Service Fabric で一般的なシナリオを診断する
この記事では、Service Fabric での監視と診断の領域でユーザーが遭遇した一般的なシナリオについて説明します。 示されているシナリオには、Service Fabric の 3 つのレイヤーであるアプリケーション、クラスター、およびインフラストラクチャがすべて含まれています。 各ソリューションでは、それぞれのシナリオを完了するために Application Insights、Azure Monitor ログ、Azure 監視ツールが使用されます。 各ソリューションの手順では、Service Fabric のコンテキストで Application Insights と Azure Monitor ログを使用する方法の概要をユーザーに説明します。
注意
この記事は最近、Log Analytics ではなく Azure Monitor ログという用語を使うように更新されました。 ログ データは引き続き Log Analytics ワークスペースに格納され、同じ Log Analytics サービスによって収集されて分析されます。 Azure Monitor のログの役割をより適切に反映させるために、用語を更新しています。 詳しくは、Azure Monitor の用語の変更に関するページをご覧ください。
前提条件と推奨事項
この記事のソリューションでは、次のツールを使用します。 これらを設定および構成しておくことをお勧めします。
- Service Fabric での Application Insights
- クラスターでの Azure Diagnostics の有効化
- Log Analytics ワークスペースを設定する
- パフォーマンス カウンターを追跡するための Log Analytics エージェント
アプリケーションのハンドルされない例外を表示するにはどうすればよいですか
アプリケーションが構成されている Application Insights リソースに移動します。
左上の [検索] をクリックします。 次に、隣のパネルで [フィルター] をクリックします。
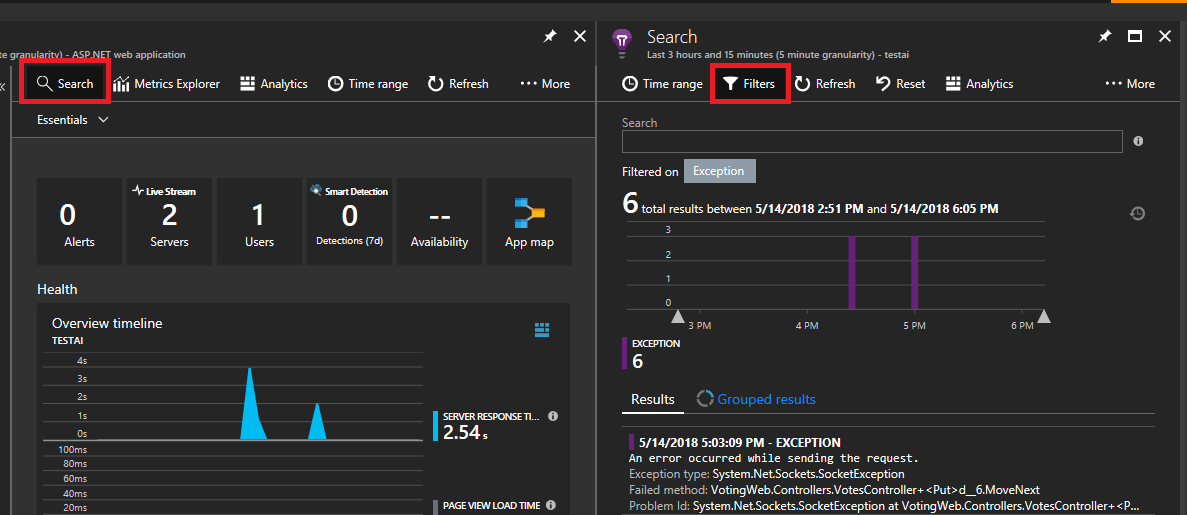
さまざまな種類のイベント (トレース、要求、カスタム イベント) が表示されます。 [例外] をフィルターとして選択します。
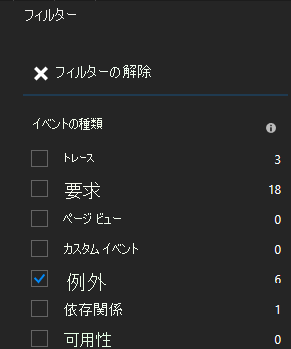
Service Fabric Application Insights SDK を使用している場合、一覧にある例外をクリックすると、サービス コンテキストなどの詳細を確認できます。
サービスで使用された HTTP 呼び出しを表示する方法を教えてください
同じ Application Insights リソースで、例外ではなく "要求" でフィルターを行って、実行されたすべての要求を表示できます。
Service Fabric Application Insights SDK を使用している場合、互いに接続されたサービスの視覚表現と、成功/失敗した要求の数を確認できます。 左側の [アプリケーション マップ] をクリックします。
![AI の [アプリケーション マップ] ブレード](media/service-fabric-diagnostics-common-scenarios/app-map-blade.png)
![AI の [アプリケーション マップ]](media/service-fabric-diagnostics-common-scenarios/app-map-new.png)
アプリケーション マップの詳細については、アプリケーション マップのドキュメントをご覧ください。
ノードがダウンした場合に通知されるアラートを作成する方法を教えてください
ノード イベントは Service Fabric クラスターによって追跡されます。 ServiceFabric(NameofResourceGroup) という名前の Service Fabric Analytics ソリューション リソースに移動します。
[概要] ブレードの下部にあるグラフをクリックします。
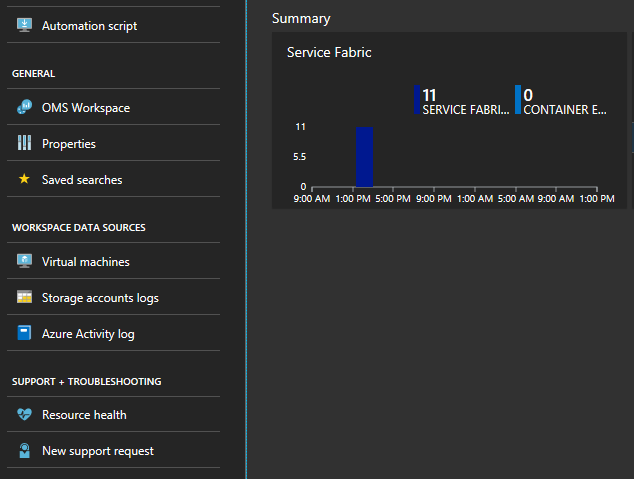
さまざまなメトリックを示す多数のグラフとタイルが表示されます。 いずれかのグラフをクリックすると、[ログ検索] に移動します。 ここで、クラスター イベントまたはパフォーマンス カウンターを照会できます。
次のクエリを入力します。 これらのイベント ID は、ノード イベントのリファレンスで確認できます。
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626上部の [新しいアラート ルール] をクリックします。これで、このクエリに基づいてイベントが到着した場合にいつも、選択した通信手段でアラートが届きます。
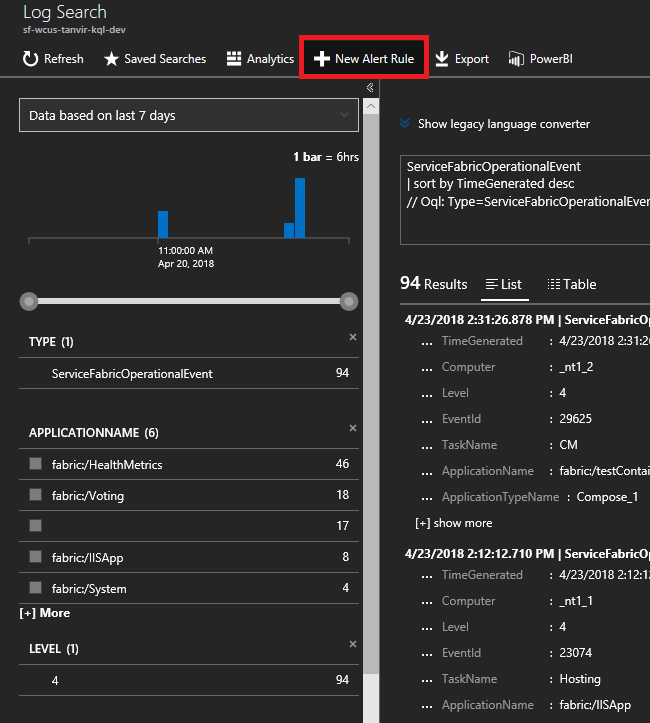
アプリケーション アップグレードのロールバックに関するアラートを受け取るには、どうすればよいですか
前と同じ [ログ検索] ウィンドウで、アップグレードのロールバックに関する次のクエリを入力します。 これらのイベント ID は、アプリケーション イベントのリファレンスで確認できます。
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624上部の [新しいアラート ルール] をクリックします。これで、このクエリに基づいてイベントが到着した場合にいつもアラートが届きます。
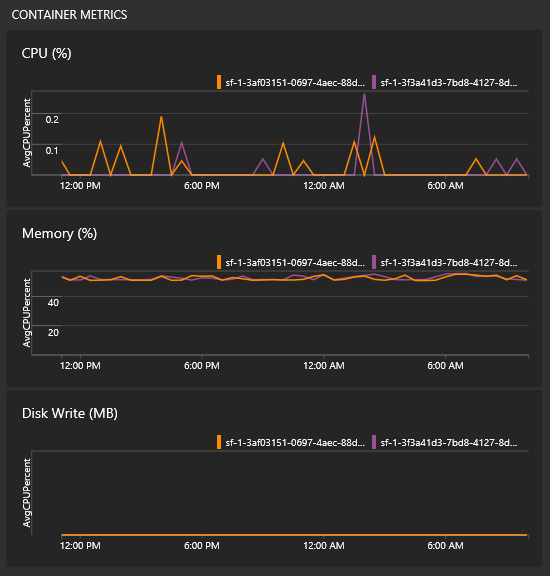
コンテナー メトリックの確認方法を教えてください
すべてのグラフと同じビューに、コンテナーのパフォーマンスに関するタイルがいくつか表示されます。 これらのタイルの作成には、Log Analytics エージェントとコンテナー監視ソリューションが必要です。
Note
コンテナーの内部からテレメトリをインストルメント化するには、コンテナー用の Application Insights NuGet パッケージを追加する必要があります。
パフォーマンス カウンターを監視するにはどうすればよいですか
Log Analytics エージェントをクラスターに追加したら、追跡したい特定のパフォーマンス カウンターを追加する必要があります。ポータルでソリューションのページから Log Analytics ワークスペースのページに移動します。ワークスペースのタブは左側のメニューにあります。
ワークスペースのページが表示されたら、同じく左側のメニューにある [詳細設定] をクリックします。
![Log Analytics の [詳細設定]](media/service-fabric-diagnostics-common-scenarios/advancedsettingsoms.png)
[データ] > [Windows パフォーマンス カウンター] (Linux マシンの場合は [データ] > [Linux パフォーマンス カウンター]) の順にクリックして、Log Analytics エージェント経由でノードから特定のカウンターを収集することを開始します。 追加するカウンターの形式の例を次に示します。
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor Timeこのクイック スタートでは、VotingData と VotingWeb というプロセス名が使用されます。そのため、これらのカウンターの追跡は次のようになります。
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes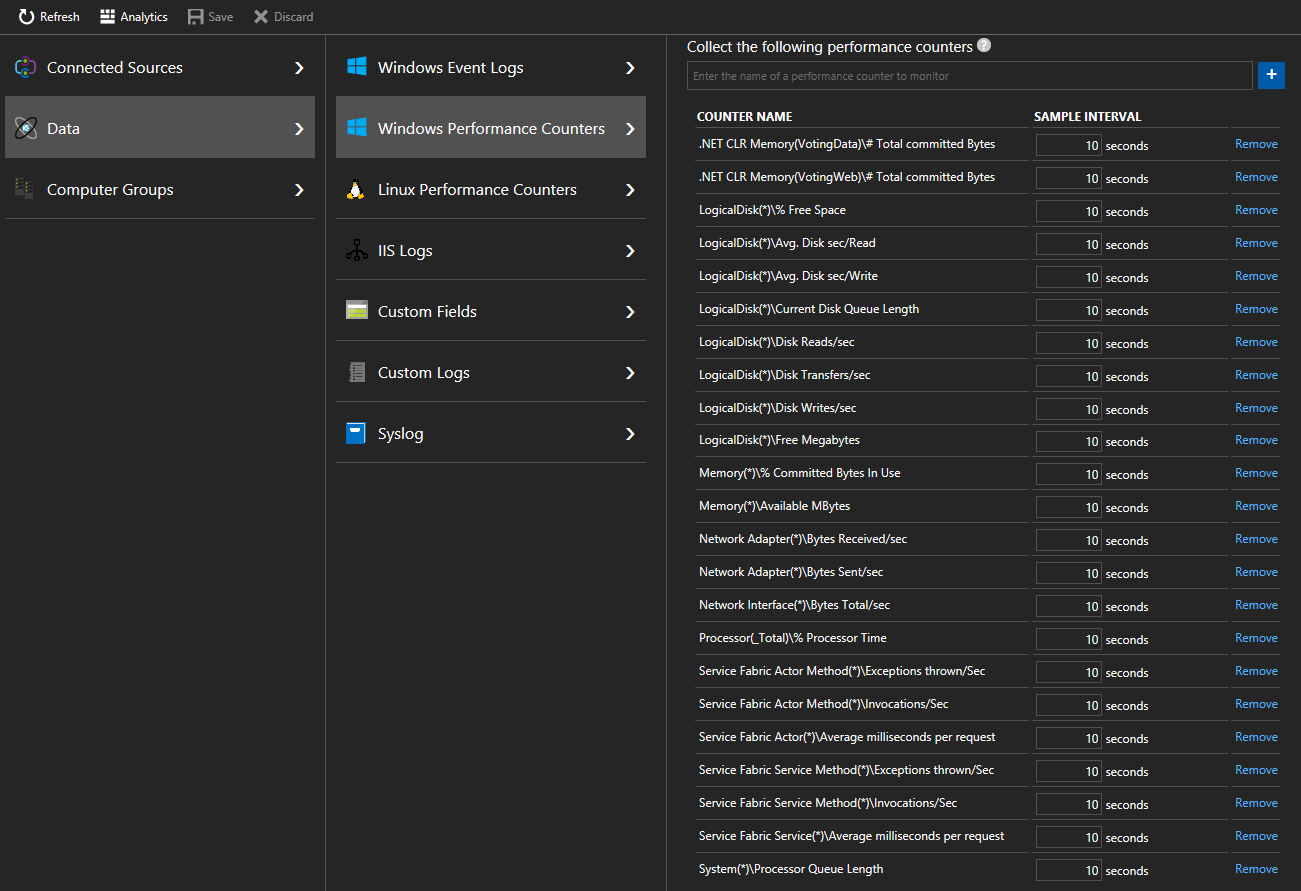
これで、インフラストラクチャで処理されているワークロードと、リソース使用率に基づいて設定された関連アラートを確認できるようになります。 たとえば、プロセッサ使用率の合計が 90% を上回るか、または 5% 未満になったときに通知されるアラートを設定したい場合があります。 この場合に使用するカウンター名は "% Processor Time" です。 これは、次のクエリのアラート ルールを作成することで実行できます。
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Reliable Services と Reliable Actors のパフォーマンスを追跡する方法を教えてください
アプリケーションで Reliable Services または Reliable Actors のパフォーマンスを追跡するには、Service Fabric アクター、Service Fabric アクター メソッド、Service Fabric サービス、Service Fabric サービス メソッドのカウンターも収集する必要があります。 信頼できるサービスと、収集する必要があるアクター パフォーマンス カウンターの例を次に示します
Note
現在、Service Fabric のパフォーマンス カウンターは Log Analytics エージェントでは収集できませんが、他の診断ソリューションでは収集できます
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Reliable Services と Reliable Actors に関するパフォーマンス カウンターの完全な一覧を確認するには、それぞれのリンクをご利用ください。
次のステップ
- 一般的なコード パッケージのアクティブ化エラーを参照する
- AI のアラートを設定して、パフォーマンスまたは使用状況の変化について通知を受けます
- Application Insights のスマート検出は、 AI に送信されるテレメトリのプロアクティブ分析を実行し、潜在的なパフォーマンスの問題を警告します
- 検出と診断に役立つ Azure Monitor ログのアラートについてさらに学習します。
- オンプレミス クラスター向けに、Azure Monitor ログでは、データを Azure Monitor ログに送信するために使用できるゲートウェイ (HTTP 転送プロキシ) を提供されています。 詳細については、「インターネットにアクセスできないコンピューターを Log Analytics ゲートウェイを使って Azure Monitor ログに接続する」を参照してください
- Azure Monitor ログの一部として提供されているログ検索とクエリ機能の詳細を確認します
- Azure Monitor ログとそれが提供するサービスの詳しい概要について、Azure Monitor ログとは何かに関するページで確認します
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示