ワークロードの正常性モデリング
クラウド アプリケーションでは大量の運用データが生成されるため、問題を迅速に特定して解決することが困難になります。 この課題の一般的な理由は、ワークロードの機能に合わせてカスタマイズされた正常性ベースラインが存在しないことと、そのベースラインからのドリフトを検出できないことです。
正常性モデリングは、ビジネス コンテキストと生の監視データを組み合わせてワークロードの全体的な正常性を定量化する可観測性の演習です。 これは、ワークロードを監視できるベースラインを設定するのに役立ちます。 インフラストラクチャとアプリケーション コンポーネントからのテレメトリなどのデータを検討する必要があります。 正常性モデリングには、ワークロードの品質目標を達成するために必要な他の情報も組み込まれる場合があります。
パフォーマンスの問題や運用上の低下により、予想される動作状態からのずれが発生する可能性があります。 ワークロードの正常性をモデル化することで、ドリフトを特定し、ビジネスへの影響を考慮した情報に基づいた運用上の決定を行うことができます。
正常性モデリングは、部族の運用に関する知識と実用的な分析情報の間のギャップを埋めます。 重要な問題を効果的に管理するのに役立ちます。 この概念は、信頼性と運用の有効性を最大化するために不可欠です。
このガイドでは、ワークロードとそのすべてのサブシステムのランタイム正常性を評価するモデルを構築する方法など、正常性モデリングに関する実用的なガイダンスを提供します。
| 用語 | 定義 |
|---|---|
| 正常性のモデリング | ビジネス コンテキストを使用して監視データを正常性状態として解釈する可観測性の演習。 |
| 正常性モデル | 特定のスコープに対する論理エンティティとそのリレーションシップのグラフィカル表現。 各ノードには、モデル全体で監視データを合理化するための正常性状態定義があります。 |
| 正常性エンティティ | システムの個々の単位、複数の関連エンティティの論理組み合わせ、またはシステム全体を表す論理コンポーネント。 |
| 正常性の状態 | エンティティの正常性に関する意味のある運用上の分析情報を提供する、定義済みの測定可能な状態。 |
| 正常性シグナル | エンティティの動作に関する分析情報を提供する個々のデータ ストリーム。 |
| モデルのモデル | エンティティがコンポーネント システムの個別の正常性モデルを表す集計モデリング スコープ。 |
正常性モデリングの概要を理解するには、このビデオをwatchすることをお勧めします。
正常性、正常性モデリング、および正常性モデルとは
"正常性" という用語は、エンティティとその依存関係の操作状態を指します。 そのエンティティには、システムの個々の単位、複数の関連エンティティの論理的な組み合わせ、またはシステム全体を指定できます。
正常性は、次の 3 つの状態のいずれかで表することをお勧めします。
健康:最適に動作し、品質の期待に応える
低下: 潜在的な問題を示す正常な動作よりも少ない
異常: 重大な状態にあり、直ちに注意が必要です
注意
状態の代わりにスコアを使用して正常性を表し、より多くのデータ粒度を提供できます。
正常性状態は、監視データとドメイン情報を組み合わせることによって派生します。 各状態は定義する必要があり、測定可能である必要があります。 正常性状態は、正常性 シグナルを使用して計算されます。これは、エンティティの運用動作に関する分析情報を提供する個々のデータ ストリームです。 シグナルには、メトリック、ログ、トレース、またはその他の品質特性を含めることができます。 たとえば、仮想マシン (VM) エンティティの正常性シグナルによって、CPU 使用率メトリックが追跡される場合があります。 このエンティティのその他のシグナルには、メモリ使用量、ネットワーク待機時間、またはエラー率が含まれる場合があります。
正常性シグナルを定義するときに、ワークロードの非機能要件を考慮します。 CPU 使用率の例では、正常性状態ごとに予想されるしきい値を含めます。 使用率がワークロード要件に従って許容しきい値を超えた場合、システムは 正常 から 低下 または異常に移行 します。 これらの状態の変更によって、適切なアラートまたはアクションがトリガーされます。
正常性モデリングでは、エンティティに、複数の正常性シグナルから派生し、ワークロードにコンテキスト化された適切に定義された状態が必要です。 たとえば、VM の正常性定義は次のようになります。
正常: 応答時間、リソース使用率、システム全体のパフォーマンスなど、主要な非機能要件とターゲットが完全に満たされます。 たとえば、要求の 95% は 500 ミリ秒以内に処理されます。 ワークロードは、CPU、メモリ、ストレージなどの VM リソースを最適に使用し、ワークロードの需要と使用可能な容量のバランスを維持します。 ユーザー エクスペリエンスは予想されるレベルです。
低下: リソースは最適なパフォーマンスを発揮していませんが、引き続き動作しています。 たとえば、ストレージ ディスクで調整の問題が発生しています。 ユーザーの応答が遅くなる可能性があります。
異常: 劣化が許容される制限を超えています。 リソースの応答性が低下したり、利用できなくなったり、システムが許容されるパフォーマンス レベルを満たさなくなったりします。 ユーザー エクスペリエンスは深刻な影響を受ける。
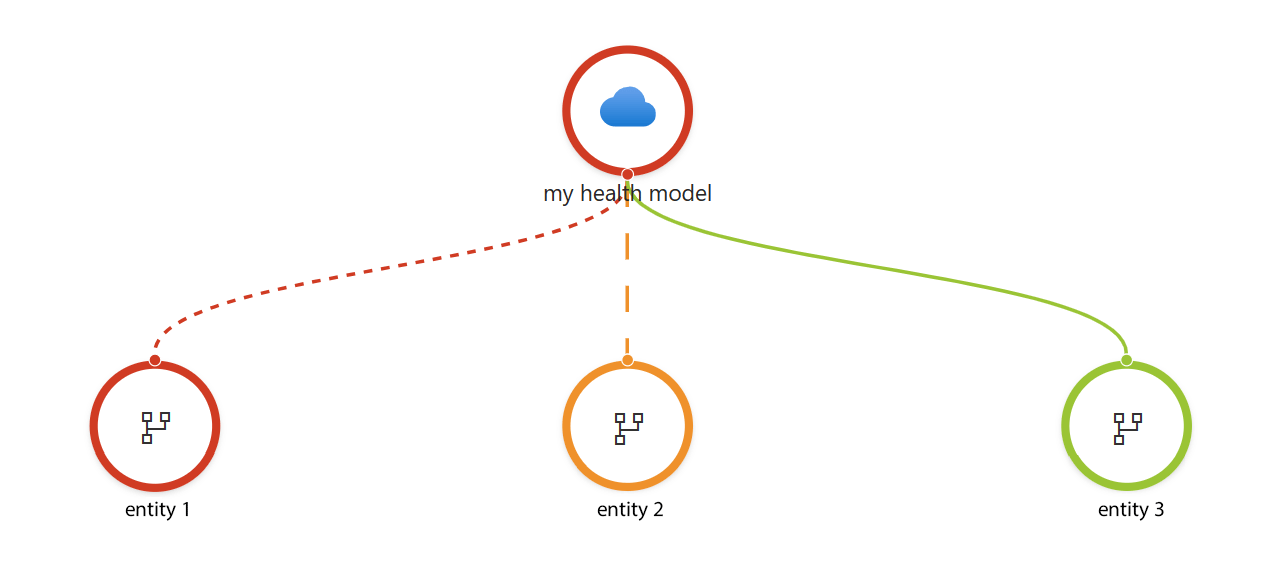
正常性モデリングの結果は、ワークロード アーキテクチャの論理エンティティとその関係の モデル またはグラフィカル表現です。 各ノードには正常性状態の定義があります。
重要
正常性モデリング は、ビジネス シナリオを十分に理解していれば、さまざまなスコープで実装して適用できる抽象的な概念です。

画像では、次のようになります。
エンティティ は、システムの側面を表すワークロードの論理コンポーネントです。 サーバー、データベース、ネットワークなどのインフラストラクチャ コンポーネントにすることができます。 また、特定のアプリケーション モジュール、ポッド、サービス、またはマイクロサービスを指定することもできます。 または、エンティティは、ワークロード内のユーザー操作とシステム フローをキャプチャできます。
注意
ユーザー フローとシステム フローは、アプリケーションおよびインフラストラクチャ コンポーネントを含むビジネス シナリオ全体の非機能要件をまとめたものです。 この概要には、アプリケーションのビジネス価値が反映されます。
システム内の依存関係チェーンミラーエンティティ間のリレーションシップ。 たとえば、アプリケーション モジュールは、 リレーションシップを形成する特定のインフラストラクチャ コンポーネントを呼び出す場合があります。
eコマース ワークロードで、Azure Service Bus キューで失敗したメッセージが急増し、支払いが失敗するシナリオを考えてみましょう。 この問題は、暗黙的な収益損失のためにorganizationにとって重要です。 アプリケーション開発者は、このメトリックスパイクが支払いに及ぼす影響を理解しているかもしれませんが、この部族の知識は運用チーム全体で共有されることはあまりありません。
正常性モデルを使用すると、オペレーターは問題とその影響をすぐに可視化できます。 支払いフローは、ワークロード コンポーネントの 1 つである Service Bus に依存します。 視覚的な表現により、Service Bus インスタンスの低下状態と、その支払フローへの影響が明らかになります。 オペレーターは、問題の重要性を理解し、その特定のコンポーネントに修復作業を集中させることができます。
正常性モデリングは、前のシナリオでは次の点で重要でした。
問題の分離を高速化することで、検出時間 (TTD) と軽減時間 (TTM) が向上し、問題と潜在的な修正プログラムの検出が迅速になりました。
オペレーターは正常性状態に基づいてアラートを受け取り、不要なノイズを減らしました。 オペレーターは、支払いに対するビジネスへの影響に関する特定のコンテキストを提供する通知を受け取った。
依存関係チェーンは、オペレーターが運用上の問題の程度を完全に理解するのに役立ちました。 この知識は、影響評価を促進し、優先順位付けされた対応につながりました。 また、オペレーターは、カスケードまたは相関する問題を簡単に特定できます。
オペレーターは、正常性モデルが異常の根本原因と関連する特定の正常性シグナルに関する分析情報を提供したため、インシデント後のアクティビティを正確に実行しました。
これは、すべてのチーム メンバーにとって監視データを意味のあるものにしました。 これは、部族の知識と共有された洞察の間のギャップを埋め合わしました。
organizationは、AI 主導の運用への将来の投資のベースラインとして正常性モデルを使用して、インテリジェントな分析情報を導き出しました。
正常性モデル スキーマ
正常性モデルは、可観測性のユース ケース用に最適化された個別のデータ スキーマを提供します。 このスキーマは、抽象的な概念から測定可能なソリューションに正常性モデリングを取ります。 特定の要件、目標、アーキテクチャ コンテキストをモデル化することで、独自のシナリオに合わせて正常性データを調整できます。

正常性は、相対的なデータの概念です。 各モデルは、同じエンティティ セットを使用している場合でも、コンテキスト スコープに対して一意で優先順位が付いた正常性データを表します。 特定のシナリオで 正常 に構成されるものは、他のコンテキストで大きく異なる場合があります。
たとえば、ワークロード内で同じ種類の Azure リソースを考えてみましょう。
- VM A は、CPU に依存するアプリケーションを実行します。
- VM B は、メモリを集中的に使用するサービスを処理します。
これらのマシンの正常性定義は異なります。 CPU 使用率メトリックは VM A の正常性状態に影響を与える可能性があり、VM B はメモリ関連のメトリックに優先順位を付ける可能性があります。
重要
正常性モデルでは、すべての障害を同じように扱うべきではありません。 予期される障害または一時的な障害と回復可能な障害と、実際の障害状態を明確に区別する必要があります。
正常性モデルを構築する
正常性モデルを構築するための最初の手順は、論理的な設計演習であり、通常は次のセクションで説明するアクティビティが含まれます。

ワークロード設計を評価する
この論理設計演習を開始するには、ワークロード設計の次のコンポーネントを評価します。
コンピューティング クラスターやデータベースなどのインフラストラクチャ コンポーネント
コンピューティングとその関連コンポーネントで実行されるアプリケーション コンポーネント
コンポーネント間の論理的または物理的な依存関係
たとえば、eコマース アプリケーションの正常性モデルは、ユーザーのサインイン、チェックアウト、支払いなどの重要なプロセスの現在の状態を表す必要があります。
ビジネス要件を使用したコンテキスト化
各フローがorganizationに与える相対的な重要度と全体的な影響を評価します。 ユーザー エクスペリエンス、セキュリティ、運用効率などの要因を考慮してください。 たとえば、ほとんどのシナリオでは、支払いプロセスの失敗は、レポート プロセスの失敗よりも重要である可能性があります。
各フローに関連する問題を処理するためのエスカレーション パスを特定します。 詳細については、「 フローを使用してワークロード設計を最適化する」を参照してください。
注意
正常性モデリングの価値は、ビジネス シナリオとコンテキストを組み込む場合にのみ実現します。 その後、運用上の問題によるビジネスへの影響を合理化できます。
信頼性メトリックへのマップ
アプリケーション設計全体で関連する 信頼性メトリック を探します。
アプリケーション全体とその個々のビジネス プロセスに対して、サービス レベル インジケーター (SLI) とサービス レベル目標 (SLO) を定義することを検討してください。 これらの SLI と SLO は、正常性モデルで考慮される特定の正常性シグナルと一致する必要があります。 これにより、アプリケーションの許容可能なサービス レベルの達成を正確に反映する正常性の包括的な定義を作成します。
重要
SLI と SLO は、重要な正常性シグナルです。 必要なサービスのレベルを他の品質属性と共に反映する、正常性の意味のある定義が作成されます。 また、サービス正常性目標 (CIO) を定義して、集計された時間範囲で達成する正常性をキャプチャすることもできます。
正常性シグナルを識別する
包括的な正常性モデルを構築するには、メトリック、ログ、トレースなど、さまざまな種類の監視データを関連付けます。 これにより、正常性の概念が、特定のエンティティまたはワークロード全体のランタイム状態を正確に反映するようにします。
プラットフォームのメトリックとログを使用する
正常性モデリングのコンテキストでは、基になる Azure リソースからプラットフォーム レベルのメトリックとログを収集することが不可欠です。 これらのメトリックには、CPU 使用率、ネットワークインとネットワークアウト、1 秒あたりのディスク操作が含まれます。 正常性モデルでこのデータを使用して、信頼性の高い環境を維持しながら潜在的な問題を検出して予測できます。
さらに、このアプローチは、一時的な障害、一時的な中断、非一過性障害、または永続的な問題を区別するのに役立ちます。
注意
ベスト プラクティスとして、選択したログ集計テクノロジに診断ログとメトリックを送信するように、すべてのアプリケーション リソースを構成する必要があります。 Azure Policyを使用してガードレールを構築し、アプリケーション全体で一貫した診断設定を確保し、各 Azure サービスに対して選択した構成を適用します。
アプリケーション ログを追加する
アプリケーション ログは、正常性モデルの診断データの重要なソースです。 アプリケーション ログのベスト プラクティスを次に示します。
セマンティック ログまたは構造化ログ記録を使用します。 構造化ログを使用すると、大規模なログ データの自動消費と分析が容易になります。
ストレージ アカウントではなく Azure Monitor ログ ワークスペースに Azure リソース メトリックと診断 データを格納することを検討してください。 この方法を使用すると、 Kusto クエリ を使用して正常性シグナルを作成し、効率的な評価を行うことができます。
運用環境でデータをログに記録します。 アプリケーションが運用環境で動作している間に、包括的なデータをキャプチャします。 正常性評価と、検出された運用環境の問題の診断には、十分な情報が不可欠です。
サービス境界でイベントをログに記録します。 サービスの境界を通過する関連付け ID を含めます。 トランザクションに複数のサービスが関係し、そのうちの 1 つが失敗した場合、関連付け ID は、アプリケーション全体で要求を追跡し、エラーの原因を特定するのに役立ちます。
非同期ログを使用します。 アプリケーション コードをブロックする可能性がある同期ログ記録操作は避けてください。 非同期ログは、ログの書き込み中に要求バックログを防ぐことで可用性を確保します。
アプリケーション のログ記録と監査を分離します。 診断ログとは別に監査ログを維持します。 監査レコードはコンプライアンスまたは規制の要件を満たしますが、それらを個別に維持すると、トランザクションが削除されるのを防ぐことができます。
分散トレースを実装する
重要なシステム フロー間で テレメトリを関連付けることで 、分散トレースを実装します。 相関テレメトリは、エンドツーエンドのトランザクションに関する分析情報を提供し、障害が発生した場合の有効な根本原因分析 (RCA) に不可欠です。
正常性プローブを使用する
アプリケーションの外部で正常性プローブを実装して実行し、アプリケーションの正常性と応答性を明示的にチェックします。 正常性モデル内のシグナルとしてプローブ応答を使用します。
アプリケーション全体または個々のコンポーネントからの応答時間を測定することで、正常性プローブを実装できます。 プローブはプロセスを実行して待機時間とチェック可用性を測定したり、アプリケーションから情報を抽出したりできます。 詳細については、「正常性エンドポイントの監視パターン」を参照してください。
ほとんどのロード バランサーでは、構成された間隔でアプリケーション エンドポイントに ping を実行する正常性プローブの実行がサポートされています。 または、外部ウォッチドッグ サービスを使用することもできます。 ウォッチドッグ サービスは、ワークロード内の複数のコンポーネントからの正常性チェックを集計します。 ウォッチドッグは、既知の正常性状態に対して即時修復を行うコードをホストすることもできます。
構造と機能の監視手法を採用する
構造の監視には、セマンティック ログとメトリックをアプリケーションに装備する必要があります。 アプリケーションは、これらのメトリックを直接収集します。これには、現在のメモリ消費量、要求待機時間、およびその他の関連するアプリケーション レベルのデータが含まれます。
機能監視を使用して監視プロセスを強化します。 このアプローチでは、プラットフォーム サービスの測定と、全体的なユーザー エクスペリエンスへの影響に焦点を当てています。 構造監視とは異なり、機能監視ではシステムに関する詳細な知識は必要ありません。 アプリケーションの外部から見える動作をテストします。 このアプローチは、SLO と SLI を評価する場合に役立ちます。
設計をモデル化する
識別されたアプリケーション設計をエンティティとリレーションシップとして表します。 正常性シグナルを特定のコンポーネントにマップして、エンティティ レベルで正常性状態を定量化します。 正常性状態がモデルを通じて伝達される方法を決定するには、コンポーネントの重要度を考慮してください。 たとえば、レポート コンポーネントは他のコンポーネントほど重要ではなく、ワークロード全体の正常性に異なる影響を及ぼす可能性があります。
アクション可能なアラートを設定する
評価された正常性状態を使用して、アラートと自動アクションをトリガーします。 正常性は、コア監視データテネットとして、既存の運用 Runbook 内に統合する必要があります。
通常、監視データとアラート ルールの間には 1 対 1 のマッピングがあり、アラート ストームやアンビエント アラート ノイズなどの望ましくない結果につながる可能性があります。 たとえば、コンピューティング クラスターでは、CPU 使用率とエラー数に基づいて大量の VM レベルのアラートが失敗時にオペレーターを圧倒し、解決の遅延を引き起こす可能性があります。 同様に、構成されたアラートの数が多い場合、アンビエント アラート ノイズによって、見落とされたり無視されたりするアラートが発生することがよくあります。
正常性モデルでは、監視データとアラート ルールの分離が導入されます。 正常性定義は、多くのシグナルを 1 つの正常性状態に集約します。これにより、オペレーターがorganizationにとって重要な価値の高いアラートのみに集中できるように、アラートの数が減ります。 eコマースのシナリオを考えてみましょう。 Service Bus キューなどの基になるリソースの変更ではなく、プロセス支払フローの正常性の変更に関する通知を送信するようにアラートを設定できます。
注意
正常性モデルのすべてのレイヤーにわたってアラートを生成する機能により、さまざまなワークロード ペルソナに柔軟性が提供されます。 アプリケーション所有者と製品マネージャーは、主要なビジネス シナリオまたはワークロード全体の正常性状態の変化に関するアラートを受け取ることができます。 オペレーターは、インフラストラクチャまたはアプリケーション コンポーネントの正常性に基づいてアラートを生成できます。
モデルを視覚化する
正常性モデルの現在の状態と履歴を効果的に伝えるために、テーブルやグラフなどの視覚的表現を作成します。 視覚化がビジネス コンテキストと一致し、実用的な分析情報を提供していることを確認します。
正常性モデルを視覚化する場合は、 トラフィック ライト アプローチを採用して、依存関係チェーン全体で正常性状態をすぐに洞察できるようにします。
正常な場合は緑色、低下した場合はアンバー、異常な場合は赤を割り当てます。 色分けされた状態をすばやく特定することで、アプリケーションの劣化の根本原因を効率的に見つけることができます。
注意
健康モデルのダッシュボードを作成するときは、視覚障碍のあるユーザーのアクセシビリティ要件を検討することをお勧めします。 図のベスト プラクティスについては、「 アーキテクチャ設計図」を参照してください。
正常性モデルを採用する
正常性モデルを構築したら、次のユース ケースを考慮して、障害や運用上の問題の検出と解釈を促進します。
さまざまなロールへの適用性
正常性モデリングでは、ジョブ機能またはワークロードの同じコンテキスト内のロールに固有の情報を提供できます。 たとえば、DevOps ロールには運用正常性情報が必要な場合があります。 セキュリティ責任者は、侵入信号とセキュリティの露出についてより懸念している可能性があります。 データベース管理者は、データベース リソースを介してアプリケーション モデルのサブセットにのみ関心を持つ可能性があります。
さまざまな利害関係者に合わせて正常性分析情報を調整します。 重複するデータ セットから個別のモデルを作成することを検討してください。
継続的な検証
正常性モデルを使用して、ロード テストやカオス テストなどのテストと検証プロセスを最適化します。 正常性モデルをエンジニアリング ライフサイクルに組み込むことで、テスト中にランタイムの運用状態を検証し、スケール シナリオと障害シナリオでモデルの有効性を評価できます。
組織の正常性
正常性モデリングは通常、個々のアプリケーションの正常性状態の定量化に関連していますが、その適用性はその範囲を超えています。
個々のワークロード レベルでは、正常性モデルによって、アプリケーションの可観測性と運用上の分析情報の基盤が提供されます。 各アプリケーションには、コンテキスト内の各正常性状態の意味をキャプチャする独自の正常性モデルを用意できます。
モデルのモデルを構築することで、複数 の正常性モデルを高レベルのコンストラクトに組み合わせることができます。 たとえば、大規模なモデル内のコンポーネントとして正常性モデルを使用することで、ビジネス ユニットまたはクラウド資産全体の監視フットプリントを構築できます。 正常性モデルは、資産内のワークロードを最上位のグラフ内のノードとして表します。 このモデルのリレーションシップを使用して、データ フロー、サービス相互作用、共有インフラストラクチャなど、アプリケーション間の依存関係をキャプチャします。
eコマース、支払い、注文処理のさまざまなアプリケーションを持つ小売企業を考えてみましょう。 これらの各アプリケーションを独立した正常性モデルとして定義して、そのワークロードの正常性の意味を定量化できます。 その後、親モデルを使用して、これらすべてのコンポーネント正常性モデルをエンティティとしてマップし、依存関係チェーンを通じてアプリケーション間の運用への影響をキャプチャできます。 たとえば、eコマース アプリケーションが異常になった場合、支払いアプリケーションにカスケード効果があります。
IT 運用の正常性の傾向と AI
正常性モデリングでは、特定のビジネス コンテキストに合わせて調整される定量化された運用ベースラインが提供されます。 AI for IT 運用 (AIOps) は、運用効率を向上させる一般的な方法です。 正常性データは、正常性の傾向を分析するための機械学習モデルの基本的な入力です。 たとえば、機械学習モデルでは次のことができます。
状態の変更からさらに分析情報を抽出し、アクションを推奨します。
時間の経過に伴う正常性の傾向を分析して、問題の予測とモデルの絞り込みを促進します。
正常性モデルを維持する
heath モデルの維持は、アプリケーションの開発と運用に合わせた継続的なエンジニアリング アクティビティです。 アプリケーションの進化に合わせて、正常性モデルが並行して進化していることを確認します。
また、正常性モデルは、開発ライフサイクルに統合する必要があるワークロード成果物のように扱います。 正常性モデルの一貫性のあるバージョン管理のために、コードとしてのインフラストラクチャ (IaC) を採用します。 ワークロードに対してインフラストラクチャとアプリケーション コンポーネントを追加または削除するときにモデルが最新の状態に保たれるように、自動化を使用します。
正常性データは、時間の経過と同時に値が徐々に減少します。 運用効率を最適化し、コストを最小限に抑えるには、正常性データを 30 日を超えて保持しないようにします。 必要に応じて、監査要件を満たすためにデータをアーカイブするか、IT 運用のための AI で長期的なパターン分析を伴うシナリオでデータをアーカイブできます。
注意
正常性データをアーカイブするときは、モデルの構成状態と結合してください。 このコンテキストがないと、状態の変更を解釈するのは困難な場合があります。
関連リンク
- ASP.NET で正常性プローブを実装する方法については、「ASP.NET Coreの正常性チェック」を参照してください。
- メトリックの監視の詳細については、「Azure Monitor メトリックの概要」を参照してください。
- Application Insights の使用方法については、「 Application Insights」を参照してください。
- ミッション クリティカルなワークロードに関連する設計上の考慮事項と推奨事項については、「 Azure でのミッション クリティカルなワークロードの正常性モデリングと監視」を参照してください。
- 実践的なエクスペリエンスについては、「 ミッション クリティカルなワークロードの正常性モデルを設計する」を参照してください。
次のステップ
フィードバック
以下は間もなく提供いたします。2024 年を通じて、コンテンツのフィードバック メカニズムとして GitHub の issue を段階的に廃止し、新しいフィードバック システムに置き換えます。 詳細については、「https://aka.ms/ContentUserFeedback」を参照してください。
フィードバックの送信と表示