Azure Synapse Analytics で専用 SQL プールを使用して分散テーブルを設計するためのガイダンス
この記事には、専用 SQL プールでハッシュ分散およびラウンドロビン分散の各テーブルを設計するための推奨事項が記載されています。
この記事では、専用 SQL プールのデータ分散とデータ移動の概念を理解していることを前提としています。 詳細については、Azure Synapse Analytics のアーキテクチャに関する記事を参照してください。
分散テーブルについて
分散テーブルは単一のテーブルとして表示されますが、実際には、行が 60 のディストリビューションにわたって格納されています。 行はハッシュ アルゴリズムまたはラウンド ロビン アルゴリズムを使って、分散されます。
ハッシュ分散は、この記事で取り上げる主題であり、大規模なファクト テーブルでのクエリ パフォーマンスを向上させます。 ラウンド ロビン分散は、読み込み速度の向上に役立ちます。 これらの設計の選択は、クエリおよび読み込みパフォーマンスの向上に大きな影響を与えます。
もう 1 つのテーブル ストレージの選択肢としては、すべての計算ノードにわたって小規模なテーブルをレプリケートする方法があります。 詳しくは、レプリケート テーブルを使用するための設計ガイダンスに関する記事をご覧ください。 3 つの選択肢から簡単に選ぶには、テーブルの概要を示した記事の「分散テーブル」を参照してください。
テーブル設計の一環として、ご利用のデータと、そのデータを照会する方法についてできる限り理解してください。 たとえば、次のような質問を考えてみます。
- テーブルの大きさはどの程度か。
- どの程度の頻度でテーブルが更新されるか。
- 専用 SQL プール内にファクトおよびディメンションのテーブルがあるか。
ハッシュによる分散
ハッシュ分散テーブルでは、決定論的なハッシュ関数を使用して各行を 1 つのディストリビューションに割り当て、複数の計算ノードにわたってテーブル行を分散させます。
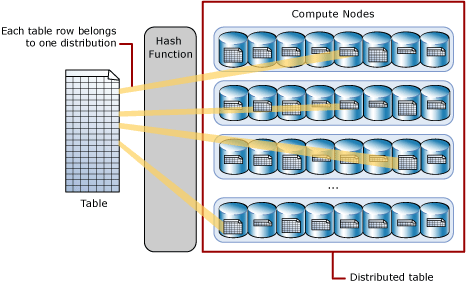
同一値は常に同じディストリビューションにハッシュされるため、SQL Analytics には行の位置情報に関する組み込みのナレッジがあります。 専用 SQL プールではこのナレッジを使用して、クエリ時のデータ移動を最小化し、クエリ パフォーマンスを向上させます。
ハッシュ分散テーブルは、スター スキーマにある大規模なファクト テーブルに適しています。 非常に多数の行を格納し、その上で高度なパフォーマンスを実現できます。 期待通りの分散システムのパフォーマンスを得るために役立つ設計上の考慮事項はいくつかあります。 適切なディストリビューション列を選択することは、この記事で説明されている考慮事項の 1 つです。
ハッシュ分散テーブルの使用は、次の場合に検討してください。
- ディスク上のテーブル サイズが 2 GB を超えている。
- テーブルで、頻繁な挿入、更新、削除操作が行われる。
ラウンド ロビンによる分散
ラウンド ロビン分散テーブルは、すべてのディストリビューションにわたって均等にテーブル行を分散させます。 ディストリビューションに対する行の割り当てはランダムです。 ハッシュ分散テーブルとは異なり、同じ値を持つ行が必ず同じディストリビューションに割り当てられるわけではありません。
その結果、クエリを解決するために、システムでデータの移動操作を呼び出して、データを整理することが必要になる場合があります。 この特別な手順のために、クエリが遅くなる可能性があります。 たとえば、ラウンド ロビン テーブルを結合する場合、通常は行を再度シャッフルする必要があり、パフォーマンスの低下につながります。
次のシナリオでは、テーブルにラウンド ロビンによる分散を使用することを検討してください。
- 既定になっているので、作業開始時の単純な始点とする場合
- 明確な結合キーが存在しない場合
- テーブルをハッシュ分散するのに適した候補列がない場合
- テーブルが共通の結合キーを他のテーブルと共有していない場合
- 結合がクエリの他の結合ほど重要ではない場合
- テーブルが一時ステージング テーブルである場合
ニューヨークのタクシー データの読み込みに関するチュートリアルでは、ラウンドロビン ステージング テーブルにデータを読み込む例を示しています。
ディストリビューション列の選択
ハッシュ分散テーブルには、ハッシュ キーであるディストリビューション列または列のセットがあります。 たとえば、次のコードは、ディストリビューション列として ProductKey を使ってハッシュ分散テーブルを作成します。
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
ハッシュ分散は、ベース テーブルの分散をより均等にするために、複数の列に適用できます。 複数列分散を使用すると、分散用に最大 8 つの列を選択できます。 これにより、時間の経過に伴うデータの偏りを減らすだけでなく、クエリのパフォーマンスも向上します。 次に例を示します。
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Note
このコマンドを使用してデータベースの互換性レベルを 50 に変更すると、Azure Synapse Analytics の複数列分散を有効にできます。
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; データベース互換レベルの設定について詳しくは、「ALTER DATABASE SCOPED CONFIGURATION」をご覧ください。 複数列分散の詳細については、CREATE MATERIALIZED VIEW、CREATE TABLE、または CREATE TABLE AS SELECT を参照してください。
ディストリビューション列に格納されているデータを更新できます。 ディストリビューション列のデータを更新すると、データ シャッフル操作が発生する可能性があります。
このハッシュ列の値によって行の分散方法が決まるため、ディストリビューション列の選択は、設計上の重要な決定事項です。 最適な選択肢は複数の要因によって決まり、多くの場合、トレードオフが生じます。 いったんディストリビューション列または列セットを選択したら、その列を変更することはできません。 最初に最適な列を選択しなかった場合は、CREATE TABLE AS SELECT (CTAS) を使用して、目的の分散ハッシュ キーでテーブルを再作成できます。
均等に分散したデータを含むディストリビューション列を選択する
最適なパフォーマンスを得るために、すべてのディストリビューションでほぼ同じ行数を含むようにする必要があります。 1 つまたは複数のディストリビューションに含まれる行数が不均衡な場合、並列クエリが一部のディストリビューションで他よりも先に終わります。 クエリは、すべてのディストリビューションで処理が終了するまで完了できないので、各クエリは単に最も処理が遅いディストリビューションと同じ速度になります。
- データ スキューとは、複数のディストリビューションにわたってデータが均等に分散されていないことを意味します。
- 処理のスキューとは、クエリの並列実行を行うときに、一部のディストリビューションで他よりも処理が長引くことを意味します。 これは、データがスキューしている場合に発生する可能性があります。
並列処理のバランスを取るには、以下のようなディストリビューション列または列のセットを選びます。
- 多数の一意の値を含む。 1 つ以上のディストリビューション列に、重複値を含めることができます。 同じ値を持つすべての行が、同じディストリビューションに割り当てられます。 60 個のディストリビューションがあるため、複数の一意の値を持つディストリビューションや、ゼロ値で終了するものが含まれている可能性があります。
- NULL がない、または少ししか NULL がない。 極端な例として、ディストリビューション列のすべての値が NULL の場合、すべての行が同じディストリビューションに割り当てられます。 その結果、クエリ処理は 1 つのディストリビューションにスキューされ、並列処理のメリットはなくなります。
- 日付列ではない。 同じ日付のすべてのデータが同じディストリビューションに配置されるか、日付別にレコードがクラスター化されます。 複数のユーザーがすべて、同じ日付 (今日の日付など) でフィルター処理している場合、60 個のディストリビューションのうち 1 つのみで、すべての処理操作が行われます。
データ移動を最小化するディストリビューション列を選択する
正確なクエリ結果を得るために、クエリでは 1 つの計算ノードから別の計算ノードへとデータを移動させる場合があります。 データ移動は、一般的に、クエリに分散テーブルでの結合と集計が含まれる場合に発生します。 データ移動を最小化できるディストリビューション列または列セットを選択することが、専用 SQL プールのパフォーマンスを最適化するための最も重要な戦略の 1 つです。
データ移動を最小化するために、以下のようなディストリビューション列または列のセットを選択します。
JOIN、GROUP BY、DISTINCT、OVER、およびHAVING句で使用されている。 2 つの大規模なファクト テーブルで頻繁に結合が生じる場合、両方のテーブルを結合列の 1 つに分散させると、クエリのパフォーマンスが向上します。 あるテーブルが結合に使用されない場合、GROUP BY句に頻繁に出現する列または列セットでそのテーブルを分散させることを検討します。WHERE句で使用されていない。 クエリのWHERE句とテーブルのディストリビューション列が同じ列にある場合、クエリでデータ スキューが高くなる可能性があり、少数のディストリビューションのみに処理負荷がかかることにつながります。 これはクエリのパフォーマンスに影響を与えます。理想的には、多数のディストリビューションで処理負荷を共有します。- 日付列ではない。
WHERE句は多くの場合、日付別にフィルター処理されます。 この場合、すべての処理が、少数のディストリビューションのみで実行される可能性があり、クエリのパフォーマンスに影響を与えます。 理想的には、多数のディストリビューションで処理負荷を共有します。
ハッシュ分散テーブルを設計したら、次の手順として、そのテーブルにデータを読み込みます。 読み込みのガイダンスについては、読み込みの概要に関する記事をご覧ください。
お使いのディストリビューションが適切な選択かどうかを判断する方法
ハッシュ分散テーブルにデータを読み込んだ後は、60 のディストリビューションにどの程度均等に行が分散されているかを確認します。 ディストリビューションあたりの行数の変化が 10 % までであれば、パフォーマンスに顕著な影響はありません。
ディストリビューション列を評価するには、次の方法を検討してください。
テーブルにデータ スキューが発生しているかを判断する
データ スキューをチェックする簡単な方法として、DBCC PDW_SHOWSPACEUSED を使用できます。 次の SQL コードは、60 の各ディストリビューションに格納されているテーブル行の数を返します。 バランスの取れたパフォーマンスを実現するには、分散テーブルの行をディストリビューション全体で均等に広げる必要があることに注意してください。
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
10 % を超えるデータ スキューが発生しているテーブルを特定するには、次の手順を実行します。
- テーブルの概要に関する記事に示されているビュー
dbo.vTableSizesを作成します。 - 次のクエリを実行します。
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
データ移動に関するクエリ計画をチェックする
適切なディストリビューション列セットを使用すると、結合と集計でデータ移動を最小限に抑えることができます。 このことは、結合の記述方法に影響を及ぼします。 2 つのハッシュ分散テーブルで結合の際のデータ移動を最小化するには、結合列の 1 つがディストリビューション列にある必要があります。 2 つのハッシュ分散テーブルが同じデータ型のディストリビューション列で結合された場合、その結合はデータ移動を必要としません。 結合では、データ移動を発生させずに、追加の列を使用できます。
結合中のデータ移動を回避するには、次の手順を実行します。
- 結合に関係するテーブルでは、結合に参加する列の いずれか でハッシュ分散する必要があります。
- 両方のテーブルで結合列のデータ型が一致する必要があります。
- 列を equal 演算子で結合する必要があります。
- 結合の種類を
CROSS JOINにすることはできません。
クエリによってデータ移動が発生するかどうかを見極めるには、クエリ プランを確認できます。
ディストリビューション列の問題を解決する
データ スキューのすべてのケースを解決する必要はありません。 データの分散では、データ スキューとデータ移動の最小化において適切なバランスを見つけることが重要です。 常にデータ スキューとデータ移動の両方を最小化することはできません。 場合によっては、データ移動を最小化するメリットが、データ スキューによる影響を上回る可能性があります。
テーブルでデータ傾斜を解決する必要があるかを決定するには、ワークロード内のデータ ボリュームとクエリについて可能な限り理解する必要があります。 クエリの監視に関する記事に記載された手順を使用して、クエリ パフォーマンスのスキューの影響を監視できます。 具体的には、個々のディストリビューションで大規模なクエリの完了にかかる時間を探索します。
既存のテーブル上のディストリビューション列は変更できないため、データ スキューの一般的な解決方法として、異なるディストリビューション列を持つテーブルを再作成します。
新しいディストリビューション列セットを含むテーブルを再作成する
この例では、CREATE TABLE AS SELECT を使用して、別のハッシュ ディストリビューション列を含むテーブルを再作成します。
最初に CREATE TABLE AS SELECT (CTAS) を使用して新しいキーを持つ新しいテーブルを作成します。 次に、統計を再作成し、最後に名前を変更してテーブルを入れ替えます。
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
関連するコンテンツ
分散テーブルを作成するには、以下のいずれかのステートメントを使用します。