クイックスタート: Apache Spark のジョブ定義を使用してデータを変換する
このクイックスタートでは、Azure Synapse Analytics で Apache Spark ジョブ定義を使用してパイプラインを作成します。
前提条件
- Azure サブスクリプション:Azure サブスクリプションをお持ちでない場合は、開始する前に無料の Azure アカウントを作成してください。
- Azure Synapse ワークスペース:「クイックスタート:Synapse ワークスペースを作成する」の手順に従い、Azure portal を使用して Synapse ワークスペースを作成します。
- Apache Spark ジョブ定義: 「チュートリアル: Synapse Studio で Apache Spark ジョブ定義を作成する」の手順に従い、Synapse ワークスペースで Apache Spark ジョブ定義を作成します。
Synapse Studio に移動する
Azure Synapse ワークスペースが作成された後、Synapse Studio を開く方法は 2 つあります。
- Azure portal で Synapse ワークスペースを開きます。 [はじめに] の下の [Synapse Studio を開く] カードで、[開く] を選択します。
- Azure Synapse Analytics を開き、ワークスペースにサインインします。
このクイックスタートでは、例として "sampletest" という名前のワークスペースを使用します。 自動的に Synapse Studio のホーム ページに移動します。
Apache Spark ジョブ定義を使用してパイプラインを作成する
パイプラインには、一連のアクティビティを実行するための論理フローが含まれています。 このセクションでは、Apache Spark ジョブ定義アクティビティを含んだパイプラインを作成します。
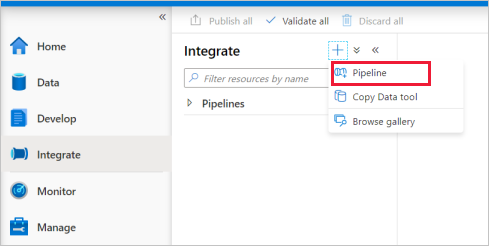
[統合] タブに移動します。パイプライン ヘッダーの横にあるプラス符号のアイコンを選択し、 [パイプライン] を選択します。
パイプラインの [プロパティ] 設定ページで、名前として「demo」と入力します。
[アクティビティ] ペインの [Synapse] で、 [Spark job definition](Spark ジョブ定義) をパイプライン キャンバス上にドラッグします。
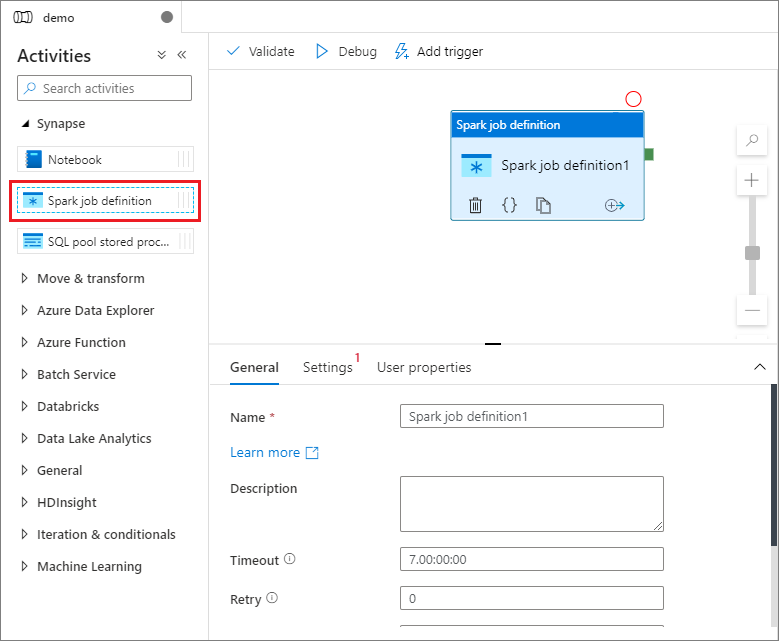
Apache Spark ジョブ定義キャンバスを設定する
Apache Spark ジョブ定義を作成すると、自動的に Spark ジョブ定義キャンバスに切り替わります。
全般設定
キャンバスで Spark ジョブ定義モジュールを選択します。
[全般] タブで、 [名前] に「sample」と入力します。
(省略可) 説明を入力することもできます。
タイムアウト: アクティビティを実行できる最大時間。 既定値は 7 日です。これは許容される最大時間でもあります。 形式は D.HH:MM:SS です。
再試行: 最大再試行回数。
再試行の間隔: 何秒おきに再試行するか。
セキュリティで保護された出力: オンにした場合、アクティビティからの出力がログにキャプチャされません。
セキュリティで保護された入力: オンにした場合、アクティビティからの入力がログにキャプチャされません。
![Spark ジョブ定義の [全般]](media/quickstart-transform-data-using-spark-job-definition/spark-job-definition-general.png)
Settings tab
このパネルでは、実行する Spark ジョブ定義を参照できます。
Spark ジョブ定義リストを展開し、既存の Apache Spark ジョブ定義を選択できます。 [New](新規) ボタンを選択して新しい Apache Spark ジョブ定義を作成し、実行する Spark ジョブ定義を参照することもできます。
(省略可能) Apache Spark ジョブ定義の情報が入力できます。 次の設定が空の場合は、Spark ジョブ定義自体の設定が実行するために使用され、次の設定が空でない場合は、これらの設定によって Spark ジョブ定義自体の設定が置き換えられます。
プロパティ 説明 Main definition file (メイン定義ファイル) ジョブに使用されるメイン ファイルです。 ストレージから PY/JAR/ZIP ファイルを選択します。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。
サンプル:abfss://…/path/to/wordcount.jarサブフォルダーからの参照 メイン定義ファイルのルート フォルダーからサブフォルダーをスキャンすると、これらのファイルが参照ファイルとして追加されます。 "jars"、"pyFiles"、"files"、または "archives" という名前のフォルダーがスキャンされ、フォルダー名では大文字と小文字が区別されます。 メイン クラス名 完全修飾識別子またはメイン定義ファイル内のメイン クラス。
サンプル:WordCountコマンド ライン引数 [New](新規) ボタンをクリックしてコマンドライン引数を追加できます。 コマンドライン引数を追加すると、Spark ジョブ定義で設定したコマンドライン引数がオーバーライドされることに注意してください。
サンプル:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultApache Spark プール 一覧から Apache Spark プールが選択できます。 Python コード リファレンス メイン定義ファイルの参照に使用される追加 Python コード ファイル。
ファイル (.py、.py3、.zip) を "pyFiles" プロパティに渡すことがサポートされています。 Spark ジョブ定義で定義されている "pyFiles" プロパティをオーバーライドします。参照ファイル メイン定義ファイル内で参照に使用される追加ファイル。 エグゼキューターを動的に割り当てる この設定は、Spark アプリケーションのエグゼキューターの割り当てに対する Spark 構成の動的割り当てプロパティにマップされます。 Executor の最小数 ジョブの指定された Spark プール内に割り当てられる Executor の最小数。 Executor の最大数 ジョブの指定された Spark プール内に割り当てられる Executor の最大数。 Driver size (ドライバー サイズ) ジョブ用の指定された Apache Spark プール内で提供される、ドライバーに使用するコアとメモリの数。 Spark の構成 「Spark Configuration - Application properties (Spark 構成 - アプリケーションのプロパティ)」と題するトピックに示されている Spark 構成プロパティの値を指定します。 ユーザーは、既定の構成とカスタマイズされた構成を使用できます。 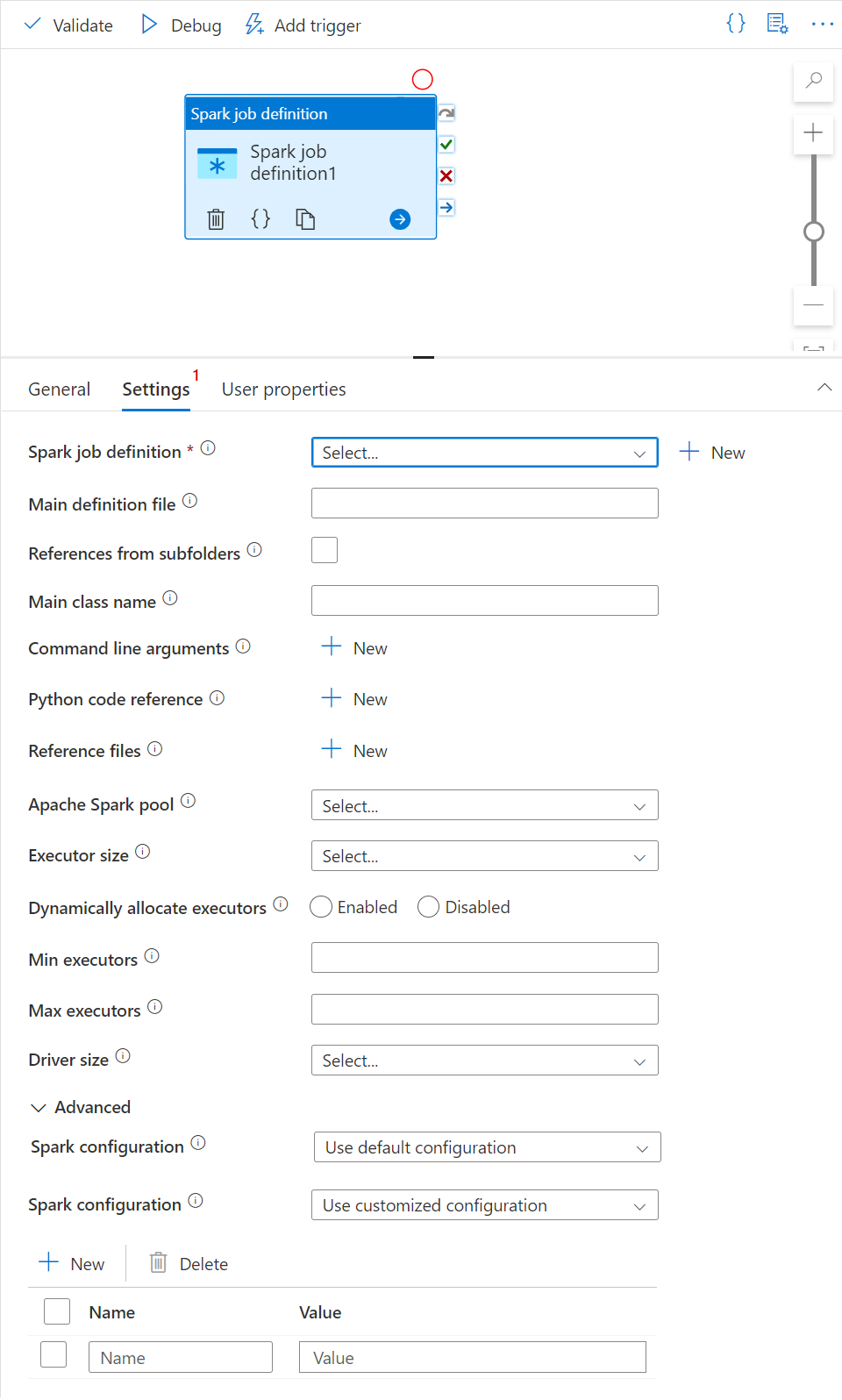
[動的なコンテンツの追加] ボタンをクリックするか、ショートカット キー Alt+Shift+D を押すことで動的コンテンツを追加できます。 [動的なコンテンツの追加] ページでは、式、関数、システム変数を自由に組み合わせて動的なコンテンツを追加できます。
[ユーザーのプロパティ] タブ
このパネルでは、Apache Spark ジョブ定義アクティビティのプロパティを追加できます。

次のステップ
次の記事に進んで、Azure Synapse Analytics のサポートを確認します。