ASP.NET Core アプリでのデータの操作
ヒント
このコンテンツは eBook の「ASP.NET Core および Azure での最新の Web アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

"データは貴重なものであり、システム自体よりも長く存在します。"
Tim Berners-lee
データ アクセスは、ほぼすべてのソフトウェア アプリケーションの重要な部分です。 ASP.NET Core は、Entity Framework Core (および Entity Framework 6 も) を含む、さまざまなデータ アクセス オプションをサポートし、どの .NET データ アクセス フレームワークでも使用できます。 使用するデータ アクセス フレームワークの選択は、アプリケーションのニーズによって異なります。 ApplicationCore および UI プロジェクトからのこれらの選択を抽象化し、インフラストラクチャに実装の詳細をカプセル化することは、疎結合のテスト可能なソフトウェアの生成に役立ちます。
Entity Framework Core (リレーショナル データベース用)
リレーショナル データを操作する必要がある新しい ASP.NET Core アプリケーションを作成する場合、Entity Framework Core (EF Core) を使用して、アプリケーションからそのデータにアクセスすることをお勧めします。 EF Core はオブジェクト リレーショナル マッパー (O/RM) であり、.NET 開発者がデータ ソースのオブジェクトを保持できるようにします。 これにより、通常は開発者が記述する必要があるほとんどのデータ アクセス コードが不要になります。 ASP.NET Core と同様、EF Core は、モジュラー型クロスプラットフォーム アプリケーションをサポートするために、完全に書き換えられました。 NuGet パッケージとしてご利用のアプリケーションに追加し、アプリの起動時に構成して、必要に応じて依存関係の挿入を使用して要求します。
SQL Server データベースで EE Core を使用するには、次の dotnet CLI コマンドを実行します。
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
テストのために、InMemory データ ソースのサポートを追加するには、次のコマンドを使用します。
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
EF Core を操作するには、DbContext のサブクラスが必要です。 このクラスでは、ご利用のアプリケーションで操作するエンティティのコレクションを表すプロパティを保持します。 eShopOnWeb サンプルには、アイテム、ブランド、型のコレクションと共に CatalogContext が含まれます。
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext には、DbContextOptions を受け入れるコンストラクターが必要です。また、この引数を基本の DbContext コンストラクターに渡す必要があります。 アプリケーションに DbContext を 1 つだけ含める場合は、DbContextOptions のインスタンスを渡すことができますが、複数含める場合は、汎用の DbContextOptions<T> 型を使用し、汎用パラメーターとして DbContext 型を渡す必要があります。
EF Core の構成
ASP.NET Core アプリケーションでは、通常、アプリケーションの他の依存関係を持つ Program.cs で EF Core を構成します。 EF Core では、構成を効率化するいくつかの便利な拡張メソッドをサポートする、DbContextOptionsBuilder を使用します。 Configuration で定義されている接続文字列で SQL Server データベースを使用するように CatalogContext を構成するには、次のコードを追加します。
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
メモリ内データベースを使用するには、次のようにします。
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
EF Core をインストールして、DbContext の子の型を作成し、その型をアプリケーションのサービスに追加したら、EE Core を使用できます。 DbContext 型のインスタンスを必要とする任意のサービスで要求し、単にコレクション内にある場合と同じように、LINQ を使用して永続化されたエンティティの操作を開始することができます。 EF Core では、ご利用のデータを格納して取得するために、LINQ 式を SQL クエリに変換する作業を行います。
図 8-1 に示すように、ロガーを構成し、そのレベルが少なくとも Information に設定されていることを確認することで、EF Core で実行されるクエリを確認できます。
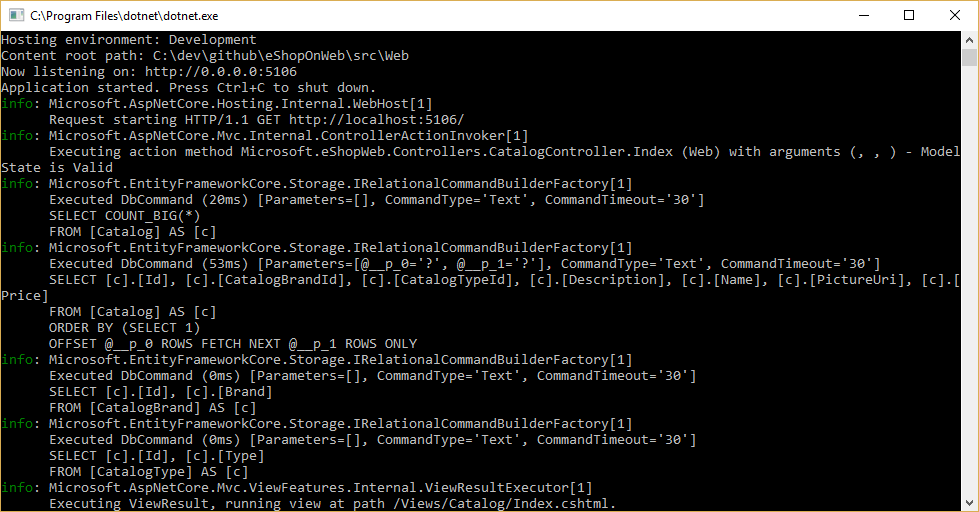
図 8-1。 コンソールへの EF Core クエリのログ記録
データのフェッチと格納
EF Core からデータを取得するには、適切なプロパティにアクセスし、LINQ を使用して結果をフィルター処理します。 また、LINQ を使用して射影を実行し、1 つの型から別の型に結果を変換することもできます。 次の例では、CatalogBrands を取得します。ここでは、名前で並べ替え、Enabled プロパティでフィルター処理し、SelectListItem 型に射影します。
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
上記の例では、クエリをすぐに実行するために、ToListAsync への呼び出しを追加することが重要です。 それ以外の場合、ステートメントは IQueryable<SelectListItem> を brandItems に割り当て、列挙されるまで実行されません。 メソッドから IQueryable 結果を返すことには長所と短所があります。 EF Core で構築されるクエリをさらに変更できますが、EF Core で変換できないクエリに操作が追加された場合、実行時にのみ発生するエラーが発生する可能性もあります。 データ アクセスを実行するメソッドにすべてのフィルターを渡して、結果としてメモリ内コレクション (List<T> など) を戻す方が一般的には安全です。
EF Core は、永続化からフェッチするエンティティの変更を追跡します。 追跡対象エンティティの変更を保存するには、DbContext で SaveChangesAsync メソッドを呼び出すだけです。これで、エンティティのフェッチに使用されたものと同じ DbContext インスタンスであることが確認されます。 エンティティの追加と削除は適切な DbSet プロパティで直接行います。この場合も、データベース コマンドを実行するために SaveChangesAsync を呼び出します。 次の例では、永続化のエンティティの追加、更新、および削除を示します。
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core では、フェッチおよび保存のための同期と非同期の両方のメソッドがサポートされます。 Web アプリケーションでは、非同期メソッドで async/await パターンを使用することをお勧めします。これにより、データ アクセス操作が完了するのを待機している間に、Web サーバーのスレッドがブロックされなくなります。
詳細については、「バッファリングとストリーミング」を参照してください。
関連データのフェッチ
EF Core は、エンティティの取得時に、データベースのそのエンティティを直接格納されているすべてのプロパティに設定します。 関連エンティティのリストなどの、ナビゲーション プロパティは設定されず、その値が null に設定される場合があります。 このプロセスにより、EF Core は必要以上のデータをフェッチしなくなります。これは、効率的にすばやく要求を処理し、応答を返す必要がある Web アプリケーションで特に重要です。 一括読み込みを使用して、エンティティとのリレーションシップを含めるには、次のように、クエリで Include 拡張メソッドを使用してプロパティを指定します。
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
複数のリレーションシップを含めることができます。また、ThenInclude を使用して、サブリレーションシップを含めることもできます。 EF Core は単一のクエリを実行して、エンティティの結果セットを取得します。 あるいは、次のように '.' で区切った文字列を .Include() 拡張メソッドに渡すことで、ナビゲーション プロパティを含めることができます。
.Include("Items.Products")
この仕様はフィルタリング ロジックをカプセル化するだけでなく、データを入力するプロパティなど、返すデータのシェイプも指定できます。 eShopOnWeb サンプルには、仕様内で一括読み込み情報のカプセル化を実演するいくつかの仕様が含まれています。 クエリの一部として仕様がどのように使用されるのかここで確認できます。
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
関連データを読み込むために、明示的読み込みを使用することもできます。 明示的読み込みを使用すれば、既に取得されているエンティティに追加データを読み込むことができます。 この方法では、データベースに別の要求を行う必要があるため、要求ごとに行うデータベース ラウンドトリップの数を最小限に抑える必要がある Web アプリケーションにはお勧めできません。
遅延読み込みは、アプリケーションでの参照時に関連データを自動的に読み込む機能です。 EF Core では、バージョン 2.1 で遅延読み込みのサポートが追加されました。 遅延読み込みは既定では有効になりません。Microsoft.EntityFrameworkCore.Proxies をインストールする必要があります。 明示的読み込みと同様、遅延読み込みは通常、Web アプリケーションでは無効にする必要があります。遅延読み込みを使用すると、各 Web 要求内で追加のデータベース クエリが行われるためです。 待機時間が短く、テストに使用されるデータ セットが少量である場合、遅延読み込みによって発生するオーバーヘッドは、残念ながら開発時にはあまり気付かれません。 しかし、ユーザーやデータがより多く、待機時間がより長い運用環境では、追加のデータベース要求により、遅延読み込みを多用する Web アプリケーションのパフォーマンスが低下する可能性があります。
Web アプリケーションでのエンティティの遅延読み込みを回避する
実際のデータベース クエリを調べながら、アプリケーションをテストすることをお勧めします。 特定の状況では、EF Core によって、アプリケーションに最適なクエリよりも多くのクエリやコストのかかるクエリが作成される場合があります。 このような問題は、デカルト爆発と呼ばれます。 EF Core チームは、実行時の動作を調整する方法の 1 つとして、AsSplitQuery メソッド を使用できるようにします。
データをカプセル化する
EF Core は、モデルでその状態を正しくカプセル化するための機能をいくつか備えています。 ドメイン モデルでよくある問題として、コレクションのナビゲーション プロパティが一般にアクセス可能なリスト型として公開されることがあります。 この問題により、すべてのコラボレーターがこれらのコレクション型のコンテンツを操作できるようになり、結果として、コレクションに関係する重要なビジネス ルールが無視され、オブジェクトが無効な状態のままになるおそれがあります。 この問題の解決策は、関連するコレクションへの読み取り専用アクセスを公開することと、クライアントがこれらのコレクションを操作する方法を定義したメソッドを明示的に提供することです。次の例をご覧ください。
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
このエンティティ型ではパブリックの List または ICollection プロパティが公開されず、代わりに、基になるリスト型をラップする IReadOnlyCollection 型が公開されます。 このパターンを使用するとき、次のように、バッキング フィールドを使用するように Entity Framework Core に指示できます。
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
ドメイン モデルを改善する別の方法としては、ID がなく、そのプロパティだけで区別される型に値オブジェクトを使用するという方法があります。 エンティティのプロパティとしてこのような型を使用すると、ロジックはそれが属する値オブジェクトに固有となり、同じ概念を使用する複数のエンティティ間でロジックが重複することがありません。 Entity Framework Core では、次のように、所有されるエンティティとして型を構成することで、所有するエンティティと同じテーブルに値オブジェクトを保持できます。
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
この例では、ShipToAddress プロパティの型は Address です。 Address は、Street や City など、いくつかのプロパティを持つ値オブジェクトです。 EF Core では、Address プロパティごとに 1 列の配分で Order オブジェクトがそのテーブルにマッピングされます。各列の名前の先頭にプロパティの名前が接頭辞として付きます。 この例で、Order テーブルに ShipToAddress_Street や ShipToAddress_City などの列が含まれます。 必要に応じて、所有型を別のテーブルに格納することもできます。
詳細については、EF Core の所有エンティティのサポートに関する記事を参照してください。
回復力のある接続
SQL データベースなどの外部リソースが使用できなくなる場合があります。 一時的に使用できなくなった場合、アプリケーションは再試行ロジックを使用して、例外の発生を防ぐことができます。 この手法は一般的に接続の復元性と呼ばれます。 指数バックオフを含む独自の再試行手法は、最大再試行回数に達するまで、指数関数的に増加する待機時間で再試行することで実装できます。 この手法を使用すると、クラウドのリソースが短時間、断続的に使用できなくなるおそれがあり、その結果、一部の要求が失敗してしまいます。
Azure SQL DB の場合、Entity Framework Core に内部データベース接続の復元機能と再試行ロジックが既に用意されています。 ただし、回復力のある EF Core 接続を使用する場合は、各 DbContext 接続に対して Entity Framework 実行戦略を有効にする必要があります。
たとえば、EF Core 接続レベルで次のコードを実行すると、接続が失敗した場合に再試行される回復力のある SQL 接続が有効になります。
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
BeginTransaction と複数の DbContext を使用した実行戦略と明示的なトランザクション
EF Core 接続で再試行を有効にすると、EF Core を使用して実行する各操作は、独自の再試行可能な操作になります。 一時的なエラーが発生した場合、SaveChangesAsync への各クエリと各呼び出しは 1 つのユニットとして再試行されます。
一方、BeginTransaction を使用してトランザクションを開始するコードの場合、1 ユニットとして扱う必要のある独自の操作グループを定義しています。エラーが発生した場合、トランザクション内のすべてがロールバックされる必要があります。 EF 実行戦略 (再試行ポリシー) を使用し、複数の DbContext からの SaveChangesAsync をいくつかトランザクションに含める場合、そのトランザクションを実行しようとすると、次のような例外が表示されます。
System.InvalidOperationException: 構成された実行戦略 SqlServerRetryingExecutionStrategy は、ユーザーが開始したトランザクションをサポートしていません。 DbContext.Database.CreateExecutionStrategy() から返された実行戦略を使用して、再試行可能なユニットとしてトランザクション内のすべての操作を実行します。
この解決策では、実行する必要があるすべてを表すデリゲートを使用して EF 実行戦略を手動で呼び出します。 一時的なエラーが発生した場合、実行戦略によってデリゲートが再び呼び出されます。 次のコードは、この方法を実装する方法を示しています。
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://video2.skills-academy.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
最初の DbContext は _catalogContext で、2 番目の DbContext は _integrationEventLogService オブジェクト内にあります。 最後に、Commit アクションが、複数の DbContext で EF 実行戦略を使用して実行されます。
参照 – Entity Framework Core
- EF Core ドキュメントhttps://video2.skills-academy.com/ef/
- EF Core: 関連データhttps://video2.skills-academy.com/ef/core/querying/related-data
- ASPNET アプリケーションでのエンティティの遅延読み込みを回避するhttps://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core または micro-ORM の選択
EF Core は、永続化を管理するための優れた選択肢であり、ほとんどの場合でアプリケーション開発者からデータベースの詳細をカプセル化することができますが、これが唯一の選択肢というわけではありません。 もう 1 つの一般的なオープンソースの代替手段として、Dapper (いわゆる micro-ORM) もあります。 micro-ORM はデータ構造にオブジェクトをマップするための軽量なツールであり、すべての機能が備わっているわけではありません。 Dapper の場合、その設計目標は、データの取得と更新に使用される基になるクエリの完全なカプセル化ではなく、パフォーマンスに重点を置くことです。 開発者からの SQL が抽象化されないため、Dapper は "機械により近い" ものであり、開発者は特定のデータ アクセス操作で使用する正確なクエリを記述することができます。
EF Core では 2 つの重要な機能が提供されます。これらは Dapper とは異なり、パフォーマンスのオーバーヘッドも増えます。 1 つ目は、LINQ 式から SQL への変換です。 これらの変換はキャッシュされますが、それでも最初の実行時にオーバーヘッドが発生します。 2 つ目は、エンティティの変更追跡です (効率的な更新ステートメントを生成できます)。 この動作は、AsNoTracking 拡張機能を使用することで、特定のクエリに対してオフにすることができます。 また、EF Core は、通常は非常に効率的で、パフォーマンスの観点から完全に受け入れ可能である場合に SQL クエリを生成します。ただし、実行する正確なクエリを微調整する必要がある場合は、EF Core を使用して、カスタム SQL を渡す (またはストアド プロシージャを実行する) こともできます。 この場合も、Dapper は、ほんのわずかではありますが、EF Core より優れています。 さまざまなデータ アクセス方法の現在のパフォーマンス ベンチマーク データについては、Dapper サイトを参照してください。
EF Core と Dapper との構文の違いを確認するために、アイテム リストを取得する同じ方法の次の 2 つのバージョンについて考えてみます。
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Dapper でより複雑なオブジェクト グラフを作成する必要がある場合は、(EF Core の場合と同じように Include を追加するのではなく) 関連付けられているクエリを自分で記述する必要があります。 この機能は、複数のマップされたオブジェクトに個々の行をマップできる、マルチ マッピングという機能などのさまざまな構文で使用できます。 たとえば、User という種類の Owner プロパティを指定した Post クラスの場合、次の SQL では必要なデータがすべて返されます。
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
返された各行には、User と Post の両方のデータが含まれます。 User データを Owner プロパティを使用して Post データにアタッチする必要があるため、次の関数が使用されます。
(post, user) => { post.Owner = user; return post; }
関連付けられているユーザー データが設定された Owner プロパティを使用してポストのコレクションを返すための完全なコード リストは、次のようになります。
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
あまり優れたカプセル化は提供されないため、Dapper では、開発者がデータの格納方法と、データを効率的にクエリし、さらにコードを記述してフェッチする方法の詳細を把握する必要があります。 モデルが変更された場合、単に新しい移行を作成したり (EE Core の別の機能)、DbContext の 1 つの場所でマッピング情報を更新するのではなく、影響を受けるすべてのクエリを更新する必要があります。 これらのクエリではコンパイル時間が保証されないため、モデルやデータベースの変更に応じて実行時に中断し、エラーの迅速な検出がより困難になる可能性があります。 これらのトレードオフと引き換えに、Dapper では非常に高速なパフォーマンスが提供されます。
ほとんどのアプリケーション、およびほぼすべてのアプリケーションのほとんどの部分に対して、EE Core は許容可能なパフォーマンスを提供します。 したがって、その開発者の生産性の利点が、そのパフォーマンスのオーバーヘッドを上回る可能性があります。 キャッシュから利点を得られるクエリの場合、実際のクエリはごくわずかな時間にのみ実行され、比較的小さなクエリ パフォーマンスの違いが問題になる可能性があります。
SQL または NoSQL
従来、SQL Server などのリレーショナル データベースが永続的なデータ記憶域のマーケットプレースの多くを占めますが、使用可能な唯一のソリューションではありません。 MongoDB などの NoSQL データベースでは、オブジェクトを格納するさまざまな方法が提供されます。 オブジェクトをテーブルと行にマップするのではなく、オブジェクト グラフ全体をシリアル化して、結果を格納することもできます。 この方法の利点は、少なくとも最初は単純さとパフォーマンスとなります。 オブジェクトを、そのオブジェクトがデータベースから最後に取得されてから変更された可能性のある、リレーションシップ、更新、および行を持つ多くのテーブルに分解するよりも、キーを持つ単一のシリアル化されたオブジェクトを格納する方が簡単です。 同様に、キーベースのストアから単一のオブジェクトをフェッチして逆シリアル化することは、リレーショナル データベースから同じオブジェクトを完全に構成するために必要な複雑な結合や複数のデータベース クエリよりも通常ははるかに速くて簡単です。 また、ロックやトランザクションあるいは固定スキーマがないため、NoSQL データベースは多くのコンピューターにわたるスケーリングに適しており、非常に大規模なデータセットをサポートできます。
その一方で、NoSQL データベース (通常は呼び出し時に) には欠点があります。 リレーショナル データベースでは、正規化を使用して整合性を適用し、データの重複を防ぎます。 この方法により、データベースの合計サイズが小さくなり、共有データの更新がデータベース全体ですぐに使用できるようになります。 リレーショナル データベースでは、Address テーブルによって、ID を使用して Country テーブルが参照される場合があります。国/地域の名前が変更された場合、アドレス レコードは更新プログラムの利点が得られ、それ自体の更新は必要ありません。 ただし、NoSQL データベースでは、Address とそれに関連付けられている Country が、格納されている多くのオブジェクトの一部としてシリアル化される可能性があります。 国/地域の名前を更新するには、単一行ではなく、すべてのオブジェクトを更新する必要があります。 リレーショナル データベースでは、外部キーのようなルールを適用することで、リレーショナルの整合性を確認することもできます。 通常、NoSQL データベースでは、そのデータに対するこのような制約は提供されません。
NoSQL データベースで対処する必要があるもう 1 つの複雑なものとして、バージョン管理があります。 オブジェクトのプロパティが変更された場合、格納された過去のバージョンから逆シリアル化できなくなる可能性があります。 したがって、シリアル化された (以前の) バージョンのオブジェクトを持つ既存のすべてのオブジェクトを更新して、新しいスキーマに準拠する必要があります。 この方法は、スキーマの変更に更新スクリプトとマッピング更新が必要な場合がある、リレーショナル データベースとは概念的に異なります。 ただし、NoSQL の方法では多くの場合、変更する必要があるエントリの数がはるかに増えます。これは、データの重複が増えるためです。
NoSQL データベースには、リレーショナル データベースでは通常サポートされない固定スキーマなど、複数のバージョンのオブジェクトを格納できます。 ただし、その場合、自分のアプリケーション コードに以前のバージョンのオブジェクトが存在することを考慮する必要があり、複雑さが増します。
通常、NoSQL データベースでは ACID が適用されません。つまり、リレーショナル データベースよりもパフォーマンスとスケーラビリティの両方が優れています。 これは、正規化されたテーブル構造のストレージには適さない非常に大規模なデータセットとオブジェクトに最適です。 単一のアプリケーションでリレーショナル データベースと NoSQL データベースの両方 (それぞれ適宜使用) を利用できない理由はありません。
Azure Cosmos DB
Azure Cosmos DB はフル マネージドの NoSQL データベース サービスであり、クラウドベースのスキーマレスなデータ ストレージを提供します。 Azure Cosmos DB は、高速で予測可能なパフォーマンス、高可用性、エラスティック スケーリング、およびグローバル配布用に作成されています。 NoSQL データベースであるにもかかわらず、開発者は JSON データで豊富で使い慣れた SQL クエリ機能を使用できます。 Azure Cosmos DB のすべてのリソースは、JSON ドキュメントとして保存されます。 リソースは、アイテム (メタデータを含むドキュメント) およびフィード (アイテムのコレクション) として管理されます。 図 8-2 は、さまざまな Azure Cosmos DB リソース間の関係を示しています。
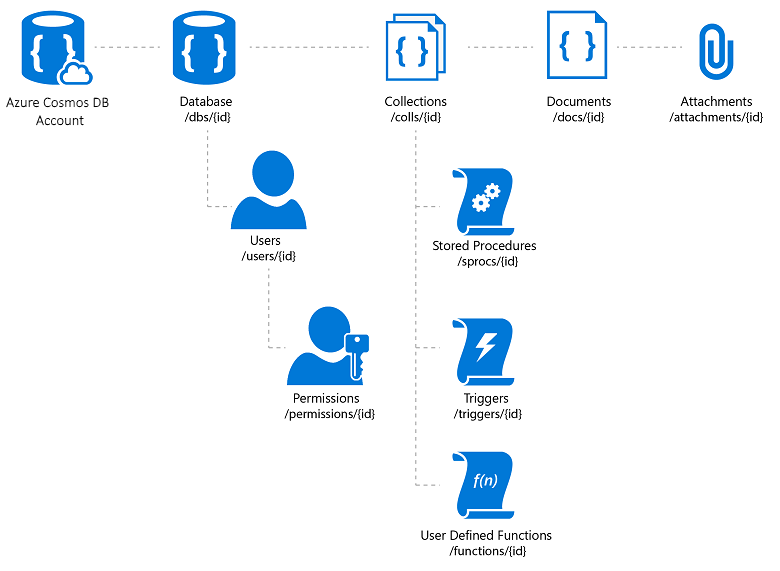
図 8-2 Azure Cosmos DB リソースの編成。
Azure Cosmos DB のクエリ言語は、JSON ドキュメントを照会するためのシンプルで強力なインターフェイスです。 言語では ANSI SQL 文法のサブセットがサポートされ、JavaScript のオブジェクト、配列、オブジェクトの構築、関数呼び出しと緊密に統合できます。
参照 – Azure Cosmos DB
- Azure Cosmos DB の概要 https://video2.skills-academy.com/azure/cosmos-db/introduction
その他の永続性オプション
リレーショナルおよび NoSQL ストレージ オプションに加え、ASP.NET Core アプリケーションでは Azure Storage を使用して、クラウドベースのスケーラブルな方法でさまざまなデータ形式とファイルを格納できます。 Azure Storage は非常にスケーラブルであるため、最初に少量のデータを格納し、アプリケーションで必要になった場合に数百または数テラバイトのデータを格納するようにスケール アップできます。 Azure Storage では次の 4 つの種類のデータがサポートされます。
非構造化テキストまたはバイナリ ストレージ用の Blob Storage。これは、オブジェクト ストレージとも呼ばれます。
行キーを使用してアクセス可能な、構造化データセット用の Table Storage。
信頼性の高いキューベースのメッセージング用の Queue Storage。
Azure 仮想マシンとオンプレミス アプリケーション間での共有ファイル アクセス用の File Storage。
参照 – Azure Storage
キャッシュ
Web アプリケーションでは、各 Web 要求をできるだけ短時間に完了する必要があります。 この機能を実現する 1 つの方法は、サーバーが要求を完了するために行う必要がある、外部呼出しの数を制限することです。 キャッシュでは、サーバー (または、データ ソースよりクエリが簡単な別のデータ ストア) にデータのコピーを格納します。 Web アプリケーション、および特に非 SPA の従来の Web アプリケーションでは、要求ごとにユーザー インターフェイス全体を構築する必要があります。 この方法では、ユーザー要求のたびに同じ多数のデータベース クエリが何度も繰り返されます。 ほとんどの場合、このデータはめったに変更されないため、データベースから常に要求する理由はほとんどありません。 ASP.NET Core では (ページ全体をキャッシュする) 応答キャッシュおよび (より詳細なキャッシュ動作をサポートする) データ キャッシュがサポートされます。
キャッシュを実装する場合、関心の分離に注意することが重要です。 データ アクセス ロジック、またはユーザー インターフェイスでのキャッシュ ロジックの実装は避けてください。 代わりに、独自のクラスにキャッシュをカプセル化し、その動作を管理する構成を使用します。 この方法は、開放/閉鎖および単一責任の原則に従っており、成長に伴う自分のアプリケーションのキャッシュの使用方法を管理しやすくします。
ASP.NET Core の応答キャッシュ
ASP.NET Core では、2 つのレベルの応答キャッシュがサポートされます。 最初のレベルではサーバーには何もキャッシュしませんが、応答をキャッシュするようにクライアントおよびプロキシ サーバーに指示する HTTP ヘッダーを追加します。 この機能は、個々のコントローラーまたはアクションに ResponseCache 属性を追加すると実装されます。
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
前の例では、応答に次のヘッダーが追加され、最大で 60 秒間、結果をキャッシュするようクライアントに指示します。
Cache-Control: public,max-age=60
サーバー側のメモリ内キャッシュをアプリケーションに追加するには、Microsoft.AspNetCore.ResponseCaching NuGet パッケージを参照し、応答キャッシュ ミドルウェアを追加する必要があります。 このミドルウェアは、アプリの起動時に、サービスとミドルウェアを使用して構成されます。
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
応答キャッシュ ミドルウェアは、カスタマイズ可能な一連の条件に基づいて、自動的に応答をキャッシュします。 既定では、GET または HEAD メソッドを使用して要求された 200 (OK) の応答のみがキャッシュされます。 さらに、要求には、Cache-Control: public ヘッダーを含む応答が必要であり、Authorization や Set-Cookie のヘッダーを含めることはできません。 応答キャッシュ ミドルウェアで使用されるキャッシュ条件の完全なリストを参照してください。
データ キャッシュ
完全な Web 応答のキャッシュではなく (または、このようなキャッシュに加えて)、個々のデータ クエリの結果をキャッシュすることができます。 この機能には、Web サーバーでメモリ内キャッシュを使用するか、分散キャッシュを使用できます。 このセクションでは、メモリ内キャッシュの実装方法を示します。
次のコードを使用して、メモリ (または分散) キャッシュのサポートを追加します。
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Microsoft.Extensions.Caching.Memory NuGet パッケージも必ず追加してください。
サービスを追加したら、キャッシュにアクセスする必要がある場合は常に、依存関係の挿入を使用して IMemoryCache を要求します。 この例の CachedCatalogService では、基になる CatalogService 実装へのアクセスを制御 (または動作を追加) する ICatalogService の代替実装を提供することで、プロキシ (またはデコレーター) 設計パターンが使用されます。
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
キャッシュされたバージョンのサービスを使用するが、そのコンストラクターで必要になる CatalogService のインスタンスをサービスが引き続き取得できるようにアプリケーションを構成するには、Program.cs に以下の行を追加します。
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
このコードがあることで、カタログ データをフェッチするデータセット呼び出しは、要求ごとではなく、1 分に 1 回だけ行われるようになります。 サイトへのトラフィックによっては、データベースに対して行われるクエリの数と、このサービスによって公開されている 3 つのクエリすべてに現在依存しているホーム ページの平均ページ読み込み時間に、これが大きな影響を与える可能性があります。
キャッシュの実装時に発生する問題は、"古いデータ" です。つまり、ソースで変更されても、その古いバージョンがキャッシュ内に残っているデータです。 この問題を軽減する簡単な方法は、キャッシュ期間を短くすることです。これは、ビジーなアプリケーションで、データのキャッシュ期間を長くすることで得られる利益が限定的であるためです。 たとえば、単一のデータベース クエリを実行し、1 秒ごとに 10 回要求されるページがあるとします。 このページが 1 分間キャッシュされると、1 分ごとに実行されるデータベース クエリの数は 600 から 1 に減り、99.8% の減少率となります。 代わりにキャッシュ期間を 1 時間にした場合、全体的な減少率は 99.997% となりますが、古いデータの確率的および潜在的な経過期間はどちらも大幅に増えます。
含まれているデータを更新する場合、事前にキャッシュ エントリを削除することもできます。 キーがわかっている場合は、個々のエントリを削除できます。
_cache.Remove(cacheKey);
アプリケーションでキャッシュされているエントリを更新する機能が公開されている場合は、更新を実行するコードの対応するキャッシュ エントリを削除することができます。 特定のデータ セットに依存する多くの異なるエントリが存在する場合もあります。 その場合は、CancellationChangeToken を使用して、キャッシュ エントリ間の依存関係を作成すると便利です。 CancellationChangeToken を使用すれば、トークンをキャンセルすることで一度に複数のキャッシュ エントリを期限切れにすることができます。
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
キャッシュでは、データベースから同じ値を繰り返し要求する Web ページのパフォーマンスを大幅に向上させることができます。 キャッシュを適用する前に、必ずデータ アクセスとページのパフォーマンスを測定し、改善の必要性があると判断した場合にのみ、キャッシュを適用するようにしてください。 キャッシュでは Web サーバーのメモリ リソースが消費され、アプリケーションの複雑さも増すため、この手法を使用して不完全な最適化を行わないことが重要です。
BlazorWebAssembly アプリにデータを取得する
Blazor Server を使用するアプリを構築している場合は、この章でここまで説明してきたように、Entity Framework やその他の直接データ アクセス テクノロジを使用できます。 ところが、他の SPA フレームワークのように、BlazorWebAssembly アプリを構築する場合は、データ アクセスのための別の方法が必要になります。 通常、これらのアプリケーションによって、データ アクセスと Web API エンドポイントを介したサーバーとのやりとりが行われます。
実行されるデータまたは操作の機密性が高い場合は、前の章のセキュリティに関するセクションを確認し、承認されていないアクセスから API を保護してください。
BlazorWebAssembly アプリの例は、BlazorAdmin プロジェクトの Blazor内にあります。 このプロジェクトは eShopOnWeb Web プロジェクト内でホストされ、管理者グループのユーザーがストア内の項目を管理できます。 図 8-3 は、アプリケーションのスクリーンショットです。
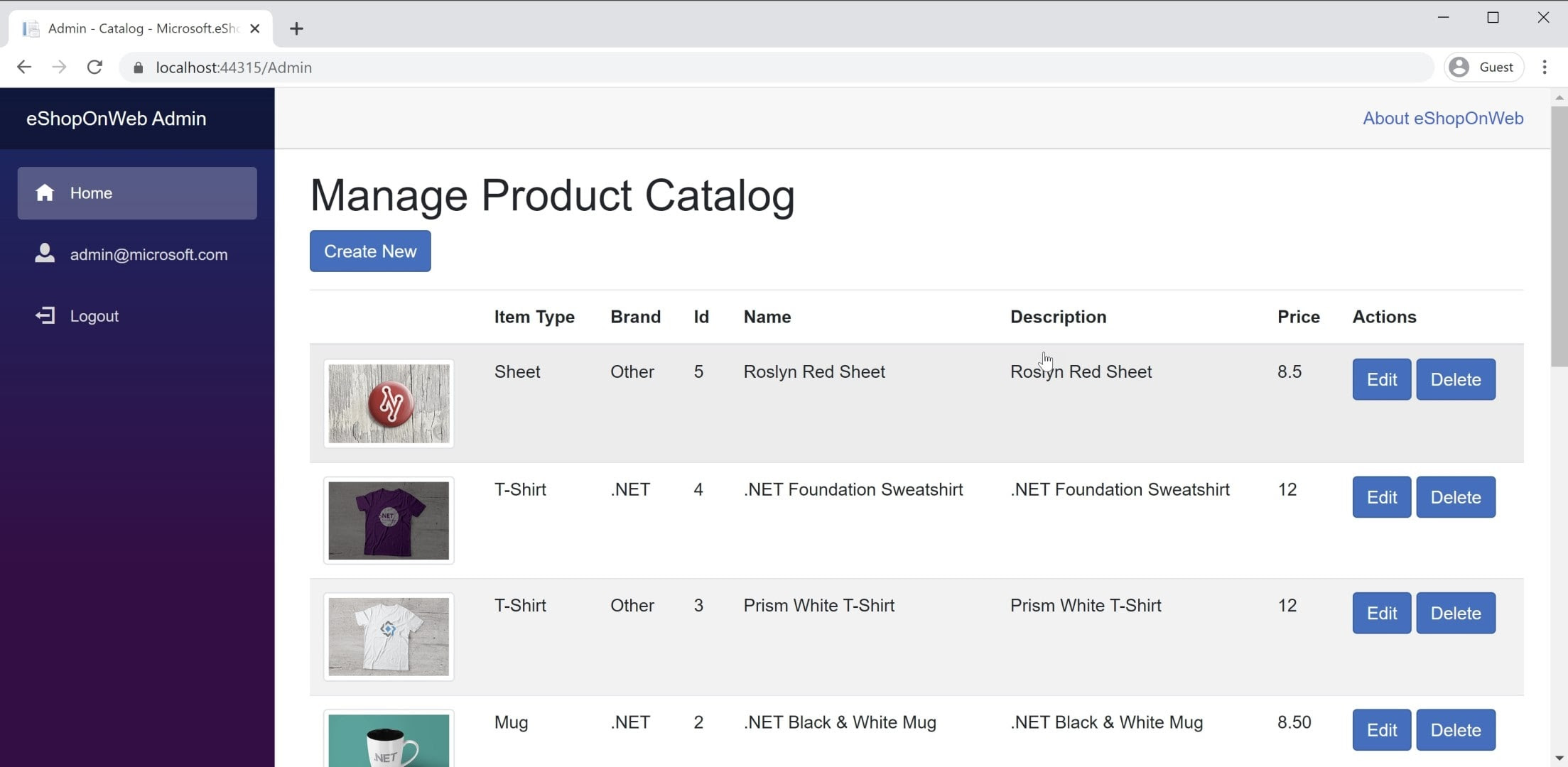
図 8-3 eShopOnWeb Catalog Admin スクリーンショット。
BlazorWebAssembly アプリ内の Web API からデータをフェッチする場合は、.NET アプリケーションの場合と同様に HttpClient のインスタンスを使用するだけです。 基本的な手順としては、送信する要求 (必要に応じて、通常は POST または PUT 要求用) を作成し、要求自体を待機して、ステータス コードを確認し、応答を逆シリアル化します。 API の特定のセットに対して行う要求の数が多い場合は、API をカプセル化し、HttpClient ベース アドレスを一元的に構成することをお勧めします。 このようにすると、環境間でこれらの設定を調整する必要がある場合に 1 か所で変更するだけで済みます。 このサービスのサポートを Program.Main に追加する必要があります。
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
サービスに安全にアクセスする必要がある場合は、セキュリティで保護されたトークンにアクセスし、すべての要求でこのトークンを認証ヘッダーとして渡すように HttpClient を構成する必要があります。
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
この操作は、Transient の有効期間で HttpClient がアプリケーションのサービスに追加されていない場合に、HttpClient が挿入されているすべてのコンポーネントから実行できます。 アプリケーション内の HttpClient へのすべての参照が同じインスタンスを参照するため、1 つのコンポーネント内でそれを変更すると、アプリケーション全体にフローされます。 この認証チェックを実行する (続けてトークンを指定する) のに適した場所は、サイトのメイン ナビゲーションのような共有コンポーネントです。 このアプローチの詳細については、BlazorAdminの BlazorAdmin プロジェクトを参照してください。
従来の JavaScript SPA に対するBlazorWebAssembly の利点の 1 つは、データ転送オブジェクト (DTO) のコピーを同期させておく必要がないことです。 BlazorWebAssembly プロジェクトと Web API プロジェクトはどちらも、共通の共有プロジェクトで同じ DTO を共有できます。 この方法により、SPA の開発に伴う摩擦の一部が軽減されます。
API エンドポイントからデータを迅速に取得するには、組み込みのヘルパー メソッド GetFromJsonAsync を使用できます。 同様のメソッドは、POST、PUT などにもあります。以下は、BlazorWebAssembly アプリで構成済みの HttpClient を使用して、API エンドポイントから CatalogItem を取得する方法を示します。
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
必要なデータが得られたら、通常はローカルで変更を追跡します。 バックエンド データ ストアを更新する場合は、この目的のために追加の Web API を呼び出します。
参照 – Blazor データ
- ASP.NET Core Blazorhttps://video2.skills-academy.com/aspnet/core/blazor/call-web-api から Web API を呼び出す
.NET