search service client // used to upload docs into Index const client = new SearchClient( SEARCH_ENDPOINT, SEARCH_INDEX_NAME, new AzureKeyCredential(SEARCH_ADMIN_KEY) ); // Create Search service Index client // used to create new Index const clientIndex = new SearchIndexClient( SEARCH_ENDPOINT, new AzureKeyCredential(SEARCH_ADMIN_KEY) ); // Insert docs into Search Index // in batch const insertData = async (data) => { let batch = 0; let batchArray = []; for (let i = 0; i < data.length; i++) { const row = data[i]; // Convert string data to typed data // Types are defined in schema batchArray.push({ id: row.book_id, goodreads_book_id: parseInt(row.goodreads_book_id), best_book_id: parseInt(row.best_book_id), work_id: parseInt(row.work_id), books_count: !row.books_count ? 0 : parseInt(row.books_count), isbn: row.isbn, isbn13: row.isbn13, authors: row.authors.split(',').map((name) => name.trim()), original_publication_year: !row.original_publication_year ? 0 : parseInt(row.original_publication_year), original_title: row.original_title, title: row.title, language_code: row.language_code, average_rating: !row.average_rating ? 0 : parseFloat(row.average_rating), ratings_count: !row.ratings_count ? 0 : parseInt(row.ratings_count), work_ratings_count: !row.work_ratings_count ? 0 : parseInt(row.work_ratings_count), work_text_reviews_count: !row.work_text_reviews_count ? 0 : parseInt(row.work_text_reviews_count), ratings_1: !row.ratings_1 ? 0 : parseInt(row.ratings_1), ratings_2: !row.ratings_2 ? 0 : parseInt(row.ratings_2), ratings_3: !row.ratings_3 ? 0 : parseInt(row.ratings_3), ratings_4: !row.ratings_4 ? 0 : parseInt(row.ratings_4), ratings_5: !row.ratings_5 ? 0 : parseInt(row.ratings_5), image_url: row.image_url, small_image_url: row.small_image_url }); console.log(`${i}`); // Insert batch into Index if (batchArray.length % BATCH_SIZE === 0) { await client.uploadDocuments(batchArray); console.log(`BATCH SENT`); batchArray = []; } } // Insert any final batch into Index if (batchArray.length > 0) { await client.uploadDocuments(batchArray); console.log(`FINAL BATCH SENT`); batchArray = []; } }; const bulkInsert = async () => { // Download CSV Data file const response = await fetch(BOOKS_URL, { method: 'GET' }); if (response.ok) { console.log(`book list fetched`); const fileData = await response.text(); console.log(`book list data received`); // convert CSV to JSON const dataObj = Papa.parse(fileData, { header: true, encoding: 'utf8', skipEmptyLines: true }); console.log(`book list data parsed`); // Insert JSON into Search Index await insertData(dataObj.data); console.log(`book list data inserted`); } else { console.log(`Couldn\t download data`); } }; // Create Search Index async function createIndex() { SEARCH_INDEX_SCHEMA.name = SEARCH_INDEX_NAME; const result = await clientIndex.createIndex(SEARCH_INDEX_SCHEMA); } await createIndex(); console.log('index created'); await bulkInsert(); console.log('data inserted into index');プロジェクト ディレクトリのサブディレクトリ
search-website-functions-v4/bulk-insertのために Visual Studio で統合ターミナルを開き、次のコマンドを実行して依存関係をインストールします。npm install
Search 用の一括インポート スクリプトを実行する
プロジェクト ディレクトリのサブディレクトリ
search-website-functions-v4/bulk-insertに Visual Studio の統合ターミナルを引き続き使用し、bulk_insert_books.jsスクリプトを実行します。npm startコードを実行すると、コンソールに進行状況が表示されます。
アップロードが完了すると、コンソールに出力される最後のステートメントは "done" になります。
新しい検索インデックスを確認する
アップロードが完了すると、検索インデックスを使用できるようになります。 Azure portal で新しいインデックスを確認します。
Azure portal で、前の手順で作成した検索サービスを見つけます。
左側の [インデックス] を選択し、適切なブックのインデックスを選択します。
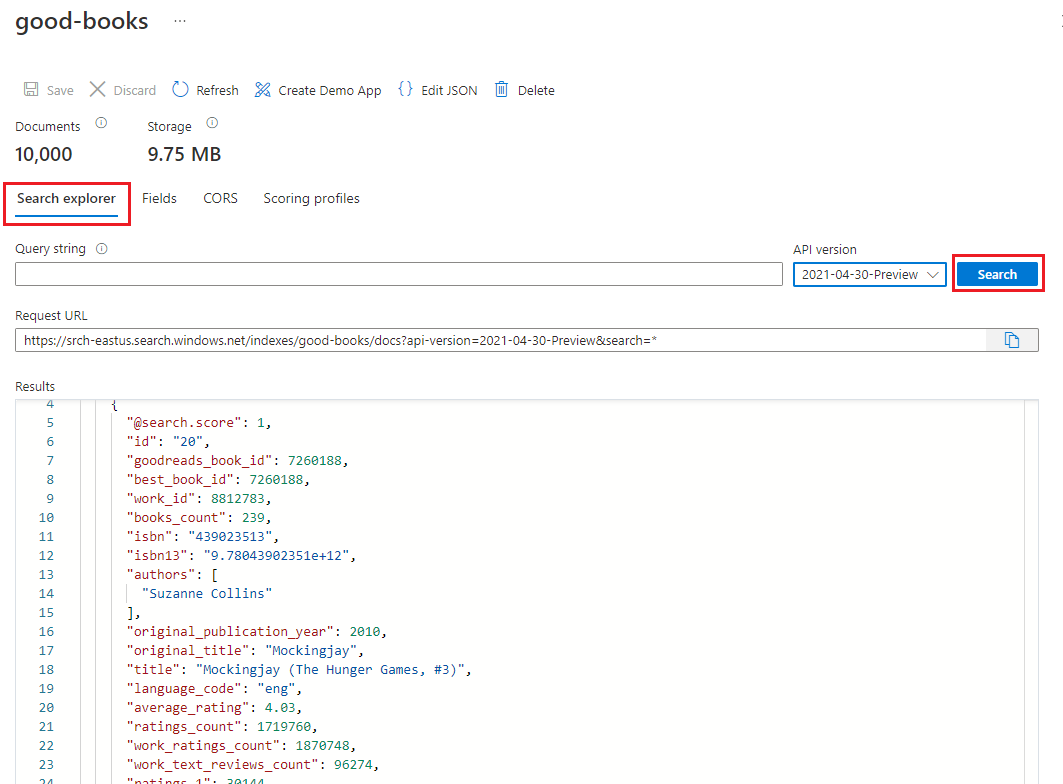
既定では、[検索エクスプローラー] タブにインデックスが開きます。[検索] を選択して、インデックスからドキュメントを返します。


一括インポート ファイルの変更をロールバックする
次の git コマンドを Visual Studio Code 統合ターミナルの bulk-insert ディレクトリで使用して、変更をロールバックします。 これらはチュートリアルを続ける上で必要ありません。これらのシークレットをリポジトリに保存したりプッシュしたりしないでください。
git checkout .
Search リソース名をコピーする
Search リソース名をメモします。 これは、Azure 関数アプリを自分の Search リソースに接続するために必要になります。
注意事項
Azure 関数内で自分の Search 管理者キーを使用したくなるかもしれませんが、それでは最小特権の原則に沿っていません。 Azure 関数では、クエリ キーを使用して最小特権に準拠します。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示