クイックスタート: Azure Synapse Pipelines を使用してデータを取り込む (プレビュー)
このクイックスタートでは、データソースから Azure Synapse Data Explorer プールにデータを読み込む方法について説明します。
前提条件
Azure サブスクリプション。 無料の Azure アカウントを作成します。
Synapse Studio または Azure portal を使用して Data Explorer プールを作成します
Data Explorer データベースを作成します。
Synapse Studio の左側のペインで、 [データ] を選択します。
+ (新しいリソースの追加) >[Data Explorer プール] を選択し、次の情報を使用します。
設定 提案された値 説明 プール名 contosodataexplorer 使用する Data Explorer プールの名前 Name TestDatabase データベース名はクラスター内で一意である必要があります。 既定のリテンション期間 365 クエリにデータを使用できることが保証される期間 (日数) です。 期間は、データが取り込まれた時点から測定されます。 既定のキャッシュ期間 31 頻繁にクエリされるデータが、長期ストレージではなく SSD ストレージまたは RAM で利用できるように保持される期間 (日数) です。 [作成] を選択してデータベースを作成します。 通常、作成にかかる時間は 1 分未満です。
テーブルを作成する
- Synapse Studio の左側のウィンドウで、 [開発] を選択します。
- [KQL スクリプト] で、[+] (新しいリソースの追加) >[KQL スクリプト] を選びます。 右側のウィンドウで、スクリプト名を指定できます。
- [接続先] メニューで、[contosodataexplorer] を選択します。
- [データベースの使用] メニューで、 [TestDatabase] を選択します。
- 次のコマンドを貼り付け、 [実行] を選択してテーブルを作成します。
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)ヒント
テーブルが正常に作成されたことを確認します。 左側のペインで、[データ] を選び、contosodataexplorer のその他のメニューを選び、[最新の情報に更新] を選択します。 [contosodataexplorer] で [テーブル] を展開し、StormEvents テーブルが一覧に表示されていることを確認します。
クエリとデータ インジェストのエンドポイントを取得します。 リンクされたサービスを構成するには、クエリ エンドポイントが必要です。
Synapse Studio の左側のペインで、 [管理]>[Data Explorer プール] を選びます。
詳細を表示する データ エクスプローラー プールを選択します。
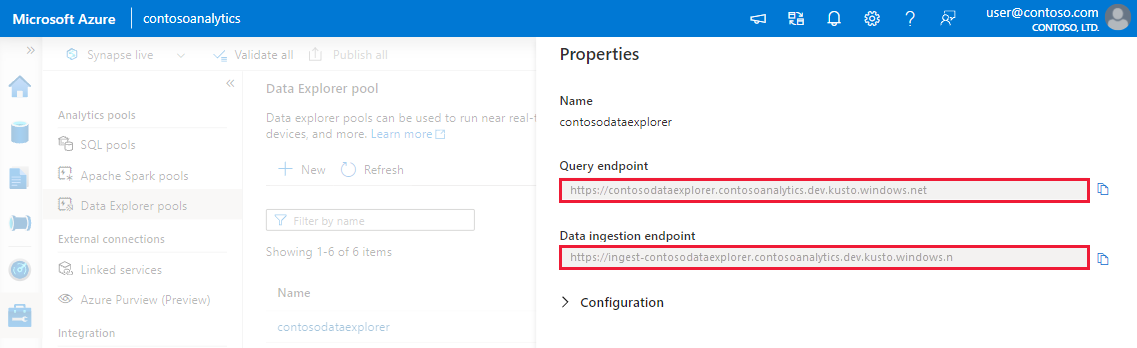
クエリとデータ インジェストのエンドポイントをメモします。 データ エクスプローラー プールへの接続を構成するときに、クラスターとしてクエリ エンドポイントを使用します。 データ インジェスト用に SDK を構成する場合は、データ インジェスト エンドポイントを使用します。
リンクされたサービスを作成する
Azure Synapse Analytics で、リンクされたサービスとは、他のサービスへの接続情報を定義した場所です。 このセクションでは、Azure Data Explorer のリンク サービスを作成します。
Synapse Studio の左側のペインで、 [管理]>[リンクされたサービス] の順に選択します。
[+新規] を選択します。
ギャラリーから [Azure Data Explorer] サービスを選択し、 [続行] を選択します。

[New Linked service](新しくリンクされたサービス) ページで、次の情報を使用します。
設定 提案された値 Description Name contosodataexplorerlinkedservice 新しい Azure Data Explorer のリンクされたサービスの名前。 認証方法 Managed Identity 新しいサービスの認証方法。 Account selection method (アカウントの選択方法) "手動で入力" クエリ エンドポイントを指定するメソッド。 エンドポイント https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net 以前にメモしたクエリ エンドポイント。 データベース TestDatabase データを取り込むデータベース。 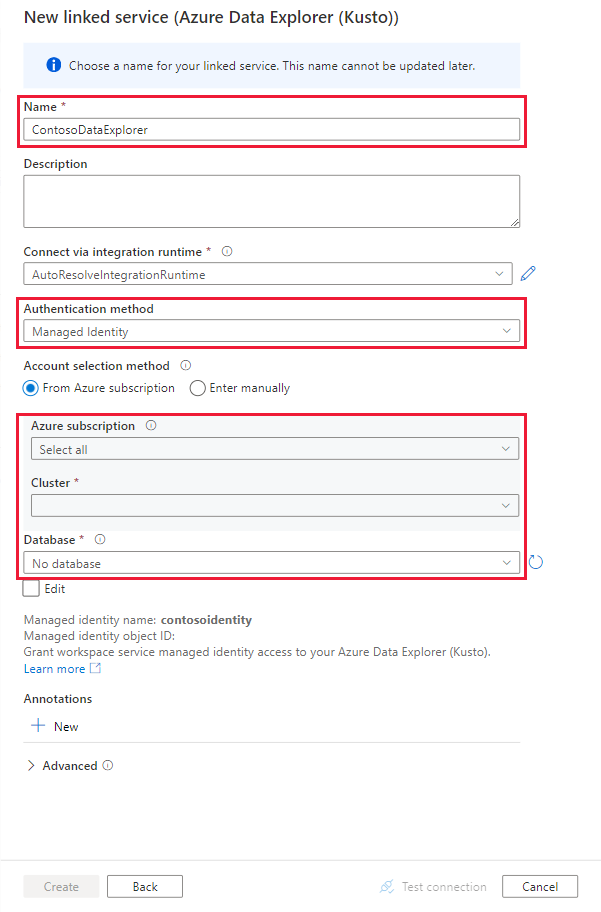
[テスト接続] を選択して設定を検証し、 [作成] を選択します。
データを取り込むパイプラインを作成する
パイプラインには、一連のアクティビティを実行するための論理フローが含まれています。 このセクションでは、優先ソースのデータを Data Explorer プールに取り込むコピー アクティビティを含むパイプラインを作成します。
Synapse Studio の左側のペインで、 [統合] を選択します。
[+] >[パイプライン] を選択します。 右側のペインで、パイプラインに名前を付けることができます。
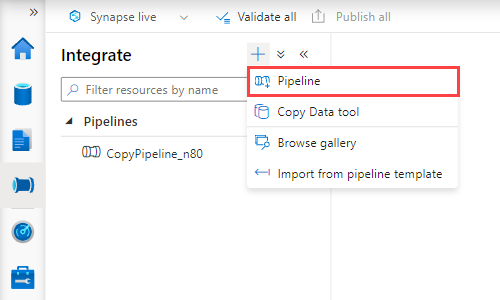
[アクティビティ]>[移動と変換] で、[データ コピー]をパイプライン キャンバスにドラッグします。
コピー アクティビティを選択し、 [ソース] タブにアクセスします。データのコピー元として、新しいソース データセットを選択または作成します。
[シンク] タブに移動します。 [新規] を選択して、新しいシンク データセットを作成します。
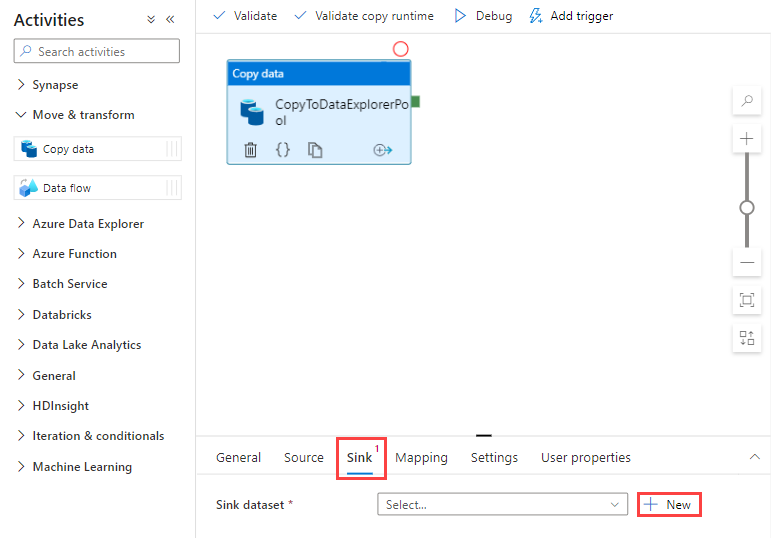
ギャラリーから [Azure Data Explorer] データセットを選択し、 [続行] を選択します。
[プロパティの設定] ウィンドウで、次の情報を使用してから [OK] を選択します。
設定 提案された値 Description Name AzureDataExplorerTable 新しいパイプラインの名前。 リンクされたサービス contosodataexplorerlinkedservice 前に作成した、リンクされたサービス。 テーブル StormEvents 前に作成したテーブル。 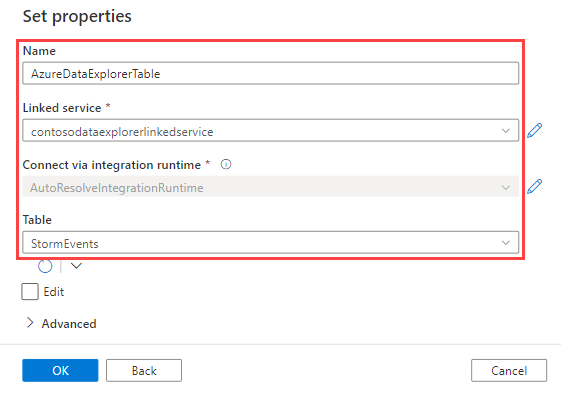
パイプラインを検証するには、ツール バーの [検証] を選択します。 パイプラインの検証の出力結果がページの右側に表示されます。
パイプラインをデバッグして発行する
パイプラインの構成が完了したら、成果物を発行する前にデバッグを実行することで、すべてが正しいことを確認できます。
ツールバーの [デバッグ] を選択します。 ウィンドウ下部の [出力] タブにパイプラインの実行の状態が表示されます。
パイプラインの実行に成功したら、上部のツール バーで [すべて発行] を選択します。 この操作により、作成したエンティティ (データセットとパイプライン) が Synapse Analytics サービスに発行されます。
[正常に発行されました] というメッセージが表示されるまで待機します。 通知メッセージを表示するには、右上にあるベル ボタンを選択します。
パイプラインをトリガーして監視する
このセクションでは、前の手順で発行したパイプラインを手動でトリガーします。
ツール バーの [トリガーの追加] を選択し、 [Trigger Now](今すぐトリガー) を選択します。 [Pipeline Run](パイプラインの実行) ページで [OK] を選択します。
左側のサイドバーにある [監視] タブに移動します。 手動トリガーによってトリガーされたパイプラインの実行が表示されます。
パイプラインの実行が正常に完了したら、 [パイプライン名] 列のリンクを選択してアクティビティの実行の詳細を表示するか、またはパイプラインを再実行します。 この例では、アクティビティが 1 つだけなので、一覧に表示されるエントリは 1 つのみです。
コピー操作の詳細を確認するには、 [アクティビティ名] 列の [詳細] リンク (眼鏡アイコン) を選択します。 ソースからシンクにコピーされるデータの量、データのスループット、実行ステップと対応する期間、使用される構成などの詳細を監視できます。
パイプラインの実行ビューに戻るには、上部の [すべてのパイプラインの実行] リンクを選択します。 [最新の情報に更新] を選択して、一覧を更新します。
データが Data Explorer プールに正しく書き込まれていることを確認します。