Azure Synapse Analytics で Apache Spark ジョブを最適化する
Apache Spark クラスター構成を特定のワークロード用に最適化する方法について説明します。 最もよくある課題は、不適切な構成 (特に不適切なサイズの実行プログラム)、実行時間の長い操作、およびデカルト演算を生じるタスクが原因の、メモリ不足です。 ジョブは、適切なキャッシュを使用し、データ スキューを可能にすることで、高速化することができます。 最適なパフォーマンスを得るためには、実行時間が長くリソースを多く消費する Spark ジョブの実行を監視し、確認します。
次のセクションでは、一般的な Spark ジョブの最適化と推奨事項について説明します。
データ抽象化の選択
以前のバージョンの Spark では、データの抽象化に RDD が使用されていましたが、Spark 1.3 と 1.6 では、DataFrames と DataSets がそれぞれ導入されました。 次の相対的な利点を考慮してください。
- DataFrames
- ほとんどの状況で最適な選択肢。
- Catalyst を介してクエリを最適化。
- ステージ全体のコード生成。
- ダイレクト メモリ アクセス
- ガベージ コレクション (GC) のオーバーヘッドが低い。
- コンパイル時のチェックやドメイン オブジェクトのプログラミングがないため、開発者にとっては DataSets ほど使いやすくない。
- DataSets
- パフォーマンスへの影響が許容範囲内である複雑な ETL パイプラインに適している。
- パフォーマンスへの影響が非常に大きい可能性のある集計には適さない。
- Catalyst を介してクエリを最適化。
- ドメイン オブジェクトのプログラミングとコンパイル時のチェックを提供することにより、開発者にっとって使いやすい。
- シリアル化/逆シリアル化のオーバーヘッドを追加。
- GC のオーバーヘッドが高い。
- ステージ全体のコード生成を中断する。
- RDD
- 新しいカスタム RDD を構築する必要がある場合を除き、RDD を使用する必要がない。
- Catalyst を介したクエリ最適化がない。
- ステージ全体のコード生成がない。
- GC のオーバーヘッドが高い。
- Spark 1.x のレガシ API を使用する必要がある。
最適なデータ形式の使用
Spark では、csv、json、xml、parquet、orc、avro など、多くの形式がサポートされています。 Spark は、外部データ ソースを使用して他の多くの形式をサポートするように拡張できます。詳細については、Apache Spark パッケージを参照してください。
パフォーマンスのために最適な形式は Snappy で圧縮した Parquet であり、これが Spark 2.x の既定値です。 Parquet はデータを列形式で格納し、Spark で高度に最適化されています。 また、"snappy 圧縮" では、gzip 圧縮よりもファイルが大きくなる場合があります。 これらのファイルは性質上、分割可能であるため、より速く圧縮解除されます。
キャッシュの使用
Spark は、.persist()、.cache()、CACHE TABLE などのさまざまな方法で使用できる、独自のネイティブ キャッシュ メカニズムを備えています。 このネイティブ キャッシュは、小さいデータ セットと、中間結果をキャッシュする必要がある ETL パイプラインで有効です。 ただし、Spark ネイティブ キャッシュは、現在のところパーティション分割では適切に機能しません。キャッシュされたテーブルがパーティション分割のデータを保持しないためです。
メモリの効率的な使用
Spark はデータをメモリ内に配置することで動作するため、メモリ リソースの管理は Spark ジョブの実行の最適化の重要な側面です。 クラスターのメモリを効率的に使用するために適用できる手法がいくつかあります。
小さいデータ パーティションを優先し、パーティション分割戦略でデータのサイズ、種類、および分散を要因とします。
Synapse Spark (ランタイム 3.1 以降) では、Kryo データのシリアル化は既定で有効になっています。
ワークロードの要件に基づいて、Spark 構成を使用して Kryo シリアライザーのバッファー サイズをカスタマイズできます。
// Set the desired property spark.conf.set("spark.kryoserializer.buffer.max", "256m")Spark 構成設定を監視し、チューニングします。
参考までに、Spark のメモリ構造と一部の重要な実行プログラムのメモリ パラメーターを、次のイメージで示します。
Spark メモリに関する考慮事項
Azure Synapse の Apache Spark では、YARN Apache Hadoop YARN を使用します。YARN は、Spark の各ノード上のすべてのコンテナーで使用される最大合計メモリを制御します。 次の図は、重要なオブジェクトとそれらの関連性を示しています。
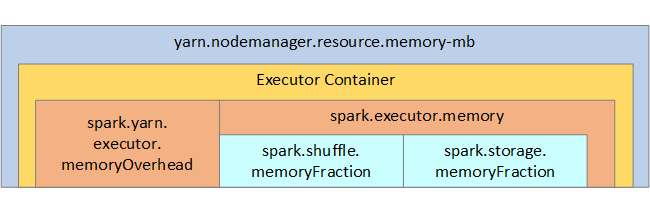
''メモリ不足'' のメッセージに対処するには、次を試してください。
- DAG 管理シャッフルを確認します。 マップ側の reduce 処理、ソース データの事前パーティション分割 (またはバケット化)、1 つのシャッフルの最大化、および送信されるデータ量の削減によって削減します。
- 固定メモリが
GroupByKeyに制限されたReduceByKeyを優先します。これは集計、ウィンドウ化、およびその他の機能を提供しますが、無制限のメモリ制限があります。 - 実行プログラムやパーティションでより多くの操作を実行する
TreeReduceを、すべての操作をドライバーで実行するReduceより優先します。 - 下位レベルの RDD オブジェクトではなく、DataFrames を利用します。
- "上位 N"、各種の集計、ウィンドウ化操作などのアクションをカプセル化する、ComplexTypes を作成します。
データのシリアル化の最適化
Spark ジョブは分散されるため、パフォーマンスを最適にするためには適切なデータのシリアル化が重要です。 Spark には 2 つのシリアル化のオプションがあります。
- Java シリアル化
- Kryo シリアル化は既定値です。 これは新しい形式であり、シリアル化が Java よりも高速で、よりコンパクトになる可能性があります。 Kryo ではプログラムでクラスを登録する必要があり、まだシリアル化可能なすべての種類がサポートされているわけではありません。
バケットの使用
バケットはデータのパーティション分割に似ていますが、各バケットは、1 つだけではなく一連の列の値を保持できます。 バケットは、製品識別子などの大量 (数百万以上) の値でパーティション分割する場合に適しています。 バケットは、行のバケット キーをハッシュすることで決定されます。 バケット化したテーブルは、バケット化と並べ替えの方法についてのメタデータを格納するため、固有の最適化を提供します。
いくつかの高度なバケット機能を、次に示します。
- バケットのメタ情報に基づくクエリの最適化
- 最適化された集計。
- 最適化された結合
パーティション分割とバケットは同時に使用することができます。
最適化された結合とシャッフル
結合またはシャッフルで低速のジョブがある場合、その原因はデータ スキュー (ジョブ データの非対称) である可能性があります。 たとえば、マップ ジョブには 20 秒かかることがありますが、データが結合またはシャッフルされているジョブの実行には何時間もかかります。 データ スキューを修正するには、キー全体をソルティングするか、キーの一部のサブセットのみに分離したソルトを使用する必要があります。 分離したソルトを使用する場合は、マップの結合でソルティングしたキーのサブセットを分離するため、さらにフィルター処理する必要があります。 もう 1 つのオプションは、バケット列を導入し、最初にバケットで事前に集計することです。
結合が遅くなるもう 1 つの要因は、結合タイプである可能性があります。 既定では、Spark は SortMerge 結合タイプを使用します。 このタイプの結合は大きいデータ セットには最適ですが、それ以外の場合は、マージする前に最初にデータの左側と右側を並べ替える必要があるため、計算コストが高くなります。
Broadcast 結合は、小さいデータ セット、または結合の一方の側がもう一方よりはるかに小さい場合に最適です。 このタイプの結合は、一方の側をすべての実行プログラムにブロードキャストするため、通常はブロードキャストに多くのメモリが必要です。
spark.sql.autoBroadcastJoinThreshold を設定することで構成内の結合タイプを変更することも、DataFrame API (dataframe.join(broadcast(df2))) を使用して結合のヒントを設定することもできます。
// Option 1
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1*1024*1024*1024)
// Option 2
val df1 = spark.table("FactTableA")
val df2 = spark.table("dimMP")
df1.join(broadcast(df2), Seq("PK")).
createOrReplaceTempView("V_JOIN")
sql("SELECT col1, col2 FROM V_JOIN")
バケット化したテーブルを使用する場合は、3 つ目の結合タイプ、Merge 結合があります。 事前のパーティション分割と事前の並べ替えが適切に行われているデータセットは、SortMerge 結合からコストのかかる並べ替えフェーズを省略します。
結合の順序は、より複雑なクエリでは特に重要です。 最も選択的な結合から開始してください。 また、可能な場合は、集計後に行数を増やす結合を移動してください。
デカルト結合の並列処理を管理するには、入れ子になった構造やウィンドウ化を追加することができ、場合によっては Spark ジョブの 1 つまたは複数の手順をスキップすることができます。
実行プログラムの適切なサイズの選択
実行プログラムの構成を決定する際は、Java ガベージ コレクション (GC) のオーバーヘッドを考慮してください。
実行プログラムのサイズを小さくする要因:
- GC オーバーヘッドを 10% 未満に保つため、ヒープ サイズを 32 GB より小さくします。
- GC オーバーヘッドを 10% 未満に保つため、コア数を減らします。
実行プログラムのサイズを大きくする要因:
- 実行プログラム間の通信オーバーヘッドを削減します。
- 大きいクラスター (実行プログラムが 100 より多い) 上の実行プログラム (N2) の間で開いている接続の数を減らします。
- メモリを大量に使用するタスクに合わせて、ヒープ サイズを増やします。
- 省略可能:実行プログラムあたりのメモリ オーバーヘッドを減らします。
- 省略可能:CPU をオーバーサブスクライブすることで、使用率とコンカレンシーを増やします。
実行プログラムのサイズを選択する際の一般的な目安:
- 実行プログラムあたり 30 GB から始めて、使用可能なコンピューターのコアを分散します。
- 大きいクラスター (実行プログラムが 100 より多い) の実行プログラムのコアの数を増やします。
- 試運転と、GC オーバーヘッドなどの上記の要因の両方に基づいて、サイズを変更します。
同時クエリを実行する場合は、次を考慮してください。
- 実行プログラムあたり 30 GB と、すべてのコンピューター コアから始めます。
- CPU をオーバーサブスクライブすることで、複数の並列の Spark アプリケーションを作成します (約 30% の待機時間の改善)。
- クエリを並列アプリケーション全体に分散します。
- 試運転と、GC オーバーヘッドなどの上記の要因の両方に基づいて、サイズを変更します。
タイムライン ビュー、SQL グラフ、ジョブの統計情報などを調べることで、外れ値やその他のパフォーマンスの問題に対するクエリのパフォーマンスを監視します。 場合によっては、1 つまたは 2、3 の実行プログラムが他よりも遅くなり、タスクの実行にかなり長くかかることがあります。 これは大きいクラスター (ノードが 30 より多い) で頻繁に発生します。 この場合は、スケジューラが低速のタスクを補正できるよう、より多くのタスクに操作を分割します。
たとえば、タスクの数を、少なくとも 2 回、アプリケーション内の実行プログラムのコア数と同数にします。 また、conf: spark.speculation = true を使用してタスクの予測実行を有効にすることもできます。
ジョブ実行の最適化
- たとえばデータを 2 回使用してからキャッシュする場合は、必要に応じてキャッシュします。
- 変数はすべての実行プログラムにブロードキャストします。 変数は 1 回シリアル化されるだけなので、結果として検索が高速になります。
- ドライバーでスレッド プールを使用します。これにより、多数のタスクの操作が高速になります。
Spark 2.x クエリのパフォーマンスに重要なものは、ステージ全体のコード生成に依存する Tungsten エンジンです。 場合によっては、ステージ全体のコード生成を利用できないことがあります。
たとえば、集計式で変更できない型 (string) を使用すると、HashAggregate ではなく SortAggregateが表示されます。 たとえば、パフォーマンスを向上させるために、次を実行してから、コード生成を再度有効にします。
MAX(AMOUNT) -> MAX(cast(AMOUNT as DOUBLE))