Azure Synapse Analytics の Apache Spark GPU アクセラレーション プール (非推奨)
Apache Spark は、ビッグデータ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする並列処理フレームワークです。 Azure Synapse Analytics の Apache Spark は、Apache Spark を Microsoft がクラウドに実装したものです。
Azure Synapse では、GPU の大規模な並列処理能力を使用して処理を高速化する、基になる RAPIDS ライブラリを使用して Spark ワークロードを実行するための Azure Synapse GPU 対応プールを作成できるようになりました。 Apache Spark 用の RAPIDS アクセラレータを使用すると、GPU 対応プール用に事前構成された構成設定を有効にするだけで、コードを変更することなく既存の Spark アプリケーションを実行できます。 この構成を設定することにより、ワークロード、またはワークロードの一部に対して RAPIDS ベースの GPU アクセラレータをオンまたはオフにできます。
spark.conf.set('spark.rapids.sql.enabled','true/false')
Note
Azure Synapse GPU 対応プールのプレビューは非推奨になりました。
注意事項
Azure Synapse Runtime for Apache Spark 3.1 および 3.2 上の GPU の非推奨化と無効化の通知
- Apache Spark 3.2 (非推奨) ランタイムで GPU アクセラレーション プレビューが非推奨になりました。 非推奨のランタイムでは、バグおよび機能の修正は行われません。 このランタイムと Spark 3.2 の対応する GPU アクセラレーション プレビューは、2024 年 7 月 8 日の時点で廃止され、無効化されました。
- Azure Synapse 3.1 (非推奨) ランタイムで GPU アクセラレーション プレビューが非推奨になりました。 Azure Synapse Runtime for Apache Spark 3.1 は、2023 年 1 月 26 日でサポート終了となりました。公式サポートの提供は 2024 年 1 月 26 日をもって終了し、この日付以降、サポート チケットの処理、バグ修正、セキュリティ更新は行われません。
Apache Spark 用の RAPIDS アクセラレータ
Spark RAPIDS アクセラレータは、サポートされている GPU 操作で Spark ジョブの物理プランを上書きし、それらの操作を GPU 上で実行して処理を高速化することによって機能するプラグインです。 このライブラリは現在プレビュー段階であり、すべての Spark 操作がサポートされているわけではありません (現在サポートされている操作の一覧については、こちらを参照してください。新しいリリースによって段階的にサポートが追加されます)。
クラスター構成オプション
RAPIDS アクセラレータ プラグインでは、GPU と Executor 間の一対一のマッピングのみがサポートされています。 つまり、Spark ジョブでは、(使用可能な GPU と CPU コアの数に応じて) プール リソースで対応できる Executor とドライバー リソースを要求する必要があります。 この条件を満たし、すべてのプール リソースを最適に使用できるようにするためには、GPU 対応プールで実行されている Spark アプリケーションに対して次のようにドライバーと Executor を構成する必要があります。
| プール サイズ | ドライバー サイズのオプション | ドライバー コア | ドライバーのメモリ (GB) | Executor コア | Executor のメモリ (GB) | Executor の数 |
|---|---|---|---|---|---|---|
| GPU-Large | Small ドライバー | 4 | 30 | 12 | 60 | プール内のノードの数 |
| GPU-Large | Medium ドライバー | 7 | 30 | 9 | 60 | プール内のノードの数 |
| GPU-XLarge | Medium ドライバー | 8 | 40 | 14 | 80 | 4 * プール内のノードの数 |
| GPU-XLarge | Large ドライバー | 12 | 40 | 13 | 80 | 4 * プール内のノードの数 |
上記の構成のいずれかを満たしていないワークロードは受け入れられません。 これは、プールで使用可能なすべてのリソースを利用し、最も効率的でパフォーマンスの高い構成で Spark ジョブが実行されるようにするために行われます。
ユーザーは、ワークロードを通じて上記の構成を設定できます。 ノートブックの場合、次に示すように、ユーザーは %%configure マジック コマンドを使用して上記の構成のいずれかを設定できます。
たとえば、3 つのノードの大規模なプールを使用する場合は、次のようになります。
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Azure Synapse GPU アクセラレータ プールでノートブックを介してサンプル Spark ジョブを実行する
このセクションに進む前に、Azure Synapse Analytics でのノートブックの使用方法の基本的概念を理解しておくことをお勧めします。 GPU アクセラレータを使用して Spark アプリケーションを実行する手順について説明します。 Spark アプリケーションは、Synapse 内でサポートされている 4 つのすべての言語 PySpark (Python)、Spark (Scala)、SparkSQL、.NET for Spark (C#) で作成できます。
GPU 対応プールを作成します。
ノートブックを作成し、最初の手順で作成した GPU 対応プールに接続します。
前のセクションで説明したように構成を設定します。
ノートブックの最初のセルに次のコードをコピーして、サンプル データフレームを作成します。
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
- 次に、部門 ID ごとの給与の最高額を取得して集計を行い、その結果を表示してみましょう。
- GPU で実行されたクエリ内の操作を確認するには、Spark History Server を介して SQL プランを調べます。
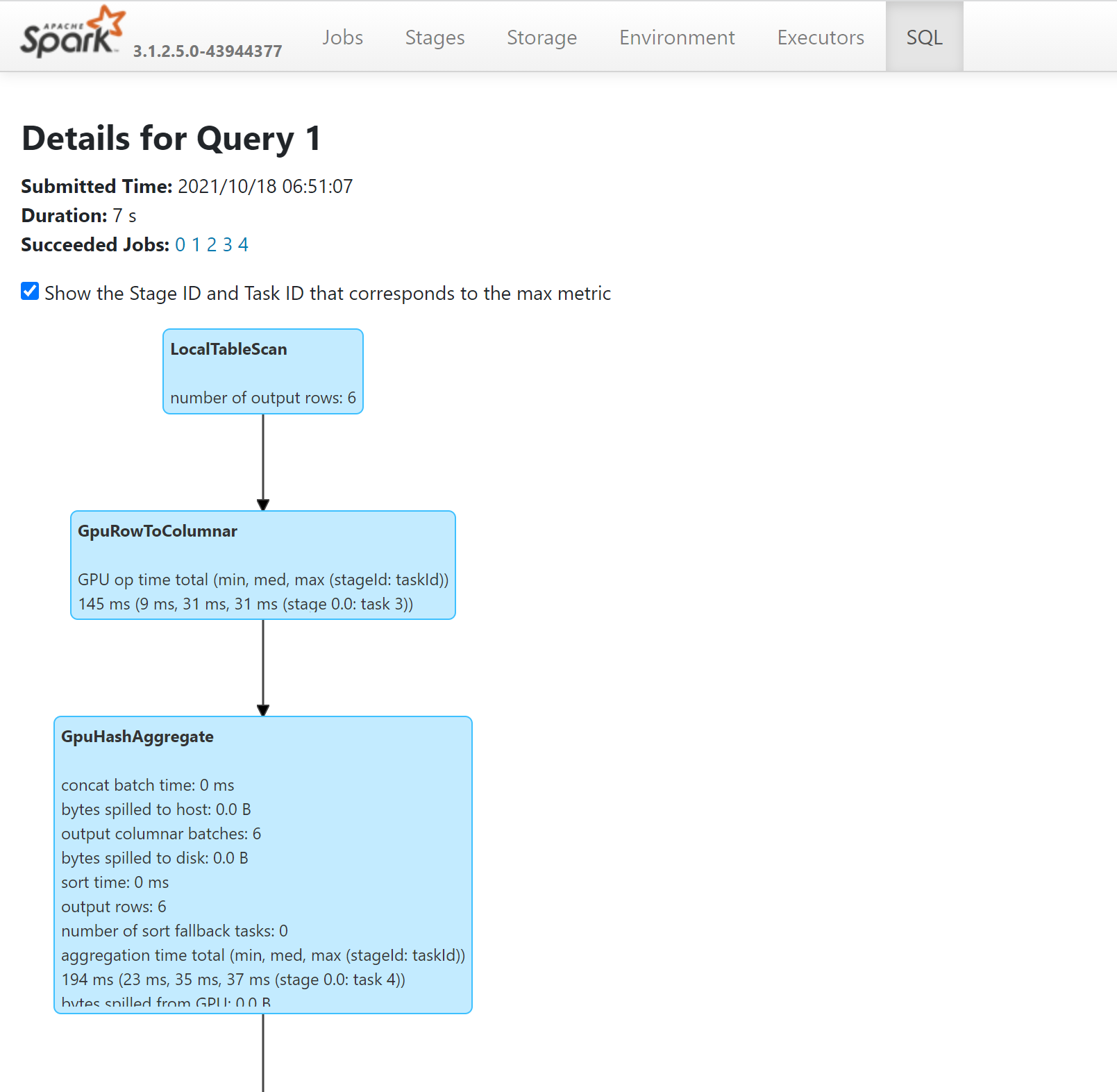
GPU 用にアプリケーションを調整する方法
ほとんどの Spark ジョブでは、構成設定を既定値から調整することでパフォーマンスの向上を確認できます。これは、Apache Spark の RAPIDS アクセラレータ プラグインを利用しているジョブでも同様です。
Azure Synapse GPU 対応プールでのクォータとリソース制約
ワークスペースレベル
すべての Azure Synapse ワークスペースには、既定のクォータである 50 個の GPU 仮想コアが付属しています。 GPU コアのクォータを増やすには、Azure portal でサポート リクエストを送信してください。