Azure Time Series Insights Gen1 で待機時間を削減するために調整を監視して緩和する
Note
Time Series Insights サービスは、2024 年 7 月 7 日に廃止されます。 できるだけ早く既存の環境を代替ソリューションに移行することを検討してください。 サポートの終了と移行の詳細については、こちらのドキュメントを参照してください。
注意事項
これは Gen1 の記事です。
着信データの量が環境の構成を超えると、Azure Time Series Insights で待機時間や調整が発生する可能性があります。
分析するデータ量に合わせて環境を正しく構成することによって待機時間と調整を回避できます。
次の操作をしたときに待機時間と調整が発生する可能性が最も高くなります。
- 割り当てられた受信レートを超えるかもしれない古いデータを含むイベント ソースを追加した (Azure Time Series Insights はキャッチアップする必要があります)。
- 環境にイベント ソースを追加した結果、追加イベントによるスパイクが発生した (環境の容量を超えた可能性があります)。
- 大量の履歴イベントをイベント ソースにプッシュした結果、ラグが発生した (Azure Time Series Insights はキャッチアップする必要があります)。
- 参照データをテレメトリと結合した結果、イベントのサイズが大きくなった。 パケットの最大許容サイズは 32 KB です。32 KB を超えるデータ パケットは切り詰められます。
ビデオ
Azure Time Series Insights データのイングレス動作とそれを計画する方法の説明
アラートを使用した待機時間と調整の監視
アラートは、環境で発生する待機時間の問題の診断および緩和に役立ちます。
Azure portal で、Azure Time Series Insights 環境を選択します。 次に、[アラート] を選択します。

[+ 新しいアラート ルール] を選択します。 [ルールの作成] パネルが表示されます。 [条件] の [追加] を選択します。

次に、シグナル ロジックの正確な条件を構成します。
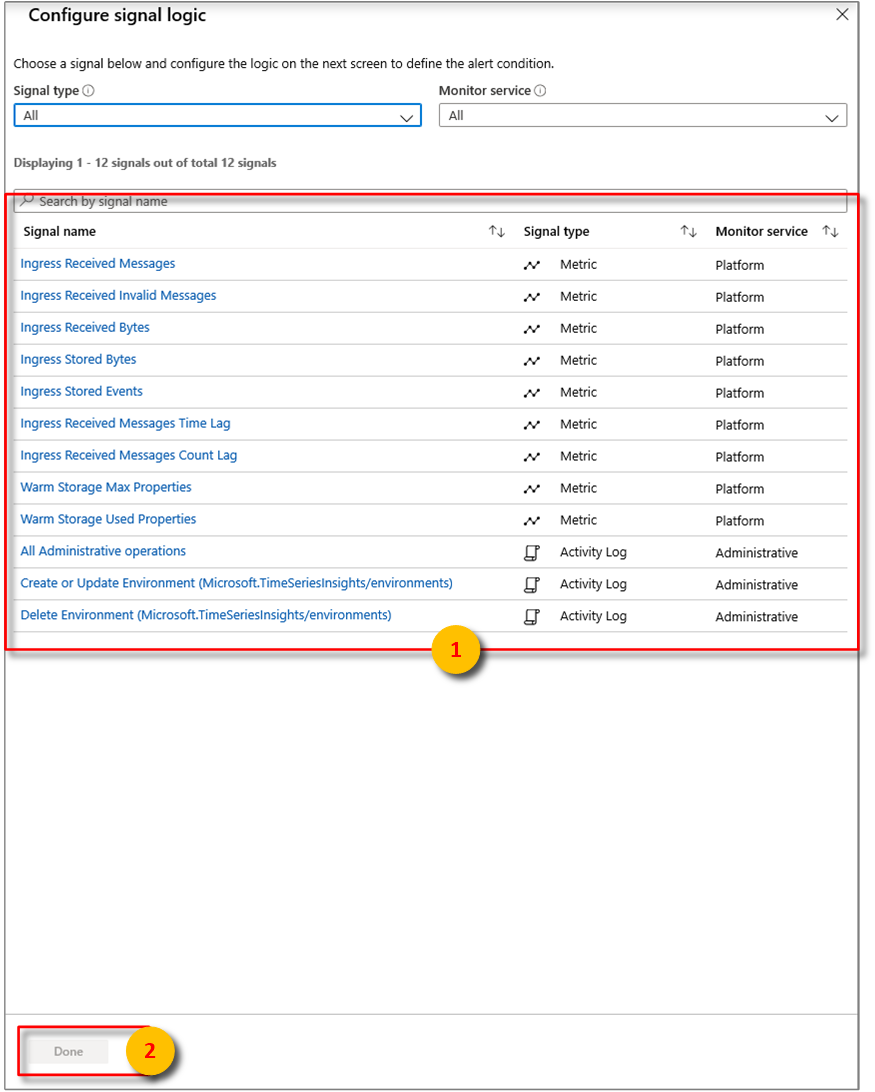
そこから、次のいずれかの条件を使用してアラートを構成できます。
メトリック 説明 受信バイトの受信 イベント ソースから読み取られた生バイト数。 通常、生バイト数にはプロパティの名前と値が含まれます。 無効な受信メッセージの受信 すべての Azure Event Hubs または Azure IoT Hub イベント ソースから読み取られた無効なメッセージの数。 受信メッセージの受信 すべての Event Hubs または IoT Hub イベント ソースから読み取られたメッセージの数。 保存済みバイトの受信 クエリ用に保存済みで利用できるイベントの合計サイズ。 サイズはプロパティ値のみに基づいて計算されます。 Ingress Stored Events (保存済みイベントの受信) クエリ用に保存済みで利用できるフラット化されたイベントの数。 Ingress Received Message Time Lag (受信メッセージの受信のタイム ラグ) メッセージがイベント ソースでエンキューされた時刻とそれがイングレスで処理された時刻の間の差 (秒単位)。 Ingress Received Message Count Lag (受信メッセージの受信のカウント ラグ) イベント ソース パーティションで待ち行列の最後に入っているメッセージのシーケンス番号とイングレスで処理されているメッセージのシーケンス番号の間の差。 完了 を選択します。
目的のシグナル ロジックを構成したら、選択したアラート規則を目視で確認します。
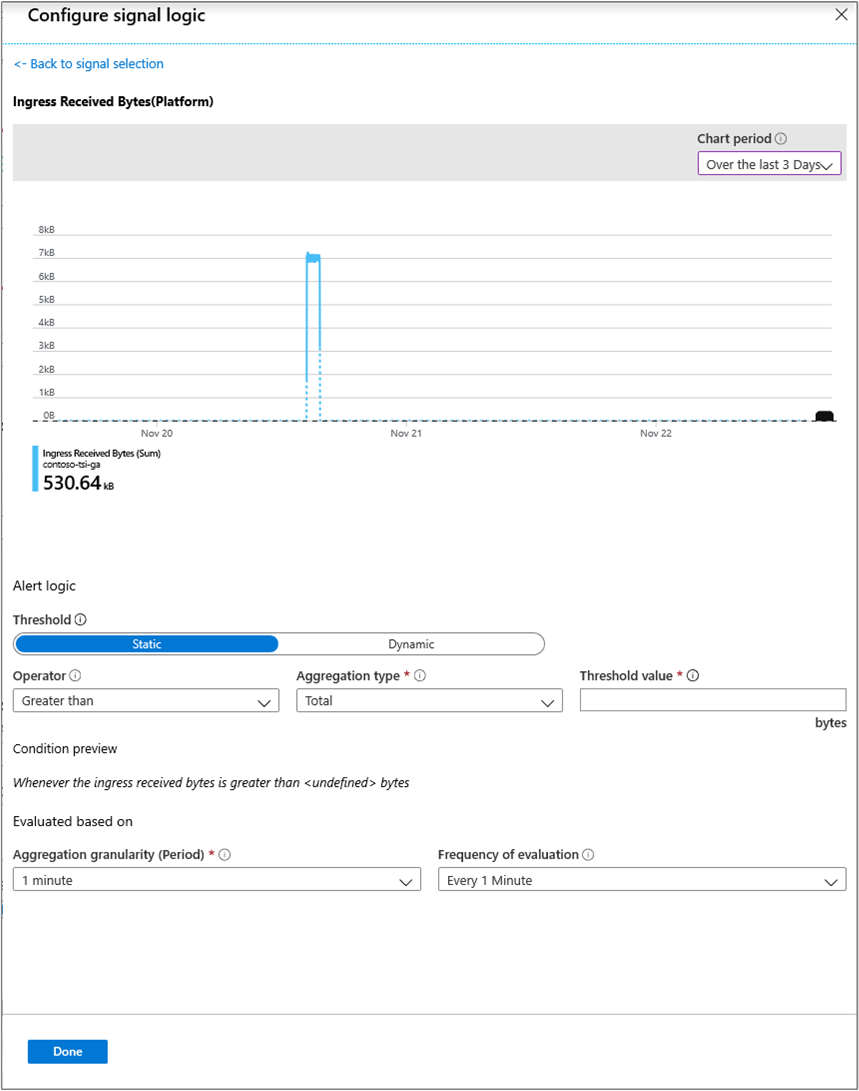




調整とイングレスの管理
調整中、[受信メッセージの受信のタイム ラグ] の値が登録され、メッセージがイベント ソースに届く実際の時間から Azure Time Series Insights 環境が何秒遅れているのかが通知されます (約 30 ~ 60 秒のインデックス作成時間を除きます)。
[Ingress Received Message Count Lag]\(受信メッセージの受信のカウント ラグ\) にも値が含まれるはずです。その値で何通のメッセージが送れているのか判断できます。 遅れを取り戻す最も簡単な方法は、差を埋めるだけのサイズまで環境の容量を増やすことです。
たとえば、S1 環境が 5,000,000 メッセージの遅れを示している場合、環境のサイズを 6 ユニットまで増やせば 1 日がかりで追いつける可能性があります。 さらに増やせば、それだけ短時間で追いつくことができます。 このキャッチアップ期間は、環境に初めてプロビジョニングするときに一般的に発生します。特に、イベントが既に入っているイベント ソースに接続するときや、大量の履歴データを一括アップロードするときに発生します。
別の方法としては、2 時間の環境の合計容量より若干低いしきい値以上に保存済みイベントの受信アラートを設定することです。 このアラートは、頻繁に容量に達しているかどうかを理解するのに役立ちます。そのような状況は、待機時間が発生する可能性が高いことを示しています。
たとえば、3 つの S1 ユニットをプロビジョニング済み (または 1 分間の受信容量あたり 2100 イベント) の場合、保存済みイベントの受信アラートを 2 時間に対して 1900 イベント以上に設定できます。 このしきい値を頻繁に超えてアラートがトリガーされる場合、プロビジョニング不足である可能性が高いです。
調整されている疑いがある場合、受信メッセージの受信をイベント ソースの送信メッセージと比較できます。 Event Hub への受信が受信メッセージの受信より大きい場合、Azure Time Series Insights は調整されている可能性があります。
パフォーマンスの向上
調整や待機時間を軽減するための最善の修正方法は、環境の容量を増やすことです。
分析するデータ量に合わせて環境を正しく構成することによって待機時間と調整を回避できます。 環境内に容量を追加する方法の詳細については、環境のスケーリングに関する記事を参照してください。