Azure Synapse Analytics で Synapse ノートブックを作成、開発、管理する
Synapse ノートブックは、ライブ コード、視覚化、および説明テキストを含むファイルを作成するための Web インターフェイスです。 ノートブックは、アイデアを確認し、簡単な実験を使用してデータから分析情報を得るのに最適な場所です。 また、ノートブックは、データの準備、データの視覚化、機械学習、およびその他のビッグ データのシナリオで広く使用されています。
Synapse ノートブックでは、次のことができます。
- 設定作業をせずに使用を開始する。
- 組み込みのエンタープライズ セキュリティ機能を使用してデータを安全に保つ。
- 未加工の形式 (CSV、txt、JSON など) 全体のデータ、処理されたファイル形式 (parquet、Delta Lake、ORC など)、および Spark と SQL に対する SQL の表形式データ ファイルを分析する。
- 高度な作成機能と組み込みのデータの視覚化で生産性を高める。
この記事では、Synapse Studio でノートブックを使用する方法について説明します。
ノートブックを作成する
ノートブックを作成するには、2 つの方法があります。 新しいノートブックを作成することも、既存のノートブックをオブジェクト エクスプローラーから Synapse ワークスペースにインポートすることもできます。 Synapse ノートブックでは、標準の Jupyter Notebook IPYNB ファイルが認識されます。
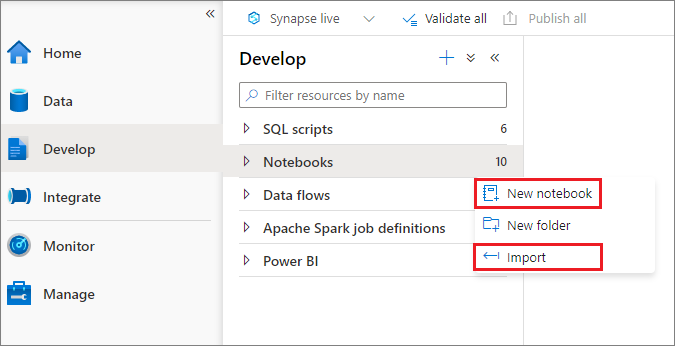
ノートブックを開発する
ノートブックは、個別にまたはグループとして実行できるコードまたはテキストの個々のブロックである、セルで構成されます。
ノートブックを開発するための豊富な操作が提供されます。
- セルを追加する
- 第一言語を設定する
- 複数の言語を使用する
- 一時テーブルを使用して言語間でデータを参照する
- IDE スタイルの IntelliSense
- コード スニペット
- ツールバー ボタンを使用してテキスト セルを書式設定する
- セル操作を元に戻す/やり直す
- コード セルのコメント化
- セルを移動する
- セルを削除する
- セル入力を折りたたむ
- セル出力を折りたたむ
- ノートブックのアウトライン
Note
ノートブックには、SparkSession が自動的に作成され、spark という変数に格納されます。 また、sc と呼ばれるSparkContext の変数もあります。 ユーザーはこれらの変数に直接アクセスでき、これらの変数の値を変更しないでください。
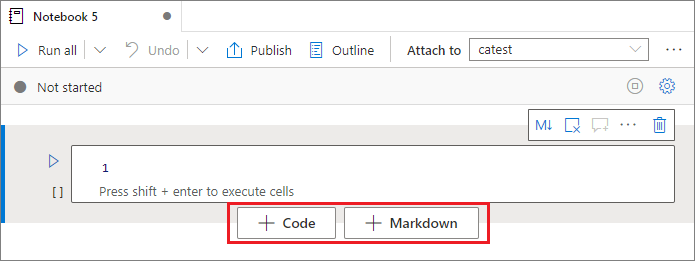
セルを追加する
ノートブックに新しいセルを追加するには、複数の方法があります。
2 つのセル間のスペースをポイントし、 [コード] または [Markdown] を選択します。
コマンド モードの aznb ショートカット キーを使用します。 現在のセルの上にセルを挿入するには、A キーを押します。 現在のセルの下にセルを挿入するには、B キーを押します。
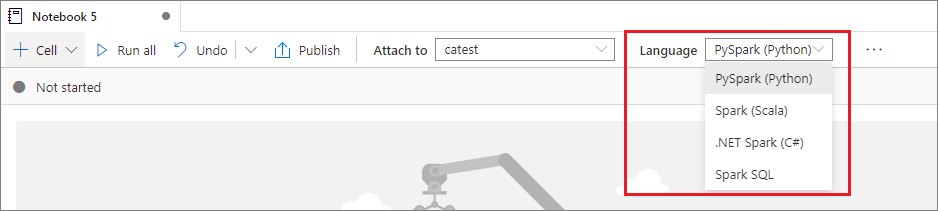
第一言語を設定する
Synapse ノートブックでは、次の 4 つの Apache Spark 言語がサポートされます。
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- .NET Spark (C#)
- SparkR (R)
上部のコマンド バーにあるドロップダウン リストから、新しく追加されたセルの第一言語を設定できます。
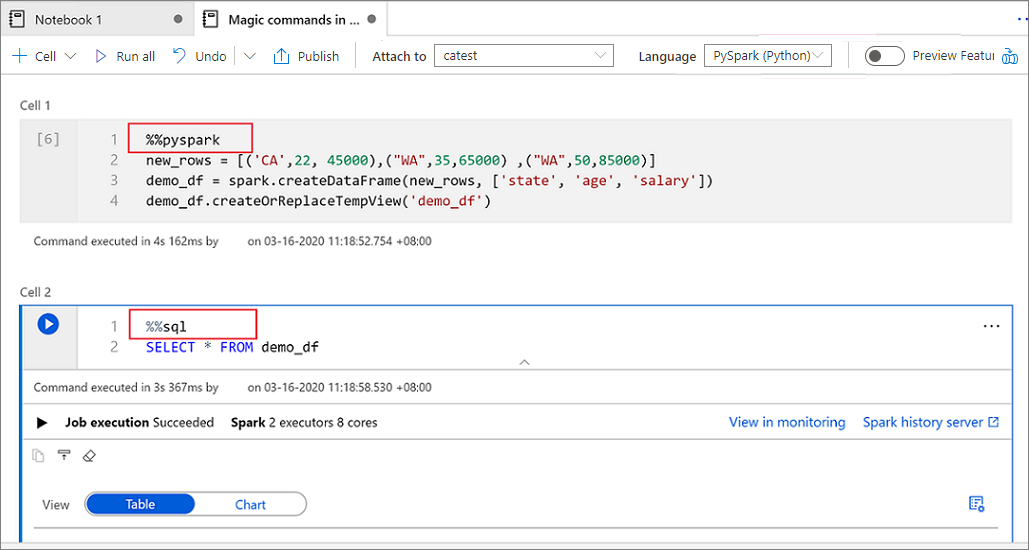
複数の言語を使用する
1 つのノートブックで、セルの先頭に正しい言語マジック コマンドを指定することで、複数の言語を使用できます。 次の表に、セルの言語を切り替えるマジック コマンドを一覧表示します。
| マジック コマンド | Language | 説明 |
|---|---|---|
| %%pyspark | Python | Spark コンテキストに対して、Python クエリを実行します。 |
| %%spark | Scala | Spark コンテキストに対して、Scala クエリを実行します。 |
| %%sql | SparkSQL | Spark コンテキストに対して、SparkSQL クエリを実行します。 |
| %%csharp | .NET for Spark C# | Spark コンテキストに対して、 .NET for Spark C# クエリを実行します。 |
| %%sparkr | R | Spark コンテキストに対して、R クエリを実行します。 |
次の図は、Spark(Scala) ノートブックで、 %%pyspark マジック コマンドを使用する PySpark クエリ、または %%sql マジック コマンドでの SparkSQL クエリの記述方法の例です。 ノートブックの第一言語が PySpark に設定されていることに注目してください。
一時テーブルを使用して言語間でデータを参照する
Synapse ノートブックでは、異なる言語間でデータや変数を直接参照することはできません。 Spark では、複数の言語間で一時テーブルを参照することができます。 以下は、回避策として Spark の一時テーブルを使用して、PySpark および SparkSQL で Scala DataFrame を読み取る方法の例です。
セル 1 で、Scala を使用して SQL プール コネクタから DataFrame を読み取り、一時テーブルを作成します。
%%spark val scalaDataFrame = spark.read.sqlanalytics("mySQLPoolDatabase.dbo.mySQLPoolTable") scalaDataFrame.createOrReplaceTempView( "mydataframetable" )セル 2 で、Spark SQL を使用してデータに対してクエリを実行します。
%%sql SELECT * FROM mydataframetableセル 3 では、PySpark のデータを使用します。
%%pyspark myNewPythonDataFrame = spark.sql("SELECT * FROM mydataframetable")
IDE スタイルの IntelliSense
Synapse ノートブックは、IDE スタイルの IntelliSense をセル エディターに取り込むために、Monaco エディターと統合されています。 構文の強調表示、エラー マーカー、および自動コード補完は、コードを記述したり、問題をより迅速に特定したりするために役立ちます。
IntelliSense の機能は、言語によって異なる成熟度レベルにあります。 次の表を使用して、サポートされている内容を確認してください。
| Languages | 構文の強調表示 | 構文のエラー マーカー | 構文のコード補完 | 変数のコード補完 | システム関数のコード補完 | ユーザー関数のコード補完 | スマート インデント | コードの折りたたみ |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | はい | イエス | イエス | イエス | イエス | イエス | イエス | はい |
| Spark (Scala) | はい | イエス | イエス | イエス | イエス | イエス | - | はい |
| SparkSQL | はい | イエス | イエス | イエス | はい | - | - | - |
| .NET for Spark (C#) | はい | イエス | イエス | イエス | イエス | イエス | イエス | はい |
注意
変数コード補完、システム関数コード補完、.NET for Spark のユーザー関数コード補完 (C#) を利用するには、アクティブな Spark セッションが必要です。
コード スニペット
Synapse ノートブックには、Spark セッションの構成、Spark DataFrame としてのデータの読み取り、matplotlib でのグラフの描画など、一般的に使用されるコード パターンの入力を容易にするコード スニペットが用意されています。
スニペットは、他の候補と一緒に IDE スタイルの IntelliSense のショートカット キーに表示されます。 コード スニペットの内容は、コード セル言語に準拠したものとなります。 使用可能なスニペットを確認するには、「Snippet」と入力するか、コード セル エディターのスニペットのタイトルに表示されるキーワードを入力します。 たとえば、「read」と入力すると、さまざまなデータ ソースからデータを読み取るスニペットの一覧が表示されます。

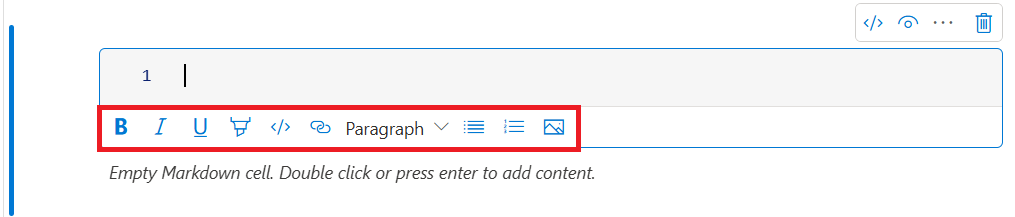
ツールバー ボタンを使用してテキスト セルを書式設定する
テキスト セル ツールバーの書式ボタンを使用して、一般的なマークダウン アクションを実行することができます。 これにはテキストの太字設定、テキストの斜体設定、ドロップダウンを使用した段落と見出し、コードの挿入、順序指定されていないリストの挿入、順序指定済みリストの挿入、ハイパーリンクの挿入、URL からの画像の挿入などが含まれます。
セル操作を元に戻す/やり直す
[元に戻す] / [やり直す] ボタンを選択するか、Z / Shift+Z キーを押して、最新のセル操作を取り消します。 これで、最大で 10 個の最新の過去のセル操作を元に戻すかやり直すことができます。

サポートされているセルを元に戻す操作:
- セルの挿入または削除: [元に戻す] を選択すると、削除操作を取り消すことができます。テキスト コンテンツはセルと共に保持されます。
- セルの順序を変更する。
- パラメーターを切り替える。
- コード セルと Markdown セルの間で変換を行う。
注意
セル内のテキスト操作とコード セルのコメント化操作は元に戻せません。 これで、最大で 10 個の最新の過去のセル操作を元に戻すかやり直すことができます。
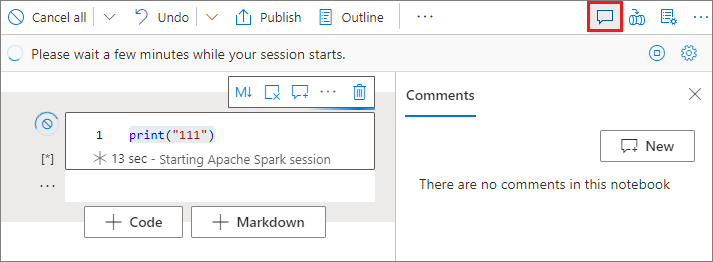
コード セルのコメント化
ノートブックのツール バーの [コメント] ボタンを選択して、 [コメント] ペインを開きます。
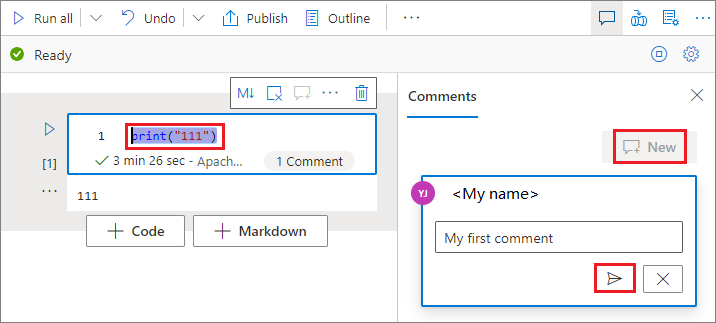
コード セル内のコードを選択し、 [コメント] ペインで [新規] をクリックし、コメントを追加してから、 [コメントの投稿] ボタンをクリックして保存します。
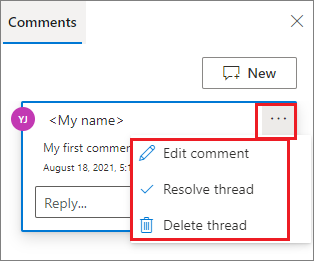
コメントの横にある [詳細] ボタンをクリックすると、コメントの編集、スレッドの解決、またはスレッドの削除を実行できます。
セルを移動する
セルの左側をクリックし、目的の位置までドラッグします。
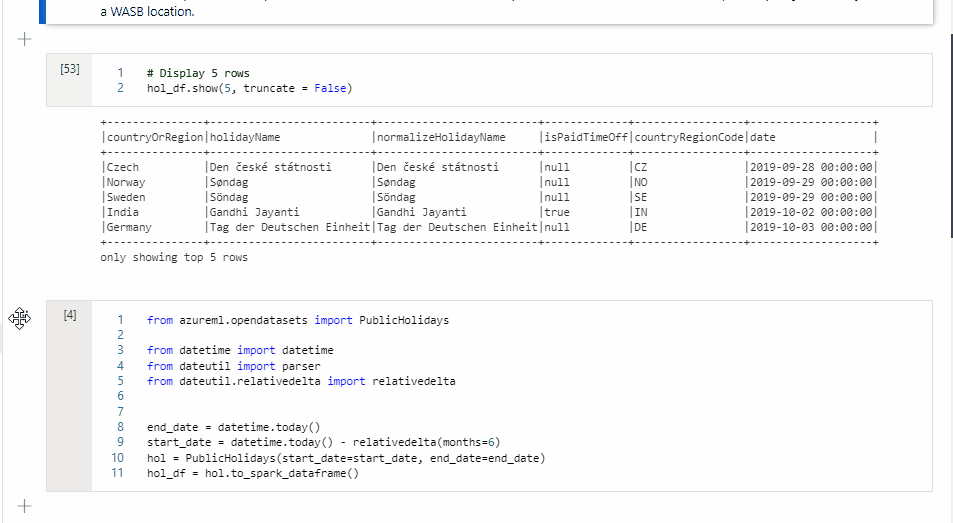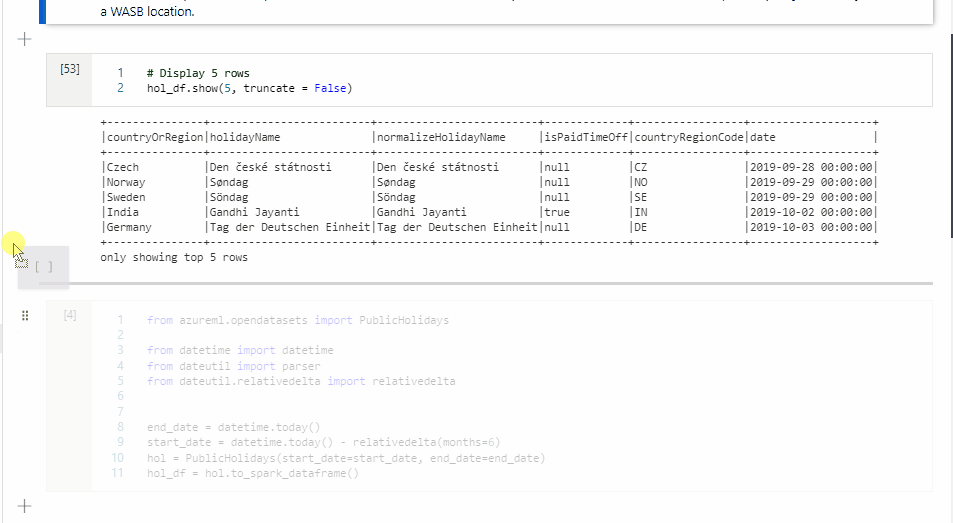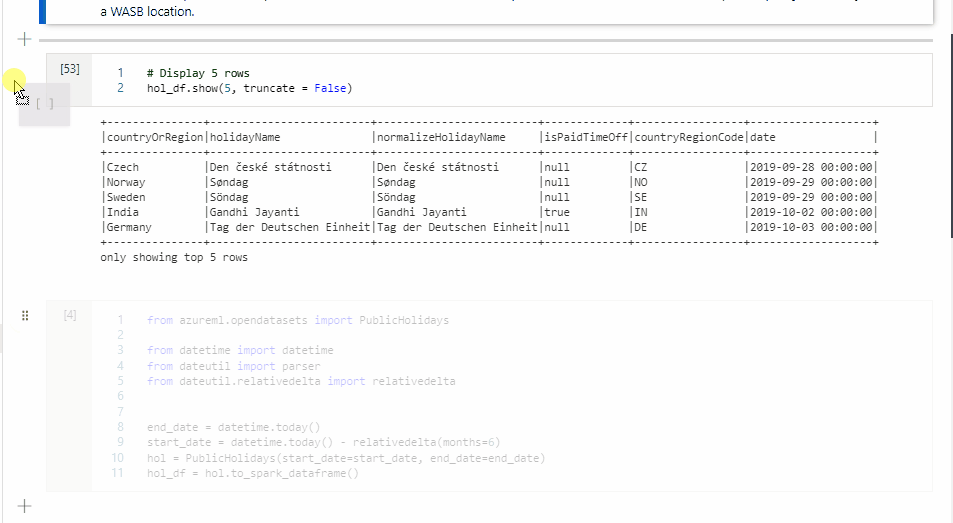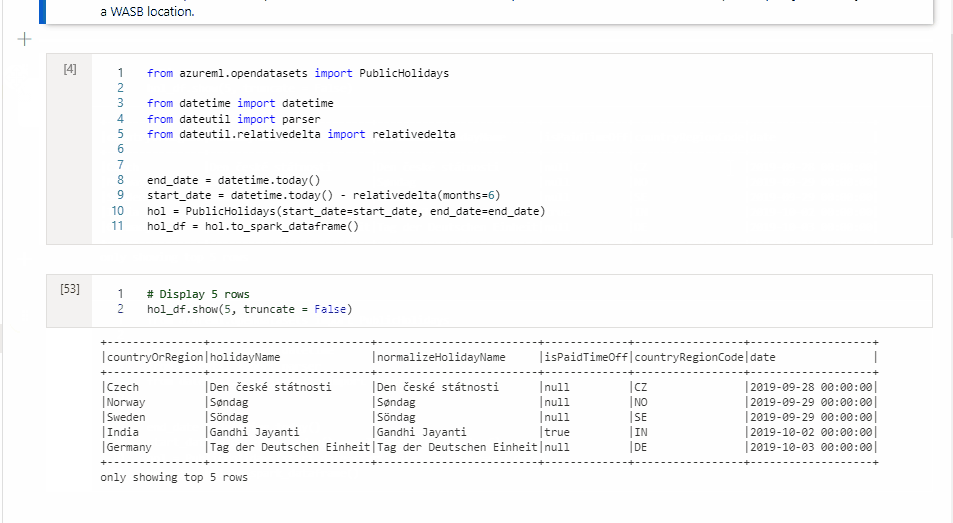
セルを削除する
セルを削除するには、セルの右側にある削除ボタンを選択します。
コマンド モードのショートカット キーを使用することもできます。 現在のセルを削除するには、Shift + D キーを押します。
セル入力を折りたたむ
セル ツールバーで [More commands](その他のコマンド) 省略記号 (...) を選択し、 [入力の非表示] を選択して、現在のセルの入力を折りたたみます。 これを展開するには、セルが折りたたまれている状態で [Show input](入力を表示する) を選択します。
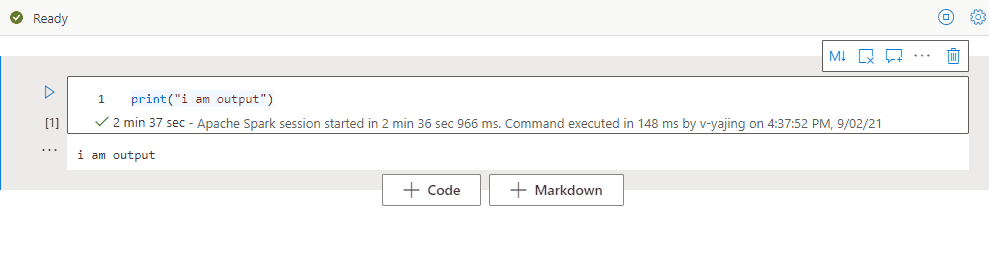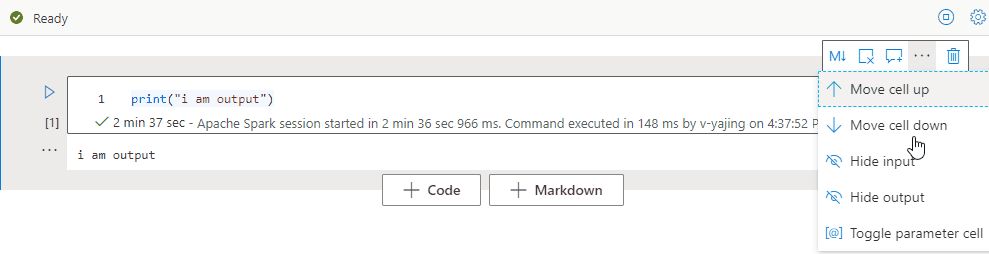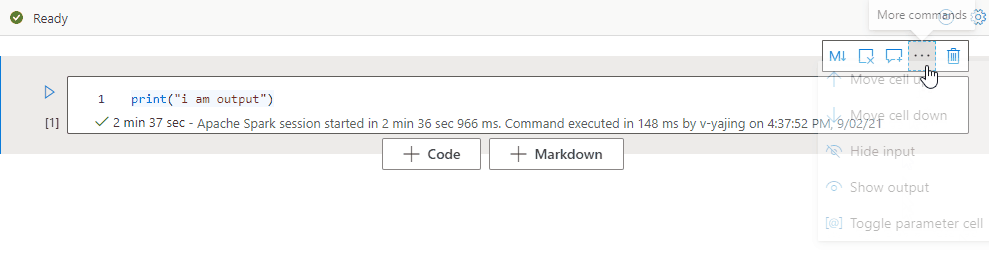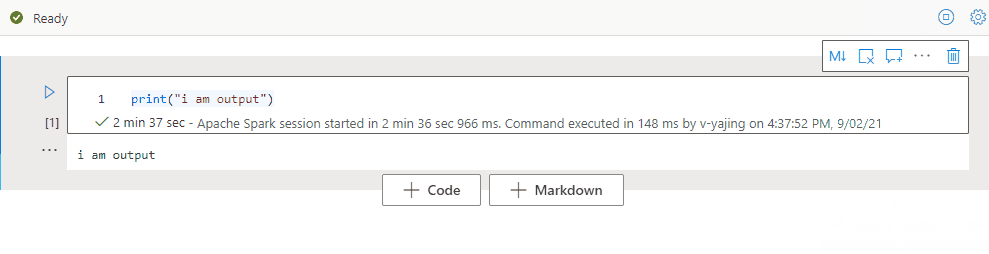
セル出力を折りたたむ
セル ツールバーで [More commands](その他のコマンド) 省略記号 (...) を選択し、 [出力の非表示] を選択して、現在のセルの出力を折りたたみます。 これを展開するには、セルの出力が非表示になっている状態で [出力の表示] を選択します。
ノートブックのアウトライン
アウトライン (目次) では、素早くナビゲーションできるようにサイドバー ウィンドウ内に任意の Markdown セルの最初の Markdown ヘッダーが表示されます。 アウトラインのサイドバーは、最適な方法で画面に合わせてサイズを変更したり折りたたんだりすることができます。 ノートブックのコマンド バーにある [アウトライン] ボタンを選択すると、サイドバーを開いたり非表示にしたりできます。
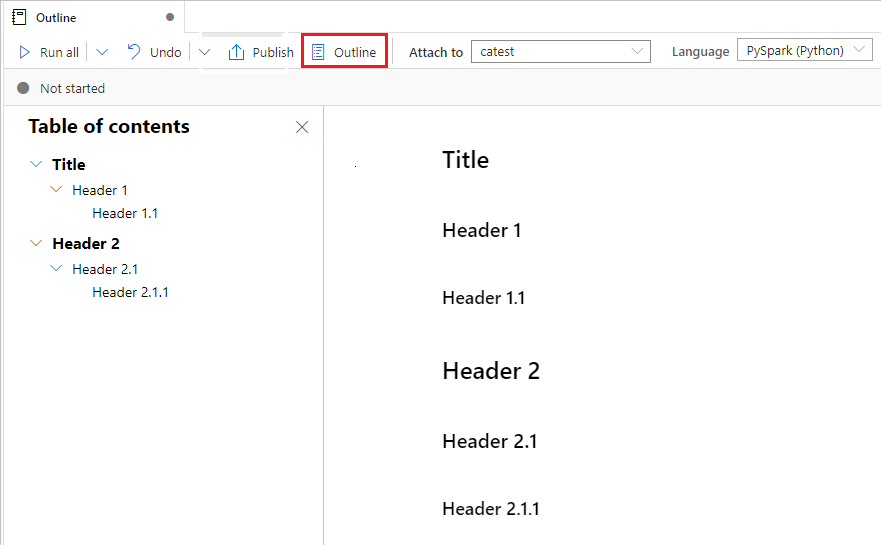
ノートブックを実行する
ノートブックのコード セルは、個別に、または一度にすべて実行できます。 ノートブックには各セルの状態と進行状況が示されます。
セルを実行する
セルでコードを実行するには、いくつかの方法があります。
実行するセルをポイントし、 [セルの実行] ボタンを選択するか、Ctrl + Enter キーを押します。

コマンド モードのショートカット キーを使用します。 現在のセルを実行し、下のセルを選択するには、Shift + Enter キーを押します。 現在のセルを実行し、新しいセルを下に挿入するには、Alt + Enter キーを押します。
すべてのセルを実行する
現在のノートブック内のすべてのセルを順に実行するには、 [すべて実行] ボタンを選択します。

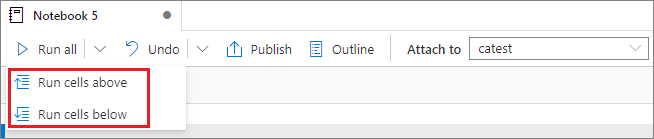
上または下のすべてのセルを実行する
[すべて実行] ボタンからドロップダウン リストを展開し、 [Run cells above](上のセルの実行) を選択して、現在のセルの上にあるものをすべて順に実行します。 現在のセルの下にあるものをすべて実行するには、 [Run cells below](下のセルの実行) を選択します。
実行中のすべてのセルを取り消す
実行中のセルまたはキューで待機しているセルを取り消すには、 [すべて取り消し] ボタンを選択します。

ノートブック参照
%run <notebook path> マジック コマンドを使用して、現在のノートブックのコンテキスト内で別のノートブックを参照することができます。 参照ノートブックで定義されているすべての変数を、現在のノートブックで使用できます。 %run マジック コマンドでは、入れ子になった呼び出しはサポートされますが、再帰呼び出しはサポートされません。 ステートメントの深度が 5 を超えると、例外が発生します。
例: %run /<path>/Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }。
Notebook リファレンスは、対話モードと Synapse パイプラインの両方で機能します。
注意
%runコマンドでは現在、絶対パスまたはノートブック名のみをパラメーターとして渡すことのみがサポートされており、相対パスはサポートされていません。%runコマンドでは現在、4 つのパラメーター値型int、float、bool、stringのみがサポートされており、変数置換操作はサポートされていません。- 参照されているノートブックを発行する必要があります。 未公開のノートブックの参照が有効になっている場合を除き、ノートブックを参照するには、それらを公開する必要があります。 Synapse Studio では、Git リポジトリから発行されていないノートブックは認識されません。
- 参照されるノートブックでは、深さが 5 を超えるステートメントはサポートされていません。
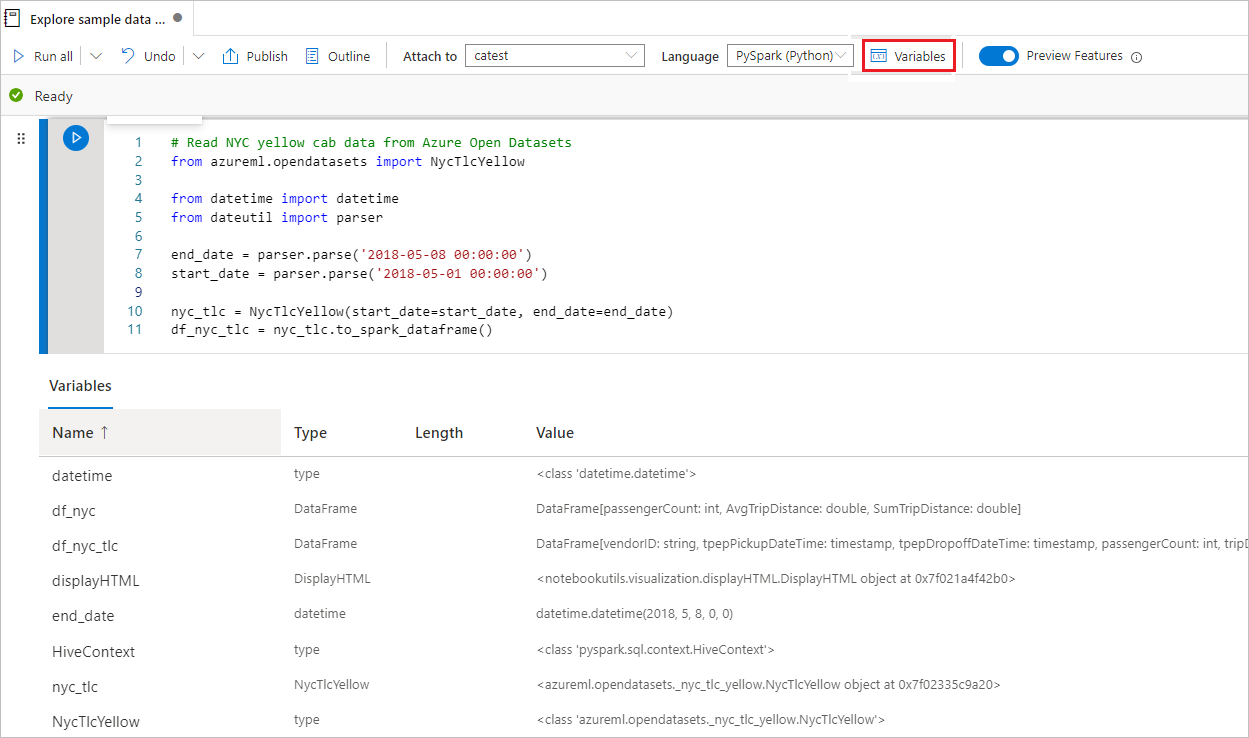
変数エクスプローラー
Synapse ノートブックは、PySpark (Python) セルの現在の Spark セッションでの変数の名前、型、長さ、値の一覧を表示するための、組み込み変数エクスプローラーを提供します。 コード セルに変数が定義されると、自動的に表示される変数も増えます。 各列ヘッダーをクリックすると、テーブル内の変数が並べ替えられます。
ノートブックのコマンド バーの [変数] ボタンを選択して、変数エクスプローラーを開いたり非表示にしたりできます。
注意
変数エクスプローラーは Python にのみ対応しています。
セルの状態インジケーター
セルの下に詳細なセルの実行の状態が表示されます。これは、現在の進行状況を確認するのに役立ちます。 セルの実行が完了すると、合計期間と終了時間を含む実行の概要が表示され、今後の参照用に保持されます。

Spark 進行状況インジケーター
Synapse ノートブックは、純粋に Spark ベースです。 コード セルは、サーバーレス Apache Spark プールに対してリモートで実行されます。 Spark ジョブの進行状況インジケーターは、リアルタイムの進行状況バーで示されます。これは、ジョブの実行状態を把握するのに役立ちます。 ジョブごとまたはステージごとのタスク数は、Spark ジョブの並列レベルを識別するのに役立ちます。 また、ジョブ (またはステージ) の名前のリンクを選択することで、特定のジョブ (またはステージ) の Spark UI をさらに掘り下げて調べることもできます。
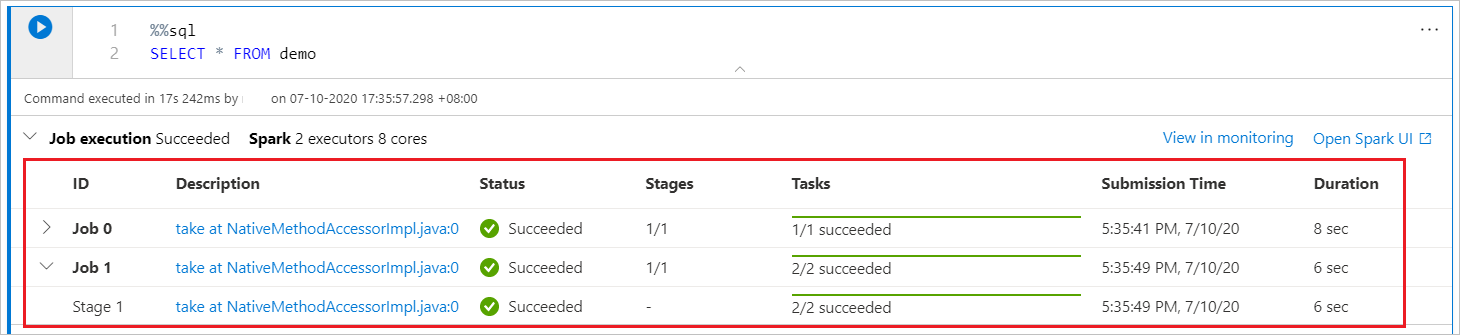
Spark セッションの構成
[Configure session](セッションの構成) では、現在の Spark セッションに設定するタイムアウト期間、Executor の数とサイズを指定できます。 Spark セッションを再起動すると、構成の変更が有効になります。 キャッシュされたノートブック変数はすべて消去されます。
また、Apache Spark の構成から構成を作成したり、既存の構成を選択したりすることもできます。 詳細については、Apache Spark の構成管理に関する記事を参照してください。

Spark セッション構成のマジック コマンド
マジック コマンド %%configure を使用して Spark セッションの設定を指定することもできます。 設定を有効にするには、Spark セッションを再起動する必要があります。 %%configure はノートブックの先頭で実行することをお勧めします。 次に例を示します。有効なパラメーターの一覧については、 https://github.com/cloudera/livy#request-body を参照してください。
%%configure
{
//You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory":"28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g", "472g"]
"driverCores":4, // Recommended values: [4, 8, 16, 32, 64, 80]
"executorMemory":"28g",
"executorCores":4,
"jars":["abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar","wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":{
//Example of standard spark property, to find more available properties please visit:https://spark.apache.org/docs/latest/configuration.html#application-properties.
"spark.driver.maxResultSize":"10g",
//Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows":"3000"
}
}
注意
- %%configure では、"DriverMemory" と "ExecutorMemory" を同じ値に設定することをお勧めします。"driverCores" と "executorCores" も同様です。
- %%configure は Synapse パイプラインで使用できますが、最初のコード セルに設定されていない場合は、セッションを再起動できないため、パイプライン実行は失敗します。
- mssparkutils.notebook.run で使用された %%configure は無視されますが、%run notebook で使用された場合は引き続き実行されます。
- "conf" 本文では、標準の Spark 構成プロパティを使用する必要があります。 Spark 構成プロパティの第 1 レベルの参照はサポートされていません。
- "spark.driver.cores"、"spark.executor.cores"、"spark.driver.memory"、"spark.executor.memory"、"spark.executor.instances" など、一部の特殊な Spark プロパティは "conf" 本文で有効になりません。
パイプラインからのパラメーター化されたセッション構成
パラメーター化されたセッション構成を使用すると、%% configure マジックの値をパイプライン実行 (Notebook アクティビティ) のパラメーターに置き換えることができます。 %%configure コード セルを準備するときに、既定値 (同様に構成可能。下記の例では 4 と "2000") を、このようなオブジェクトでオーバーライドできます。
{
"activityParameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"activityParameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"activityParameterName": "rows",
"defaultValue": "2000"
}
}
}
ノートブックが対話モードで直接実行された場合、または "activityParameterName" に一致するパラメーターがパイプラインの Notebook アクティビティから提供されない場合、Notebook では既定値が使用されます。
パイプライン実行モード中は、以下のようにパイプラインの Notebook アクティビティ設定を構成できます。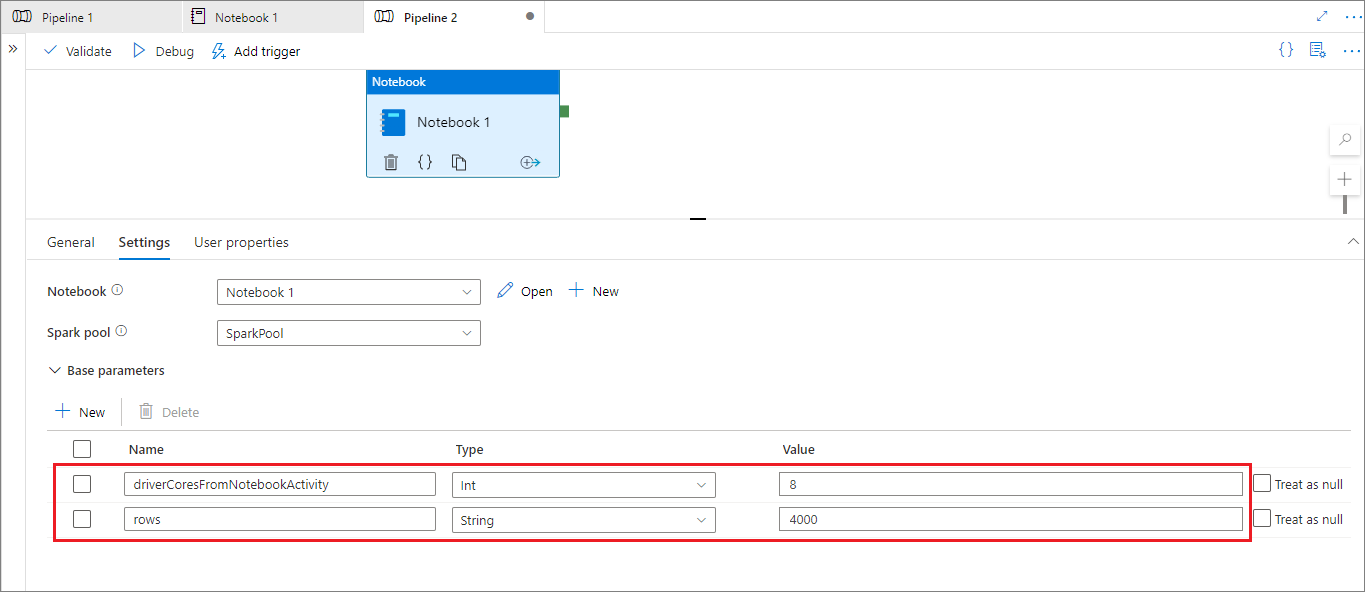
セッション構成を変更する場合は、パイプラインの Notebook アクティビティのパラメーター名をノートブック内の activityParameterName と同じにする必要があります。 このパイプラインを実行すると、この例では、%% configure の driverCores が 8 に、livy.rsc.sql.num-rows が 4000 に置き換えられます。
注意
この新しい %%configure マジックを使用したために実行パイプラインが失敗した場合は、ノートブックの対話モードで %%configure magic cell を実行することにより、追加のエラー情報を確認できます。
データをノートブックに取り込む
以下のコード サンプルに示すように、Azure Blob Storage、Azure Data Lake Store Gen 2、および SQL プールからデータを読み込むことができます。
Azure Data Lake Store Gen2 から CSV を Spark DataFrame として読み取る
from pyspark.sql import SparkSession
from pyspark.sql.types import *
account_name = "Your account name"
container_name = "Your container name"
relative_path = "Your path"
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
df1 = spark.read.option('header', 'true') \
.option('delimiter', ',') \
.csv(adls_path + '/Testfile.csv')
Azure Blob Storage から CSV を Spark DataFrame として読み取る
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
df = spark.read.option("header", "true") \
.option("delimiter","|") \
.schema(schema) \
.csv(wasbs_path)
プライマリ ストレージ アカウントからデータを読み取る
プライマリ ストレージ アカウントのデータに直接アクセスすることができます。 秘密鍵を指定する必要はありません。 データ エクスプローラーで、ファイルを右クリックし、 [新しいノートブック] を選択して、データ エクストラクターが自動生成された新しいノートブックを表示します。
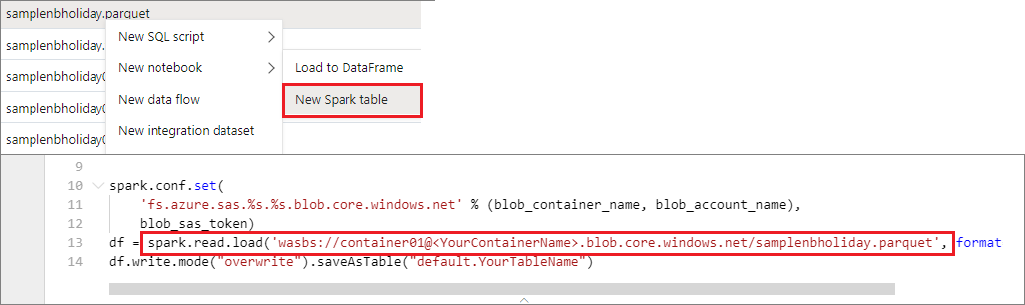
IPython ウィジェット
ウィジェットは、多くの場合、スライダーやテキストボックスなどのコントロールとして、ブラウザーに表示されるイベントフルな Python オブジェクトです。IPython ウィジェットは Python 環境でのみ動作し、他の言語 (Scala、SQL、C# など) ではまだサポートされていません。
IPython ウィジェットを使用するには
Jupyter ウィジェット フレームワークを使用するには、最初に
ipywidgetsモジュールをインポートする必要があります。import ipywidgets as widgetsトップレベルの
display関数を使用してウィジェットをレンダリングしたり、ウィジェットの種類の式をコード セルの最後の行に残したりすることができます。slider = widgets.IntSlider() display(slider)slider = widgets.IntSlider() sliderセルを実行すると、ウィジェットが出力領域に表示されます。
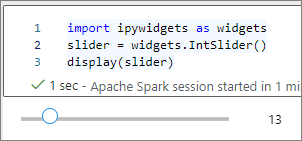
複数の
display()呼び出しを使用して同じウィジェット インスタンスを複数回レンダリングできますが、それらは互いに同期されたままです。slider = widgets.IntSlider() display(slider) display(slider)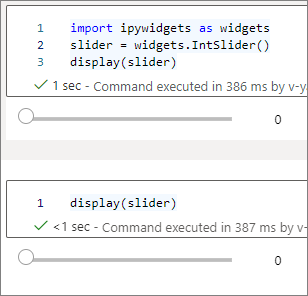
2 つのウィジェットを互いに独立してレンダリングするには、2 つのウィジェット インスタンスを作成します。
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)
サポートされているウィジェット
| ウィジェットの種類 | ウィジェット |
|---|---|
| 数値ウィジェット | IntSlider、FloatSlider、FloatLogSlider、IntRangeSlider、FloatRangeSlider、IntProgress、FloatProgress、BoundedIntText、BoundedFloatText、IntText、FloatText |
| ブール値ウィジェット | ToggleButton、Checkbox、Valid |
| 選択ウィジェット | Dropdown、RadioButtons、Select、SelectionSlider、SelectionRangeSlider、ToggleButtons、SelectMultiple |
| 文字列ウィジェット | Text、Text area、Combobox、Password、Label、HTML、HTML Math、Image、Button |
| 再生 (アニメーション) ウィジェット | 日付の選択、カラー ピッカー、コントローラー |
| コンテナーまたはレイアウト ウィジェット | Box、HBox、VBox、GridBox、Accordion、Tabs、Stacked |
既知の制限事項
次のウィジェットはまだサポートされていません。以下のような対応する回避策に従ってください。
機能 回避策 Outputウィジェット代わりに print()関数を使用して、stdout にテキストを書き込むことができます。widgets.jslink()widgets.link()関数を使用して、似たような 2 つのウィジェットをリンクできます。FileUploadウィジェットまだサポートされていません。 Synapse によって提供されるグローバル
display関数では、IPythondisplay関数とは異なる 1 回の呼び出しで複数のウィジェットを表示すること (つまり、display(a, b)) はサポートされません。IPython ウィジェットを含むノートブックを閉じると、対応するセルを再度実行するまで表示したり操作したりすることはできません。
ノートブックを保存する
ワークスペースには、単一のノートブックまたはすべてのノートブックを保存できます。
単一のノートブックに加えた変更を保存するには、ノートブックのコマンド バーにある [公開] ボタンを選択します。

ワークスペース内のすべてのノートブックを保存するには、ワークスペースのコマンド バーにある [すべて公開] ボタンを選択します。

ノートブックのプロパティでは、保存時にセル出力を含めるかどうかを構成できます。
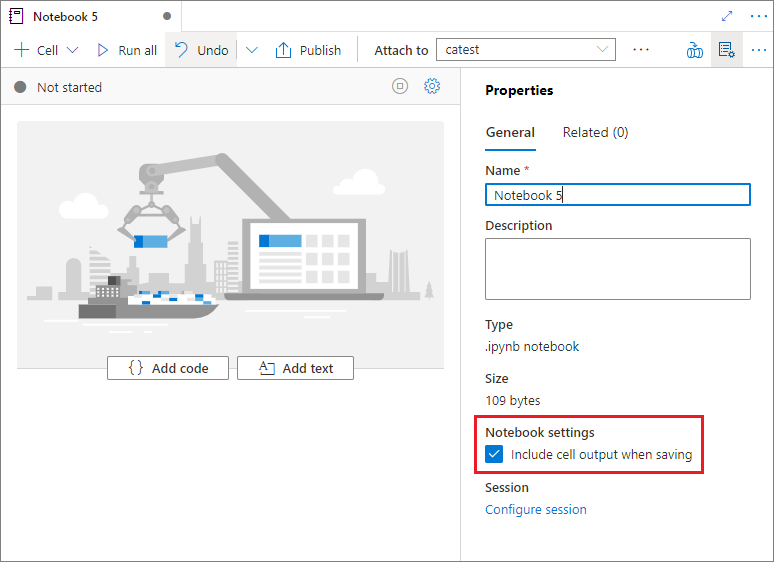
マジック コマンド
Synapse ノートブックでは、使い慣れた Jupyter マジック コマンドを使用できます。 以下の一覧で、現在使用可能なマジック コマンドを確認してください。 ユーザーのニーズに合ったマジック コマンドを引き続き作成できるよう、GitHub でユース ケースについてお知らせください。
注意
Synapse パイプラインでは、次のマジック コマンドのみがサポートされています: %%pyspark、%%spark、%%csharp、%%sql。
使用可能なライン マジック: %lsmagic、%time、%timeit、%history、%run、%load
使用可能なセル マジック: %%time、%%timeit、%%capture、%%writefile、%%sql、%%pyspark、%%spark、%%csharp、%%html、%%configure
発行されていないノートブックを参照する
発行されていないノートブックの参照は、「ローカル」でデバッグを行いたいときに役立ちます。この機能を有効にすると、ノートブック実行によって Web キャッシュ内の現在のコンテンツがフェッチされ、ノートブックの参照ステートメントが含まれたセルを実行すると、クラスター内に保存されているバージョンではなく、現在のノートブック ブラウザー内にあるノートブックを参照します。つまり、公開 (ライブ モード) またはコミット (Git モード) せずに、ノートブック エディター内の変更を他のノートブックから即座に参照できます。この方法を活用することにより、開発やデバッグ プロセス中に共通ライブラリが汚染されるのを簡単に回避できます。
[プロパティ] パネルから [発行されていないノートブックを参照する] を有効にできます。
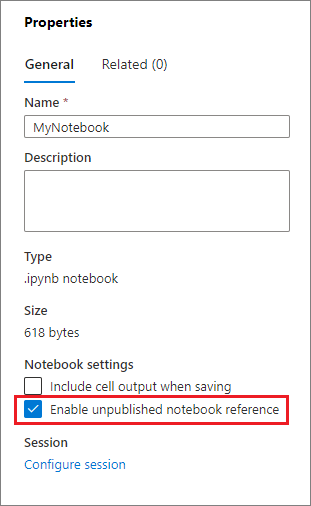
さまざまなケースの比較については、下記の表を確認してください。
ここでは、%run と mssparkutils.notebook.run の動作は同じであることに注意してください。 ここでは、例として %run を使用します。
| ケース | Disable | 有効化 |
|---|---|---|
| ライブ モード | ||
- Nb1 (発行済み) %run Nb1 |
Nb1 の発行済みバージョンを実行する | Nb1 の発行済みバージョンを実行する |
- Nb1 (新規) %run Nb1 |
エラー | 新規の Nb1 を実行する |
- Nb1 (以前に発行済み、編集済み) %run Nb1 |
Nb1 の発行済みバージョンを実行する | Nb1 の編集済みバージョンを実行する |
| Git モード | ||
- Nb1 (発行済み) %run Nb1 |
Nb1 の発行済みバージョンを実行する | Nb1 の発行済みバージョンを実行する |
- Nb1 (新規) %run Nb1 |
エラー | 新規の Nb1 を実行する |
- Nb1 (発行されていない、コミット済み) %run Nb1 |
エラー | コミット済み Nb1 を実行する |
- Nb1 (以前に発行済み、コミット済み) %run Nb1 |
Nb1 の発行済みバージョンを実行する | Nb1 のコミット済みバージョンを実行する |
- Nb1 (以前に発行済み、現在のブランチで新規) %run Nb1 |
Nb1 の発行済みバージョンを実行する | 新規の Nb1 を実行する |
- Nb1 (発行されていない、以前にコミット済み、編集済み) %run Nb1 |
エラー | Nb1 の編集済みバージョンを実行する |
- Nb1 (以前に発行済みでコミット済み、編集済み) %run Nb1 |
Nb1 の発行済みバージョンを実行する | Nb1 の編集済みバージョンを実行する |
まとめ
- 無効の場合は、常に発行済みバージョンを実行します。
- 有効にした場合、参照実行では、ノートブック UX から確認できる現在のバージョンのノートブックが常に採用されます。
アクティブなセッションの管理
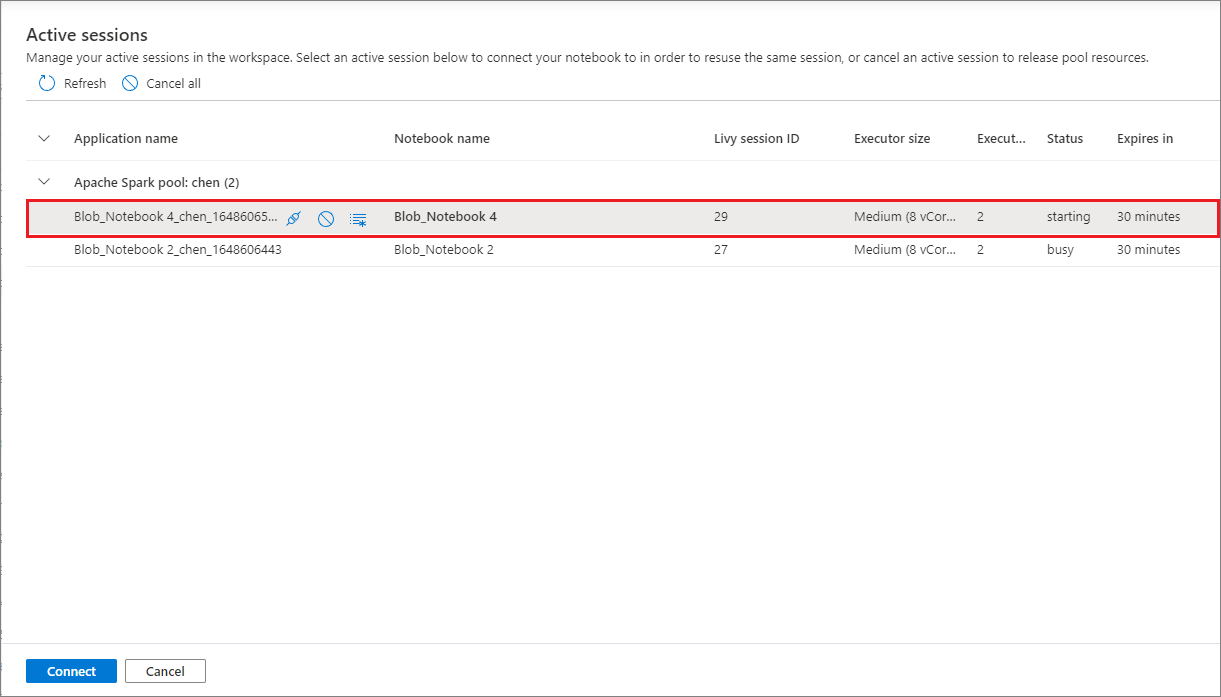
新しいセッションを開始しなくても、ノートブック セッションを便利に再利用できるようになりました。 Synapse ノートブックでは、[セッションの管理] リストでアクティブなセッションの管理をサポートするようになりました。ノートブックから開始した現在のワークスペース内のすべてのセッションを確認できます。
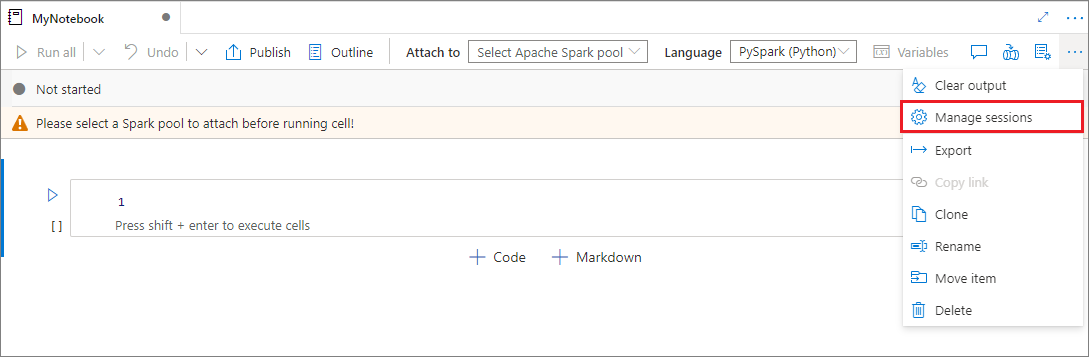
[アクティブなセッション] の一覧には、セッションの情報と、現在セッションにアタッチされている対応するノートブックが表示されます。 ここから、ノートブックでデタッチ、セッションの停止、関しの表示を行うことができます。 さらに、選択したノートブックを別のノートブックから開始されたリスト内のアクティブなセッションに簡単に接続でき、セッションは (アイドル状態でなければ )前のノートブックから切り離され、現在のノートブックに接続されます。
ノートブックでの Python のログ記録
次のサンプル コードに従って、Python ログを検索し、さまざまなログ レベルと形式を設定できます。
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
入力コマンドの履歴を表示する
Synapse ノートブックは、現在のセッション内で実行された入力コマンド履歴を出力するマジック コマンド %history をサポートしています。標準の Jupyter Ipython コマンドと比較すると、%history はノートブック内の複数の言語コンテキストに対して機能します。
%history [-n] [range [range ...]]
オプション:
- -n: 実行番号を出力します。
指定できる範囲は次のとおりです。
- N: N 番目に実行されたセルのコードを出力します。
- M-N: M 番目から N 番目に実行されたセルにコードを出力します。
例:
- 1 番目から 2 番目に実行されたセルまでの入力履歴を出力:
%history -n 1-2
ノートブックを統合する
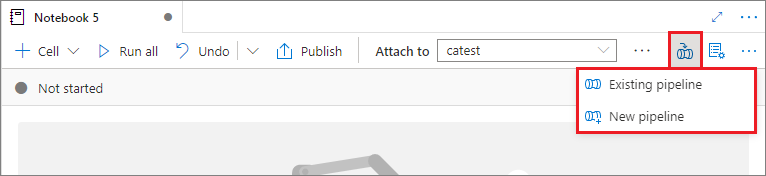
ノートブックをパイプラインに追加する
右上隅にある [パイプラインへの追加] ボタンを選択して、ノートブックを既存のパイプラインに追加するか、新しいパイプラインを作成します。
パラメーター セルを指定する
ノートブックをパラメーター化するには、省略記号 (...) を選択して、セル ツールバーの [more commands](その他のコマンド) にアクセスします。 次に、 [パラメーター セルを切り替えます] を選択して、セルをパラメーター セルとして指定します。
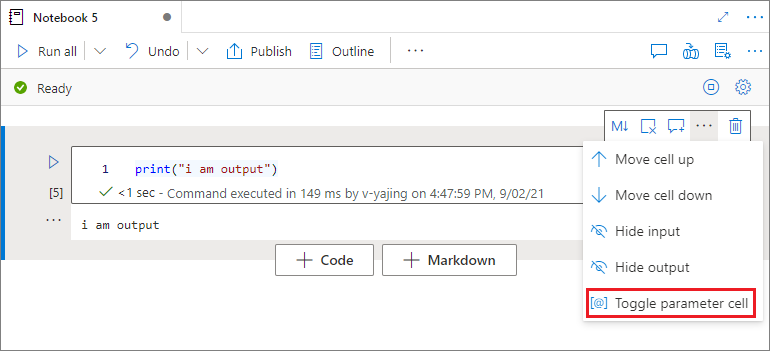
パラメーター セルが検索され、このセルは実行時に渡されるパラメーターの既定値として扱われます。 実行エンジンは、既定値を上書きするために、入力パラメーターを含んだ新しいセルをパラメーター セルの下に追加します。
パイプラインからパラメーター値を割り当てる
パラメーターを使ってノートブックを作成したら、Synapse Notebook アクティビティを使用して、パイプラインから実行できます。 アクティビティをパイプライン キャンバスに追加した後、 [設定] タブの [基本パラメーター] セクションで、パラメーターの値を設定できます。
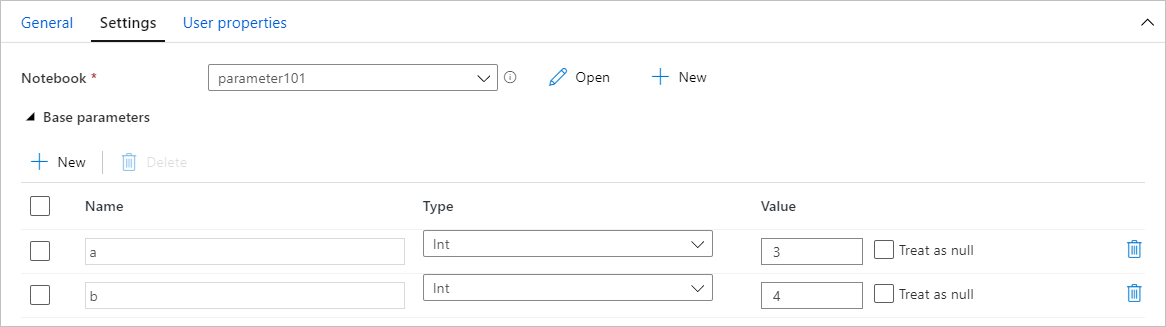
パラメーター値を割り当てるときは、パイプライン式言語 または システム変数を使用できます。
ショートカット キー
Jupyter Notebook と同様に、Synapse ノートブックにはモーダル ユーザー インターフェイスが採用されています。 キーボードの動作は、ノートブック セルのモードによって異なります。 Synapse ノートブックでは、特定のコード セルに対して、コマンド モードと編集モードという 2 つのモードがサポートされます。
入力を求めるテキスト カーソルがない場合、セルはコマンド モードになります。 セルがコマンド モードの場合、ノートブックを全体として編集できますが、個々のセルに入力することはできません。
ESCキーを押すか、マウスを使用してセルのエディター領域の外側を選択し、コマンド モードに入ります。
編集モードは、エディター領域への入力を求めるテキスト カーソルによって示されます。 セルが編集モードの場合、セルに入力することができます。
Enterキーを押すか、マウスを使用してセルのエディター領域を選択し、編集モードに入ります。
コマンド モードのショートカット キー
| アクション | Synapse ノートブックのショートカット |
|---|---|
| 現在のセルを実行して下のものを選択する | Shift + Enter |
| 現在のセルを実行して下に挿入する | Alt + Enter |
| 現在のセルを実行する | Ctrl + Enter |
| 上のセルを選択する | 上へ |
| 下のセルを選択する | [下へ] |
| 前のセルを選択する | K |
| 次のセルを選択する | J |
| 上にセルを挿入する | A |
| 下にセルを挿入する | B |
| 選択されたセルを削除する | Shift + D |
| 編集モードに切り替える | 次に、 |
編集モードのショートカット キー
次のキーストローク ショートカットを使用すると、編集モードのときに Synapse ノートブックのコードをより簡単に移動して実行できます。
| アクション | Synapse ノートブックのショートカット |
|---|---|
| カーソルを上に移動する | 上へ |
| カーソルを下に移動する | [下へ] |
| 元に戻す | Ctrl + Z |
| やり直し | Ctrl + Y |
| コメント化する/コメントを解除する | Ctrl + / |
| 前の単語を削除する | Ctrl + Backspace |
| 後の単語を削除する | Ctrl + Delete |
| セルの先頭に移動する | Ctrl + Home |
| セルの末尾に移動する | Ctrl + End |
| 1 単語左に移動する | Ctrl + Left |
| 1 単語右に移動する | Ctrl + Right |
| すべて選択する | Ctrl + A |
| インデントする | Ctrl + ] |
| インデントを解除する | Ctrl + [ |
| コマンド モードに切り替える | Esc |
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示