Azure Synapse Analytics の Apache Spark Advisor (プレビュー)
Apache Spark Advisor を使うと、Spark で実行されるコマンドとコードを分析し、Notebook の実行時にリアルタイムでアドバイスを表示することができます。 Spark Advisor には、よくある間違いをユーザーが回避できるように支援し、コード最適化のための推奨事項を提供し、エラー分析を実行し、失敗の根本原因を特定するのに役立つパターンが組み込まれています。
組み込みのアドバイス
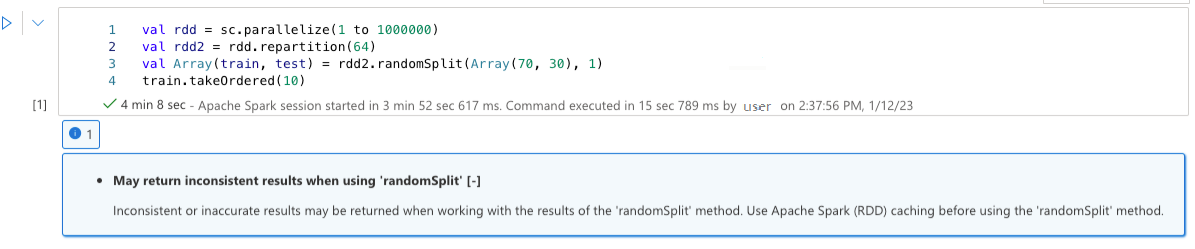
"randomSplit" を使用すると、一貫性のない結果が返されることがある
"randomSplit" メソッドの結果を操作するとき、一貫性のない結果または不正確な結果が返される可能性があります。 "randomSplit" メソッドを使う前に、Apache Spark (RDD) キャッシュを使います。
randomSplit() メソッドは、データ フレームに対して sample() を何回も実行することと同じであり、サンプルごとに、パーティション内のデータ フレームの再フェッチ、パーティション分割、並べ替えが行われます。 パーティション間のデータの分散と並べ替えの順序は、randomSplit() と sample() の両方に対して重要です。 データの再フェッチ時にいずれかが変化した場合、分割間で値の重複や欠落が発生する可能性があり、同じシードを使用する同じサンプルで異なる結果が生成される可能性があります。
これらの不整合はすべての実行で発生するわけではありませんが、それらを完全に排除するには、データ フレームのキャッシュ、列の再パーティション分割、または groupBy などの集計関数の適用を行います。
テーブルやビューの名前が既に使用されている
作成されるテーブルと同じ名前のビューが既に存在するか、作成されるビューと同じ名前のテーブルが既に存在します。 この名前がクエリまたはアプリケーションで使われていると、どちらが最初に作成されたかに関係なく、ビューのみが返されます。 競合を回避するには、テーブルまたはビューの名前を変更します。
ヒントを認識できない
選んだクエリに、認識されないヒントが含まれています。 ヒントのスペルが正しいことを確認します。
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
指定した関係の名前が見つからない
ヒントで指定されている関係が見つかりません。 関係のスペルが正しく、ヒントのスコープ内でアクセス可能であることを確認します。
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
クエリ内のヒントによって、別のヒントの適用が妨げられる
選んだクエリに、別のヒントが適用されるのを妨げるヒントが含まれています。
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
丸めエラーの伝達を減らすため "spark.advise.divisionExprConvertRule.enable" を有効にする
このクエリには、Double 型の式が含まれています。 構成 "spark.advise.divisionExprConvertRule.enable" を有効にすることをお勧めします。これは、除算式を減らし、丸めエラーの伝達を減らすのに役立ちます。
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
クエリのパフォーマンスを向上させるるため "spark.advise.nonEqJoinConvertRule.enable" を有効にする
このクエリには、クエリ内の "OR" 条件のために時間のかかる結合が含まれています。 構成 "spark.advise.nonEqJoinConvertRule.enable" を有効にすることをお勧めします。これは、"OR" 条件によってトリガーされる結合を SMJ または BHJ に変換して、このクエリを高速化するのに役立ちます。
小さなファイルの圧縮を使って差分テーブルを最適化する
このクエリは、多数の小さなファイルを含む差分テーブル上にあります。 クエリのパフォーマンスを高めるために、差分テーブルに対して OPTIMIZE コマンドを実行します。 詳細については、この記事を参照してください。
ZOrder を使って差分テーブルを最適化する
このクエリは差分テーブル上にあり、高度に選択的なフィルターが含まれています。 クエリのパフォーマンスを高めるために、差分テーブルに対して OPTIMIZE ZORDER BY コマンドを実行します。 詳細については、この記事を参照してください。
ユーザーの作業
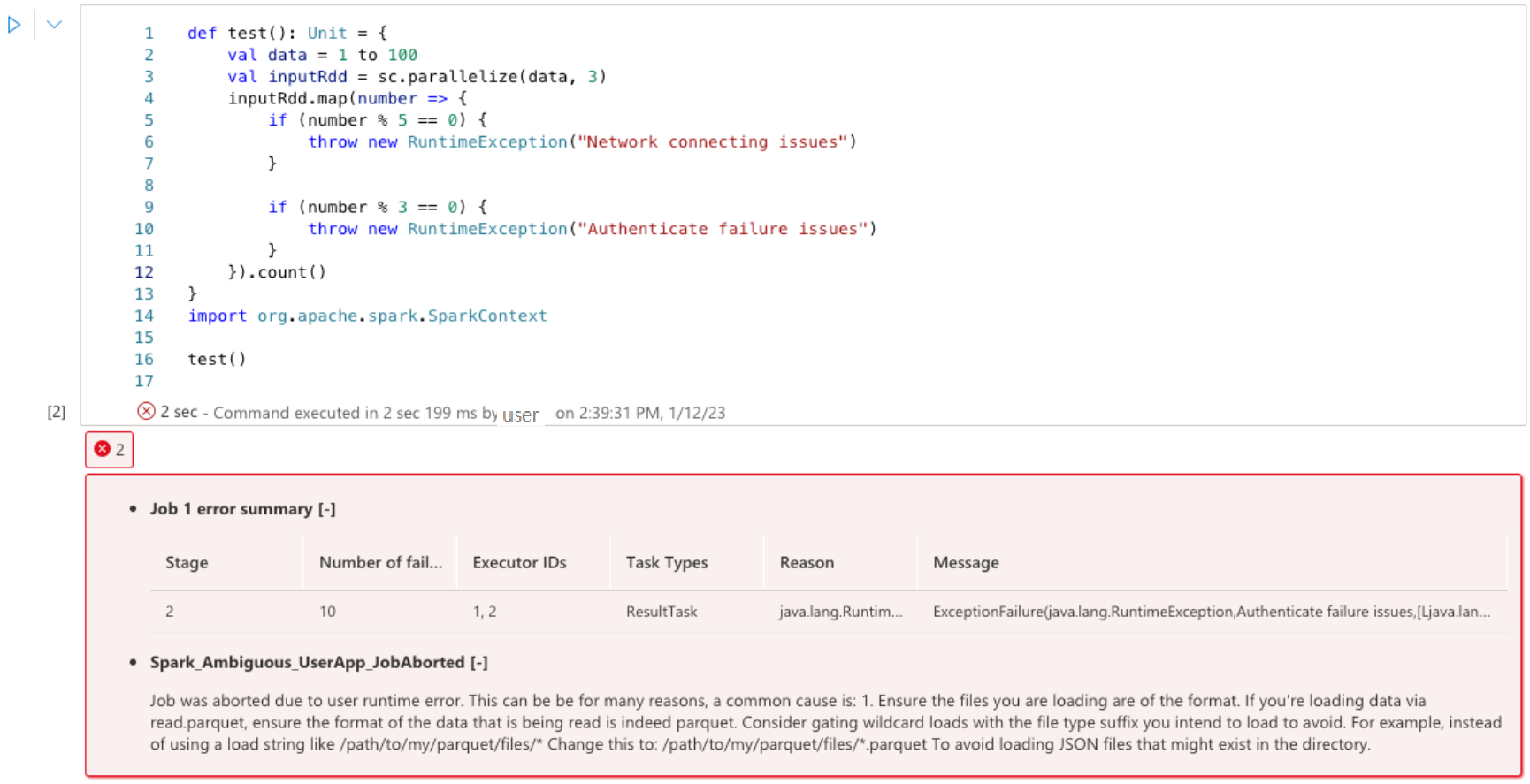
Apache Spark Advisor の Notebook のセル出力には、情報、警告、エラーなどのアドバイスがリアルタイムで表示されます。
Info
警告

エラー
次のステップ
Apache Spark アプリケーションの監視に関する詳細については、Synapse Studio での Apache Spark アプリケーションの監視に関する記事を参照してください。
ノートブックを作成する方法の詳細については、Synapse ノートブックを使用する方法に関する記事を参照してください。